Um recurso NodeGroup do Dataproc é um grupo de nós de cluster do Dataproc que executam uma função atribuída. Nesta página, descrevemos o grupo de nós de driver, que é um grupo de VMs do Compute Engine atribuídas à função Driver para executar drivers de jobs no cluster do Dataproc.
Quando usar grupos de nós de driver
- Use grupos de nós de driver apenas quando precisar executar muitos jobs simultâneos em um cluster compartilhado.
- Aumente os recursos do nó principal antes de usar grupos de nós de driver para evitar limitações do grupo de nós de driver.
Como os nós de driver ajudam você a executar um trabalho simultâneo
O Dataproc inicia um processo de driver de job em um nó mestre do cluster do Dataproc para cada job. O processo de driver, por sua vez,
executa um driver de aplicativo, como spark-submit, como processo filho.
No entanto, o número de jobs simultâneos em execução no mestre é limitado pelos recursos disponíveis no nó mestre. Como os nós mestres do Dataproc não podem ser escalonados, um job pode falhar ou ser limitado quando os recursos do nó mestre são insuficientes para executar um job.
Os grupos de nós de driver são grupos de nós especiais gerenciados pelo YARN. Portanto, a simultaneidade de jobs não é limitada pelos recursos do nó mestre. Em clusters com um grupo de nós de driver, os drivers de aplicativos são executados em nós de driver. Cada nó de driver pode executar vários drivers de aplicativo se tiver recursos suficientes.
Vantagens
Usar um cluster do Dataproc com um grupo de nós de driver permite:
- Escalonar horizontalmente os recursos do driver de job para executar mais jobs simultâneos
- Escalonar os recursos de driver separadamente dos recursos de worker
- Reduza a escala mais rapidamente em clusters de imagem do Dataproc 2.0 e versões mais recentes. Nesses clusters, o mestre do aplicativo é executado em um driver do Spark em um
grupo de nós de driver (o
spark.yarn.unmanagedAM.enabledé definido comotruepor padrão). - Personalizar a inicialização do nó de driver. É possível adicionar
{ROLE} == 'Driver'em um script de inicialização para que ele execute ações em um grupo de nós de driver na seleção de nós.
Limitações
- Os grupos de nós não são compatíveis com os modelos de fluxo de trabalho do Dataproc.
- Não é possível parar, reiniciar ou escalonar automaticamente clusters de grupos de nós.
- O mestre do aplicativo MapReduce é executado em nós de worker. A reduzir escala vertical dos nós de trabalho pode ser lenta se você ativar a desativação gradual.
- A simultaneidade de jobs é afetada pela propriedade de cluster
dataproc:agent.process.threads.job.max. Por exemplo, com três masters e essa propriedade definida como o valor padrão de100, a simultaneidade máxima de jobs no nível do cluster é300.
Grupo de nós do driver comparado ao modo de cluster do Spark
| Recurso | Modo de cluster do Spark | Grupo de nós do driver |
|---|---|---|
| Reduzir escala vertical do nó de trabalho | Os drivers de longa duração são executados nos mesmos nós de trabalho que os contêineres de curta duração, o que torna lenta reduzir escala vertical de workers usando o encerramento normal. | Os nós de trabalho reduzir escala vertical mais rapidamente quando os drivers são executados em grupos de nós. |
| Saída transmitida do driver | É necessário pesquisar nos registros do YARN para encontrar o nó em que o driver foi programado. | A saída do driver é transmitida para o Cloud Storage e pode ser visualizada
no console Google Cloud e na saída do comando gcloud dataproc jobs wait
após a conclusão de um job. |
Permissões do IAM do grupo de nós do driver
As seguintes permissões do IAM estão associadas às ações relacionadas ao grupo de nós do Dataproc.
| Permissão | Ação |
|---|---|
dataproc.nodeGroups.create
|
Crie grupos de nós do Dataproc. Se um usuário tiver dataproc.clusters.create no projeto, essa permissão será concedida. |
dataproc.nodeGroups.get |
Receba os detalhes de um grupo de nós do Dataproc. |
dataproc.nodeGroups.update |
Redimensione um grupo de nós do Dataproc. |
Operações do grupo de nós do driver
É possível usar a CLI gcloud e a API Dataproc para criar, receber, redimensionar, excluir e enviar um job a um grupo de nós de driver do Dataproc.
