Was ist nicht überwachtes Lernen?
Unüberwachtes Lernen künstlicher Intelligenz ist eine Art des maschinellen Lernens, bei dem die KI ohne menschliche Aufsicht aus Daten lernt. Anders als beim überwachten Lernen erhalten die Modelle für nicht überwachtes maschinelles Lernen Daten ohne Label und können so ohne ausdrückliche Anleitung oder Anweisungen Muster erkennen und zu Erkenntnissen kommen.
Unabhängig davon, ob es Ihnen bewusst ist, wirken sich künstliche Intelligenz und maschinelles Lernen auf jeden Aspekt des täglichen Lebens aus und helfen dabei, aus Daten Erkenntnisse zu gewinnen, die Ihnen dabei helfen können, Effizienzen zu steigern, Kosten zu senken und fundierte Entscheidungen zu treffen. Unternehmen nutzen heute Algorithmen für maschinelles Lernen, um personalisierte Empfehlungen, Übersetzungen in Echtzeit oder sogar automatisch generierte Texte, Bilder und andere Arten von Inhalten zu erstellen.
Hier lernen Sie die Grundlagen des unüberwachten maschinellen Lernens, dessen Funktionsweise und einige seiner gängigen Anwendungen kennen.
Neukunden erhalten ein Guthaben von bis zu 300 $, um die Gemini Enterprise Agent Platform und andere Google Cloud-Produkte auszuprobieren.
Wie funktioniert nicht überwachtes Lernen?
Wie der Name schon sagt, werden beim unüberwachten Lernen selbstlernende Algorithmen verwendet, die ohne Labels oder vorheriges Training lernen. Stattdessen erhält das Modell Rohdaten ohne Label. Es muss seine eigenen Regeln ableiten und die Informationen anhand von Ähnlichkeiten, Unterschieden und Mustern strukturieren, ohne dass es explizite Anweisungen für die Verarbeitung der einzelnen Daten erhält.
Algorithmen für unüberwachtes Lernen eignen sich besser für komplexere Verarbeitungsaufgaben, wie das Organisieren großer Datasets in Clustern. Sie sind nützlich, um bisher unentdeckte Muster in Daten zu erkennen, und können dabei helfen, Merkmale zu identifizieren, die für die Kategorisierung von Daten nützlich sind.
Stellen Sie sich vor, Sie haben ein großes Dataset mit Wetterdaten. Ein Algorithmus für unüberwachtes Lernen durchsucht die Daten und identifiziert Muster in den Datenpunkten. Er könnte beispielsweise Daten nach Temperatur oder ähnlichen Wetterlagen gruppieren.
Der Algorithmus selbst versteht diese Muster nicht auf der Grundlage von Informationen, die Sie zuvor bereitgestellt haben. Sie können sich dann aber die Datengruppierungen ansehen und versuchen, sie auf der Grundlage Ihres Verständnisses des Datasets zu klassifizieren. Beispielsweise könnten Sie erkennen, dass die verschiedenen Temperaturgruppen alle vier Jahreszeiten darstellen oder dass die Wetterlagen in verschiedene Wettertypen wie Regen, Graupel oder Schnee unterteilt sind.
