Quando il sistema "Infrastructure as code" cresce oltre l'esempio "Hello World" senza pianificazione, il codice tende a diventare non strutturato. Le configurazioni non pianificate sono hardcoded. La manutenibilità diminuisce drasticamente.
Utilizza questo documento per strutturare le implementazioni in modo più efficiente e su larga scala.
Inoltre, applica la convenzione di denominazione e le best practice interne in tutti i team. Questo documento è destinato a un pubblico tecnicamente avanzato e presuppone una conoscenza di base di Python, Google Cloud dell'infrastruttura, di Deployment Manager e, in generale, dell'infrastruttura come codice.
Prima di iniziare
- Se vuoi utilizzare gli esempi di riga di comando in questa guida, installa lo strumento a riga di comando`gcloud`.
- Se vuoi utilizzare gli esempi di API in questa guida, configura l'accesso API.
Più ambienti con un'unica base di codice
Per le implementazioni di grandi dimensioni con più di una dozzina di risorse, le best practice standard richiedono l'utilizzo di una quantità significativa di proprietà esterne (parametri di configurazione), in modo da evitare di codificare stringhe e logica in modelli generici. Molte di queste proprietà sono parzialmente duplicate a causa di ambienti simili, ad esempio ambiente di sviluppo, test o produzione, e servizi simili. Ad esempio, tutti i servizi standard vengono eseguiti su uno stack LAMP simile. Seguire queste best practice comporta un ampio insieme di proprietà di configurazione con un elevato grado di duplicazione che può diventare difficile da gestire, aumentando così la possibilità di errori umani.
La tabella seguente è un esempio di codice che illustra le differenze tra una configurazione gerarchica e una singola configurazione per deployment. La tabella evidenzia una duplicazione comune nella configurazione singola. Utilizzando la configurazione gerarchica, la tabella mostra come spostare le sezioni ripetute a un livello superiore della gerarchia per evitare ripetizioni e ridurre le possibilità di errore umano.
| Modello | Configurazione gerarchica senza ridondanza | Configurazione singola con ridondanza |
|---|---|---|
|
|
N/D |
|
|
|
|
|
|
|
|
|
Per gestire meglio un codebase di grandi dimensioni, utilizza un layout gerarchico strutturato con una unione a cascata delle proprietà di configurazione. Per farlo, utilizzi più file per la configurazione, anziché uno solo. Inoltre, utilizzi funzioni di supporto e condividi parte del codice base con la tua organizzazione.
La strutturazione e la disposizione a cascata del codice in modo gerarchico offre diversi vantaggi:
- Se dividi la configurazione in più file, migliori la struttura e la leggibilità delle proprietà. Inoltre, eviti di duplicarli.
- Progetti l'unione gerarchica per applicare in cascata i valori in modo logico, creando file di configurazione di primo livello riutilizzabili in progetti o componenti.
- Definisci ogni proprietà una sola volta (a parte gli override), evitando la necessità di gestire gli spazi dei nomi nei nomi delle proprietà.
- I tuoi modelli non devono conoscere l'ambiente effettivo, perché la configurazione appropriata viene caricata in base alle variabili appropriate.
Strutturare gerarchicamente il codebase
Un deployment di Deployment Manager contiene una configurazione YAML o un file di schema, insieme a diversi file Python. Insieme, questi file formano la base di codice di un deployment. I file Python possono avere scopi diversi. Puoi utilizzare i file Python come modelli di deployment, come file di codice generali (classi helper) o come file di codice che archiviano le proprietà di configurazione.
Per strutturare la base di codice in modo gerarchico, utilizzi alcuni file Python come file di configurazione, anziché il file di configurazione standard. Questo approccio offre maggiore flessibilità rispetto al collegamento del deployment a un singolo file YAML.