Criar um cluster de grupo de nós de driver
Um grupo de nós de driver está associado a um cluster do Dataproc. Você cria um grupo de nós como parte da criação de um cluster do Dataproc. Use a CLI gcloud ou a API REST do Dataproc para criar um cluster do Dataproc com um grupo de nós de driver.
gcloud
gcloud dataproc clusters create CLUSTER_NAME \ --region=REGION \ --driver-pool-size=SIZE \ --driver-pool-id=NODE_GROUP_ID
Sinalizações obrigatórias:
- CLUSTER_NAME: o nome do cluster, que precisa ser exclusivo em um projeto. O nome precisa começar com uma letra minúscula e pode conter até 51 letras minúsculas, números e hífens. Não pode terminar com um hífen. O nome de um cluster excluído pode ser reutilizado.
- REGION: a região em que o cluster vai estar localizado.
- SIZE: o número de nós de driver no grupo de nós. O número de nós necessários depende da carga de trabalho e do tipo de máquina do pool de drivers. O número de nós mínimos do grupo de drivers é igual à memória total ou às vCPUs exigidas pelos drivers de jobs divididas pela memória ou pelas vCPUs da máquina de cada pool de drivers.
- NODE_GROUP_ID: opcional e recomendado. O ID precisa ser exclusivo no cluster. Use esse ID para identificar o grupo de drivers em operações futuras, como redimensionar o grupo de nós. Se não for especificado, o Dataproc vai gerar o ID do grupo de nós.
Sinalização recomendada:
--enable-component-gateway: adicione esta flag para ativar o Gateway de componentes do Dataproc, que fornece acesso à interface da Web do YARN. As páginas "Aplicativo" e "Scheduler" da interface do YARN mostram o status do cluster e do job, a memória da fila de aplicativos, a capacidade principal e outras métricas.
Outras flags:as flags driver-pool opcionais a seguir podem ser adicionadas ao comando gcloud dataproc clusters create para personalizar o grupo de nós.
| Sinalização | Valor padrão |
|---|---|
--driver-pool-id |
Um identificador de string gerado pelo serviço se não for definido pela flag. Esse ID pode ser usado para identificar o grupo de nós ao realizar operações futuras do pool de nós, como redimensionar o grupo de nós. |
--driver-pool-machine-type |
n1-standard-4 |
--driver-pool-accelerator |
Sem padrão. Ao especificar um acelerador, o tipo de GPU é obrigatório, e o número de GPUs é opcional. |
--num-driver-pool-local-ssds |
Sem padrão |
--driver-pool-local-ssd-interface |
Sem padrão |
--driver-pool-boot-disk-type |
pd-standard |
--driver-pool-boot-disk-size |
1000 GB |
--driver-pool-min-cpu-platform |
AUTOMATIC |
REST
Conclua um
AuxiliaryNodeGroup
como parte de uma solicitação
cluster.create
da API Dataproc.
Antes de usar os dados da solicitação abaixo, faça as substituições a seguir:
- PROJECT_ID: obrigatório. ID do projeto do Google Cloud.
- REGION: obrigatório. Região do cluster do Dataproc.
- CLUSTER_NAME: obrigatório. O nome do cluster, que precisa ser exclusivo em um projeto. O nome precisa começar com uma letra minúscula e pode conter até 51 letras minúsculas, números e hífens. Ele não pode terminar com um hífen. O nome de um cluster excluído pode ser reutilizado.
- SIZE: obrigatório. Número de nós no grupo de nós.
- NODE_GROUP_ID: opcional e recomendado. O ID precisa ser exclusivo no cluster. Use esse ID para identificar o grupo de drivers em operações futuras, como redimensionar o grupo de nós. Se não for especificado, o Dataproc vai gerar o ID do grupo de nós.
Outras opções:consulte NodeGroup.
Método HTTP e URL:
POST https://dataproc.googleapis.com/v1/projects/PROJECT_ID/regions/REGION/clusters
Corpo JSON da solicitação:
{
"clusterName":"CLUSTER_NAME",
"config": {
"softwareConfig": {
"imageVersion":""
},
"endpointConfig": {
"enableHttpPortAccess": true
},
"auxiliaryNodeGroups": [{
"nodeGroup":{
"roles":["DRIVER"],
"nodeGroupConfig": {
"numInstances": SIZE
}
},
"nodeGroupId": "NODE_GROUP_ID"
}]
}
}
Para enviar a solicitação, expanda uma destas opções:
Você receberá uma resposta JSON semelhante a esta:
{
"projectId": "PROJECT_ID",
"clusterName": "CLUSTER_NAME",
"config": {
...