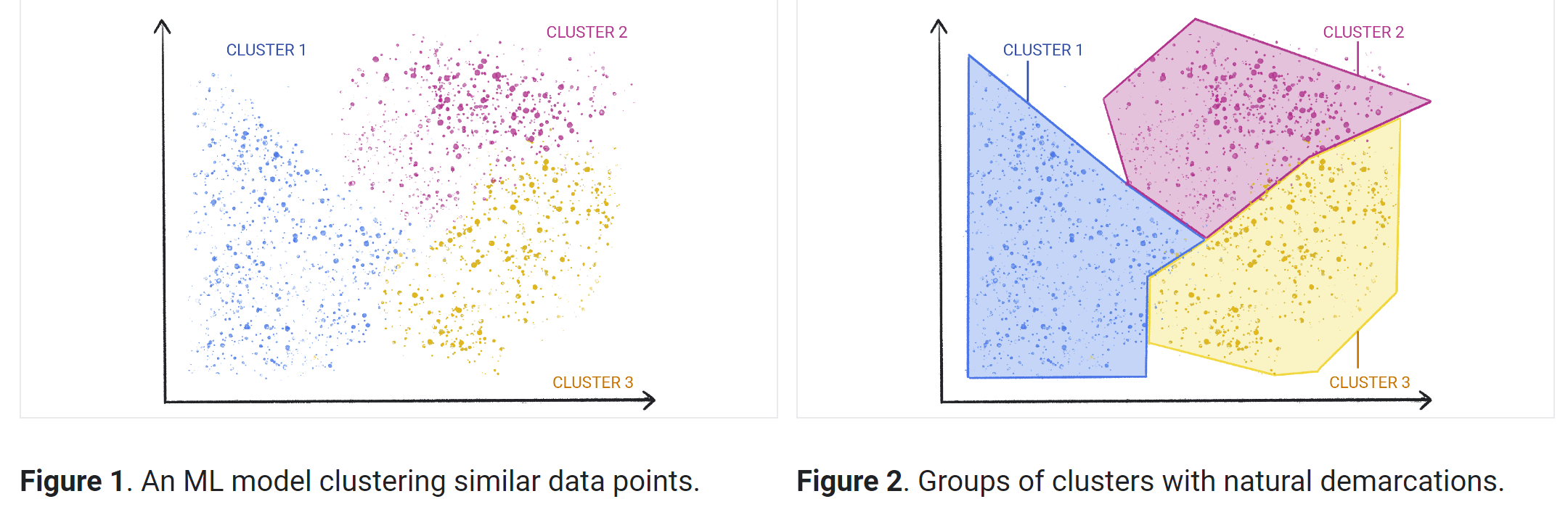
Unüberwachte Machine-Learning-Methoden
Im Allgemeinen gibt es drei Arten von Aufgaben für unbeaufsichtigtes Lernen: Clustering, Assoziationsregeln und Dimensionalitätsreduktion.
Im Folgenden gehen wir etwas genauer auf die einzelnen Arten von Techniken für unüberwachtes Lernen ein.
Clustering
Clustering ist eine Technik, mit der unbeschriftete Rohdaten untersucht und basierend auf Ähnlichkeiten oder Unterschieden in Gruppen (oder Cluster) gegliedert werden. Es wird in einer Vielzahl von Anwendungen eingesetzt, darunter Kundensegmentierung, Betrugserkennung und Bildanalyse. Clustering-Algorithmen teilen Daten in natürliche Gruppen auf, indem sie ähnliche Strukturen oder Muster in nicht kategorisierten Daten finden.
Clustering ist einer der beliebtesten Ansätze für unbeaufsichtigtes maschinelles Lernen. Es gibt verschiedene Arten von Algorithmen für unbeaufsichtigtes Lernen, die für das Clustering verwendet werden, darunter exklusive, überlappende, hierarchische und probabilistische.
- Exklusives Clustering: Daten werden so gruppiert, dass ein einzelner Datenpunkt nur in einem Cluster vorhanden sein kann. Dies wird auch als „hartes“ Clustering bezeichnet. Ein häufiges Beispiel für exklusives Clustering ist der K-Means-Clustering-Algorithmus, der Datenpunkte in eine vom Nutzer definierte Anzahl K von Clustern aufteilt.
- Überlappende Clustering: Daten werden so gruppiert, dass ein einzelner Datenpunkt in zwei oder mehr Clustern mit unterschiedlichen Mitgliedschaftsgraden vorhanden sein kann. Dies wird auch als „weiches“ Clustering bezeichnet.
- Hierarchisches Clustering: Daten werden anhand von Ähnlichkeiten in verschiedene Cluster unterteilt, die dann wiederholt zusammengeführt und basierend auf ihren hierarchischen Beziehungen organisiert werden. Es gibt zwei Haupttypen von hierarchischem Clustering: agglomeratives und divisives Clustering. Diese Methode wird auch als HAC (Hierarchical Cluster Analysis) bezeichnet.
