Trino (anciennement Presto) est un moteur de requêtes SQL distribué conçu pour interroger des ensembles de données volumineux répartis entre une ou plusieurs sources de données hétérogènes. Trino peut interroger Hive, Kafka, MySQL et d'autres sources de données par le biais de connecteurs. Ce tutoriel vous explique comment :
- installer le service Trino sur un cluster Dataproc ;
- interroger les données publiques d'un client Trino installé sur votre machine locale qui communique avec un service Trino sur votre cluster ;
- exécuter des requêtes à partir d'une application Java qui communique avec le service Trino sur votre cluster par le biais du pilote Java JDBC de Trino.
Objectifs
- Extrayez les données de BigQuery.
- Chargez les données dans Cloud Storage sous forme de fichiers CSV.
- Transformez les données :
- Présentez les données sous forme d'une table externe Hive pour rendre les données interrogeables par Trino.
- Convertissez les données du format CSV au format Parquet pour accélérer les requêtes.
Coûts
Dans ce document, vous utilisez les composants facturables de Google Cloudsuivants :
Vous pouvez obtenir une estimation des coûts en fonction de votre utilisation prévue à l'aide du simulateur de coût.
Avant de commencer
Si vous ne l'avez pas déjà fait, créez un projet Google Cloud et un bucket Cloud Storage pour stocker les données utilisées dans ce tutoriel. 1. Configurer le projet- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Dataproc, Compute Engine, Cloud Storage, and BigQuery APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Install the Google Cloud CLI.
-
Si vous utilisez un fournisseur d'identité (IdP) externe, vous devez d'abord vous connecter à la gcloud CLI avec votre identité fédérée.
-
Pour initialiser la gcloud CLI, exécutez la commande suivante :
gcloud init -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Dataproc, Compute Engine, Cloud Storage, and BigQuery APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Install the Google Cloud CLI.
-
Si vous utilisez un fournisseur d'identité (IdP) externe, vous devez d'abord vous connecter à la gcloud CLI avec votre identité fédérée.
-
Pour initialiser la gcloud CLI, exécutez la commande suivante :
gcloud init - In the Google Cloud console, go to the Cloud Storage Buckets page.
- Click Create.
- On the Create a bucket page, enter your bucket information. To go to the next
step, click Continue.
-
In the Get started section, do the following:
- Enter a globally unique name that meets the bucket naming requirements.
- To add a
bucket label,
expand the Labels section (),
click add_box
Add label, and specify a
keyand avaluefor your label.
-
In the Choose where to store your data section, do the following:
- Select a Location type.
- Choose a location where your bucket's data is permanently stored from the Location type drop-down menu.
- If you select the dual-region location type, you can also choose to enable turbo replication by using the relevant checkbox.
- To set up cross-bucket replication, select
Add cross-bucket replication via Storage Transfer Service and
follow these steps:
Set up cross-bucket replication
- In the Bucket menu, select a bucket.
In the Replication settings section, click Configure to configure settings for the replication job.
The Configure cross-bucket replication pane appears.
- To filter objects to replicate by object name prefix, enter a prefix that you want to include or exclude objects from, then click Add a prefix.
- To set a storage class for the replicated objects, select a storage class from the Storage class menu. If you skip this step, the replicated objects will use the destination bucket's storage class by default.
- Click Done.
-
In the Choose how to store your data section, do the following:
- Select a default storage class for the bucket or Autoclass for automatic storage class management of your bucket's data.
- To enable hierarchical namespace, in the Optimize storage for data-intensive workloads section, select Enable hierarchical namespace on this bucket.
- In the Choose how to control access to objects section, select whether or not your bucket enforces public access prevention, and select an access control method for your bucket's objects.
-
In the Choose how to protect object data section, do the
following:
- Select any of the options under Data protection that you
want to set for your bucket.
- To enable soft delete, click the Soft delete policy (For data recovery) checkbox, and specify the number of days you want to retain objects after deletion.
- To set Object Versioning, click the Object versioning (For version control) checkbox, and specify the maximum number of versions per object and the number of days after which the noncurrent versions expire.
- To enable the retention policy on objects and buckets, click the Retention (For compliance) checkbox, and then do the following:
- To enable Object Retention Lock, click the Enable object retention checkbox.
- To enable Bucket Lock, click the Set bucket retention policy checkbox, and choose a unit of time and a length of time for your retention period.
- To choose how your object data will be encrypted, expand the Data encryption section (), and select a Data encryption method.
- Select any of the options under Data protection that you
want to set for your bucket.
-
In the Get started section, do the following:
- Click Create.
