Cloud Logging에서 Dataproc 작업 및 클러스터 로그를 보고, 검색하고, 필터링하고, 보관 처리할 수 있습니다.
비용을 알아보려면 Google Cloud Observability 가격 책정을 참조하세요.
로깅 보관에 대한 자세한 내용은 로그 보관 기간을 참조하세요.
모든 로그를 사용 중지하거나 로깅에서 로그를 제외하려면 로그 제외를 참조하세요.
Logging에서 Cloud Storage, BigQuery 또는 Pub/Sub로 로그를 라우팅하려면 라우팅 및 스토리지 개요를 참조하세요.
구성요소 로깅 수준
클러스터를 만들 때 구성요소별 log4j 클러스터 속성(예: hadoop-log4j)을 사용하여 Spark, Hadoop, Flink, 기타 Dataproc 구성요소 로깅 수준을 설정합니다. 클러스터 기반 구성요소 로깅 수준은 YARN ResourceManager와 같은 서비스 데몬과 클러스터에서 실행되는 작업에 적용됩니다.
log4j 속성이 Presto와 같은 구성요소에 지원되지 않으면 구성요소의 log4j.properties 또는 log4j2.properties 파일을 수정하는 초기화 작업을 작성합니다.
작업별 구성요소 로깅 수준: 작업을 제출할 때 구성요소 로깅 수준도 설정할 수 있습니다. 이러한 로깅 수준은 작업에 적용되며 클러스터를 만들 때 설정된 로깅 수준보다 우선합니다. 자세한 내용은 클러스터와 작업 속성 비교를 참조하세요.
Spark 및 Hive 구성요소 버전 로깅 수준:
Spark 3.3.X 및 Hive 3.X 구성요소는 log4j2 속성을 사용하고 이전 버전의 구성요소는 log4j 속성을 사용합니다(Apache Log4j2 참조).
spark-log4j: 프리픽스를 사용하여 클러스터에서 Spark 로깅 수준을 설정합니다.
예시: Spark 3.1을 사용해
log4j.logger.org.apache.spark를 설정하는 Dataproc 이미지 버전 2.0gcloud dataproc clusters create ... \ --properties spark-log4j:log4j.logger.org.apache.spark=DEBUG
예시: Spark 3.3을 사용해
logger.sparkRoot.level을 설정하는 Dataproc 이미지 버전 2.1gcloud dataproc clusters create ...\ --properties spark-log4j:logger.sparkRoot.level=debug
작업 드라이버 로깅 수준
Dataproc은 작업 드라이버 프로그램에 INFO의 기본 로깅 수준을 사용합니다. gcloud dataproc jobs submit --driver-log-levels 플래그를 사용해서 하나 이상의 패키지에 대해 이 설정을 변경할 수 있습니다.
예시:
Cloud Storage 파일을 읽는 Spark 작업을 제출할 때 DEBUG 로깅 수준을 설정합니다.
gcloud dataproc jobs submit spark ...\ --driver-log-levels org.apache.spark=DEBUG,com.google.cloud.hadoop.gcsio=DEBUG
예시:
root 로거 수준을 WARN으로, com.example 로거 수준을 INFO로 설정합니다.
gcloud dataproc jobs submit hadoop ...\ --driver-log-levels root=WARN,com.example=INFO
Spark 실행자 로깅 수준
Spark 실행자 로깅 수준을 구성하려면 다음 안내를 따르세요.
log4j 구성 파일을 준비한 다음 Cloud Storage에 업로드합니다.
.작업을 제출할 때 구성 파일을 참조합니다.
예시:
gcloud dataproc jobs submit spark ...\ --file gs://my-bucket/path/spark-log4j.properties \ --properties spark.executor.extraJavaOptions=-Dlog4j.configuration=file:spark-log4j.properties
Spark는 Cloud Storage 속성 파일을 -Dlog4j.configuration에서 file:<name>으로 참조되는 작업의 로컬 작업 디렉터리에 다운로드합니다.
로깅의 Dataproc 작업 로그
Logging에서 Dataproc 작업 드라이버 로그를 사용 설정하는 방법은 Dataproc 작업 출력 및 로그를 참조하세요.
Logging에서 작업 로그 액세스
로그 탐색기, gcloud logging 명령어, Logging API를 사용하여 Dataproc 작업 로그에 액세스합니다.
콘솔
Dataproc 작업 드라이버 및 YARN 컨테이너 로그는 Cloud Dataproc 작업 리소스 아래에 나열됩니다.