- Probabilistisches Clustering: Daten werden basierend auf der Wahrscheinlichkeit, dass jeder Datenpunkt zu jedem Cluster gehört, in Clustern gruppiert. Dieser Ansatz unterscheidet sich von den anderen Methoden, bei denen Datenpunkte basierend auf ihren Ähnlichkeiten zu anderen in einem Cluster gruppiert werden.
Verknüpfung
Association Rule Mining ist ein regelbasierter Ansatz, um interessante Beziehungen zwischen Datenpunkten in großen Datasets aufzudecken. Algorithmen für unüberwachtes Lernen suchen nach häufigen Wenn-Dann-Assoziationen – auch Regeln genannt –, um Korrelationen und Kookkurrenzen in den Daten und die verschiedenen Verbindungen zwischen Datenobjekten zu erkennen.
Es wird am häufigsten verwendet, um Warenkörbe oder Datensätze zu Transaktionen zu analysieren und darzustellen, wie oft bestimmte Artikel zusammen gekauft werden. Diese Algorithmen identifizieren Kaufmuster der Kunden und bisher verborgene Beziehungen zwischen Produkten, die als Grundlage für Empfehlungssysteme oder andere Cross-Selling-Möglichkeiten dienen. Vielleicht kennen Sie diese Regeln aus den Abschnitten „Häufig zusammen gekauft“ und „Nutzer, die diesen Artikel gekauft haben, kauften auch“ in Ihrem Lieblings-Onlineshop.
Assoziationsregeln werden auch häufig verwendet, um medizinische Datensätze für klinische Diagnosen zu organisieren. Mithilfe von unüberwachtem maschinellem Lernen und Verknüpfungsregeln können Ärzte die Wahrscheinlichkeit einer bestimmten Diagnose ermitteln, indem sie die Beziehungen zwischen Symptomen aus früheren Patientenfällen vergleichen.
Apriori-Algorithmen werden in der Regel am häufigsten für das Erlernen von Assoziationsregeln verwendet, um zusammenhängende Sammlungen von Artikeln oder Artikelmengen zu identifizieren. Es werden aber auch andere Typen verwendet, z. B. Eclat- und FP-Growth-Algorithmen.
Dimensionalitätsreduktion
Die Dimensionalitätsreduktion ist eine Technik des unüberwachten Lernens, mit der die Anzahl der Features oder Dimensionen in einem Dataset reduziert wird. Mehr Daten sind im Allgemeinen besser für das maschinelle Lernen, aber sie können auch die Visualisierung der Daten erschweren.
Bei der Dimensionalitätsreduktion werden wichtige Merkmale aus dem Dataset extrahiert und die Anzahl irrelevanter oder zufällig vorhandener Merkmale reduziert. Bei dieser Methode werden PCA-Algorithmen (Principle Component Analysis) und SVD-Algorithmen (Singular Value Decomposition) verwendet, um die Anzahl der Dateneingaben zu reduzieren, ohne die Integrität der Merkmale in den Originaldaten zu beeinträchtigen.
Beispiele für unbeaufsichtigtes Lernen in der Praxis
Nachdem Sie nun die Grundlagen des unüberwachten Lernens kennen, sehen wir uns die häufigsten Anwendungsfälle an, mit denen Unternehmen große Datenmengen schnell analysieren können.
Hier sind einige Beispiele für unüberwachtes Lernen aus der Praxis:
- Anomalieerkennung: Unüberwachtes Clustering kann große Datasets verarbeiten und Datenpunkte ermitteln, die in einem Dataset atypisch sind.
- Empfehlungssysteme: Mithilfe von Verknüpfungsregeln kann unüberwachtes maschinelles Lernen bei Transaktionsdaten helfen, Muster oder Trends zu erkennen und personalisierte Empfehlungen für Onlinehändler zu erhalten.