- Définissez les variables d'environnement :
- PROJECT : ID du projet
- BUCKET_NAME : nom du bucket Cloud Storage créé à la section Avant de commencer
- REGION : région dans laquelle le cluster utilisé dans ce tutoriel sera créé (par exemple, "us-west1")
- WORKERS : trois à cinq nœuds de calcul sont recommandés pour ce tutoriel
export PROJECT=project-id export WORKERS=number export REGION=region export BUCKET_NAME=bucket-name
- Exécutez la Google Cloud CLI sur votre ordinateur local pour créer le cluster.
gcloud beta dataproc clusters create trino-cluster \ --project=${PROJECT} \ --region=${REGION} \ --num-workers=${WORKERS} \ --scopes=cloud-platform \ --optional-components=TRINO \ --image-version=2.1 \ --enable-component-gateway - Sur votre ordinateur local, exécutez la commande suivante pour importer les données relatives aux taxis issues de BigQuery sous forme de fichiers CSV sans en-têtes dans le bucket Cloud Storage créé à la section Avant de commencer.
bq --location=us extract --destination_format=CSV \ --field_delimiter=',' --print_header=false \ "bigquery-public-data:chicago_taxi_trips.taxi_trips" \ gs://${BUCKET_NAME}/chicago_taxi_trips/csv/shard-*.csv - Créez des tables externes Hive sauvegardées sous forme de fichiers CSV et Parquet dans le bucket Cloud Storage.
- Créez la table externe Hive
chicago_taxi_trips_csv.gcloud dataproc jobs submit hive \ --cluster trino-cluster \ --region=${REGION} \ --execute " CREATE EXTERNAL TABLE chicago_taxi_trips_csv( unique_key STRING, taxi_id STRING, trip_start_timestamp TIMESTAMP, trip_end_timestamp TIMESTAMP, trip_seconds INT, trip_miles FLOAT, pickup_census_tract INT, dropoff_census_tract INT, pickup_community_area INT, dropoff_community_area INT, fare FLOAT, tips FLOAT, tolls FLOAT, extras FLOAT, trip_total FLOAT, payment_type STRING, company STRING, pickup_latitude FLOAT, pickup_longitude FLOAT, pickup_location STRING, dropoff_latitude FLOAT, dropoff_longitude FLOAT, dropoff_location STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE location 'gs://${BUCKET_NAME}/chicago_taxi_trips/csv/';" - Vérifiez que la table externe Hive a été créée.
gcloud dataproc jobs submit hive \ --cluster trino-cluster \ --region=${REGION} \ --execute "SELECT COUNT(*) FROM chicago_taxi_trips_csv;" - Créez une autre table externe Hive
chicago_taxi_trips_parquetcomportant les mêmes colonnes, mais avec des données stockées au format Parquet pour de meilleures performances d'interrogation.gcloud dataproc jobs submit hive \ --cluster trino-cluster \ --region=${REGION} \ --execute " CREATE EXTERNAL TABLE chicago_taxi_trips_parquet( unique_key STRING, taxi_id STRING, trip_start_timestamp TIMESTAMP, trip_end_timestamp TIMESTAMP, trip_seconds INT, trip_miles FLOAT, pickup_census_tract INT, dropoff_census_tract INT, pickup_community_area INT, dropoff_community_area INT, fare FLOAT, tips FLOAT, tolls FLOAT, extras FLOAT, trip_total FLOAT, payment_type STRING, company STRING, pickup_latitude FLOAT, pickup_longitude FLOAT, pickup_location STRING, dropoff_latitude FLOAT, dropoff_longitude FLOAT, dropoff_location STRING) STORED AS PARQUET location 'gs://${BUCKET_NAME}/chicago_taxi_trips/parquet/';" - Chargez les données issues de la table CSV Hive dans la table Parquet Hive.
gcloud dataproc jobs submit hive \ --cluster trino-cluster \ --region=${REGION} \ --execute " INSERT OVERWRITE TABLE chicago_taxi_trips_parquet SELECT * FROM chicago_taxi_trips_csv;" - Vérifiez que les données ont été chargées correctement.
gcloud dataproc jobs submit hive \ --cluster trino-cluster \ --region=${REGION} \ --execute "SELECT COUNT(*) FROM chicago_taxi_trips_parquet;"
- Créez la table externe Hive
- Exécutez la commande suivante sur votre ordinateur local pour vous connecter en SSH au nœud maître de votre cluster. Le terminal local cessera de répondre pendant l'exécution de la commande.
gcloud compute ssh trino-cluster-m
- Dans la fenêtre de terminal SSH du nœud maître de votre cluster, exécutez la CLI Trino, qui se connecte au serveur Trino s'exécutant sur le nœud maître.
