
Managed Service pour Apache Spark (anciennement Dataproc)
La nouvelle façon d'utiliser Spark plus facilement, plus intelligemment et plus rapidement
Exécutez des charges de travail Apache Spark avec des clusters Spark sans serveur et sans opération, ou des clusters gérés. Accélérez le développement avec des workflows d'IA agentique et améliorez les performances avec Lightning Engine.
Les nouveaux clients bénéficient de 300 $ de crédits pour essayer Managed Service for Apache Spark et d'autres produits Google Cloud.
Apache Spark est une marque de l'Apache Software Foundation.

Fonctionnalités
Des performances de pointe avec Lightning Engine
Exécutez les charges de travail ETL et SQL à grande échelle jusqu'à 4,9 fois plus rapidement qu'avec Apache Spark Open Source, sans modifier le code. Lightning Engine utilise un moteur d'exécution vectorisé C++ natif, la mise en cache intelligente et le brassage en colonnes optimisé. Associez ces fonctionnalités au réglage automatique intelligent de Spark pour éliminer les frais liés au réglage manuel, optimiser la mémoire et éviter automatiquement les erreurs de saturation de la mémoire.
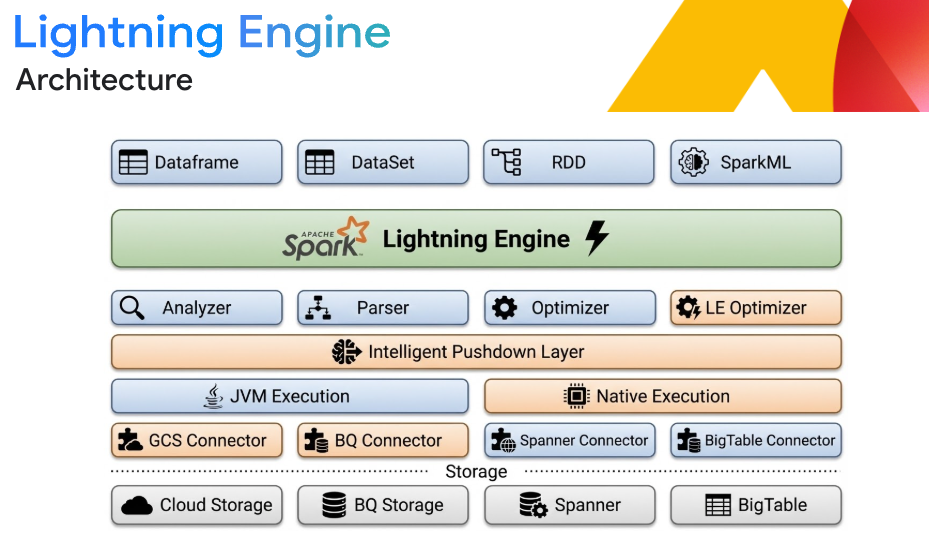
Interopérabilité flexible des lakehouses
Créez une architecture de lakehouse ouverte qui garantit l'indépendance des moteurs. Traitez les données dans des formats ouverts comme Apache Iceberg directement depuis Google Cloud Storage. Intégrez-la de manière fluide à BigQuery et à Knowledge Catalog (anciennement Dataplex) pour bénéficier d'une analyse et d'une gouvernance unifiées, garantissant une véritable interopérabilité multimoteur sans couches de traduction.
Expérience de développement unifiée et optimisée par l'IA
Traitez vos tâches en attente grâce à des agents de données qui agissent, et ne se contentent pas de répondre à des questions. Accélérez votre workflow à l'aide de Gemini intégré à l'extension agentique VSCode pour améliorer la productivité des charges de travail Spark, du développement à la production, ou utilisez l'IDE de votre choix. Utilisez les agents d'ingénierie des données et de science des données pour automatiser le data wrangling, créer des pipelines à partir du langage naturel et générer du code PySpark. Résolvez automatiquement les problèmes des jobs Spark ayant échoué avec Gemini Cloud Assist. Combinez SQL et Spark dans un seul notebook unifié axé sur l'IA.
Prêt pour l'IA et le ML d'entreprise
Créez et opérationnalisez l'ensemble de votre cycle de vie de machine learning. Accélérez l'entraînement et l'inférence de modèles grâce à la prise en charge des GPU optimisée par NVIDIA RAPIDS et les environnements d'exécution de ML préconfigurés pour PyTorch et XGBoost. Intégrez l'écosystème Google Cloud AI pour orchestrer des MLOps de bout en bout et gérer les éléments avec l'intégration de Model Registry dans Gemini Enterprise Agent Platform.
