What is unsupervised learning?
Unsupervised learning in artificial intelligence is a type of machine learning that learns from data without human supervision. Unlike supervised learning, unsupervised machine learning models are given unlabeled data and allowed to discover patterns and insights without any explicit guidance or instruction.
Whether you realize it or not, artificial intelligence and machine learning are impacting every aspect of daily life, helping to turn data into insights that can improve efficiencies, reduce costs, and better inform decision-making. Today, businesses are using machine learning algorithms to help power personalized recommendations, real-time translations, or even automatically generate text, images, and other types of content.
Here, we’ll cover the basics of unsupervised machine learning, how it works, and some of its common real-life applications.
New customers get up to $300 in free credits to try Gemini Enterprise Agent Platform and other Google Cloud products.
How does unsupervised learning work?
As the name suggests, unsupervised learning uses self-learning algorithms—they learn without any labels or prior training. Instead, the model is given raw, unlabeled data and has to infer its own rules and structure the information based on similarities, differences, and patterns without explicit instructions on how to work with each piece of data.
Unsupervised learning algorithms are better suited for more complex processing tasks, such as organizing large datasets into clusters. They are useful for identifying previously undetected patterns in data and can help identify features useful for categorizing data.
Imagine that you have a large dataset about weather. An unsupervised learning algorithm will go through the data and identify patterns in the data points. For instance, it might group data by temperature or similar weather patterns.
While the algorithm itself does not understand these patterns based on any previous information you provided, you can then go through the data groupings and attempt to classify them based on your understanding of the dataset. For instance, you might recognize that the different temperature groups represent all four seasons or that the weather patterns are separated into different types of weather, such as rain, sleet, or snow.
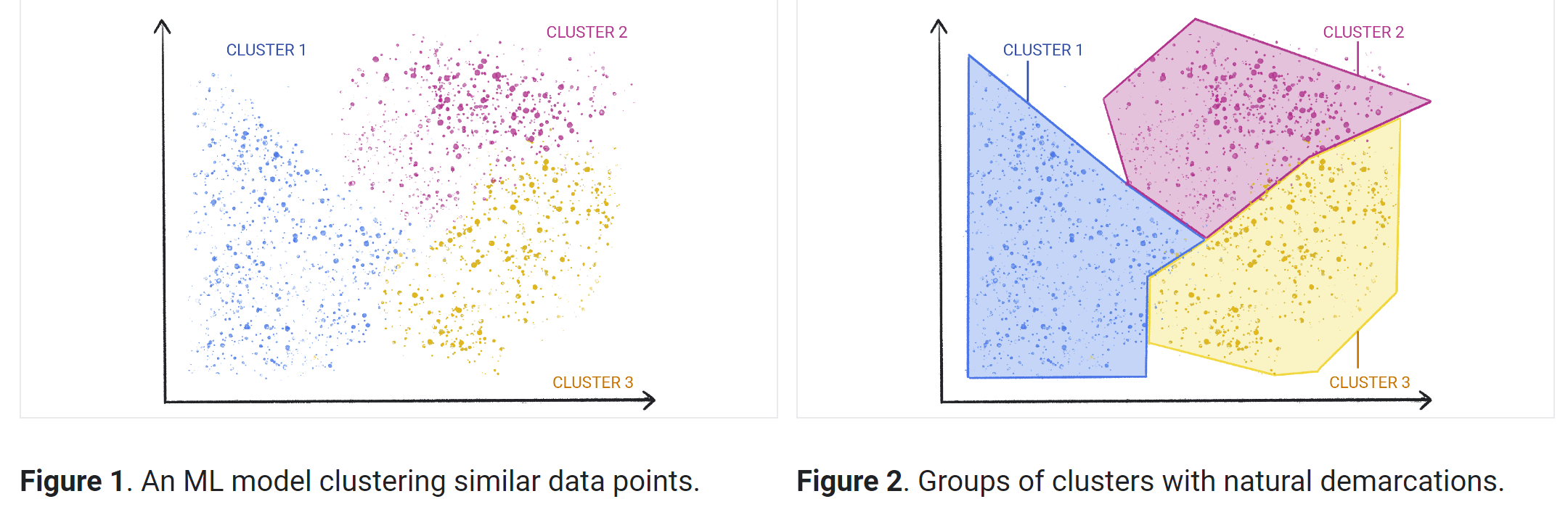
Unsupervised machine learning methods
In general, there are three types of unsupervised learning tasks: clustering, association rules, and dimensionality reduction.
Below we’ll delve a little deeper into each type of unsupervised learning technique.
Clustering
Clustering is a technique for exploring raw, unlabeled data and breaking it down into groups (or clusters) based on similarities or differences. It is used in a variety of applications, including customer segmentation, fraud detection, and image analysis. Clustering algorithms split data into natural groups by finding similar structures or patterns in uncategorized data.
