データベース シャーディングとは
データベース シャーディングは、大量のデータを扱うアプリケーションにおけるスケーラビリティの問題を解決するために使用される手法です。これには、単一の大きな論理データセットを、シャードと呼ばれるより管理しやすい小さな単位に分割することが含まれます。各シャードは別々のデータベース サーバー インスタンスに保存されるため、データとワークロードを複数のマシンに効果的に分散できます。
シャーディングは、水平スケーリング(スケールアウト)を実現するための主要な手法の一つです。CPU や RAM を増設して単一のサーバーを強化する(垂直スケーリング)方法では、最終的にハードウェアの限界に達します。一方、シャーディングでは、汎用サーバーをクラスターに追加していくことが可能です。これにより、アプリケーションはデータ量とユーザー トラフィックがどれだけ増えても対応することが可能です。

シャーディングはスケールアウトの強力な手法ですが、水平スケーリングの一般的な戦略としては以下の 3 つがあります。
- リードレプリカ: プライマリ データベースのコピーを作成して読み取り専用トラフィックを処理することで、メインサーバーの負荷を軽減する手法
- シャーディング: データと書き込みトラフィックの両方を複数の独立したサーバーに分散する手法
- 分散データベース: Spanner などのプロダクトは、データベース エンジン自体で分散とスケーリングをネイティブに処理するため、手動によるシャーディングが不要
データベース シャーディングの仕組み
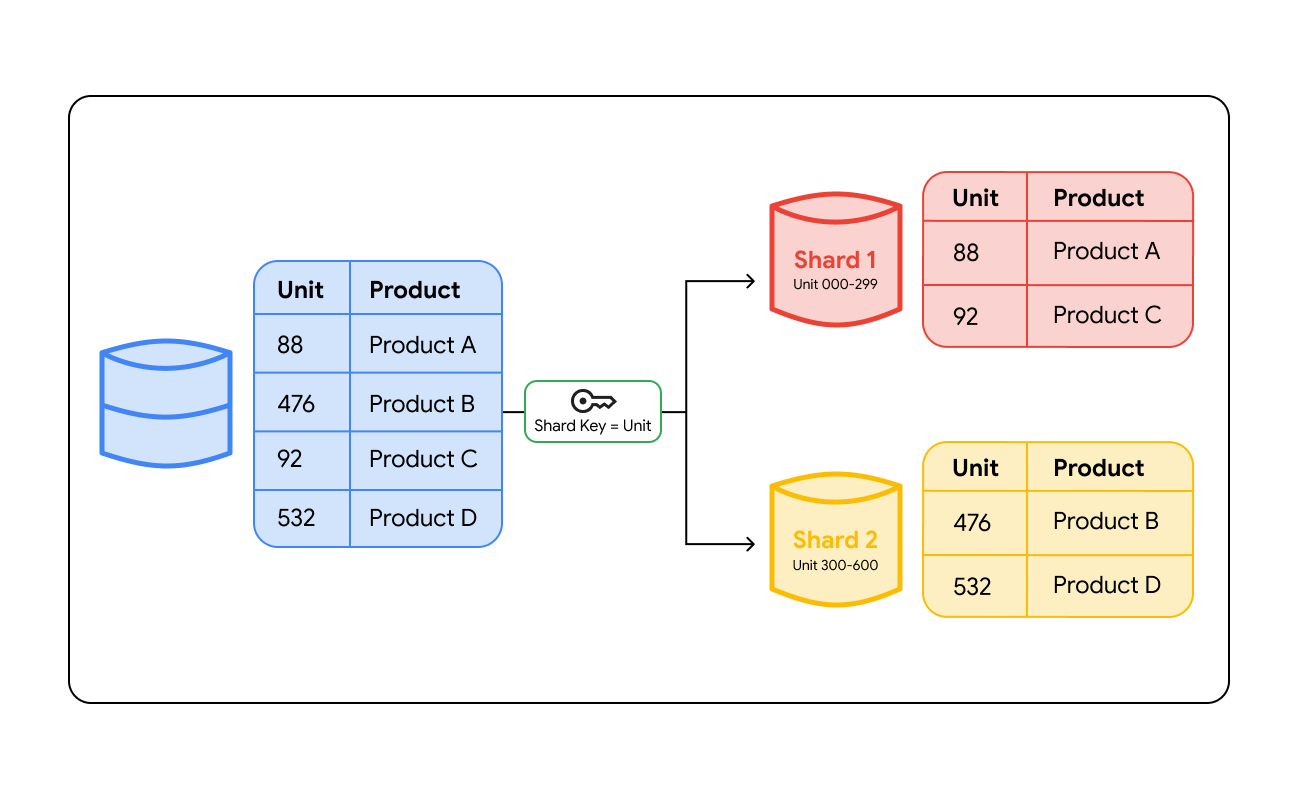
データベース シャーディングは、シャードキーと呼ばれる特定の値を基にデータをグループ化することで機能します。シャードキーとは、ユーザー ID、顧客の地域、注文番号などのデータベース内の列であり、データの特定の行をどのサーバーに保存するかを決定するものです。データがデータベースに書き込まれると、システムはこのキーを参照して、どのサーバーに配置するかを判断します。
後でデータを検索する際には、システムはクエリを正しい場所へルーティングする必要があります。このルーティングは、主に次の 2 つの方法で行われます。
- ルーティング レイヤ: シャーディング アーキテクチャでは、スマート ロードバランサまたは専用のプロキシレイヤを使用できます。アプリケーションがクエリを送信すると、ルーティング レイヤはシャードキーをチェックし、該当データを保持するシャードを特定して、トラフィックをそのサーバーに転送します。
- アプリケーション側のロジック: マルチプレーヤー ゲームや高パフォーマンスのリアルタイム アプリなどでは、アプリケーション コード自体にシャーディング ロジックが含まれている場合があります。このコードは、リクエストを送信する前に正しいシャードの場所を計算するため、ネットワークのホップを 1 回分削減でき、レイテンシの低減につながります。
関連するシャードのみを対象とすることで、データベースはクエリにより迅速に応答でき、数千件の同時リクエストがあっても速度を低下させずに処理できます。
一般的なシャーディング方法
アプリケーションごとに、データを分割するために必要なロジックは異なります。選択する方法によって、「ルーティング レイヤ」がデータをどのように特定するかが決まります。
キーベース シャーディング(ハッシュ シャーディング)
この方法では、シャードキーに対して数式(ハッシュ関数)を使用してデータを割り当てます。たとえば、システムはユーザー ID を 4 で割った余り(mod 4)を計算し、4 台のサーバーのうちどれに割り当てるかを決定します。
ハッシュ関数はデータを一貫して分散させるのに役立ちますが、シャードキーのカーディナリティが高く、頻度の偏りが少ない場合にのみ、均等な分散が保証されます。たとえば、「姓」など、共通の値を持つキーを選び、「Smith」が「Pyne」より 1,000 倍多く存在する場合、ハッシュ関数はすべての「Smith」レコードを同じシャードに送ります。これにより、数式を使っても「ホットシャード」が発生することになります。
