¿Qué es el aprendizaje no supervisado?
El aprendizaje no supervisado en la Inteligencia Artificial es un tipo de aprendizaje automático que aprende de los datos sin supervisión humana. A diferencia del aprendizaje supervisado, los modelos de aprendizaje automático no supervisados reciben datos sin etiquetar y pueden descubrir patrones y estadísticas sin ninguna orientación o instrucción explícita.
Sin importar si lo sabes o no, la Inteligencia Artificial y el aprendizaje automático impactan en todos los aspectos de la vida diaria y ayudan a convertir los datos en estadísticas que pueden mejorar la eficiencia, reducir los costos y fundamentar mejor la toma de decisiones. En la actualidad, las empresas usan algoritmos de aprendizaje automático para ofrecer recomendaciones personalizadas y traducciones en tiempo real, o incluso generar texto, imágenes y otros tipos de contenido automáticamente.
A continuación, analizaremos los conceptos básicos del aprendizaje automático no supervisado, cómo funciona y algunas de sus aplicaciones comunes en la vida real.
Los clientes nuevos obtienen hasta $300 en créditos gratuitos para probar Vertex AI y otros productos de Google Cloud.
¿Cómo funciona el aprendizaje no supervisado?
Como su nombre lo indica, el aprendizaje no supervisado utiliza algoritmos de autoaprendizaje: aprenden sin etiquetas ni entrenamiento previo. En cambio, el modelo recibe datos sin procesar y sin etiqueta y tiene que inferir sus propias reglas y estructurar la información en función de similitudes, diferencias y patrones sin instrucciones explícitas sobre cómo trabajar con cada dato.
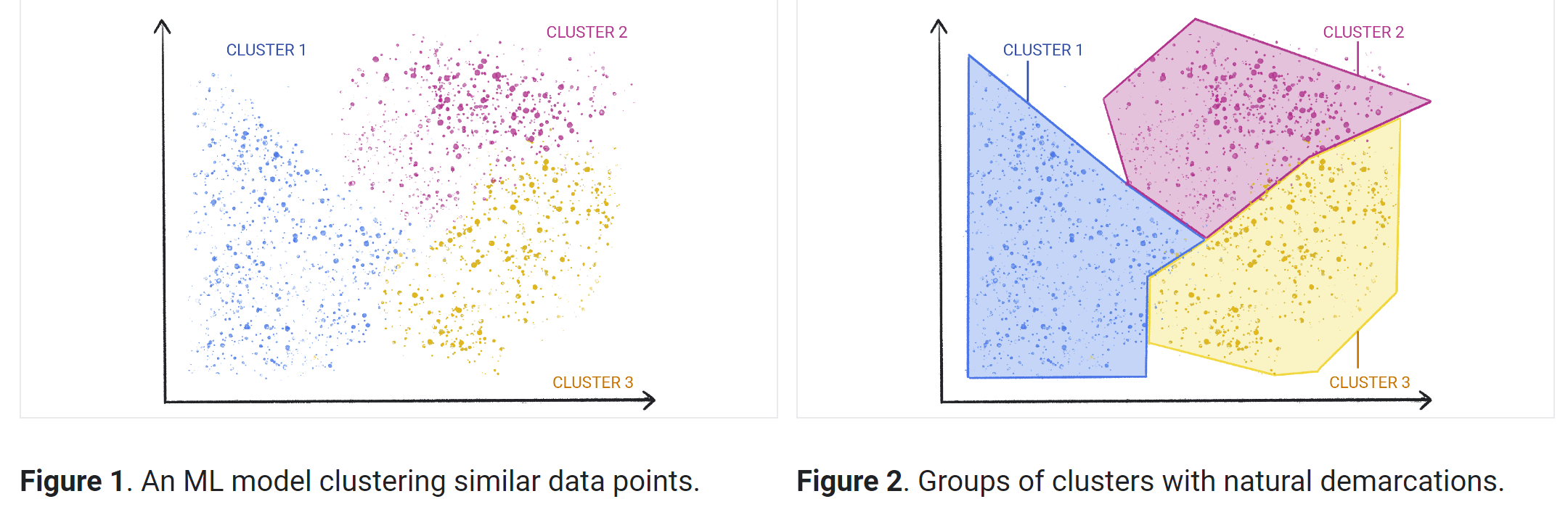
Los algoritmos de aprendizaje no supervisado son más adecuados para tareas de procesamiento más complejas, como la organización de conjuntos de datos grandes en clústeres. Son útiles para identificar patrones previamente no detectados en los datos y pueden ayudar a identificar características útiles para categorizar los datos.