Trattare l'infrastruttura come codice reale
Un principio importante per il codice pulito è Non ripeterti (DRY). Definisci tutto una sola volta. Questo approccio rende la base di codice più pulita, più facile da esaminare e convalidare e più facile da gestire. Quando una proprietà deve essere modificata in un solo posto, il rischio di errore umano diminuisce.
Per un codebase più leggero con file di configurazione più piccoli e duplicazione minima, utilizza queste linee guida per strutturare le configurazioni in modo da seguire il principio DRY.
Organizzazioni, reparti, ambienti e moduli
I principi fondamentali per strutturare il codebase in modo pulito e gerarchico sono l'utilizzo di organizzazioni, reparti, ambienti e moduli. Questi principi sono facoltativi ed estendibili. Per un diagramma della gerarchia della base di codice di esempio, che segue questi principi, vedi la gerarchia di configurazione.
Nel seguente diagramma, un modulo viene implementato in un ambiente. Il unione delle configurazioni seleziona i file di configurazione appropriati a ogni livello in base al contesto in cui vengono utilizzati. Inoltre, definisce automaticamente il sistema e il reparto.
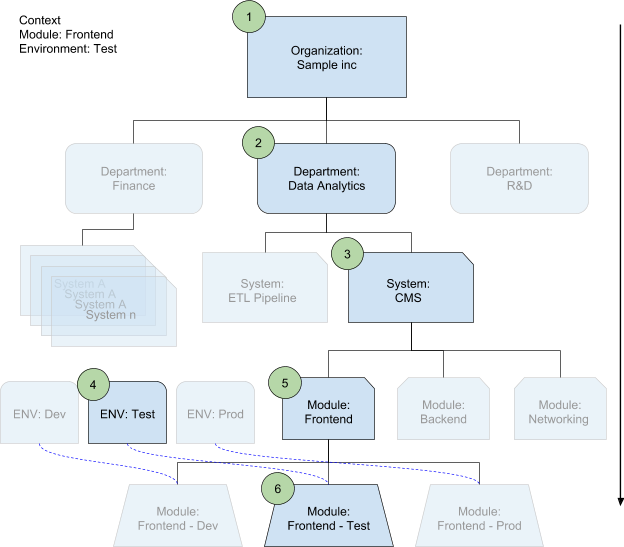
Nel seguente elenco, i numeri rappresentano l'ordine di sovrascrittura:
Proprietà organizzative
Questo è il livello più alto della tua struttura. A questo livello, puoi memorizzare proprietà di configurazione come
organization_name,organization_abbreviation, che utilizzi nella convenzione di denominazione, e funzioni di assistenza che vuoi condividere e applicare in tutti i team.Proprietà del reparto
Le organizzazioni contengono reparti, se ne hai nella tua struttura. Nel file di configurazione di ogni reparto, condividi le proprietà che non vengono utilizzate da altri reparti, ad esempio
department_nameocost_center.Proprietà di sistema (progetto)
Ogni reparto contiene sistemi. Un sistema è uno stack software ben definito, ad esempio la tua piattaforma di e-commerce. Non è un progettoGoogle Cloud , ma un ecosistema di servizi funzionante.
A livello di sistema, il tuo team ha molta più autonomia rispetto ai livelli superiori. Qui puoi definire funzioni di assistenza (ad esempio
project_name_generator(),instance_name_generator()oinstance_label_generator()) per i parametri a livello di team e di sistema (ad esempiosystem_name,default_instance_sizeonaming_prefix).Proprietà dell'ambiente
Il tuo sistema probabilmente ha più ambienti, come
Dev,TestoProd(e, facoltativamente,QAeStaging), che sono abbastanza simili tra loro. Idealmente, utilizzano lo stesso codebase e differiscono solo a livello di configurazione. A livello di ambiente, puoi sovrascrivere proprietà comedefault_instance_sizeper le configurazioniProdeQA.Proprietà dei moduli
Se il sistema è grande, dividilo in più moduli, anziché mantenerlo come un unico blocco monolitico di grandi dimensioni. Ad esempio, potresti spostare la rete e la sicurezza di base in blocchi separati. Puoi anche separare i livelli di backend, frontend e database in moduli separati. I moduli sono modelli sviluppati da terze parti, in cui aggiungi solo la configurazione appropriata. A livello di modulo, puoi definire proprietà pertinenti solo per moduli specifici, incluse quelle progettate per sovrascrivere le proprietà ereditate a livello di sistema. I livelli di ambiente e modulo sono divisioni parallele in un sistema, ma i moduli seguono gli ambienti nel processo di unione.