"auxiliaryNodeGroups": [
{
"nodeGroup": {
"name": "projects/PROJECT_ID/regions/REGION/clusters/CLUSTER_NAME/nodeGroups/NODE_GROUP_ID",
"roles": [
"DRIVER"
],
"nodeGroupConfig": {
"numInstances": SIZE,
"instanceNames": [
"CLUSTER_NAME-np-q1gp",
"CLUSTER_NAME-np-xfc0"
],
"imageUri": "https://www.googleapis.com/compute/v1/projects/cloud-dataproc-ci/global/images/dataproc-2-0-deb10-...-rc01",
"machineTypeUri": "https://www.googleapis.com/compute/v1/projects/PROJECT_ID/zones/REGION-a/machineTypes/n1-standard-4",
"diskConfig": {
"bootDiskSizeGb": 1000,
"bootDiskType": "pd-standard"
},
"managedGroupConfig": {
"instanceTemplateName": "dataproc-2a8224d2-...",
"instanceGroupManagerName": "dataproc-2a8224d2-..."
},
"minCpuPlatform": "AUTOMATIC",
"preemptibility": "NON_PREEMPTIBLE"
}
},
"nodeGroupId": "NODE_GROUP_ID"
}
]
},
}
Receber metadados do cluster do grupo de nós do driver
Use o comando
gcloud dataproc node-groups describe
ou a API Dataproc para
receber metadados do grupo de nós do driver.
gcloud
gcloud dataproc node-groups describe NODE_GROUP_ID \ --cluster=CLUSTER_NAME \ --region=REGION
Sinalizações obrigatórias:
- NODE_GROUP_ID: execute
gcloud dataproc clusters describe CLUSTER_NAMEpara listar o ID do grupo de nós. - CLUSTER_NAME: o nome do cluster.
- REGION: a região do cluster.
REST
Antes de usar os dados da solicitação abaixo, faça as substituições a seguir:
- PROJECT_ID: obrigatório. ID do projeto do Google Cloud.
- REGION: obrigatório. A região do cluster.
- CLUSTER_NAME: obrigatório. O nome do cluster.
- NODE_GROUP_ID: obrigatório. Execute
gcloud dataproc clusters describe CLUSTER_NAMEpara listar o ID do grupo de nós.
Método HTTP e URL:
GET https://dataproc.googleapis.com/v1/projects/PROJECT_ID/regions/REGION/clusters/CLUSTER_NAMEnodeGroups/Node_GROUP_ID
Para enviar a solicitação, expanda uma destas opções:
Você receberá uma resposta JSON semelhante a esta:
{
"name": "projects/PROJECT_ID/regions/REGION/clusters/CLUSTER_NAME/nodeGroups/NODE_GROUP_ID",
"roles": [
"DRIVER"
],
"nodeGroupConfig": {
"numInstances": 5,
"imageUri": "https://www.googleapis.com/compute/v1/projects/cloud-dataproc-ci/global/images/dataproc-2-0-deb10-...-rc01",
"machineTypeUri": "https://www.googleapis.com/compute/v1/projects/PROJECT_ID/zones/REGION-a/machineTypes/n1-standard-4",
"diskConfig": {
"bootDiskSizeGb": 1000,
"bootDiskType": "pd-standard"
},
"managedGroupConfig": {
"instanceTemplateName": "dataproc-driver-pool-mcia3j656h2fy",
"instanceGroupManagerName": "dataproc-driver-pool-mcia3j656h2fy"
},
"minCpuPlatform": "AUTOMATIC",
"preemptibility": "NON_PREEMPTIBLE"
}
}
Redimensionar um grupo de nós de driver
É possível usar o comando
gcloud dataproc node-groups resize
ou a API Dataproc
para adicionar ou remover nós de driver de um grupo de nós de driver de cluster.
gcloud
gcloud dataproc node-groups resize NODE_GROUP_ID \ --cluster=CLUSTER_NAME \ --region=REGION \ --size=SIZE
Sinalizações obrigatórias:
- NODE_GROUP_ID: execute
gcloud dataproc clusters describe CLUSTER_NAMEpara listar o ID do grupo de nós. - CLUSTER_NAME: o nome do cluster.
