Puedes enviar una tarea a un clúster de Dataproc mediante una solicitud HTTP o programática jobs.submit de la API de Dataproc, con la herramienta de línea de comandos gcloud de la CLI de Google Cloud en una ventana de terminal local o en Cloud Shell, o desde la Google Cloud consola abierta en un navegador local. También puedes conectarte a la instancia principal mediante SSH de tu clúster y, a continuación, ejecutar un trabajo directamente desde la instancia sin usar el servicio Dataproc.
Cómo enviar una tarea
Consola
Abre la página de Dataproc Enviar un trabajo en la Google Cloud consola de tu navegador.
Ejemplo de trabajo de Spark
Para enviar una tarea de Spark de ejemplo, rellena los campos de la página Enviar una tarea de la siguiente manera:
- Selecciona el nombre de tu clúster en la lista de clústeres.
- En Tipo de tarea, selecciona
Spark. - Asigna el valor
org.apache.spark.examples.SparkPia Clase principal o .jar. - Asigna a Arguments el argumento
1000. - Añade
file:///usr/lib/spark/examples/jars/spark-examples.jara archivos .jar:file:///denota un esquema de Hadoop LocalFileSystem. Dataproc instaló/usr/lib/spark/examples/jars/spark-examples.jaren el nodo maestro del clúster cuando creó el clúster.- También puedes especificar una ruta de Cloud Storage (
gs://your-bucket/your-jarfile.jar) o una ruta del sistema de archivos distribuidos de Hadoop (hdfs://path-to-jar.jar) a uno de tus archivos JAR.
Haz clic en Enviar para iniciar el trabajo. Una vez que se inicia el trabajo, se añade a la lista de trabajos.
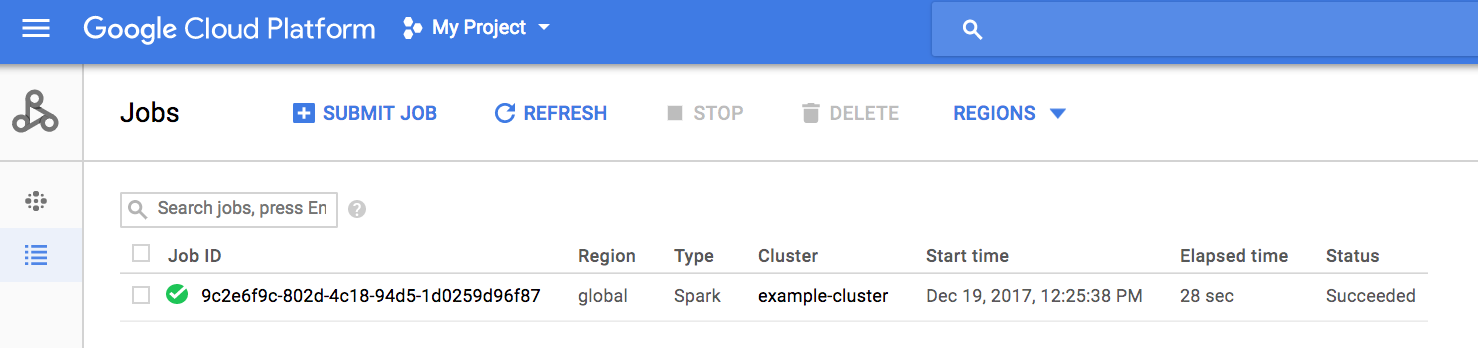
Haz clic en el ID de la tarea para abrir la página Tareas, donde puedes ver el resultado del controlador de la tarea. Como este trabajo genera líneas de salida largas que superan el ancho de la ventana del navegador, puedes marcar la casilla Ajuste de línea para que todo el texto de salida se muestre en la vista y se pueda ver el resultado calculado de pi.

Puedes ver la salida del controlador de tu tarea desde la línea de comandos con el comando gcloud dataproc jobs wait que se muestra a continuación (para obtener más información, consulta Ver la salida de una tarea: COMANDO GCLOUD).
Copia y pega el ID de tu proyecto como valor de la marca --project y el ID de empleo (que se muestra en la lista de empleos) como argumento final.
gcloud dataproc jobs wait job-id \ --project=project-id \ --region=region
A continuación se muestran fragmentos de la salida del controlador de la tarea SparkPi
de ejemplo enviada anteriormente:
... 2015-06-25 23:27:23,810 INFO [dag-scheduler-event-loop] scheduler.DAGScheduler (Logging.scala:logInfo(59)) - Stage 0 (reduce at SparkPi.scala:35) finished in 21.169 s 2015-06-25 23:27:23,810 INFO [task-result-getter-3] cluster.YarnScheduler (Logging.scala:logInfo(59)) - Removed TaskSet 0.0, whose tasks have all completed, from pool 2015-06-25 23:27:23,819 INFO [main] scheduler.DAGScheduler (Logging.scala:logInfo(59)) - Job 0 finished: reduce at SparkPi.scala:35, took 21.674931 s Pi is roughly 3.14189648 ... Job [c556b47a-4b46-4a94-9ba2-2dcee31167b2] finished successfully. driverOutputUri: gs://sample-staging-bucket/google-cloud-dataproc-metainfo/cfeaa033-749e-48b9-... ...
gcloud
Para enviar una tarea a un clúster de Dataproc, ejecuta el comando de la CLI de gcloud gcloud dataproc jobs submit de forma local en una ventana de terminal o en Cloud Shell.
gcloud dataproc jobs submit job-command \ --cluster=cluster-name \ --region=region \ other dataproc-flags \ -- job-args
- Lista los
hello-world.pyde acceso público ubicados en Cloud Storage.gcloud storage cat gs://dataproc-examples/pyspark/hello-world/hello-world.py
#!/usr/bin/python import pyspark sc = pyspark.SparkContext() rdd = sc.parallelize(['Hello,', 'world!']) words = sorted(rdd.collect()) print(words)
- Envía la tarea de PySpark a Dataproc.
gcloud dataproc jobs submit pyspark \ gs://dataproc-examples/pyspark/hello-world/hello-world.py \ --cluster=cluster-name \ --region=region
Waiting for job output... … ['Hello,', 'world!'] Job finished successfully.