Proprietà dei moduli specifiche per l'ambiente
Alcune proprietà dei moduli potrebbero dipendere anche dall'ambiente, ad esempio dimensioni delle istanze, immagini, endpoint. Le proprietà del modulo specifiche per l'ambiente sono il livello più specifico e l'ultimo punto dell'unione a cascata per sovrascrivere i valori definiti in precedenza.
Classe helper per unire le configurazioni
La classe config_merger è una classe helper che carica automaticamente i file di configurazione appropriati e unisce i relativi contenuti in un unico dizionario.
Per utilizzare la classe config_merger, devi fornire le seguenti
informazioni:
- Il nome del modulo.
- Il contesto globale, che contiene il nome dell'ambiente.
La chiamata alla funzione statica ConfigContext restituisce il dizionario di configurazione unito.
Il seguente codice mostra come utilizzare questa classe:
module = "frontend"specifica il contesto in cui vengono caricati i file di proprietà.- L'ambiente viene selezionato automaticamente da
context.properties["envName"]. La configurazione globale.
cc = config_merger.ConfigContext(context.properties, module) print cc.configs['ServiceName']
Dietro le quinte, questa classe helper deve allinearsi alle strutture di configurazione, caricare tutti i livelli nell'ordine corretto e sovrascrivere i valori di configurazione appropriati. Per modificare i livelli o l'ordine di sovrascrittura, modifica la classe di unione della configurazione.
Nell'uso quotidiano e di routine, in genere non è necessario toccare questa classe. In genere, modifichi i modelli e i file di configurazione appropriati, quindi utilizzi il dizionario di output con tutte le configurazioni.
La base di codice di esempio contiene i seguenti tre file di configurazione hardcoded:
org_config.pydepartment_config.pysystem_config.py
Puoi creare i file di configurazione dell'organizzazione e del reparto come link simbolici durante l'inizializzazione del repository. Questi file possono risiedere in un repository di codice separato, poiché non fanno parte logicamente della codebase di un team di progetto, ma sono condivisi nell'intera organizzazione e nel reparto.
L'unione della configurazione cerca anche i file corrispondenti ai livelli rimanenti della struttura:
envs/[environment name].py[environment name]/[module name].pymodules/[module name].py
File di configurazione
Deployment Manager utilizza un file di configurazione, ovvero un singolo file per un deployment specifico. Non può essere condiviso tra le implementazioni.
Quando utilizzi la classe config-merger, le proprietà di configurazione sono
completamente separate da questo file di configurazione perché non lo utilizzi.
Utilizzi invece una raccolta di file Python, che ti offre molta più
flessibilità in un deployment. Questi file possono essere condivisi anche tra
le implementazioni.
Qualsiasi file Python può contenere variabili, il che ti consente di archiviare la configurazione in modo strutturato, ma distribuito. L'approccio migliore è utilizzare
dizionari con una struttura concordata. L'unione della configurazione cerca un
dizionario chiamato configs in ogni file della catena di unione. Questi elementi separati
configs vengono uniti in un unico elemento.