- REGION: a região do cluster.
- SIZE: especifique o novo número de nós de driver no grupo de nós.
Flag opcional:
--graceful-decommission-timeout=TIMEOUT_DURATION: Ao reduzir verticalmente um grupo de nós, é possível adicionar esta flag para especificar um descomissionamento gradual TIMEOUT_DURATION e evitar o encerramento imediato dos drivers de job. Recomendação:defina uma duração de tempo limite que seja pelo menos igual à duração do job mais longo em execução no grupo de nós. Não é possível recuperar drivers com falha.
Exemplo: comando de escalonar verticalmente da CLI gcloud NodeGroup:
gcloud dataproc node-groups resize NODE_GROUP_ID \ --cluster=CLUSTER_NAME \ --region=REGION \ --size=4
Exemplo: comando de reduzir escala vertical da CLI gcloud NodeGroup:
gcloud dataproc node-groups resize NODE_GROUP_ID \ --cluster=CLUSTER_NAME \ --region=REGION \ --size=1 \ --graceful-decommission-timeout="100s"
REST
Antes de usar os dados da solicitação abaixo, faça as substituições a seguir:
- PROJECT_ID: obrigatório. ID do projeto do Google Cloud.
- REGION: obrigatório. A região do cluster.
- NODE_GROUP_ID: obrigatório. Execute
gcloud dataproc clusters describe CLUSTER_NAMEpara listar o ID do grupo de nós. - SIZE: obrigatório. Novo número de nós no grupo de nós.
- TIMEOUT_DURATION: opcional. Ao reduzir um grupo de nós, você pode adicionar um
gracefulDecommissionTimeoutao corpo da solicitação para evitar o encerramento imediato dos drivers de job. Recomendação:defina uma duração de tempo limite que seja pelo menos igual à duração do job mais longo em execução no grupo de nós. Não é possível recuperar drivers com falha.Exemplo:
{ "size": SIZE, "gracefulDecommissionTimeout": "TIMEOUT_DURATION" }
Método HTTP e URL:
POST https://dataproc.googleapis.com/v1/projects/PROJECT_ID/regions/REGION/clusters/CLUSTER_NAME/nodeGroups/Node_GROUP_ID:resize
Corpo JSON da solicitação:
{
"size": SIZE,
}
Para enviar a solicitação, expanda uma destas opções:
Você receberá uma resposta JSON semelhante a esta:
{
"name": "projects/PROJECT_ID/regions/REGION/operations/OPERATION_ID",
"metadata": {
"@type": "type.googleapis.com/google.cloud.dataproc.v1.NodeGroupOperationMetadata",
"nodeGroupId": "NODE_GROUP_ID",
"clusterUuid": "CLUSTER_UUID",
"status": {
"state": "PENDING",
"innerState": "PENDING",
"stateStartTime": "2022-12-01T23:34:53.064308Z"
},
"operationType": "RESIZE",
"description": "Scale "up or "down" a GCE node pool to SIZE nodes."
}
}
Excluir um cluster de grupo de nós de driver
Quando você exclui um cluster do Dataproc, os grupos de nós associados a ele também são excluídos.
Envie um job
É possível usar o comando gcloud dataproc jobs submit ou a API Dataproc para enviar um job a um cluster com um grupo de nós de driver.
gcloud
gcloud dataproc jobs submit JOB_COMMAND \ --cluster=CLUSTER_NAME \ --region=REGION \ --driver-required-memory-mb=DRIVER_MEMORY \ --driver-required-vcores=DRIVER_VCORES \ DATAPROC_FLAGS \ -- JOB_ARGS
Sinalizações obrigatórias:
- JOB_COMMAND: especifique o comando do job.
- CLUSTER_NAME: o nome do cluster.
- DRIVER_MEMORY: quantidade de memória de drivers de jobs em MB necessária para executar um job. Consulte Controles de memória do Yarn.
- DRIVER_VCORES: o número de vCPUs necessárias para executar um job.
Outras flags:
- DATAPROC_FLAGS: adicione outras flags gcloud dataproc jobs submit relacionadas ao tipo de job.
- JOB_ARGS: adicione argumentos (depois do
--) para transmitir ao job.