また、この方法では、数式が変更されるため、新しいサーバーを追加することも困難です。多くの場合、「再シャーディング」または新しいサーバー クラスタへのデータの移動が必要になります。
レンジベースのシャーディング
データは値の範囲に基づいて割り当てられます。たとえば、ユーザー ID 1 ~ 1,000 をサーバー A に、1,001 ~ 2,000 をサーバー B に配置するといった方法です。この方法は非常に直感的で、連続したデータを読み取る必要があるクエリ(範囲クエリ)に適しています。ただし、欠点として「ホットスポット」が発生する可能性があります。たとえば、新規ユーザーがすべてサーバー B に割り当てられると、そのサーバーがすべての処理を担当し、サーバー A はアイドル状態になってしまいます。
ディレクトリ ベースのシャーディング
この手法では、どのシャードにどのデータが保持されているかを正確に追跡するルックアップ テーブル(ディレクトリ)を使用します。数式を変更せずにシャード間でデータを移動できるため、最も高い柔軟性を実現できます。しかし、このルックアップ テーブルがボトルネックになります。すべてのクエリで最初にディレクトリを参照する必要があるため、レイテンシが発生します。また、ディレクトリに障害が発生すると、データベース全体にアクセスできなくなります。
ジオ シャーディング
ジオ シャーディングとは、ユーザーの所在地に基づいて、データを特定のサーバーに割り当てる手法です。たとえば、フランスのユーザーのデータは EU のサーバーに保存され、米国のユーザーのデータは北米のサーバーに保存されます。これにより、ユーザーのレイテンシ(待ち時間)が大幅に短縮されるとともに、企業が GDPR などのデータ所在地に関する法律の遵守にも役立ちます。
垂直シャーディング
機能的パーティショニングとも呼ばれるこの方法では、行単位ではなく機能単位でデータを分割します。たとえば、「ユーザー プロフィール」関連のすべてのテーブルをサーバー A に配置し、「写真アップロード」関連のすべてのテーブルをサーバー B に配置するといった方法です。この方法ではデータを論理的に整理できますが、実質的にはマイクロサービス型のデータ アーキテクチャと同様の構成になります。そのため、特定の機能(写真など)が単一サーバーでは処理しきれないほど大規模に成長した場合には、問題の解決にはなりません。
データが均等に分散されるようにデータベース シャーディングを最適化する方法
シャーディングにおいて最も重要な決定は、適切なシャードキーを選択することです。キーが適切でないと、データの分散が不均一(ホットスポット)になり、一方でキーが適切であれば、すべてのサーバーが均等に負担を処理できます。これを最適化するには、次の 3 つの要素を検討する必要があります。
- カーディナリティ: キーが取り得る一意の値の数を指します。カーディナリティが低いキー(「性別」や「都道府県」など)ではなく、カーディナリティが高いキー(ユーザー ID など)を使用すると、データを多数の小さなチャンクに分割できます。
- 頻度: 特定の値が頻繁に現れるキーは避ける必要があります。たとえば、「市区町村」でシャーディングし、ユーザーの 80% がニューヨークに住んでいる場合、「ニューヨーク」シャードに負荷が集中してしまいます。
- 単調な変更: タイムスタンプや自動インクリメント ID のように、時間とともに一方向に増加し続けるキーは避ける必要があります。日付でシャーディングした場合、新しい書き込みはすべて「今日」シャードに集中し、古いシャードがアイドル状態になり、書き込みホットスポットが発生します。
主なシャーディング用語