Imagina que tienes un gran conjunto de datos sobre el clima. Un algoritmo de aprendizaje no supervisado analizará los datos e identificará patrones en los datos. Por ejemplo, podría agrupar datos por temperatura o patrones climáticos similares.
Si bien el algoritmo no comprende estos patrones según la información que proporcionaste, puedes pasar por las agrupaciones de datos e intentar clasificarlos según tu comprensión del conjunto de datos. Por ejemplo, podrías reconocer que los diferentes grupos de temperatura representan las cuatro estaciones o que los patrones climáticos están separados por diferentes tipos de clima, como lluvia, aguanieve o nieve.
Métodos de aprendizaje automático no supervisados
En general, existen tres tipos de tareas de aprendizaje no supervisado: agrupamiento en clústeres, reglas de asociación y reducción de dimensiones.
A continuación, veremos con más detalle cada tipo de técnica de aprendizaje no supervisado.
Agrupamiento en clústeres
El agrupamiento en clústeres es una técnica para explorar datos sin procesar y sin etiquetar y desglosarlos en grupos (o clústeres) según las similitudes o diferencias. Se usa en una variedad de aplicaciones, como la segmentación de clientes, la detección de fraudes y el análisis de imágenes. Los algoritmos de agrupamiento en clústeres dividen los datos en grupos naturales mediante la búsqueda de estructuras o patrones similares en los datos sin clasificar.
El agrupamiento en clústeres es uno de los enfoques de aprendizaje automático no supervisado más populares. Existen varios tipos de algoritmos de aprendizaje no supervisado que se usan para el agrupamiento en clústeres, entre los que se incluyen los exclusivos, los superpuestos, los jerárquicos y los probabilísticos.
- Agrupamiento en clústeres exclusivo: Los datos se agrupan de una manera en que un dato único puede existir solo en un clúster. Esto también se conoce como agrupamiento en clústeres “difícil”. Un ejemplo común de agrupamiento en clústeres exclusivo es el algoritmo de agrupamiento en clústeres K-means, que particiona los datos en una cantidad K de clústeres definida por el usuario.
- Agrupamiento en clústeres superpuesto: Los datos se agrupan, de manera que un solo dato puede existir en dos o más clústeres con diferentes grados de membresía. Esto también se conoce como agrupamiento en clústeres “secundario”.
- Agrupamiento en clústeres jerárquico: Los datos se dividen en clústeres distintos en función de las similitudes, que luego se combinan y organizan de forma repetida según sus relaciones jerárquicas. Existen dos tipos principales de agrupamiento en clústeres jerárquico: aglomerado y divisivo. Este método también se conoce como HAC (análisis de clústeres jerárquico).
- Agrupamiento en clústeres según la probabilidad: Los datos se agrupan en clústeres según la probabilidad de que cada dato pertenezca a cada clúster. Este enfoque difiere de los otros métodos, que agrupan los datos en función de sus similitudes con otros en un clúster.
Asociación
La minería de reglas asociadas es un enfoque basado en reglas que revela relaciones interesantes entre datos de grandes conjuntos de datos. Los algoritmos de aprendizaje no supervisado buscan asociaciones frecuentes del tipo si-entonces (también llamadas reglas) para descubrir correlaciones y casos conjuntas dentro de los datos, así como las diferentes conexiones entre los objetos de datos.
Por lo general, se usa para analizar cestas de minoristas o conjuntos de datos transaccionales para representar la frecuencia con la que ciertos artículos se compran juntos. Estos algoritmos descubren los patrones de compra de los clientes y las relaciones previamente ocultas entre los productos que ayudan a fundamentar los motores de recomendaciones y otras oportunidades de venta cruzada. Es posible que te familiarices más con estas reglas en las secciones “Las personas que compraron este artículo también compraron juntas” y “Las personas que compraron este artículo también compraron” en tu tienda minorista en línea favorita.
Las reglas de asociación también se usan a menudo para organizar los conjuntos de datos médicos para diagnósticos clínicos. El uso del aprendizaje automático no supervisado y las reglas de asociación puede ayudar a los médicos a identificar la probabilidad de un diagnóstico específico mediante la comparación de las relaciones entre los síntomas de casos anteriores de pacientes.
Por lo general, los algoritmos Apriori son los más utilizados en el aprendizaje de reglas de asociación para identificar colecciones relacionadas de elementos o conjuntos de elementos. No obstante, se usan otros tipos, como los algoritmos de Eclat y de crecimiento de FP.
Reducción de la dimensionalidad
La reducción de dimensionalidad es una técnica de aprendizaje no supervisado que reduce la cantidad de atributos o dimensiones en un conjunto de datos. Por lo general, tener más datos es mejor para el aprendizaje automático, pero también puede dificultar la visualización de los datos.
