El conector spark-bigquery se usa con Apache Spark para leer y escribir datos desde y hacia BigQuery. El conector aprovecha la API Storage de BigQuery al leer datos de BigQuery.
En este tutorial se proporciona información sobre la disponibilidad del conector preinstalado y se explica cómo hacer que una versión específica del conector esté disponible para los trabajos de Spark. El código de ejemplo muestra cómo usar el conector de BigQuery de Spark en una aplicación de Spark.
Usar el conector preinstalado
El conector de Spark BigQuery está preinstalado y disponible para las tareas de Spark que se ejecutan en clústeres de Dataproc creados con versiones de imagen 2.1 o posteriores. La versión del conector preinstalado se indica en la página de lanzamiento de cada versión de la imagen. Por ejemplo, la fila Conector de BigQuery de la página Versiones de lanzamiento de imágenes 2.2.x muestra la versión del conector que está instalada en las versiones de lanzamiento de imágenes 2.2 más recientes.
Poner una versión específica de un conector a disposición de las tareas de Spark
Si quieres usar una versión de conector diferente de la versión preinstalada en un clúster con la versión de imagen 2.1 o posterior, o si quieres instalar el conector en un clúster con una versión de imagen anterior a 2.1, sigue las instrucciones de esta sección.
Importante: La versión de spark-bigquery-connector debe ser compatible con la versión de imagen del clúster de Dataproc. Consulta la matriz de compatibilidad de conectores con imágenes de Dataproc.
2.1 y versiones posteriores de clústeres de imágenes
Cuando crees un clúster de Dataproc con una versión de imagen 2.1 o posterior, especifica la versión del conector como metadatos del clúster.
Ejemplo de la CLI gcloud:
gcloud dataproc clusters create CLUSTER_NAME \ --region=REGION \ --image-version=2.2 \ --metadata=SPARK_BQ_CONNECTOR_VERSION or SPARK_BQ_CONNECTOR_URL\ other flags
Notas:
SPARK_BQ_CONNECTOR_VERSION: especifica una versión del conector. Las versiones del conector de BigQuery para Spark se indican en la página spark-bigquery-connector/releases de GitHub.
Ejemplo:
--metadata=SPARK_BQ_CONNECTOR_VERSION=0.42.1
SPARK_BQ_CONNECTOR_URL: especifica una URL que apunte al archivo JAR en Cloud Storage. Puedes especificar la URL de un conector que figure en la columna link de la sección Downloading and Using the Connector (Descargar y usar el conector) de GitHub o la ruta a una ubicación de Cloud Storage en la que hayas colocado un archivo JAR de conector personalizado.
Ejemplos:
--metadata=SPARK_BQ_CONNECTOR_URL=gs://spark-lib/bigquery/spark-3.5-bigquery-0.42.1.jar --metadata=SPARK_BQ_CONNECTOR_URL=gs://PATH_TO_CUSTOM_JAR
2.0 y clústeres de versiones de imágenes anteriores
Puede hacer que el conector de BigQuery de Spark esté disponible para su aplicación de una de las siguientes formas:
Instala spark-bigquery-connector en el directorio de archivos JAR de Spark de cada nodo mediante la acción de inicialización de conectores de Dataproc al crear el clúster.
Proporciona la URL del archivo JAR del conector cuando envíes la tarea al clúster mediante la Google Cloud consola, la CLI de gcloud o la API de Dataproc.
Consola
Usa el elemento Archivos JAR de la tarea de Spark en la página Enviar una tarea de Dataproc.