これらの用語はシステム設計で併せて使用されることが多いですが、それぞれ解決する問題は異なります。
シャーディング
シャーディングは、データの断片を完全に異なるサーバー間に分散する、水平パーティショニングの一種です。これにより、異なるサーバーが同時に書き込みを処理できるため、ハードウェアの容量制限(ストレージ)と書き込みスループットのボトルネックの両方を解消できます。
- 手動シャーディング: 手動シャーディング環境では、デベロッパーまたはデータベース管理者が、シャードキーの定義、各シャードのインフラストラクチャの作成、クエリをルーティングするロジックの記述を担当します。これにより、データの保存場所をきめ細かく制御できます。しかし、その分、メンテナンスの負担は大きくなります。特定のシャードが大きくなりすぎた場合は、手動でデータを「再シャーディング」する必要があります。これには、アプリケーションのダウンタイムを最小限に抑えながら、数百万行のデータを新しいサーバーへ移動させる作業が伴います。
- 自動シャーディング: 自動シャーディングは、Bigtable などの NoSQL データベースや Spanner などの分散 SQL データベースで一般的に採用され、データとトラフィックの分散を自動的に処理します。システムは、各サーバーのデータサイズと負荷をモニタリングします。特定のシャードが「ホットスポット」になったり、大きくなりすぎたりすると、データベース エンジンが自動的にシャードを分割し、より負荷の少ないサーバーにデータを移動します。これにより、チームの運用負担が軽減され、アプリケーションのスケーリングに伴って一貫したパフォーマンスを維持しやすくなります。
パーティショニング
パーティショニングとは、大きなテーブルをより管理しやすい小さな単位に分割すること(ログテーブルを月ごとに分割するなど)ですが、分割したものは同じサーバー インスタンス上に保持されます。これにより、テーブルの他の部分に影響を与えることなく、古いデータをアーカイブまたは削除しやすくなるため、ストレージの問題を解決できます。ただし、サーバー自体の問題を解決するものではありません。すべてのパーティションが依然として単一のマシン上に存在するため、同じ CPU と RAM を共有し続けます。そのため、サーバーがパフォーマンスの上限に達した場合、パーティショニングでは対処できません。
レプリケーション
レプリケーションとは、データベース全体を複数のサーバーにコピーするプロセスです。これは読み取りの可用性を高めるには有効な手法で、あるサーバーが故障しても、別のサーバーが処理を引き継ぐことができます。ただし、書き込まれたすべてのデータがすべてのレプリカにコピーされる必要があり、書き込み速度は単一のマシンの容量に制限されるため、書き込みスケーリングには効果が見込めません。
さらに重要な点として、ほとんどのレプリケーション モデルでは、一度に許可される「ライター」(プライマリ ノード)は 1 つだけです。複数のサーバーが同時に書き込みを許可しようとすると、2 つのサーバーが同じレコードを異なる情報で更新しようとする書き込み競合が発生するリスクがあります。これらの競合を解決することは技術的に難しく、高度な分散システムで処理されない場合、データ損失や不整合につながる可能性があります。
分散データベース
Spanner などの分散データベースを利用すると、手作業による負荷を伴わずにシャーディングのメリットが得られます。これらのシステムは、最初から複数のマシンで構成されるクラスター上で動作するように設計されています。データ分散、リバランス、レプリケーションを透過的に自動処理します。これらの中には、複数のライター(書き込みノード)を持ち、書き込みの競合を自動的に処理するシステムもあります。これにより、従来のリレーショナル データベースの一貫性を維持しながら、水平スケーリングを実現できます。
以下の表を参照して、これらの基本となるデータベースのコンセプトの違いを確認してください。
