클라이언트 라이브러리를 사용하여 Dataproc 클러스터 만들기
아래 나열된 샘플 코드는 Cloud 클라이언트 라이브러리를 사용하여 Dataproc 클러스터를 만들고 클러스터에서 작업을 실행한 다음 클러스터를 삭제하는 방법을 보여줍니다.
다음을 사용하여 이러한 작업을 수행할 수도 있습니다.
- 빠른 시작: API 탐색기 사용의 API REST 요청
- Google Cloud 콘솔을 사용하여 Dataproc 클러스터 만들기의 Google Cloud 콘솔
- Google Cloud CLI를 사용하여 Dataproc 클러스터 만들기의 Google Cloud CLI
시작하기 전에
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Dataproc API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Dataproc API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. - 클라이언트 라이브러리를 설치합니다. 자세한 내용은 개발 환경 설정을 참조하세요.
- 인증을 설정합니다.
- 샘플 GitHub 코드를 클론하고 실행합니다.
- 출력을 확인합니다. 코드는 작업 드라이브 로그를 Cloud Storage의 기본 Dataproc 스테이징 버킷으로 출력합니다. 프로젝트의 Dataproc 작업 섹션에서 Google Cloud 콘솔의 작업 드라이버 출력을 볼 수 있습니다. 작업 세부정보 페이지에서 작업 출력을 보려면 작업 ID를 클릭합니다.
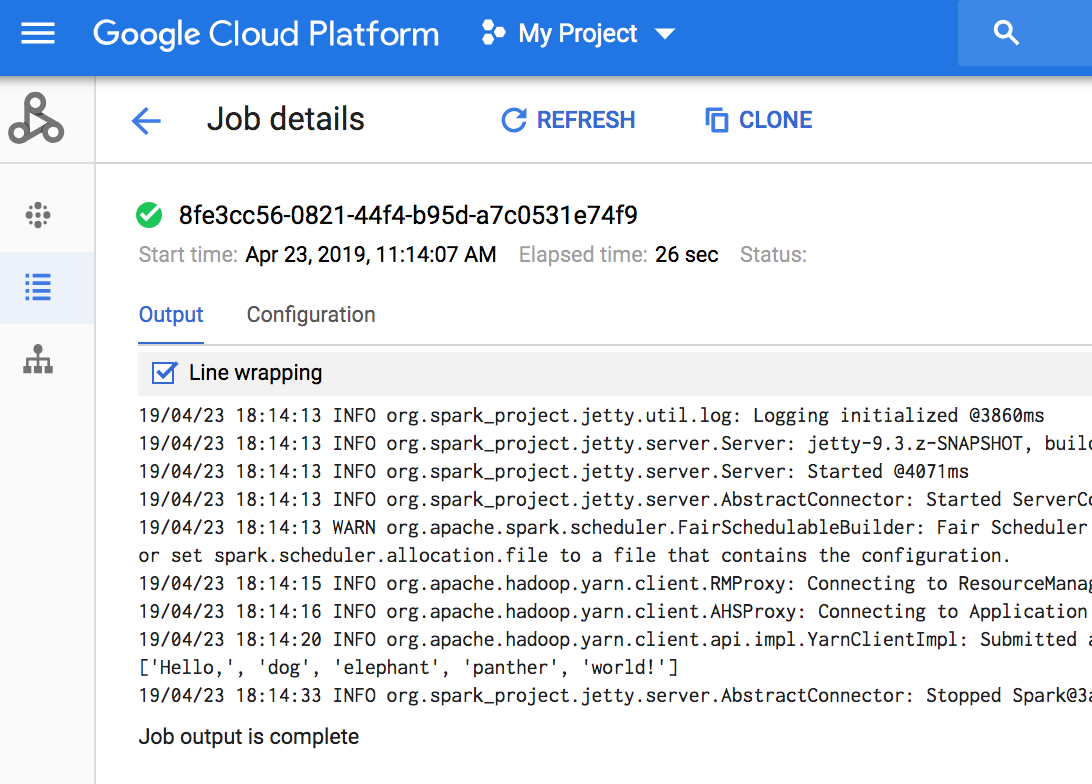
- 클라이언트 라이브러리를 설치합니다. 자세한 내용은 자바 개발 환경 설정을 참조하세요.
- 인증을 설정합니다.
- 샘플 GitHub 코드를 클론하고 실행합니다.
- 출력을 확인합니다. 코드는 작업 드라이브 로그를 Cloud Storage의 기본 Dataproc 스테이징 버킷으로 출력합니다. 프로젝트의 Dataproc 작업 섹션에서 Google Cloud 콘솔의 작업 드라이버 출력을 볼 수 있습니다. 작업 세부정보 페이지에서 작업 출력을 보려면 작업 ID를 클릭합니다.
- 클라이언트 라이브러리를 설치합니다. 자세한 내용은 Node.js 개발 환경 설정을 참조하세요.
- 인증을 설정합니다.
- 샘플 GitHub 코드를 클론하고 실행합니다.
- 출력을 확인합니다. 코드는 작업 드라이브 로그를 Cloud Storage의 기본 Dataproc 스테이징 버킷으로 출력합니다. 프로젝트의 Dataproc 작업 섹션에서 Google Cloud 콘솔의 작업 드라이버 출력을 볼 수 있습니다. 작업 세부정보 페이지에서 작업 출력을 보려면 작업 ID를 클릭합니다.
- 클라이언트 라이브러리를 설치합니다. 자세한 내용은 Python 개발 환경 설정을 참조하세요.
- 인증을 설정합니다.
- 샘플 GitHub 코드를 클론하고 실행합니다.
- 출력을 확인합니다. 코드는 작업 드라이브 로그를 Cloud Storage의 기본 Dataproc 스테이징 버킷으로 출력합니다. 프로젝트의 Dataproc 작업 섹션에서 Google Cloud 콘솔의 작업 드라이버 출력을 볼 수 있습니다. 작업 세부정보 페이지에서 작업 출력을 보려면 작업 ID를 클릭합니다.
- Dataproc 클라우드 클라이언트 라이브러리 추가 리소스를 참조하세요.
코드 실행
둘러보기: Cloud Shell에서 열기를 클릭하여 클러스터를 만들고 PySpark 작업을 실행한 다음 클러스터를 삭제하는 Python Cloud 클라이언트 라이브러리 연습을 실행합니다.