Os registos de tarefas e clusters do Dataproc podem ser vistos, pesquisados, filtrados e arquivados no Cloud Logging.
Consulte os preços do Google Cloud Observability para compreender os seus custos.
Consulte o artigo Períodos de retenção de registos para ver informações sobre a retenção de registos.
Consulte Exclusões de registos para desativar todos os registos ou excluir registos do Registo.
Consulte a vista geral do encaminhamento e armazenamento para encaminhar registos do Logging para o Cloud Storage, BigQuery ou Pub/Sub.
Níveis de registo de componentes
Defina os níveis de registo do Spark, Hadoop, Flink e outros componentes do Dataproc
com propriedades do cluster log4j específicas do componente, como hadoop-log4j, quando cria um cluster. Os níveis de registo de componentes baseados em clusters aplicam-se a daemons de serviços, como o YARN ResourceManager, e a trabalhos executados no cluster.
Se as propriedades log4j não forem suportadas para um componente, como o componente Presto, escreva uma ação de inicialização que edite o ficheiro log4j.properties ou log4j2.properties do componente.
Níveis de registo de componentes específicos da tarefa: também pode definir níveis de registo de componentes quando envia uma tarefa. Estes níveis de registo são aplicados à tarefa e têm precedência sobre os níveis de registo definidos quando criou o cluster. Consulte Propriedades de cluster vs. de tarefa para mais informações.
Níveis de registo da versão do componente Spark e Hive:
Os componentes Spark 3.3.X e Hive 3.X usam propriedades log4j2, enquanto as versões anteriores destes componentes usam propriedades log4j (consulte Apache Log4j2).
Use um prefixo spark-log4j: para definir os níveis de registo do Spark num cluster.
Exemplo: versão 2.0 da imagem do Dataproc com o Spark 3.1 para definir
log4j.logger.org.apache.spark:gcloud dataproc clusters create ... \ --properties spark-log4j:log4j.logger.org.apache.spark=DEBUG
Exemplo: versão 2.1 da imagem do Dataproc com o Spark 3.3 para definir
logger.sparkRoot.level:gcloud dataproc clusters create ...\ --properties spark-log4j:logger.sparkRoot.level=debug
Níveis de registo do controlador de tarefas
O Dataproc usa um nível de registo padrão de INFO para programas de controladores de tarefas. Pode alterar esta definição para um ou mais pacotes com a flag gcloud dataproc jobs submit
--driver-log-levels.
Exemplo:
Defina o nível de registo DEBUG quando enviar uma tarefa do Spark que leia ficheiros do Cloud Storage.
gcloud dataproc jobs submit spark ...\ --driver-log-levels org.apache.spark=DEBUG,com.google.cloud.hadoop.gcsio=DEBUG
Exemplo:
Defina o nível do registador root como WARN e o nível do registador com.example como INFO.
gcloud dataproc jobs submit hadoop ...\ --driver-log-levels root=WARN,com.example=INFO
Níveis de registo do executor do Spark
Para configurar os níveis de registo do executor do Spark:
Prepare um ficheiro de configuração log4j e, em seguida, carregue-o para o Cloud Storage
.Faça referência ao ficheiro de configuração quando enviar a tarefa.
Exemplo:
gcloud dataproc jobs submit spark ...\ --file gs://my-bucket/path/spark-log4j.properties \ --properties spark.executor.extraJavaOptions=-Dlog4j.configuration=file:spark-log4j.properties
O Spark transfere o ficheiro de propriedades do Cloud Storage para o diretório de trabalho local da tarefa, referenciado como file:<name> em -Dlog4j.configuration.
Registos de tarefas do Dataproc no Logging
Consulte o artigo Resultados e registos de tarefas do Dataproc para obter informações sobre como ativar os registos do controlador de tarefas do Dataproc no Logging.
Aceda aos registos de tarefas no registo
Aceda aos registos de tarefas do Dataproc através do Explorador de registos, do comando gcloud logging ou da API Logging.
Consola
Os registos do controlador de tarefas do Dataproc e do contentor YARN são apresentados no recurso Tarefa do Cloud Dataproc.