機能 | シャーディング | パーティショニング | レプリケーション | 分散データベース |
最終目標 | 大規模な書き込みのスケーリングとストレージ | 管理性とメンテナンス | 高可用性と読み取りのスケーリング | グローバル スケーリングの自動化 |
データのロケーション | 異なるサーバー上の異なるデータチャンク | 同一サーバー上の異なるデータチャンク | 複数のサーバー上にある同一データのコピー | クラスタ全体で管理 |
書き込みパフォーマンス | 大幅な改善(書き込みを並列で実行) | 小規模な改善(より小さいインデックス) | 改善なし(書き込みはすべてのコピーに反映される必要がある) | 大幅な改善 |
複雑さ | 高 | 中 | 低 | 低(マネージド) |
機能
シャーディング
パーティショニング
レプリケーション
分散データベース
最終目標
大規模な書き込みのスケーリングとストレージ
管理性とメンテナンス
高可用性と読み取りのスケーリング
グローバル スケーリングの自動化
データのロケーション
異なるサーバー上の異なるデータチャンク
同一サーバー上の異なるデータチャンク
複数のサーバー上にある同一データのコピー
クラスタ全体で管理
書き込みパフォーマンス
大幅な改善(書き込みを並列で実行)
小規模な改善(より小さいインデックス)
改善なし(書き込みはすべてのコピーに反映される必要がある)
大幅な改善
複雑さ
高
中
低
低(マネージド)
データベース シャーディングのメリット
テラバイト単位のデータや 1 秒あたり数百万件のトランザクションを処理するアプリケーションでは、シャーディングが唯一の実行可能なソリューションとなることがよくあります。
水平方向のスケーリング
水平方向のスケーリング
シャーディングでは、標準サーバーをクラスタに追加することで、ほぼ無限のスケーリングが可能になります。これにより、従来の垂直スケーリング アプリケーションでは必要となる「ハードウェア コスト」を回避できます。シャーディングを使用しなければ、多くの場合、性能に限界のある高価な専用ハードウェアを購入せざるを得なくなります。シャーディングにより、より手頃な価格の汎用マシンを使用して、ビジネスの成長に合わせてデータベースを拡張できるようになります。
クエリ パフォーマンスの向上
クエリ パフォーマンスの向上
シャーディングでは、各サーバーはより小さなデータセットを検索するため、個々のクエリが高速化されます。クエリは、1 億行のインデックスを検索する代わりに、100 万行のシャードを検索するだけで済む場合もあります。さらに、データは複数の異なるマシンに保存されているため、複数のクエリを並行して実行でき、アプリケーションの合計スループットが大幅に向上します。
信頼性
信頼性
シャーディングにより、障害の「影響範囲」が制限されます。1 つのシャードで障害が発生した場合、影響を受けるのはそのシャードのユーザーだけであり、アプリの他の部分はオンライン状態を維持します。しかし、サーバー数が増えるほど管理の負担は大きくなります。数十のインスタンスにわたってバックアップ、セキュリティ、パッチを管理する場合、単一サーバーからなるセットアップと比較して運用はより複雑になります。
シャーディングの課題
シャーディングは大規模なスケーリング要件を解決する手法ですが、技術面と運用面で大きなトレードオフを伴います。単一インスタンス アーキテクチャから移行する前に、これらの課題について検討しておく必要があります。
- データ ホットスポット: ハッシュ関数を使用しても、トラフィックが均等に分散されていないと「ホットスポット」が発生する可能性があります。この場合、少数の非常にアクティブなユーザーによって特定のサーバーが過負荷状態に陥る一方で、他のシャードは低負荷のままです。