- Ejecuta el ejemplo SparkPi preinstalado en el nodo maestro del clúster de Dataproc.
gcloud dataproc jobs submit spark \ --cluster=cluster-name \ --region=region \ --class=org.apache.spark.examples.SparkPi \ --jars=file:///usr/lib/spark/examples/jars/spark-examples.jar \ -- 1000
Job [54825071-ae28-4c5b-85a5-58fae6a597d6] submitted. Waiting for job output… … Pi is roughly 3.14177148 … Job finished successfully. …
REST
En esta sección se muestra cómo enviar una tarea de Spark para calcular el valor aproximado de pi mediante la API jobs.submit de Dataproc.
Antes de usar los datos de la solicitud, haz las siguientes sustituciones:
- project-id: Google Cloud ID de proyecto
- region: región del clúster
- clusterName: nombre del clúster
Método HTTP y URL:
POST https://dataproc.googleapis.com/v1/projects/project-id/regions/region/jobs:submit
Cuerpo JSON de la solicitud:
{
"job": {
"placement": {
"clusterName": "cluster-name"
},
"sparkJob": {
"args": [
"1000"
],
"mainClass": "org.apache.spark.examples.SparkPi",
"jarFileUris": [
"file:///usr/lib/spark/examples/jars/spark-examples.jar"
]
}
}
}
Para enviar tu solicitud, despliega una de estas opciones:
Deberías recibir una respuesta JSON similar a la siguiente:
{
"reference": {
"projectId": "project-id",
"jobId": "job-id"
},
"placement": {
"clusterName": "cluster-name",
"clusterUuid": "cluster-Uuid"
},
"sparkJob": {
"mainClass": "org.apache.spark.examples.SparkPi",
"args": [
"1000"
],
"jarFileUris": [
"file:///usr/lib/spark/examples/jars/spark-examples.jar"
]
},
"status": {
"state": "PENDING",
"stateStartTime": "2020-10-07T20:16:21.759Z"
},
"jobUuid": "job-Uuid"
}
Java
Python
Go
Node.js
Enviar un trabajo directamente en tu clúster
Si quieres ejecutar un trabajo directamente en tu clúster sin usar el servicio Dataproc, conéctate mediante SSH al nodo maestro de tu clúster y, a continuación, ejecuta el trabajo en el nodo maestro.
Después de establecer una conexión SSH con la instancia maestra de la VM, ejecuta comandos en una ventana de terminal del nodo maestro del clúster para hacer lo siguiente:
- Abre un shell de Spark.
- Ejecuta una tarea de Spark sencilla para contar el número de líneas de un archivo Python "hello-world" (de siete líneas) ubicado en un archivo de Cloud Storage de acceso público.
Salir del shell.
user@cluster-name-m:~$ spark-shell ... scala> sc.textFile("gs://dataproc-examples" + "/pyspark/hello-world/hello-world.py").count ... res0: Long = 7 scala> :quit
Ejecutar tareas de Bash en Dataproc
Puede que quieras ejecutar una secuencia de comandos bash como trabajo de Dataproc, ya sea porque los
motores que usas no se admiten como tipo de trabajo de Dataproc de nivel superior o porque
necesitas hacer una configuración adicional o calcular argumentos antes de iniciar un
trabajo con hadoop o spark-submit desde tu secuencia de comandos.
Ejemplo de Pig
Supongamos que ha copiado una secuencia de comandos bash hello.sh en Cloud Storage:
gcloud storage cp hello.sh gs://${BUCKET}/hello.shComo el comando pig fs usa rutas de Hadoop, copie la secuencia de comandos de Cloud Storage en un destino especificado como file:/// para asegurarse de que se encuentra en el sistema de archivos local en lugar de en HDFS. Los comandos sh posteriores hacen referencia al sistema de archivos local automáticamente y no requieren el prefijo file:///.
gcloud dataproc jobs submit pig --cluster=${CLUSTER} --region=${REGION} \
-e='fs -cp -f gs://${BUCKET}/hello.sh file:///tmp/hello.sh; sh chmod 750 /tmp/hello.sh; sh /tmp/hello.sh'También puedes especificar tu secuencia de comandos de shell de Cloud Storage como argumento --jars, ya que el argumento --jars de las tareas de Dataproc pone en el área de stage un archivo en un directorio temporal creado durante el tiempo de vida de la tarea:
gcloud dataproc jobs submit pig --cluster=${CLUSTER} --region=${REGION} \
--jars=gs://${BUCKET}/hello.sh \
-e='sh chmod 750 ${PWD}/hello.sh; sh ${PWD}/hello.sh'Ten en cuenta que el argumento --jars también puede hacer referencia a una secuencia de comandos local:
gcloud dataproc jobs submit pig --cluster=${CLUSTER} --region=${REGION} \
--jars=hello.sh \
-e='sh chmod 750 ${PWD}/hello.sh; sh ${PWD}/hello.sh'