Migrations sécurisées, évolutives et fluides
Intégrez parfaitement le service à votre stratégie de sécurité à l'aide d'IAM, de VPC Service Controls et de Kerberos. Migrez facilement les charges de travail Spark cloud et anciennes à l'aide des modèles et des outils Managed Service pour Apache Spark. Effectuez une migration Lift and Shift des charges de travail avec une compatibilité allant de Spark 2.x à Spark 4.0 sans refactorisation immédiate du code.
Efficacité mutualisée et contrôles FinOps
Optimisez l'utilisation des ressources et réduisez les coûts d'inactivité. Déployez des clusters Spark mutualisés qui permettent à 800 utilisateurs au maximum de partager des ressources de calcul, tout en maintenant une isolation stricte des données et de l'environnement. Contrôlez votre facture grâce aux capacités de scaling à zéro instance, à la facturation à la seconde et à la compatibilité des VM Spot avec les charges de travail flexibles.
Écosystème ouvert et flexible
Évitez la dépendance vis-à-vis d'un fournisseur. Bien qu'optimisés pour Apache Spark, nos clusters gérés sont compatibles avec plus de 30 outils Open Source tels qu'Apache Hadoop, Flink et Trino. Intégrez-les facilement à des outils d'orchestration tels que Managed Service pour Apache Airflow et améliorez-les avec Kubernetes et Docker pour une flexibilité maximale.
Options de déploiement
| Options de déploiement | Choisissez entre le contrôle précis des clusters gérés ou la simplicité sans opérations d'une expérience sans serveur pour trouver la meilleure option pour votre charge de travail. | ||
|---|---|---|---|
| Mode de déploiement : | Description : | Adaptés pour : | Ce que vous payez : |
Sans serveur | Jobs Spark en tant que service. Spark géré, infrastructure gérée. | Nouveaux pipelines, analyses interactives et charges de travail irrégulières pour lesquelles un modèle sans opération et basé sur le paiement au job est préférable. | Durée d'exécution du job |
Clusters | Clusters Spark en tant que service Spark géré, votre infrastructure | Migrer des charges de travail Spark ou OSS existantes, exécuter des clusters persistants ou demander une personnalisation Open Source poussée | Temps d'activité du cluster |
Options de déploiement
Choisissez entre le contrôle précis des clusters gérés ou la simplicité sans opérations d'une expérience sans serveur pour trouver la meilleure option pour votre charge de travail.
Sans serveur
Jobs Spark en tant que service.
Spark géré, infrastructure gérée.
Nouveaux pipelines, analyses interactives et charges de travail irrégulières pour lesquelles un modèle sans opération et basé sur le paiement au job est préférable.
Durée d'exécution du job
Clusters
Clusters Spark en tant que service
Spark géré, votre infrastructure
Migrer des charges de travail Spark ou OSS existantes, exécuter des clusters persistants ou demander une personnalisation Open Source poussée
Temps d'activité du cluster
Fonctionnement
Simplifiez Spark avec des clusters sans serveur et sans opération, ou gérés. Travaillez plus efficacement avec Gemini dans l'IDE de votre choix, en utilisant l'IA agentique pour accélérer le développement PySpark. Exécutez des jobs plus rapidement avec Lightning Engine, tout en maintenant une gouvernance unifiée sur votre lakehouse Open Source avec Knowledge Catalog.
Simplifiez Spark avec des clusters sans serveur et sans opération, ou gérés. Travaillez plus efficacement avec Gemini dans l'IDE de votre choix, en utilisant l'IA agentique pour accélérer le développement PySpark. Exécutez des jobs plus rapidement avec Lightning Engine, tout en maintenant une gouvernance unifiée sur votre lakehouse Open Source avec Knowledge Catalog.
Ingénierie des données à grande échelle
Pipelines ETL automatisés
Pipelines ETL automatisés
Créez des pipelines ETL Spark robustes basés sur des événements qui s'adaptent automatiquement à la demande. Exploitez l'exécution sans serveur pour les charges de travail irrégulières ou les clusters gérés pour les jobs persistants. Utilisez des modèles de workflow pour automatiser de bout en bout vos jobs de traitement de données en production les plus critiques.