Exemplos:é possível executar os exemplos a seguir em uma sessão de terminal SSH em um cluster de grupo de nós de driver do Dataproc.
Job do Spark para estimar o valor de
pi:gcloud dataproc jobs submit spark \ --cluster=CLUSTER_NAME \ --region=REGION \ --driver-required-memory-mb=2048 \ --driver-required-vcores=2 \ --class=org.apache.spark.examples.SparkPi \ --jars=file:///usr/lib/spark/examples/jars/spark-examples.jar \ -- 1000
Job de contagem de palavras do Spark:
gcloud dataproc jobs submit spark \ --cluster=CLUSTER_NAME \ --region=REGION \ --driver-required-memory-mb=2048 \ --driver-required-vcores=2 \ --class=org.apache.spark.examples.JavaWordCount \ --jars=file:///usr/lib/spark/examples/jars/spark-examples.jar \ -- 'gs://apache-beam-samples/shakespeare/macbeth.txt'
Job do PySpark para estimar o valor de
pi:gcloud dataproc jobs submit pyspark \ file:///usr/lib/spark/examples/src/main/python/pi.py \ --cluster=CLUSTER_NAME \ --region=REGION \ --driver-required-memory-mb=2048 \ --driver-required-vcores=2 \ -- 1000
Job TeraGen MapReduce do Hadoop:
gcloud dataproc jobs submit hadoop \ --cluster=CLUSTER_NAME \ --region=REGION \ --driver-required-memory-mb=2048 \ --driver-required-vcores=2 \ --jar file:///usr/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar \ -- teragen 1000 \ hdfs:///gen1/test
REST
Antes de usar os dados da solicitação abaixo, faça as substituições a seguir:
- PROJECT_ID: obrigatório. ID do projeto do Google Cloud.
- REGION: obrigatório. Região do cluster do Dataproc
- CLUSTER_NAME: obrigatório. O nome do cluster, que precisa ser exclusivo em um projeto. O nome precisa começar com uma letra minúscula e pode conter até 51 letras minúsculas, números e hífens. Ele não pode terminar com um hífen. O nome de um cluster excluído pode ser reutilizado.
- DRIVER_MEMORY: obrigatório. Quantidade de memória de drivers de job em MB necessária para executar um job (consulte Controles de memória do Yarn).
- DRIVER_VCORES: obrigatório. O número de vCPUs necessárias para executar um job.
pi.
Método HTTP e URL:
POST https://dataproc.googleapis.com/v1/projects/PROJECT_ID/regions/REGION/jobs:submit
Corpo JSON da solicitação:
{
"job": {
"placement": {
"clusterName": "CLUSTER_NAME",
},
"driverSchedulingConfig": {
"memoryMb]": DRIVER_MEMORY,
"vcores": DRIVER_VCORES
},
"sparkJob": {
"jarFileUris": "file:///usr/lib/spark/examples/jars/spark-examples.jar",
"args": [
"10000"
],
"mainClass": "org.apache.spark.examples.SparkPi"
}
}
}
Para enviar a solicitação, expanda uma destas opções:
Você receberá uma resposta JSON semelhante a esta:
{
"reference": {
"projectId": "PROJECT_ID",
"jobId": "job-id"
},
"placement": {
"clusterName": "CLUSTER_NAME",
"clusterUuid": "cluster-Uuid"
},
"sparkJob": {
"mainClass": "org.apache.spark.examples.SparkPi",
"args": [
"1000"
],
"jarFileUris": [
"file:///usr/lib/spark/examples/jars/spark-examples.jar"
]
},
"status": {
"state": "PENDING",
"stateStartTime": "start-time"
},
"jobUuid": "job-Uuid"
}
Python
- Instalar a biblioteca cliente
- Configurar as credenciais padrão do aplicativo
- Execute o código
- Job do Spark para estimar o valor de pi:
- Job do PySpark para imprimir "hello world":
Ver registros do job
Para conferir o status do job e ajudar a depurar problemas, consulte os registros do driver usando a CLI gcloud ou o console Google Cloud .
gcloud
Os registros do driver do job são transmitidos para a saída da CLI gcloud ou para o consoleGoogle Cloud durante a execução do job. Os registros do driver permanecem em um bucket de preparo do cluster do Dataproc no Cloud Storage.