Clustering is one of the most popular unsupervised machine learning approaches. There are several types of unsupervised learning algorithms that are used for clustering, which include exclusive, overlapping, hierarchical, and probabilistic.
- Exclusive clustering: Data is grouped in a way where a single data point can only exist in one cluster. This is also referred to as “hard” clustering. A common example of exclusive clustering is the K-means clustering algorithm, which partitions data points into a user-defined number K of clusters.
- Overlapping clustering: Data is grouped in a way where a single data point can exist in two or more clusters with different degrees of membership. This is also referred to as “soft” clustering.
- Hierarchical clustering: Data is divided into distinct clusters based on similarities, which are then repeatedly merged and organized based on their hierarchical relationships. There are two main types of hierarchical clustering: agglomerative and divisive clustering. This method is also referred to as HAC—hierarchical cluster analysis.
- Probabilistic clustering: Data is grouped into clusters based on the probability of each data point belonging to each cluster. This approach differs from the other methods, which group data points based on their similarities to others in a cluster.
Association
Association rule mining is a rule-based approach to reveal interesting relationships between data points in large datasets. Unsupervised learning algorithms search for frequent if-then associations—also called rules—to discover correlations and co-occurrences within the data and the different connections between data objects.
It is most commonly used to analyze retail baskets or transactional datasets to represent how often certain items are purchased together. These algorithms uncover customer purchasing patterns and previously hidden relationships between products that help inform recommendation engines or other cross-selling opportunities. You might be most familiar with these rules from the “Frequently bought together” and “People who bought this item also bought” sections on your favorite online retail shop.
Association rules are also often used to organize medical datasets for clinical diagnoses. Using unsupervised machine learning and association rules can help doctors identify the probability of a specific diagnosis by comparing relationships between symptoms from past patient cases.
Typically, Apriori algorithms are the most widely used for association rule learning to identify related collections of items or sets of items. However, other types are used, such as Eclat and FP-growth algorithms.
Dimensionality reduction
Dimensionality reduction is an unsupervised learning technique that reduces the number of features, or dimensions, in a dataset. More data is generally better for machine learning, but it can also make it more challenging to visualize the data.
Dimensionality reduction extracts important features from the dataset, reducing the number of irrelevant or random features present. This method uses principle component analysis (PCA) and singular value decomposition (SVD) algorithms to reduce the number of data inputs without compromising the integrity of the properties in the original data.
Real-world unsupervised learning examples
Now that you understand the basics of how unsupervised learning works, let’s look at the most common use cases helping businesses explore large volumes of data quickly.
Here are some real-world unsupervised learning examples:
- Anomaly detection: Unsupervised clustering can process large datasets and discover data points that are atypical in a dataset.
- Recommendation engines: Using association rules, unsupervised machine learning can help explore transactional data to discover patterns or trends that can be used to drive personalized recommendations for online retailers.
- Customer segmentation: Unsupervised learning is also commonly used to generate buyer persona profiles by clustering customers’ common traits or purchasing behaviors. These profiles can then be used to guide marketing and other business strategies.
- Fraud detection: Unsupervised learning is useful for anomaly detection, revealing unusual data points in datasets. These insights can help uncover events or behaviors that deviate from normal patterns in the data, revealing fraudulent transactions or unusual behavior like bot activity.
- Natural language processing (NLP): Unsupervised learning is commonly used for various NLP applications, such as categorizing articles in news sections, text translation and classification, or speech recognition in conversational interfaces.
- Genetic research: Genetic clustering is another common unsupervised learning example. Hierarchical clustering algorithms are often used to analyze DNA patterns and reveal evolutionary relationships.
Unsupervised learning is well suited for tasks that require exploring large amounts of unlabeled data. This approach makes it easier for businesses to gain insights from data when no labels are present, helping them to understand the underlying structure of a dataset and identify patterns and relationships between datasets without the need for a human to teach them.
Supervised learning vs. unsupervised learning
The main difference between supervised learning and unsupervised learning is the type of input data that you use. Unlike unsupervised machine learning algorithms, supervised learning relies on labeled training data to determine whether pattern recognition within a dataset is accurate.
The goals of supervised learning models are also predetermined, meaning that the type of output of a model is already known before the algorithms are applied. In other words, the input is mapped to the output based on the training data.
Related products and services
Google offers a number of innovative AI and machine learning products, solutions, and applications, enabling businesses to easily build and implement machine learning algorithms and models.


Take the next step
Start building on Google Cloud with $300 in free credits and 20+ always free products.
Need help getting started?
Contact salesWork with a trusted partner
Find a partnerContinue browsing
See all products


