- Kundensegmentierung: Unüberwachtes Lernen wird häufig verwendet, um Profile der Käuferidentität zu erstellen. Dazu werden die gemeinsamen Merkmale oder das Kaufverhalten der Kunden gruppiert. Diese Profile können dann als Grundlage für Marketing- und andere Geschäftsstrategien dienen.
- Betrugserkennung: Unüberwachtes Lernen ist nützlich für die Anomalieerkennung, bei der ungewöhnliche Datenpunkte in Datasets aufgedeckt werden. Diese Erkenntnisse können Ihnen helfen, Ereignisse oder Verhaltensweisen aufzudecken, die von normalen Mustern in den Daten abweichen, und so betrügerische Transaktionen oder ungewöhnliches Verhalten wie Bot-Aktivitäten aufzudecken.
- Natural Language Processing (NLP): Unüberwachtes Lernen wird häufig für verschiedene NLP-Anwendungen verwendet, z. B. zum Kategorisieren von Artikeln in Nachrichtenrubriken, für die Textübersetzung und -klassifizierung oder für die Spracherkennung in dialogorientierten Schnittstellen.
- Genetische Forschung: Genetisches Clustering ist ein weiteres häufiges Beispiel für unüberwachtes Lernen. Hierarchische Clustering-Algorithmen werden häufig verwendet, um DNA-Muster zu analysieren und evolutionäre Beziehungen aufzudecken.
Unüberwachtes Lernen eignet sich gut für Aufgaben, bei denen große Mengen an Daten ohne Label untersucht werden müssen. Dieser Ansatz erleichtert es Unternehmen, Erkenntnisse aus Daten zu gewinnen, wenn keine Labels vorhanden sind. So können sie die zugrunde liegende Struktur eines Datasets verstehen und Muster und Beziehungen zwischen Datasets erkennen, ohne dass ein Mensch sie unterrichten muss.
Überwachtes Lernen im Vergleich zu unüberwachtem Lernen
Der Hauptunterschied zwischen beaufsichtigtem und unbeaufsichtigtem Lernen ist die Art der Eingabedaten. Im Gegensatz zu unbeaufsichtigten Algorithmen für maschinelles Lernen stützt sich das beaufsichtigte Lernen auf gelabelte Trainingsdaten, um zu bestimmen, ob die Mustererkennung in einem Datensatz korrekt ist.
Die Ziele von Modellen für überwachtes Lernen sind ebenfalls vorgegeben. Das bedeutet, dass die Art der Ausgabe eines Modells bereits bekannt ist, bevor die Algorithmen angewendet werden. Mit anderen Worten: Die Eingabe wird anhand der Trainingsdaten der Ausgabe zugeordnet.
Ähnliche Produkte und Dienste
Google bietet eine Reihe innovativer Produkte, Lösungen und Anwendungen für KI und Machine Learning, mit denen Unternehmen ganz einfach Algorithmen und Modelle für Machine Learning erstellen und implementieren können.
 Gemini Enterprise Agent PlatformEine einheitliche End-to-End-Plattform für maschinelles Lernen zum Erstellen, Bereitstellen und Skalieren von KI-Modellen.
Gemini Enterprise Agent PlatformEine einheitliche End-to-End-Plattform für maschinelles Lernen zum Erstellen, Bereitstellen und Skalieren von KI-Modellen. Natural Language APIGoogle Machine Learning, um Informationen aus unstrukturiertem Text zu gewinnen.
Natural Language APIGoogle Machine Learning, um Informationen aus unstrukturiertem Text zu gewinnen.Lösung
Data ScienceEine umfassende Suite mit Tools für Datenverwaltung, Analysen und maschinelles Lernen.
Gleich loslegen
Profitieren Sie von einem Guthaben in Höhe von 300 $ und mehr als 20 immer kostenlose Produkten, um Google Cloud kennenzulernen.
Benötigen Sie Hilfe beim Einstieg?
Vertrieb kontaktierenMit einem zertifizierten Partnerunternehmen arbeiten
Partner findenMehr ansehen
Alle Produkte ansehen


