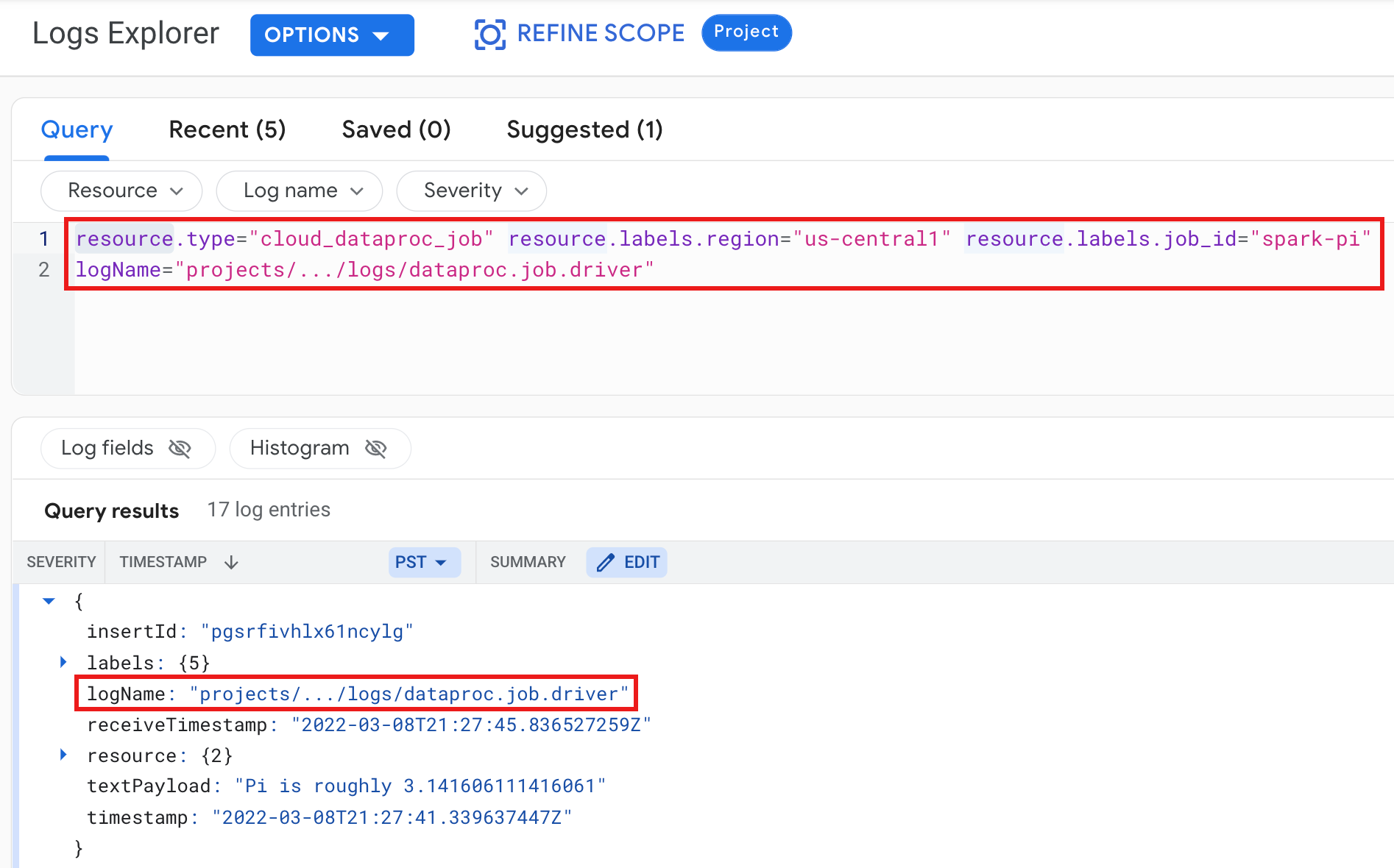
Exemplo: registo de controlador de tarefas após executar uma consulta do Logs Explorer com as seguintes seleções:
- Recurso:
Cloud Dataproc Job - Nome do registo:
dataproc.job.driver
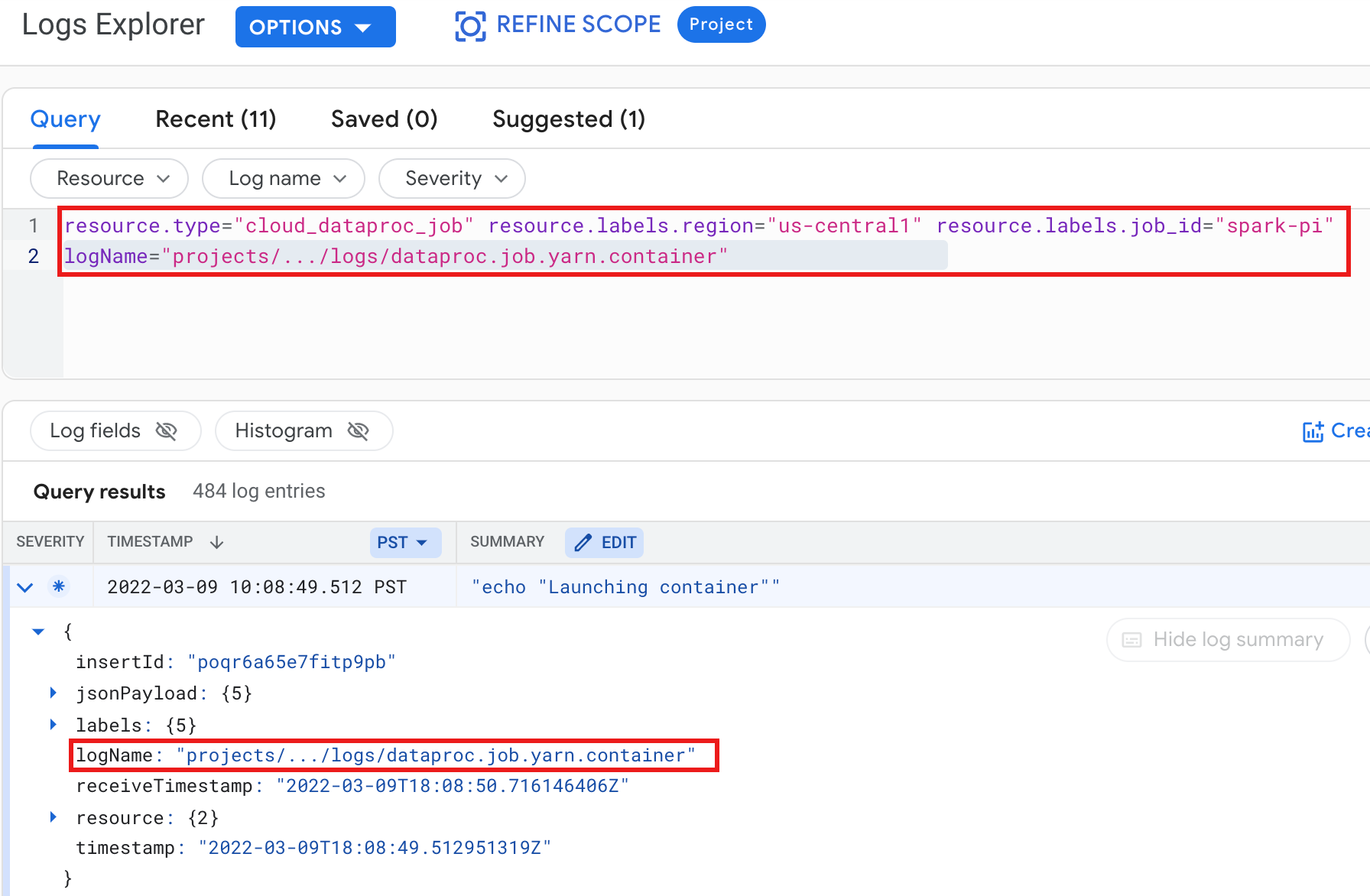
Exemplo: registo do contentor YARN após executar uma consulta do Logs Explorer com as seguintes seleções:
- Recurso:
Cloud Dataproc Job - Nome do registo:
dataproc.job.yarn.container
gcloud
Pode ler as entradas do registo de tarefas com o comando gcloud logging read. Os argumentos de recursos têm de estar entre aspas ("…"). O comando seguinte usa etiquetas de cluster para filtrar as entradas de registo devolvidas.
gcloud logging read \ "resource.type=cloud_dataproc_job \ resource.labels.region=cluster-region \ resource.labels.job_id=my-job-id"
Exemplo de saída (parcial):
jsonPayload: class: org.apache.hadoop.hdfs.StateChange filename: hadoop-hdfs-namenode-test-dataproc-resize-cluster-20190410-38an-m-0.log ,,, logName: projects/project-id/logs/hadoop-hdfs-namenode --- jsonPayload: class: SecurityLogger.org.apache.hadoop.security.authorize.ServiceAuthorizationManager filename: cluster-name-dataproc-resize-cluster-20190410-38an-m-0.log ... logName: projects/google.com:hadoop-cloud-dev/logs/hadoop-hdfs-namenode
API REST
Pode usar a API REST Logging para listar entradas de registo (consulte entries.list).