gcloud
API
Usa el campo
SparkJob.jarFileUris.Cómo especificar el archivo JAR del conector al ejecutar tareas de Spark en clústeres con versiones de imagen anteriores a la 2.0
- Especifica el archivo JAR del conector sustituyendo la información de la versión de Scala y del conector en la siguiente cadena de URI:
gs://spark-lib/bigquery/spark-bigquery-with-dependencies_SCALA_VERSION-CONNECTOR_VERSION.jar
- Usar Scala
2.12con versiones de imagen de Dataproc1.5+gs://spark-lib/bigquery/spark-bigquery-with-dependencies_2.12-CONNECTOR_VERSION.jar
gcloud dataproc jobs submit spark \ --jars=gs://spark-lib/bigquery/spark-bigquery-with-dependencies_2.12-0.23.2.jar \ -- job args
- Usa Scala
2.11con las versiones de imagen de Dataproc1.4y anteriores:gs://spark-lib/bigquery/spark-bigquery-with-dependencies_2.11-CONNECTOR_VERSION.jar
gcloud dataproc jobs submit spark \ --jars=gs://spark-lib/bigquery/spark-bigquery-with-dependencies_2.11-0.23.2.jar \ -- job-args
- Especifica el archivo JAR del conector sustituyendo la información de la versión de Scala y del conector en la siguiente cadena de URI:
Incluye el archivo JAR del conector en tu aplicación de Scala o Java Spark como dependencia (consulta Compilar con el conector).
Calcular los costes
En este documento, se utilizan los siguientes componentes facturables de Google Cloud:
- Dataproc
- BigQuery
- Cloud Storage
Para generar una estimación de costes basada en el uso previsto,
utiliza la calculadora de precios.
Leer y escribir datos en BigQuery
En este ejemplo se leen datos de BigQuery y se insertan en un DataFrame de Spark para contar palabras mediante la API de fuente de datos estándar.
El conector escribe los datos en BigQuery almacenando primero todos los datos en una tabla temporal de Cloud Storage. A continuación, copia todos los datos en BigQuery en una sola operación. El conector intenta eliminar los archivos temporales una vez que la operación de carga de BigQuery se ha completado correctamente y otra vez cuando finaliza la aplicación Spark.
Si el trabajo falla, elimina los archivos temporales de Cloud Storage que queden. Normalmente, los archivos temporales de BigQuery se encuentran en gs://[bucket]/.spark-bigquery-[jobid]-[UUID].
Configurar la facturación
De forma predeterminada, el proyecto asociado a las credenciales o a la cuenta de servicio se factura por el uso de la API. Para facturar un proyecto diferente, define la siguiente configuración: spark.conf.set("parentProject", "<BILLED-GCP-PROJECT>").
También se puede añadir a una operación de lectura o escritura, como se indica a continuación:
.option("parentProject", "<BILLED-GCP-PROJECT>").
Ejecutar el código
Antes de ejecutar este ejemplo, crea un conjunto de datos llamado "wordcount_dataset" o cambia el conjunto de datos de salida en el código por un conjunto de datos de BigQuery que ya tengas en tu proyectoGoogle Cloud .
Usa el comando bq para crear el wordcount_dataset:
bq mk wordcount_dataset
Usa el comando de la CLI de Google Cloud para crear un segmento de Cloud Storage, que se usará para exportar a BigQuery:
gcloud storage buckets create gs://[bucket]
Scala
- Examina el código y sustituye el marcador de posición [bucket] por el segmento de Cloud Storage que has creado anteriormente.
/* * Remove comment if you are not running in spark-shell. * import org.apache.spark.sql.SparkSession val spark = SparkSession.builder() .appName("spark-bigquery-demo") .getOrCreate() */ // Use the Cloud Storage bucket for temporary BigQuery export data used // by the connector. val bucket = "[bucket]" spark.conf.set("temporaryGcsBucket", bucket) // Load data in from BigQuery. See // https://github.com/GoogleCloudDataproc/spark-bigquery-connector/tree/0.17.3#properties // for option information. val wordsDF = spark.read.bigquery("bigquery-public-data:samples.shakespeare") .cache() wordsDF.createOrReplaceTempView("words") // Perform word count. val wordCountDF = spark.sql( "SELECT word, SUM(word_count) AS word_count FROM words GROUP BY word") wordCountDF.show() wordCountDF.printSchema() // Saving the data to BigQuery. (wordCountDF.write.format("bigquery") .save("wordcount_dataset.wordcount_output"))
- Ejecutar el código en tu clúster
- Usa SSH para conectarte al nodo maestro del clúster de Dataproc.
- Ve a la página Clústeres de Dataproc en la consola Google Cloud y, a continuación, haz clic en el nombre de tu clúster.