Durante l'unione, quando una proprietà con lo stesso percorso e nome viene visualizzata più volte nei dizionari, l'unione della configurazione sovrascrive la proprietà. In alcuni casi, questo comportamento è utile, ad esempio quando un valore predefinito viene sovrascritto da un valore specifico per il contesto. Tuttavia, ci sono molti altri casi in cui vuoi evitare di sovrascrivere la proprietà. Per evitare la sovrascrittura di una proprietà, aggiungi uno spazio dei nomi separato per renderla unica. Nell'esempio seguente aggiungi uno spazio dei nomi creando un livello aggiuntivo nel dizionario di configurazione, che crea un dizionario secondario.
config = {
'Zip_code': '1234'
'Count': '3'
'project_module': {
'admin': 'Joe',
}
}
config = {
'Zip_code': '5555'
'Count': '5'
'project_module_prod': {
'admin': 'Steve',
}
}
Classi helper e convenzioni di denominazione
Le convenzioni di denominazione sono il modo migliore per tenere sotto controllo l'infrastruttura di Deployment Manager. Non vuoi utilizzare nomi vaghi o generici,
come my project o test instance.
Il seguente esempio mostra una convenzione di denominazione a livello di organizzazione per le istanze:
def getInstanceName(self, name):
return '-'.join(self.configs['Org_level_configs']['Org_Short_Name'],
self.configs['Department_level_configs']['Department_Short_Name'],
self.configs['System_short_name'],
name,
self.configs["envName"])
Fornire una funzione helper semplifica l'assegnazione di un nome a ogni istanza in base alla convenzione concordata. Inoltre, semplifica la revisione del codice perché nessun nome di istanza proviene da un'altra fonte. La funzione seleziona automaticamente i nomi dalle configurazioni di livello superiore. Questo approccio consente di evitare input non necessari.
Puoi applicare queste convenzioni di denominazione alla maggior parte delle risorse Google Cloud e per le etichette. Le funzioni più complesse possono persino generare un insieme di etichette predefinite.
Struttura delle cartelle della base di codice di esempio
La struttura delle cartelle della base di codice di esempio è flessibile e personalizzabile. Tuttavia, è parzialmente codificato nel programma di unione della configurazione e nel file di schema di Deployment Manager, il che significa che se apporti una modifica, devi riflettere queste modifiche nel programma di unione della configurazione e nei file di schema.
├── global
│ ├── configs
│ └── helper
└── systems
└── my_ecom_system
├── configs
│ ├── dev
│ ├── envs
│ ├── modules
│ ├── prod
│ └── test
├── helper
└── templates
La cartella globale contiene file condivisi tra diversi team di progetto. Per semplicità, la cartella di configurazione contiene la configurazione dell'organizzazione e tutti i file di configurazione dei reparti. In questo esempio, non esiste una classe helper separata per i reparti. Puoi aggiungere qualsiasi classe helper a livello di organizzazione o sistema.
La cartella globale può trovarsi in un repository Git separato. Puoi fare riferimento ai suoi file dai singoli sistemi. Puoi anche utilizzare i link simbolici, ma potrebbero creare confusione o interruzioni in alcuni sistemi operativi.
├── configs
│ ├── Department_Data_config.py
│ ├── Department_Finance_config.py
│ ├── Department_RandD_config.py
│ └── org_config.py
└── helper
├── config_merger.py
└── naming_helper.py
La cartella dei sistemi contiene uno o più sistemi diversi. I sistemi sono separati l'uno dall'altro e non condividono configurazioni.
├── configs │ ├── dev │ ├── envs │ ├── modules │ ├── prod │ └── test ├── helper └── templates
La cartella di configurazione contiene tutti i file di configurazione univoci per questo sistema, facendo riferimento anche alle configurazioni globali tramite link simbolici.
├── department_config.py -> ../../../global/configs/Department_Data_config.py
├── org_config.py -> ../../../global/configs/org_config.py
├── system_config.py
├── dev
│ ├── frontend.py
│ └── project.py
├── prod
│ ├── frontend.py
│ └── project.py
├── test
│ ├── frontend.py
│ └── project.py
├── envs
│ ├── dev.py
│ ├── prod.py
│ └── test.py
└── modules
├── frontend.py
└── project.py
Org_config.py:
config = {
'Org_level_configs': {
'Org_Name': 'Sample Inc.',
'Org_Short_Name': 'sampl',
'HQ_Address': {
'City': 'London',
'Country': 'UK'
}
}
}
Nella cartella helper, puoi aggiungere altre classi helper e fare riferimento alle classi globali.