La reducción de dimensiones extrae atributos importantes del conjunto de datos, lo que reduce la cantidad de atributos irrelevantes o aleatorios presentes. Este método usa algoritmos de análisis de componentes de principios (PCA) y algoritmos de descomposición de valor singular (SVD) para reducir la cantidad de entradas de datos sin comprometer la integridad de las propiedades en los datos originales.
Ejemplos de aprendizaje no supervisado del mundo real
Ahora que comprendes los conceptos básicos del funcionamiento del aprendizaje no supervisado, veamos los casos de uso más comunes que ayudan a las empresas a explorar grandes volúmenes de datos con rapidez.
Estos son algunos ejemplos reales de aprendizaje no supervisado:
- Detección de anomalías: El agrupamiento en clústeres no supervisado puede procesar grandes conjuntos de datos y descubrir datos que son atípicos en un conjunto de datos.
- Motores de recomendaciones: Con las reglas de asociación, el aprendizaje automático no supervisado puede ayudar a explorar datos transaccionales a fin de descubrir patrones o tendencias que pueden usarse para impulsar recomendaciones personalizadas para minoristas en línea.
- Segmentación de clientes: El aprendizaje no supervisado también se usa comúnmente para generar perfiles de arquetipos de comprador mediante el agrupamiento en clústeres de las características comunes o los comportamientos de compra de los clientes. Estos perfiles se pueden usar para guiar el marketing y otras estrategias comerciales.
- Detección de fraudes: El aprendizaje no supervisado es útil para la detección de anomalías, ya que revela datos inusuales en los conjuntos de datos. Estas estadísticas pueden ayudar a descubrir eventos o comportamientos que se desvían de los patrones normales en los datos, lo que revela transacciones fraudulentas o comportamientos inusuales, como la actividad de bots.
- Procesamiento de lenguaje natural (PLN): El aprendizaje no supervisado se usa comúnmente para varias aplicaciones de PLN, como la categorización de artículos en secciones de noticias, la traducción y clasificación de texto, o el reconocimiento de voz en interfaces de conversación.
- Investigación genética: El agrupamiento en clústeres genético es otro ejemplo común de aprendizaje no supervisado. Los algoritmos de agrupamiento en clústeres jerárquico se suelen usar para analizar patrones de ADN y revelar relaciones evolutivas.
El aprendizaje no supervisado es adecuado para tareas que requieren explorar grandes cantidades de datos sin etiquetar. Con este enfoque, es más fácil para las empresas obtener estadísticas a partir de los datos cuando no hay etiquetas, lo que las ayuda a comprender la estructura subyacente de un conjunto de datos y a identificar patrones y relaciones entre conjuntos de datos sin la necesidad de que una persona los enseñe.
Comparación entre el aprendizaje supervisado y el aprendizaje no supervisado
La principal diferencia entre el aprendizaje supervisado y el no supervisado es el tipo de datos de entrada que usas. A diferencia de los algoritmos de aprendizaje automático no supervisado, el aprendizaje supervisado se basa en datos de entrenamiento etiquetados para determinar si el reconocimiento de patrones dentro de un conjunto de datos es preciso.
Los objetivos de los modelos de aprendizaje supervisado también están predeterminados, lo que significa que el tipo de salida de un modelo ya se conoce antes de que se apliquen los algoritmos. En otras palabras, la entrada se asigna a la salida en función de los datos de entrenamiento.
Productos y servicios relacionados
Google ofrece una variedad de productos, soluciones y aplicaciones innovadores de IA y aprendizaje automático que permiten a las empresas compilar e implementar fácilmente algoritmos y modelos de aprendizaje automático.
 Vertex AIUna plataforma de aprendizaje automático unificada de extremo a extremo para compilar, implementar y escalar modelos de IA.
Vertex AIUna plataforma de aprendizaje automático unificada de extremo a extremo para compilar, implementar y escalar modelos de IA. IA de Natural LanguageAprendizaje automático de Google para obtener estadísticas a partir de texto no estructurado
IA de Natural LanguageAprendizaje automático de Google para obtener estadísticas a partir de texto no estructuradoSolución
Ciencia de datosUn conjunto completo de herramientas de administración de datos, estadísticas y aprendizaje automático.
Da el siguiente paso
Comienza a desarrollar en Google Cloud con el crédito gratis de $300 y los más de 20 productos del nivel Siempre gratuito.
¿Necesitas ayuda para comenzar?
Comunicarse con VentasTrabaja con un socio confiable
Buscar un socioSigue explorando
Ver todos los productos