Registos de clusters do Dataproc no Logging
O Dataproc exporta os seguintes registos do Apache Hadoop, Spark, Hive, Zookeeper e outros registos de clusters do Dataproc para o Cloud Logging.
| Tipo de registo | Nome do registo | Descrição | Notas |
|---|---|---|---|
| Registos do daemon principal | hadoop-hdfs hadoop-hdfs-namenode hadoop-hdfs-secondarynamenode hadoop-hdfs-zkfc hadoop-yarn-resourcemanager hadoop-yarn-timelineserver hive-metastore hive-server2 mapred-mapred-historyserver zookeeper |
Journal node HDFS namenode HDFS secondary namenode Zookeeper failover controller YARN resource manager YARN timeline server Hive metastore Hive server2 Mapreduce job history server Zookeeper server |
|
| Registos do daemon do trabalhador |
hadoop-hdfs-datanode hadoop-yarn-nodemanager |
HDFS datanode YARN nodemanager |
|
| Registos de sistema |
autoscaler google.dataproc.agent google.dataproc.startup |
Registo do escalador automático do Dataproc Registo do agente do Dataproc Registo do script de arranque do Dataproc + registo da ação de inicialização |
|
| Registos alargados (adicionais) |
knox gateway-audit zeppelin ranger-usersync jupyter_notebook jupyter_kernel_gateway spark-history-server |
Todos os registos nos subdiretórios /var/log/ que correspondem a:knox (inclui gateway-audit.log) zeppelin ranger-usersync jupyter_notebook jupyter_kernel_gateway spark-history-server |
A definição da propriedade
dataproc:dataproc.logging.extended.enabled=false desativa a recolha de registos alargados no cluster
|
| Syslogs da VM |
syslog |
Syslogs dos nós principais e trabalhadores do cluster |
A definição da propriedade
dataproc:dataproc.logging.syslog.enabled=false desativa a recolha de syslogs da VM no cluster
|
Aceda aos registos de clusters no Cloud Logging
Pode aceder aos registos do cluster do Dataproc através do Explorador de registos, do comando gcloud logging ou da API Logging.
Consola
Faça as seguintes seleções de consultas para ver os registos de clusters no Explorador de registos:
- Recurso:
Cloud Dataproc Cluster - Nome do registo: log name
gcloud
Pode ler as entradas do registo do cluster com o comando gcloud logging read. Os argumentos de recursos têm de estar entre aspas ("…"). O comando seguinte usa etiquetas de cluster para filtrar as entradas de registo devolvidas.
gcloud logging read <<'EOF' "resource.type=cloud_dataproc_cluster resource.labels.region=cluster-region resource.labels.cluster_name=cluster-name resource.labels.cluster_uuid=cluster-uuid" EOF
Exemplo de saída (parcial):
jsonPayload: class: org.apache.hadoop.yarn.server.resourcemanager.ResourceTrackerService filename: hadoop-yarn-resourcemanager-cluster-name-m.log ... logName: projects/project-id/logs/hadoop-yarn-resourcemanager --- jsonPayload: class: org.apache.hadoop.yarn.server.resourcemanager.ResourceTrackerService filename: hadoop-yarn-resourcemanager-component-gateway-cluster-m.log ... logName: projects/project-id/logs/hadoop-yarn-resourcemanager
API REST
Pode usar a API REST Logging para listar entradas de registo (consulte entries.list).
Autorizações
Para escrever registos no Logging, a conta de serviço da VM do Dataproc tem de ter a função do IAM logging.logWriter. A conta de serviço do Dataproc predefinida tem esta função. Se usar
uma conta de serviço personalizada,
tem de atribuir esta função à conta de serviço.
Proteger os registos
Por predefinição, os registos no Logging são encriptados em repouso. Pode ativar as chaves de encriptação geridas pelo cliente (CMEK) para encriptar os registos. Para mais informações sobre o suporte de CMEK, consulte os artigos Faça a gestão das chaves que protegem os dados do Log Router e Faça a gestão das chaves que protegem os dados de armazenamento do Logging.
O que se segue?
- Explore a observabilidade do Google Cloud.