- パフォーマンスの低下: シャードキーを使用しないクエリでは、システムがすべてのサーバーに対して「スキャッター ギャザー」処理を行う必要があります。同様に、クロスシャード結合では、アプリケーションが複数の物理的な場所からデータを pull してマージする必要があるため、コンピューティングの負荷が高くなります。
- 運用の複雑さ: シャード環境の管理が必要なため、日常業務がより難しくなります。スキーマの更新、バックアップ、ポイントインタイム リカバリについては、複数の独立したインスタンス間で調整する必要があります。
- トランザクションの整合性: 多くのシャーディング アーキテクチャでは、異なるシャード間で ACID トランザクションをサポートすることが厳しい現状です。そのため、デベロッパーは多くの場合、複雑な「部分的な障害」シナリオを管理するか、結果整合性モデルに依存することを余儀なくされます。
Google Cloud を活用してデータベース シャーディングを実現するには
Google Cloud は、負担の大きい手動シャーディングを不要にするデータベース ソリューションを提供しています。これにより、インフラストラクチャの管理ではなくアプリケーションの構築に集中できるようになります。
 Spannerこれはシャーディングが不要な、グローバルに分散されたフルマネージド データベースです。データを自動的にシャーディングし、リージョン間で負荷を分散します。マルチモデル データベースとして、リレーショナル データ、Key-Value データ、グラフデータ(Spanner Graph 経由)を 1 つのインターフェースでサポートします。これにより、強整合性と SQL の使いやすさを維持しながら、水平スケーリングが可能になります。
Spannerこれはシャーディングが不要な、グローバルに分散されたフルマネージド データベースです。データを自動的にシャーディングし、リージョン間で負荷を分散します。マルチモデル データベースとして、リレーショナル データ、Key-Value データ、グラフデータ(Spanner Graph 経由)を 1 つのインターフェースでサポートします。これにより、強整合性と SQL の使いやすさを維持しながら、水平スケーリングが可能になります。 Cloud SQL および AlloyDB従来のリレーショナル データベース エンジンを使用する場合、Google Cloud は PostgreSQL、MySQL、SQL Server のマネージド インスタンスを提供しています。Cloud SQL と AlloyDB はどちらも、ネイティブ パーティショニングをサポートしており、単一のインスタンスで大規模なテーブルを管理できます。また、これらのインスタンスを使用してカスタム シャーディング アーキテクチャを構築し、複数のマシンにワークロードをスケーリングすることもできます。AlloyDB を使えば、要求の厳しいデータ処理でも高いパフォーマンスを得られます。
Cloud SQL および AlloyDB従来のリレーショナル データベース エンジンを使用する場合、Google Cloud は PostgreSQL、MySQL、SQL Server のマネージド インスタンスを提供しています。Cloud SQL と AlloyDB はどちらも、ネイティブ パーティショニングをサポートしており、単一のインスタンスで大規模なテーブルを管理できます。また、これらのインスタンスを使用してカスタム シャーディング アーキテクチャを構築し、複数のマシンにワークロードをスケーリングすることもできます。AlloyDB を使えば、要求の厳しいデータ処理でも高いパフォーマンスを得られます。- Bigtable大規模な NoSQL ワークロードには、Bigtable が最適です。これは「タブレット分割」(シャーディング)を自動的に処理し、ペタバイト単位のデータと毎秒数百万件のリクエストを管理して、パーソナライズや時系列データなどのユースケースに対応します。


