trino --catalog hive --schema default
- À l'invite
trino:default, vérifiez que Trino a accès aux tables Hive.show tables;
Table ‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐ chicago_taxi_trips_csv chicago_taxi_trips_parquet (2 rows)
- Exécutez les requêtes depuis l'invite
trino:default, et comparez les performances d'interrogation des données Parquet par rapport aux données CSV.- Requête de données Parquet
select count(*) from chicago_taxi_trips_parquet where trip_miles > 50;
_col0 ‐‐‐‐‐‐‐‐ 117957 (1 row)
Query 20180928_171735_00006_2sz8c, FINISHED, 3 nodes Splits: 308 total, 308 done (100.00%) 0:16 [113M rows, 297MB] [6.91M rows/s, 18.2MB/s] - Requête de données CSV
select count(*) from chicago_taxi_trips_csv where trip_miles > 50;
_col0 ‐‐‐‐‐‐‐‐ 117957 (1 row)
Query 20180928_171936_00009_2sz8c, FINISHED, 3 nodes Splits: 881 total, 881 done (100.00%) 0:47 [113M rows, 41.5GB] [2.42M rows/s, 911MB/s]
- Requête de données Parquet
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
- Pour supprimer le cluster :
gcloud dataproc clusters delete --project=${PROJECT} trino-cluster \ --region=${REGION} - Pour supprimer le bucket Cloud Storage créé à la section Avant de commencer, y compris les fichiers de données stockés dans le bucket :
gcloud storage rm gs://${BUCKET_NAME} --recursive
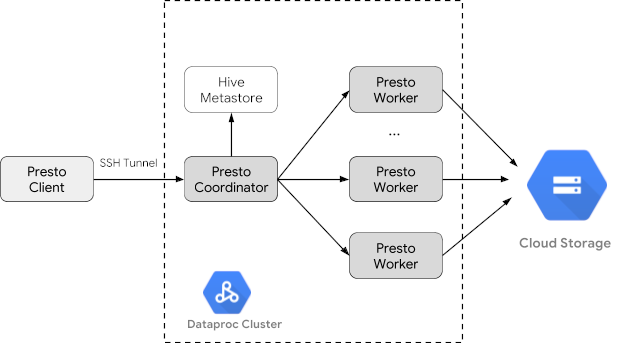
Créer un cluster Dataproc
Créez un cluster Dataproc en utilisant l'option optional-components (disponible sur les versions d'image 2.1 et ultérieures) pour installer le composant facultatif Trino sur le cluster, et en utilisant l'option enable-component-gateway pour activer la passerelle des composants et ainsi vous permettre d'accéder à l'interface utilisateur Web de Trino depuis la console Google Cloud .
Préparer les données
Exportez l'ensemble de données bigquery-public-data chicago_taxi_trips vers Cloud Storage sous forme de fichiers CSV, puis créez une table externe Hive pour référencer les données.
Exécuter des requêtes
Vous pouvez exécuter des requêtes localement à partir de la CLI Trino ou d'une application.
Requêtes depuis la CLI Trino
Cette section explique comment interroger l'ensemble de données Parquet Hive sur les taxis à l'aide de la CLI Trino.
Requêtes depuis une application Java
Pour exécuter des requêtes depuis une application Java par le biais du pilote Java JDBC de Trino :
1. Téléchargez le pilote Java JDBC de Trino.
1. Ajoutez une dépendance trino-jdbc dans le fichier Maven pom.xml.
<dependency> <groupId>io.trino</groupId> <artifactId>trino-jdbc</artifactId> <version>376</version> </dependency>
package dataproc.codelab.trino;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
import java.util.Properties;
public class TrinoQuery {
private static final String URL = "jdbc:trino://trino-cluster-m:8080/hive/default";
private static final String SOCKS_PROXY = "localhost:1080";
private static final String USER = "user";
private static final String QUERY =
"select count(*) as count from chicago_taxi_trips_parquet where trip_miles > 50";
public static void main(String[] args) {
try {
Properties properties = new Properties();
properties.setProperty("user", USER);
properties.setProperty("socksProxy", SOCKS_PROXY);
Connection connection = DriverManager.getConnection(URL, properties);
try (Statement stmt = connection.createStatement()) {
ResultSet rs = stmt.executeQuery(QUERY);
while (rs.next()) {
int count = rs.getInt("count");
System.out.println("The number of long trips: " + count);
}
}
} catch (SQLException e) {
e.printStackTrace();
}
}
}Journalisation et surveillance
Journalisation
Les journaux Trino se trouvent sous /var/log/trino/ sur les nœuds maîtres et les nœuds de calcul du cluster.
UI Web
Consultez la section Afficher les URL de la passerelle des composants et y accéder pour ouvrir l'interface utilisateur Web de Trino s'exécutant sur le nœud maître du cluster dans votre navigateur local.
Surveillance
Trino présente les informations d'exécution du cluster dans des tables d'exécution.
Dans une invite de session Trino (depuis trino:default), exécutez la requête suivante pour afficher les données des tables d'exécution :
select * FROM system.runtime.nodes;
Effectuer un nettoyage
Une fois le tutoriel terminé, vous pouvez procéder au nettoyage des ressources que vous avez créées afin qu'elles ne soient plus comptabilisées dans votre quota et qu'elles ne vous soient plus facturées. Dans les sections suivantes, nous allons voir comment supprimer ou désactiver ces ressources.
Supprimer le projet
Le moyen le plus simple d'empêcher la facturation est de supprimer le projet que vous avez créé pour ce tutoriel.
Pour supprimer le projet :