├── config_merger.py -> ../../../global/helper/config_merger.py └── naming_helper.py -> ../../../global/helper/naming_helper.py
Nella cartella dei modelli puoi archiviare o fare riferimento ai modelli di Deployment Manager. Anche i link simbolici funzionano.
├── project_creation -> ../../../../../../examples/v2/project_creation └── simple_frontend.py
Best practice
Le seguenti best practice possono aiutarti a strutturare il codice in modo gerarchico.
File di schema
Nel file dello schema, è un requisito di Deployment Manager elencare ogni file che utilizzi in qualsiasi modo durante il deployment. L'aggiunta di un'intera cartella rende il codice più breve e generico.
- Classi helper:
- path: helper/*.py
- File di configurazione:
- path: configs/*.py - path: configs/*/*.py
- Importazioni collettive (stile globo)
gcloud config set deployment_manager/glob_imports True
Deployment multipli
Una best practice per un sistema è quella di contenere più deployment, il che significa che utilizzano gli stessi set di configurazioni, anche se si tratta di moduli diversi, ad esempio networking, firewall, backend, frontend. Potresti dover accedere all'output di questi deployment da un altro deployment. Puoi eseguire query sull'output del deployment dopo che è pronto e salvarlo nella cartella delle configurazioni. Puoi aggiungere questi file di configurazione durante il processo di unione.