- En la página > Detalles del clúster, selecciona la pestaña Instancias de VM. A continuación, haga clic en
SSHa la derecha del nombre del nodo maestro del clúster>
Se abrirá una ventana del navegador en el directorio principal del nodo maestro.Connected, host fingerprint: ssh-rsa 2048 ... ... user@clusterName-m:~$
- Ve a la página Clústeres de Dataproc en la consola Google Cloud y, a continuación, haz clic en el nombre de tu clúster.
- Crea un
wordcount.scalacon el editor de textovi,vimonanopreinstalado y, a continuación, pega el código de Scala de la lista de código de Scala.nano wordcount.scala
- Inicia el
spark-shellREPL.$ spark-shell --jars=gs://spark-lib/bigquery/spark-bigquery-latest.jar ... Using Scala version ... Type in expressions to have them evaluated. Type :help for more information. ... Spark context available as sc. ... SQL context available as sqlContext. scala>
- Ejecuta wordcount.scala con el comando
:load wordcount.scalapara crear la tablawordcount_outputde BigQuery. La salida muestra 20 líneas de la salida de recuento de palabras.:load wordcount.scala ... +---------+----------+ | word|word_count| +---------+----------+ | XVII| 2| | spoil| 28| | Drink| 7| |forgetful| 5| | Cannot| 46| | cures| 10| | harder| 13| | tresses| 3| | few| 62| | steel'd| 5| | tripping| 7| | travel| 35| | ransom| 55| | hope| 366| | By| 816| | some| 1169| | those| 508| | still| 567| | art| 893| | feign| 10| +---------+----------+ only showing top 20 rows root |-- word: string (nullable = false) |-- word_count: long (nullable = true)
Para previsualizar la tabla de resultados, abra la páginaBigQuery, seleccione la tablawordcount_outputy, a continuación, haga clic en Vista previa.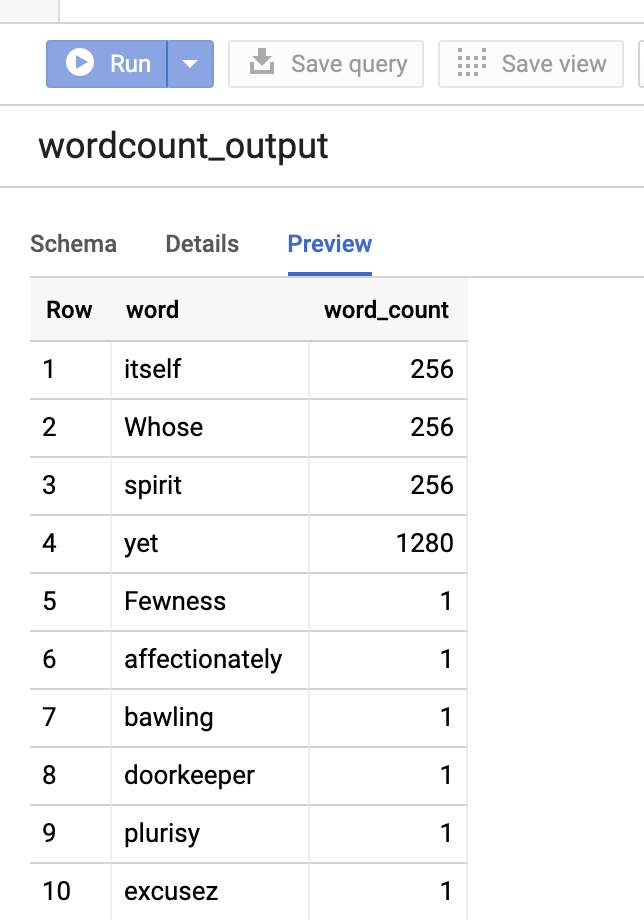
- Usa SSH para conectarte al nodo maestro del clúster de Dataproc.
PySpark
- Examina el código y sustituye el marcador de posición [bucket] por el segmento de Cloud Storage que has creado anteriormente.
