使用客户端库创建 Dataproc 集群
下面列出的示例代码介绍了如何使用 Cloud 客户端库创建 Dataproc 集群,在集群上运行作业,然后删除集群。
您还可以通过以下方法执行这些任务:
- 快速入门:使用 API Explorer 中介绍的 API REST 请求
- 使用 Google Cloud 控制台创建 Dataproc 集群中的 Google Cloud 控制台
- 使用 Google Cloud CLI 创建 Dataproc 集群中的 Google Cloud CLI
准备工作
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Dataproc API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Dataproc API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. - 安装客户端库 如需了解详情,请参阅设置 Java 开发环境。
- 设置身份验证
- 克隆并运行示例 GitHub 代码。
- 查看输出。代码会将作业驱动程序日志输出到 Cloud Storage 中的默认 Dataproc 暂存存储分区。您可以在项目的 Dataproc 作业部分中查看 Google Cloud 控制台的作业驱动程序输出。点击“作业详细信息”页面上的作业 ID 以查看作业输出。
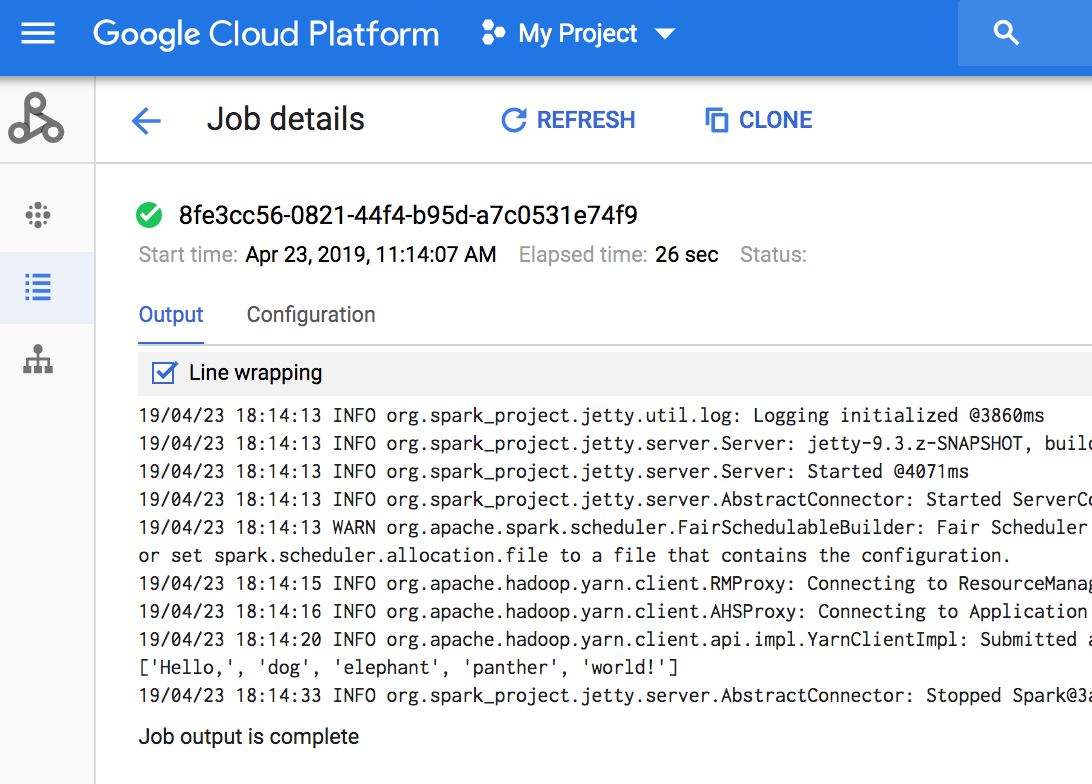
- 安装客户端库 如需了解详情,请参阅设置 Node.js 开发环境。
- 设置身份验证
- 克隆并运行示例 GitHub 代码。
- 查看输出。代码会将作业驱动程序日志输出到 Cloud Storage 中的默认 Dataproc 暂存存储分区。您可以在项目的 Dataproc 作业部分中查看 Google Cloud 控制台的作业驱动程序输出。点击“作业详细信息”页面上的作业 ID 以查看作业输出。
- 安装客户端库 如需了解详情,请参阅设置 Python 开发环境。
- 设置身份验证
- 克隆并运行示例 GitHub 代码。
- 查看输出。代码会将作业驱动程序日志输出到 Cloud Storage 中的默认 Dataproc 暂存存储分区。您可以在项目的 Dataproc 作业部分中查看 Google Cloud 控制台的作业驱动程序输出。点击“作业详细信息”页面上的作业 ID 以查看作业输出。
- 请参阅关于 Dataproc Cloud 客户端库的其他资源。
运行代码
试用演示:点击在 Cloud Shell 中打开运行 Python Cloud 客户端库演示,以创建集群、运行 PySpark 作业,然后删除集群。