Link simbolici
I link simbolici sono supportati dai comandi gcloud deployment-manager e
i file collegati vengono caricati correttamente. Tuttavia, i link simbolici non sono supportati in
tutti i sistemi operativi.
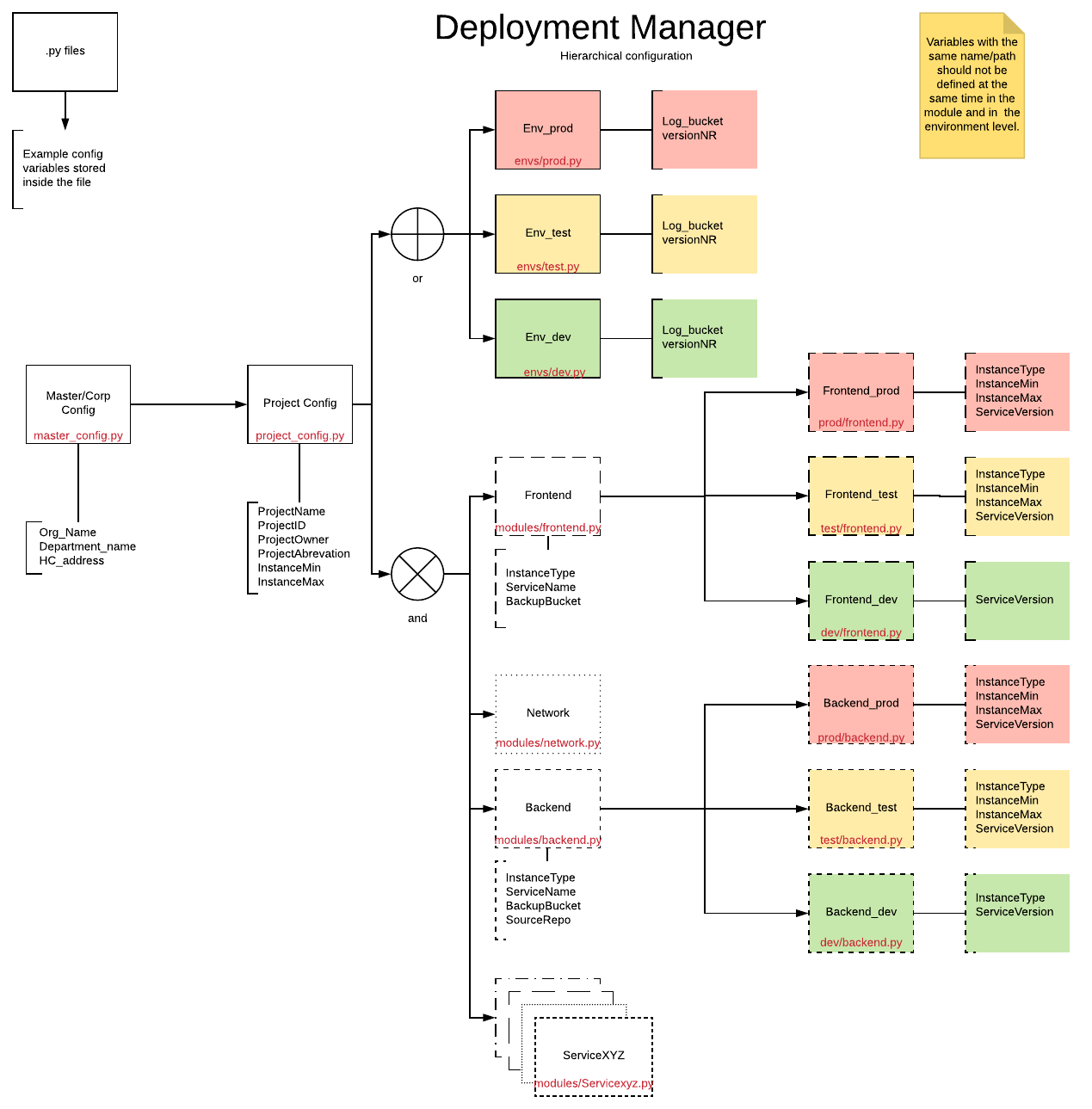
Gerarchia di configurazione
Il seguente diagramma mostra una panoramica dei diversi livelli e delle loro relazioni. Ogni rettangolo rappresenta un file di proprietà, come indicato dal nome file in rosso.
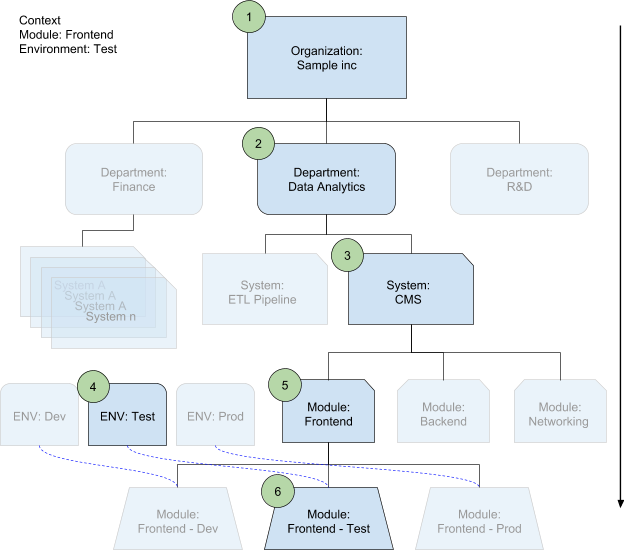
Ordine di unione sensibile al contesto
L'unione delle configurazioni seleziona i file di configurazione appropriati per ogni livello in base al contesto in cui viene utilizzato ogni file. Il contesto è un modulo che stai eseguendo il deployment in un ambiente. Questo contesto definisce automaticamente il sistema e il reparto.
Nel seguente diagramma, i numeri rappresentano l'ordine di sovrascrittura nella gerarchia:
Passaggi successivi
- Per altri esempi di deployment, consulta il repository GitHub di Deployment Manager.
- Scopri di più su modelli e deployment.