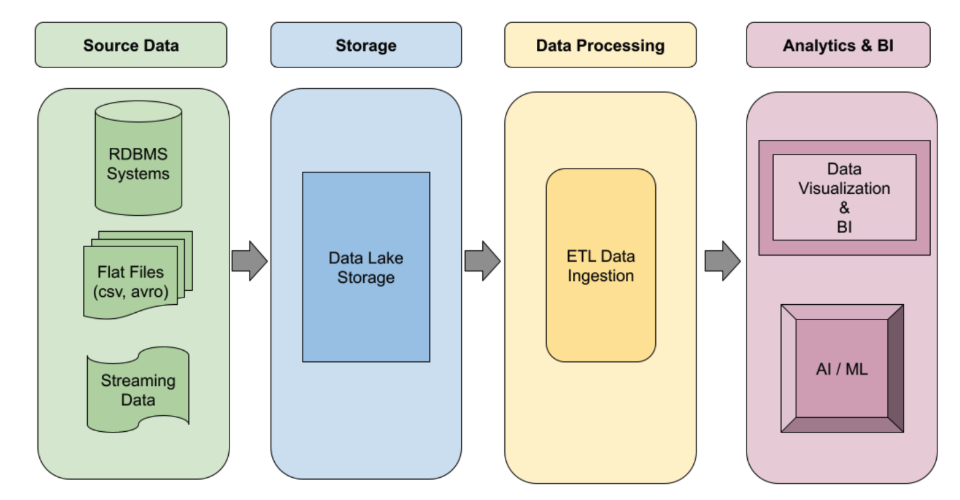


Tutoriels, guides de démarrage rapide et ateliers
Pipelines ETL automatisés
Pipelines ETL automatisés
Créez des pipelines ETL Spark robustes basés sur des événements qui s'adaptent automatiquement à la demande. Exploitez l'exécution sans serveur pour les charges de travail irrégulières ou les clusters gérés pour les jobs persistants. Utilisez des modèles de workflow pour automatiser de bout en bout vos jobs de traitement de données en production les plus critiques.
Data science et machine learning
Data science interactive
Data science interactive
Permettez aux data scientists d'explorer les données et d'itérer les modèles Spark ML. Unifiez SQL et Spark à l'aide de Gemini avec l'extension agentique VSCode ou l'IDE de votre choix, en passant facilement de l'exploration de données à la création de modèles avec PySpark à l'aide de l'exécution sans serveur. Associez des GPU à l'aide d'une seule commande.
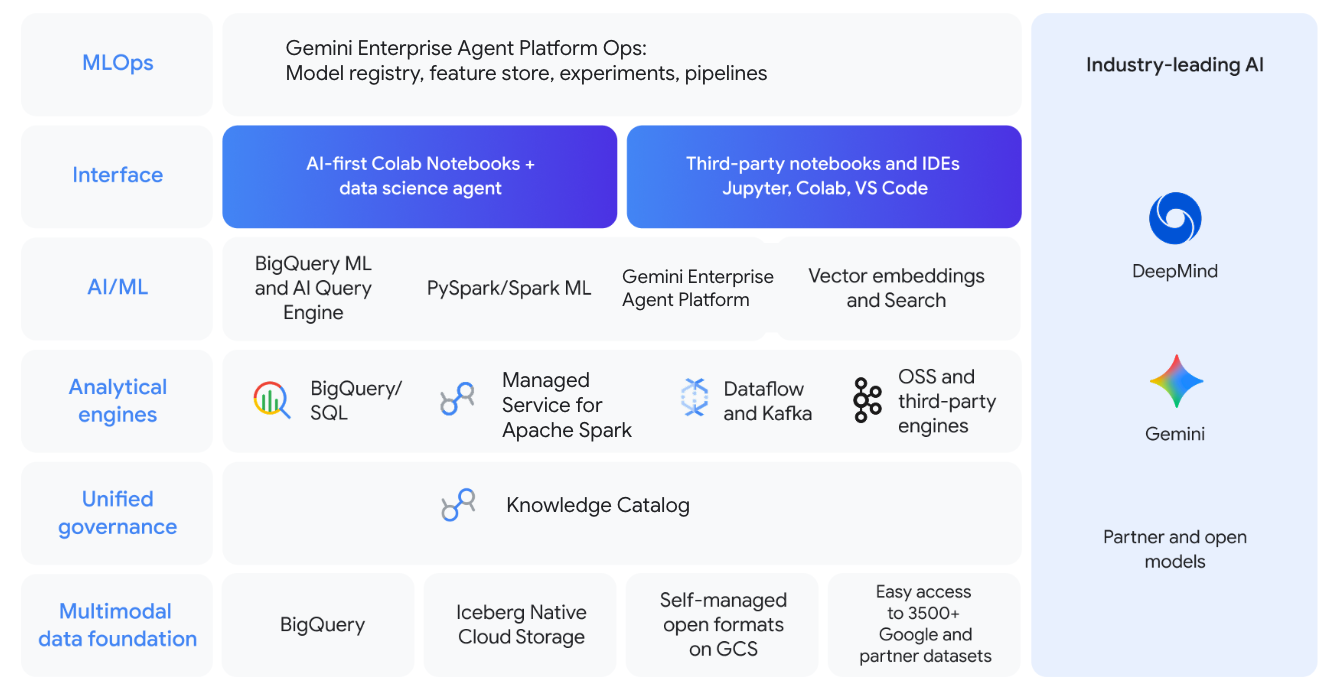


Tutoriels, guides de démarrage rapide et ateliers
Data science interactive
Data science interactive