Execute o seguinte comando da CLI gcloud para listar o local dos registros de driver no Cloud Storage:
gcloud dataproc jobs describe JOB_ID \ --region=REGION
O local dos registros de driver no Cloud Storage é listado como
driverOutputResourceUri na resposta ao comando no seguinte formato:
driverOutputResourceUri: gs://CLUSTER_STAGING_BUCKET/google-cloud-dataproc-metainfo/CLUSTER_UUID/jobs/JOB_ID
Console
Para ver os registros do cluster do grupo de nós:
É possível usar o seguinte formato de consulta do Explorador de registros para encontrar registros:
resource.type="cloud_dataproc_cluster" resource.labels.project_id="PROJECT_ID" resource.labels.cluster_name="CLUSTER_NAME" log_name="projects/PROJECT_ID/logs/LOG_TYPE>"
- PROJECT_ID: Google Cloud ID do projeto.
- CLUSTER_NAME: o nome do cluster.
- LOG_TYPE:
- Registros do usuário do Yarn:
yarn-userlogs - Registros do gerenciador de recursos do Yarn:
hadoop-yarn-resourcemanager - Registros do Node Manager do Yarn:
hadoop-yarn-nodemanager
- Registros do usuário do Yarn:
Monitorar as métricas
Os drivers de job do grupo de nós do Dataproc são executados em uma
fila secundária dataproc-driverpool-driver-queue em uma partição dataproc-driverpool.
Métricas do grupo de nós do driver
A tabela a seguir lista as métricas de driver do grupo de nós associado, que são coletadas por padrão para grupos de nós de driver.
| Métrica do grupo de nós do driver | Descrição |
|---|---|
yarn:ResourceManager:DriverPoolsQueueMetrics:AvailableMB |
A quantidade de memória disponível em mebibytes em
dataproc-driverpool-driver-queue na partição
dataproc-driverpool.
|
yarn:ResourceManager:DriverPoolsQueueMetrics:PendingContainers |
O número de contêineres pendentes (em fila) em dataproc-driverpool-driver-queue na partição dataproc-driverpool. |
Métricas da fila secundária
A tabela a seguir lista as métricas da fila secundária. As métricas são coletadas por padrão para grupos de nós de driver e podem ser ativadas para coleta em qualquer cluster do Dataproc.
| Métrica da fila secundária | Descrição |
|---|---|
yarn:ResourceManager:ChildQueueMetrics:AvailableMB |
A quantidade de memória disponível em mebibytes nessa fila na partição padrão. |
yarn:ResourceManager:ChildQueueMetrics:PendingContainers |
Número de contêineres pendentes (em fila) nesta fila na partição padrão. |
yarn:ResourceManager:ChildQueueMetrics:running_0 |
O número de jobs com um tempo de execução entre 0 e 60 minutos
nesta fila em todas as partições. |
yarn:ResourceManager:ChildQueueMetrics:running_60 |
O número de jobs com um tempo de execução entre 60 e 300 minutos
nesta fila em todas as partições. |
yarn:ResourceManager:ChildQueueMetrics:running_300 |
O número de jobs com um tempo de execução entre 300 e 1440 minutos
nesta fila em todas as partições. |
yarn:ResourceManager:ChildQueueMetrics:running_1440 |
O número de jobs com um tempo de execução maior que 1440 minutos
nesta fila em todas as partições. |
yarn:ResourceManager:ChildQueueMetrics:AppsSubmitted |
Número de aplicativos enviados a essa fila em todas as partições. |
Para conferir YARN ChildQueueMetrics e DriverPoolsQueueMetrics no
console doGoogle Cloud :
Selecione os recursos Instância de VM → Personalizado no Metrics Explorer.