#!/usr/bin/env python """BigQuery I/O PySpark example.""" from pyspark.sql import SparkSession spark = SparkSession \ .builder \ .master('yarn') \ .appName('spark-bigquery-demo') \ .getOrCreate() # Use the Cloud Storage bucket for temporary BigQuery export data used # by the connector. bucket = "[bucket]" spark.conf.set('temporaryGcsBucket', bucket) # Load data from BigQuery. words = spark.read.format('bigquery') \ .load('bigquery-public-data:samples.shakespeare') \ words.createOrReplaceTempView('words') # Perform word count. word_count = spark.sql( 'SELECT word, SUM(word_count) AS word_count FROM words GROUP BY word') word_count.show() word_count.printSchema() # Save the data to BigQuery word_count.write.format('bigquery') \ .save('wordcount_dataset.wordcount_output')
- Ejecuta el código en tu clúster
- Usar SSH para conectarse al nodo maestro del clúster de Dataproc
- Ve a la página Clústeres de Dataproc en la consola Google Cloud y, a continuación, haz clic en el nombre de tu clúster.
- En la página Detalles del clúster, selecciona la pestaña Instancias de VM. A continuación, haga clic en
SSHa la derecha del nombre del nodo maestro del clúster
Se abrirá una ventana del navegador en el directorio principal del nodo maestro.Connected, host fingerprint: ssh-rsa 2048 ... ... user@clusterName-m:~$
- Ve a la página Clústeres de Dataproc en la consola Google Cloud y, a continuación, haz clic en el nombre de tu clúster.
- Crea un
wordcount.pycon el editor de textovi,vimonanopreinstalado y, a continuación, pega el código de PySpark de la lista de código de PySpark.nano wordcount.py
- Ejecuta el recuento de palabras con
spark-submitpara crear la tablawordcount_outputde BigQuery. La lista de resultados muestra 20 líneas de la salida de recuento de palabras.spark-submit --jars gs://spark-lib/bigquery/spark-bigquery-latest.jar wordcount.py ... +---------+----------+ | word|word_count| +---------+----------+ | XVII| 2| | spoil| 28| | Drink| 7| |forgetful| 5| | Cannot| 46| | cures| 10| | harder| 13| | tresses| 3| | few| 62| | steel'd| 5| | tripping| 7| | travel| 35| | ransom| 55| | hope| 366| | By| 816| | some| 1169| | those| 508| | still| 567| | art| 893| | feign| 10| +---------+----------+ only showing top 20 rows root |-- word: string (nullable = false) |-- word_count: long (nullable = true)
Para previsualizar la tabla de resultados, abra la páginaBigQuery, seleccione la tablawordcount_outputy, a continuación, haga clic en Vista previa.
- Usar SSH para conectarse al nodo maestro del clúster de Dataproc
Consejos para solucionar problemas
Puedes examinar los registros de tareas en Cloud Logging y en el Explorador de tareas de BigQuery para solucionar problemas de las tareas de Spark que usan el conector de BigQuery.
Los registros del controlador de Dataproc contienen una entrada
BigQueryClientcon metadatos de BigQuery que incluyen eljobId:ClassNotFoundException
INFO BigQueryClient:.. jobId: JobId{project=PROJECT_ID, job=JOB_ID, location=LOCATION} Los trabajos de BigQuery contienen etiquetas
Dataproc_job_idyDataproc_job_uuid:- Registro:
protoPayload.serviceData.jobCompletedEvent.job.jobConfiguration.labels.dataproc_job_id="JOB_ID" protoPayload.serviceData.jobCompletedEvent.job.jobConfiguration.labels.dataproc_job_uuid="JOB_UUID" protoPayload.serviceData.jobCompletedEvent.job.jobName.jobId="JOB_NAME"
- Explorador de tareas de BigQuery: haga clic en un ID de tarea para ver los detalles de la tarea en Etiquetas, en Información de la tarea.
- Registro:
Siguientes pasos
- Consulta Almacenamiento de BigQuery y Spark SQL: Python.
- Consulte cómo crear un archivo de definición de tabla para una fuente de datos externa.
- Consulta cómo consultar datos con particiones externas.
- Consulta los consejos para ajustar las tareas de Spark.