Permettez aux data scientists d'explorer les données et d'itérer les modèles Spark ML. Unifiez SQL et Spark à l'aide de Gemini avec l'extension agentique VSCode ou l'IDE de votre choix, en passant facilement de l'exploration de données à la création de modèles avec PySpark à l'aide de l'exécution sans serveur. Associez des GPU à l'aide d'une seule commande.
Modernisation du lakehouse
Data lakehouse Open Source
Data lakehouse Open Source
Utilisez Managed Service pour Apache Spark comme moteur de traitement pour votre data lakehouse moderne. Traitez les données dans des formats ouverts comme Apache Iceberg directement depuis votre lac de données afin d'éliminer les silos de données. Intégrez-le à BigQuery et à Lakehouse pour Apache Iceberg pour bénéficier d'une plate-forme d'analyse unifiée et multimoteur.
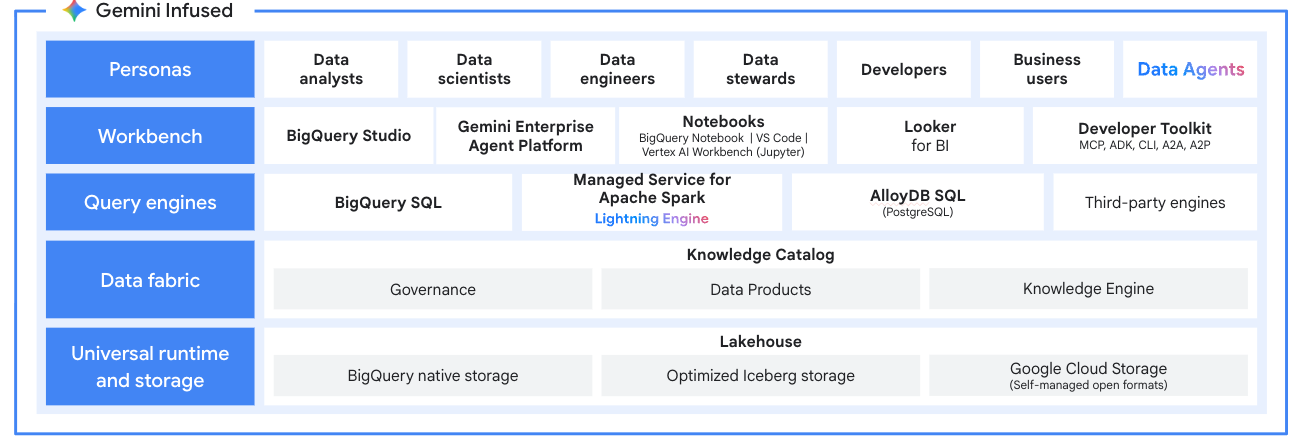

Tutoriels, guides de démarrage rapide et ateliers
Data lakehouse Open Source
Data lakehouse Open Source
Utilisez Managed Service pour Apache Spark comme moteur de traitement pour votre data lakehouse moderne. Traitez les données dans des formats ouverts comme Apache Iceberg directement depuis votre lac de données afin d'éliminer les silos de données. Intégrez-le à BigQuery et à Lakehouse pour Apache Iceberg pour bénéficier d'une plate-forme d'analyse unifiée et multimoteur.