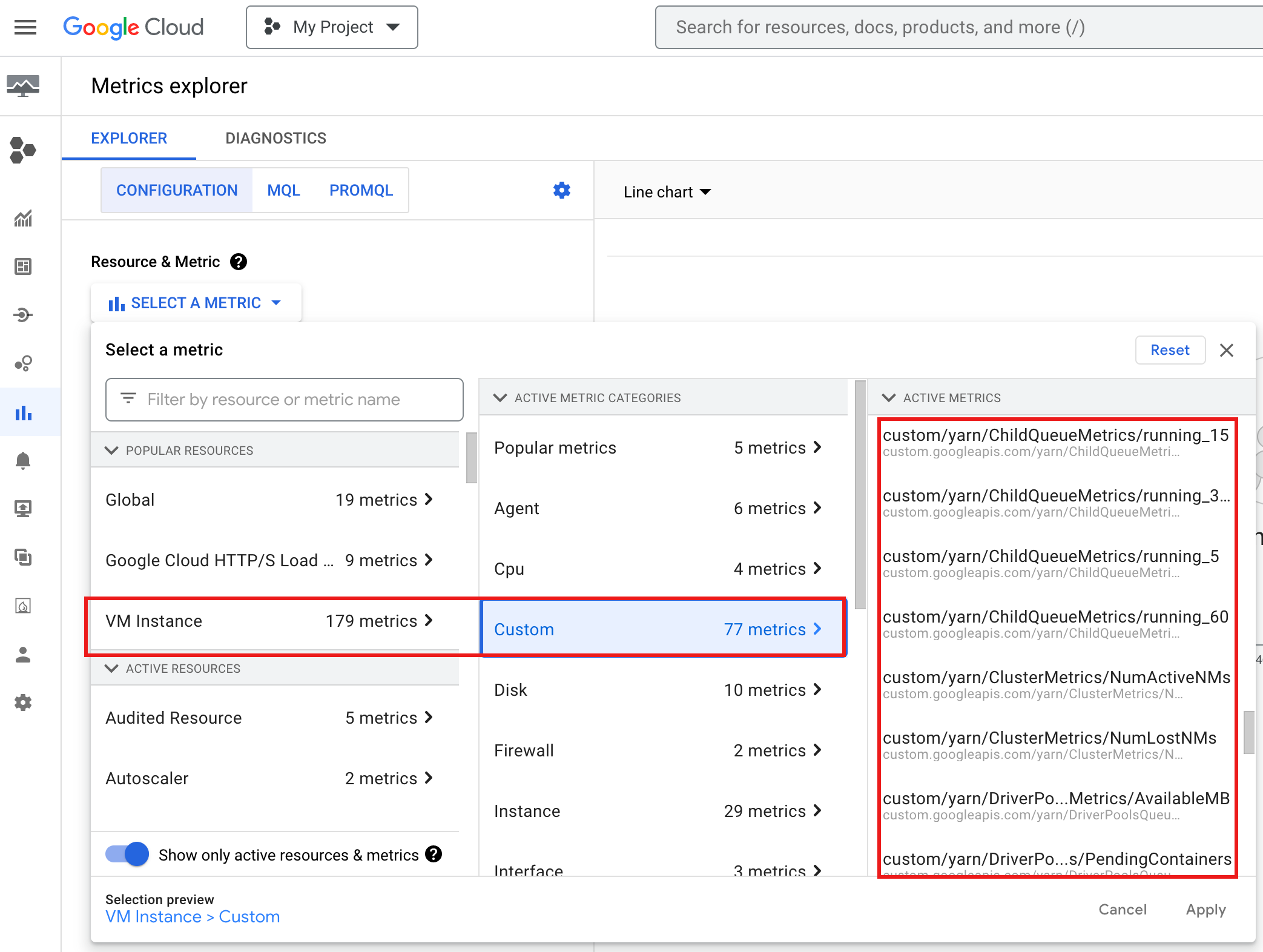
Depurar o driver do job do grupo de nós
Esta seção fornece condições e erros do grupo de nós do driver com recomendações para corrigir a condição ou o erro.
Condições
Condição:
yarn:ResourceManager:DriverPoolsQueueMetrics:AvailableMBestá se aproximando de0. Isso indica que as filas de pools de drivers do cluster estão ficando sem memória.Recomendação: aumente o tamanho da frota de motoristas.
Condição:
yarn:ResourceManager:DriverPoolsQueueMetrics:PendingContainersé maior que 0. Isso pode indicar que as filas de pools de drivers do cluster estão ficando sem memória e que o YARN está enfileirando jobs.Recomendação: aumente o tamanho da frota de motoristas.
Erros
Erro:
Cluster <var>CLUSTER_NAME</var> requires driver scheduling config to run SPARK job because it contains a node pool with role DRIVER. Positive values are required for all driver scheduling config values.Recomendação:defina
driver-required-memory-mbedriver-required-vcorescom números positivos.Erro:
Container exited with a non-zero exit code 137.Recomendação:aumente
driver-required-memory-mbpara o uso de memória do job.