Tarification
| Fonctionnement de la tarification de Managed Service pour Apache Spark | Les tarifs dépendent du modèle de déploiement choisi. Le modèle sans serveur est facturé par exécution de job, tandis que les clusters sont facturés en fonction du temps d'activité et des ressources de calcul sous-jacentes. | |
|---|---|---|
| Mode de déploiement : | Ce que vous payez : | Ce que vous payez : |
Sans serveur | Seules les ressources que vous utilisez vous sont facturées. Facturation à la seconde pour le calcul, les GPU et l'espace de stockage aléatoire. Le scaling à zéro instance vous garantit de ne jamais payer pour une capacité inactive. | À partir de 0,06 $ par heure d'unités de calcul de données |
Niveau Premium et accélérateurs : Accédez à Lightning Engine pour des performances jusqu'à 4,9 fois plus rapides ou associez des GPU NVIDIA pour les charges de travail d'IA/de ML. | À partir de 0,089 $ par heure d'unités de calcul de données Niveau Premium sans serveur | |
Clusters | Facturation basée sur la disponibilité du cluster. Facturation des ressources Compute Engine sous-jacentes et frais de gestion fixes. Exploitez les VM Spot et le scaling à zéro instance pour optimiser les coûts. | À partir de 0,01 $ par vCPU-heure Frais de gestion |
Module complémentaire Lightning Engine : Offrez des performances révolutionnaires à vos clusters. Bénéficiez d'une exécution jusqu'à 4,9 fois plus rapide qu'avec Spark Open Source. | À partir de 0,0025 $ par vCPU-heure | |
Découvrez plus d'informations sur la tarification de Managed Service pour Apache Spark. Afficher le détail des tarifs
Fonctionnement de la tarification de Managed Service pour Apache Spark
Les tarifs dépendent du modèle de déploiement choisi. Le modèle sans serveur est facturé par exécution de job, tandis que les clusters sont facturés en fonction du temps d'activité et des ressources de calcul sous-jacentes.
Sans serveur
Seules les ressources que vous utilisez vous sont facturées. Facturation à la seconde pour le calcul, les GPU et l'espace de stockage aléatoire. Le scaling à zéro instance vous garantit de ne jamais payer pour une capacité inactive.
Starting at
0,06 $ par heure d'unités de calcul de données
Niveau Premium et accélérateurs :
Accédez à Lightning Engine pour des performances jusqu'à 4,9 fois plus rapides ou associez des GPU NVIDIA pour les charges de travail d'IA/de ML.
Starting at
0,089 $ par heure d'unités de calcul de données
Niveau Premium sans serveur
Clusters
Facturation basée sur la disponibilité du cluster. Facturation des ressources Compute Engine sous-jacentes et frais de gestion fixes. Exploitez les VM Spot et le scaling à zéro instance pour optimiser les coûts.
Starting at
0,01 $ par vCPU-heure
Frais de gestion
Module complémentaire Lightning Engine :
Offrez des performances révolutionnaires à vos clusters. Bénéficiez d'une exécution jusqu'à 4,9 fois plus rapide qu'avec Spark Open Source.
Starting at
0,0025 $ par vCPU-heure
Découvrez plus d'informations sur la tarification de Managed Service pour Apache Spark. Afficher le détail des tarifs
Cas d'utilisation métier
Témoignages de clients

"Certains de nos contrôles qualité qui prenaient 11 heures ne prennent plus que quelques minutes."
Michael Manos, directeur technique chez Dun & Bradstreet
La migration vers Google Cloud a permis à Dun & Bradstreet d'accélérer considérablement les flux de données, de réduire les processus de contrôle qualité de plusieurs heures à quelques minutes et de diviser par deux le temps nécessaire à la publication de nouvelles données. Cette base de données solide permet également à Dun & Bradstreet d'exploiter tout le potentiel de l'écosystème Google Cloud, y compris les technologies de pointe liées aux données et à l'IA.



La différence de Managed Service pour Apache Spark
Productivité zéro opération avec des options de déploiement flexibles. Choisissez l'exécution sans serveur ou des clusters entièrement gérés pour éliminer les frais d'infrastructure et les coûts liés au réglage manuel.
Développement de l'IA agentique. Accélérez votre workflow avec Gemini intégré à l'extension agentique VSCode ou à l'IDE de votre choix, ainsi qu'avec des agents de données qui automatisent le codage PySpark, le data wrangling et le dépannage des jobs dans un notebook unifié.
Des performances de pointe optimisées par Lightning Engine. Accélérez vos charges de travail ETL et de data science les plus exigeantes jusqu'à 4,9 fois et réduisez considérablement votre coût total de possession.










Autres ressources :
Questions fréquentes
Qu'est-il advenu de Dataproc et de Spark sans serveur ?
Pour simplifier votre expérience, nous avons unifié Dataproc et Google Cloud Serverless pour Apache Spark en un seul produit : Managed Service pour Apache Spark. Vous bénéficiez des mêmes fonctionnalités puissantes, mais vous pouvez désormais choisir votre modèle de déploiement préféré (sans serveur et sans opération, ou clusters entièrement gérés) à partir d'une interface unique et unifiée. Comparer les deux modes de déploiement plus en détail
Quand dois-je choisir des clusters sans serveur plutôt que des clusters gérés ?
Choisissez l'option sans serveur si vous souhaitez vous concentrer uniquement sur le code, sans avoir à gérer l'infrastructure. C'est l'idéal pour les nouveaux pipelines et les analyses ad hoc. Privilégiez les clusters gérés si vous avez besoin d'un contrôle précis, si vous migrez des charges de travail Spark existantes ou cloud ou d'autres charges de travail OSS, ou si vous avez besoin de clusters persistants intégrant différents outils Open Source.
Qu'est-ce que Lightning Engine ?
Lightning Engine est le moteur d'exécution natif et hautement optimisé de Google Cloud. Conçu avec des bibliothèques C++, il optimise chaque couche, des connecteurs de stockage à haut débit à la mise en cache intelligente. Il offre des performances jusqu'à 4,9 fois supérieures à celles de Spark standard et un rapport prix/performances deux fois supérieur à celui de la principale alternative Spark haute vitesse. Il s'intègre parfaitement à vos déploiements sans serveur ou en cluster, sans aucune modification de code.
Dois-je installer mes propres bibliothèques de ML comme PyTorch ?
Non. Si vous exécutez des charges de travail d'IA/de ML, vous pouvez utiliser nos environnements d'exécution de ML préconfigurés. Ces environnements intègrent des bibliothèques courantes telles que PyTorch, XGBoost et scikit-learn, ainsi que des pilotes de GPU NVIDIA optimisés, vous libérant ainsi de toute la complexité liée à la configuration.
Managed Service pour Apache Spark est-il entièrement compatible avec l'Open Source ?
Oui. Nous fournissons un environnement Apache Spark 100 % compatible avec l'Open Source. Vous pouvez exécuter votre code Spark existant sans le modifier, ce qui garantit une portabilité complète des charges de travail et évite la dépendance vis-à-vis d'un fournisseur.
Comment l'IA Gemini aide-t-elle au développement Spark ?
L'IA Gemini peut être intégrée directement à l'IDE de votre choix pour vous servir de copilote. Elle vous aide à écrire et à déboguer du code PySpark plus rapidement, tandis que Gemini Cloud Assist fournit une analyse automatisée des causes fondamentales et des recommandations de dépannage pour les jobs ayant échoué.
Puis-je utiliser ce service pour créer un data lakehouse ouvert ?
Absolument. Managed Service pour Apache Spark est un moteur de traitement essentiel pour le lakehouse ouvert de Google Cloud. Il vous permet de traiter des données dans des formats ouverts comme Apache Iceberg directement depuis Cloud Storage, et s'intègre parfaitement à BigQuery et Knowledge Catalog pour Apache Iceberg.
Comment fonctionnent les niveaux de tarification Standard et Premium ?
Les niveaux Standard et Premium ne s'appliquent actuellement qu'aux déploiements sans serveur. Le niveau Standard est idéal pour le traitement par lot et l'ETL à usage général et économique. Le niveau Premium est conçu pour vos charges de travail les plus exigeantes. Il offre des performances 4,9 fois supérieures à celles d'Apache Spark Open Source avec Lightning Engine et permet d'accéder aux fonctionnalités d'IA/de ML accélérées par GPU.


