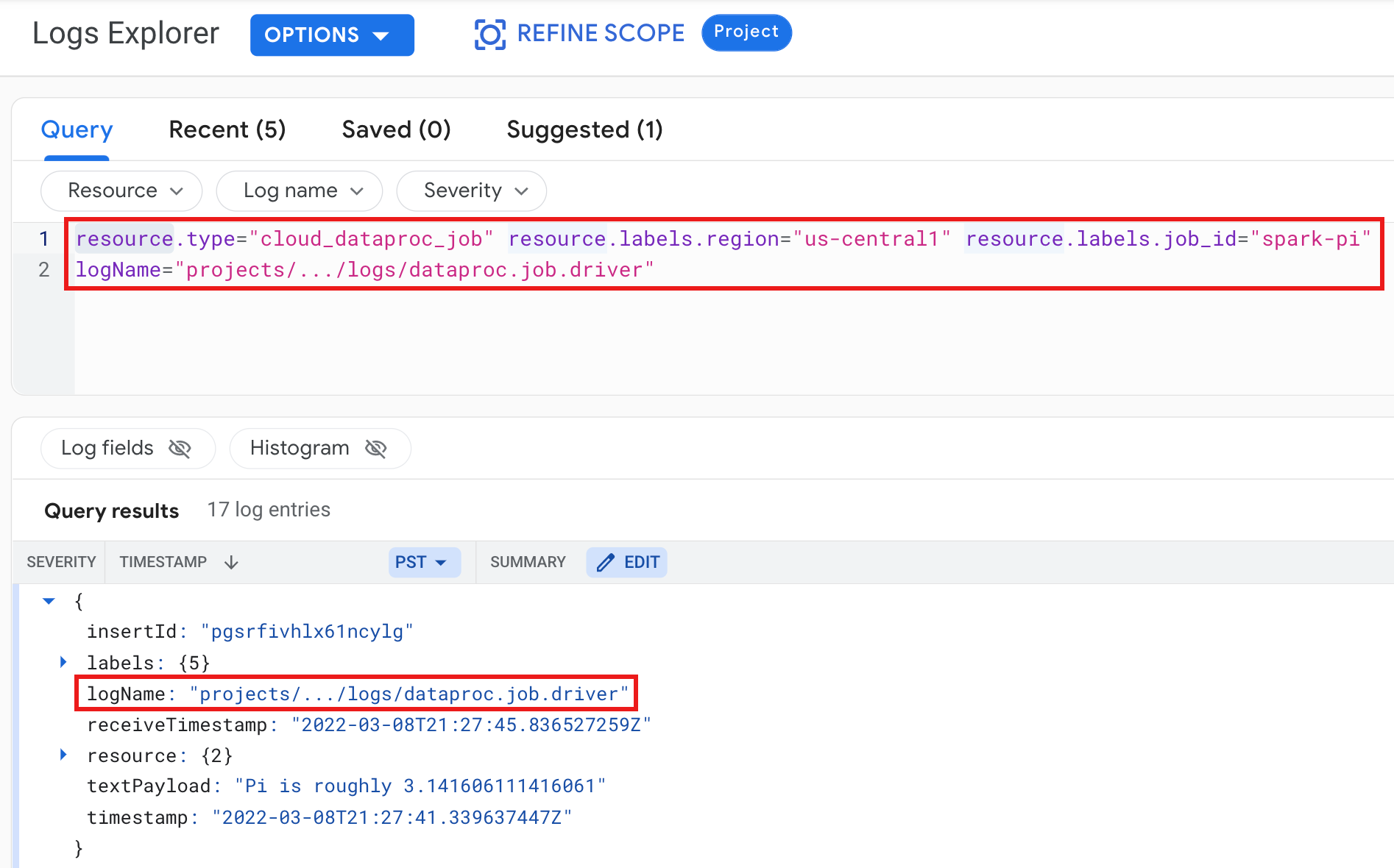
예시: 다음 항목을 선택하여 로그 탐색기 쿼리를 실행한 후의 작업 드라이버 로그
- 리소스:
Cloud Dataproc Job - 로그 이름:
dataproc.job.driver
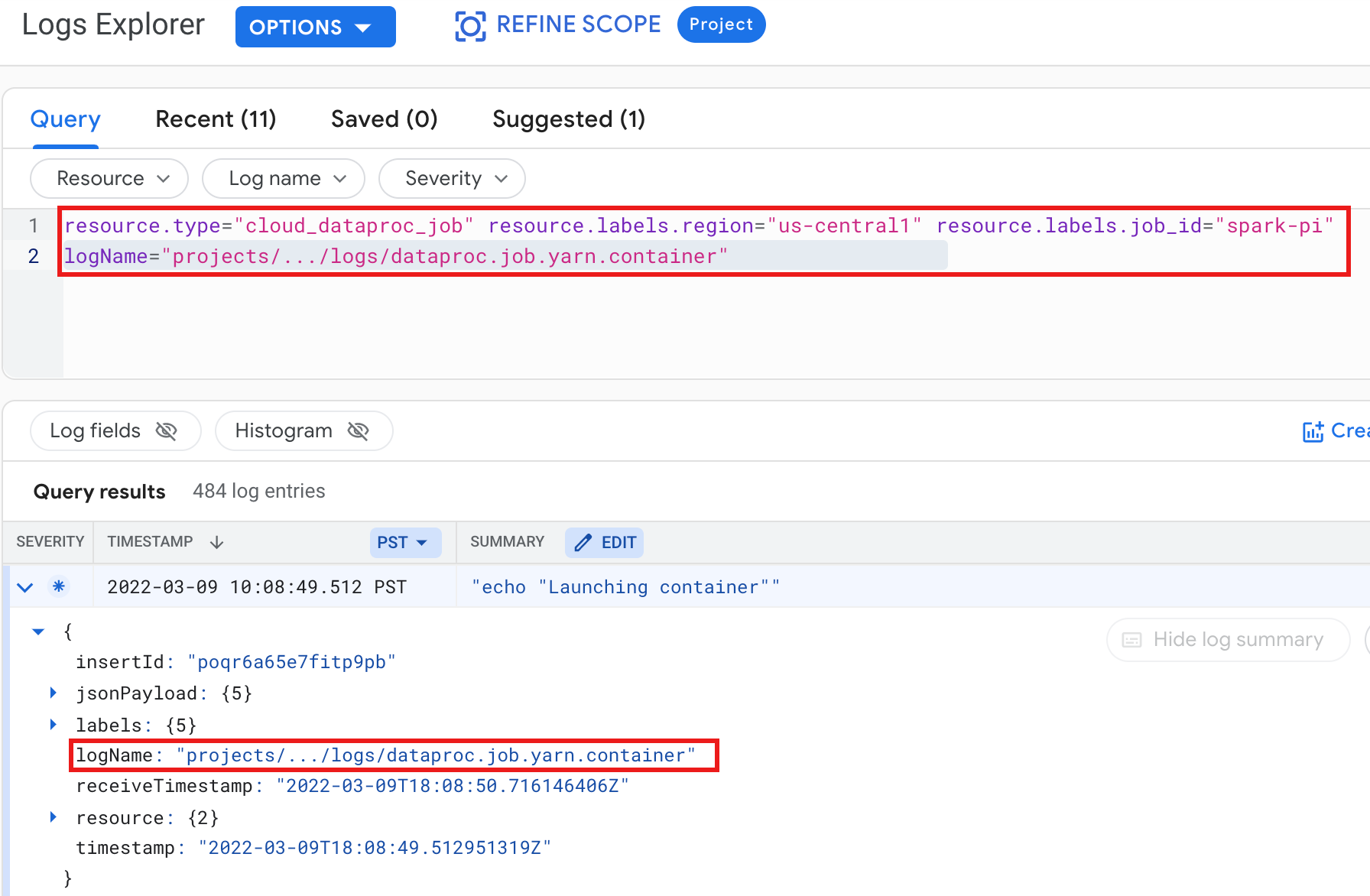
예시: 다음 선택 항목으로 로그 탐색기 쿼리를 실행한 후 YARN 컨테이너 로그
- 리소스:
Cloud Dataproc Job - 로그 이름:
dataproc.job.yarn.container
gcloud
gcloud 로깅 읽기 명령어를 사용하여 작업 로그 항목을 읽을 수 있습니다. 리소스 인수는 따옴표로 묶어야 합니다("..."). 다음 명령어는 클러스터 라벨을 사용하여 반환된 로그 항목을 필터링합니다.
gcloud logging read \ "resource.type=cloud_dataproc_job \ resource.labels.region=cluster-region \ resource.labels.job_id=my-job-id"
샘플 출력(부분):
jsonPayload: class: org.apache.hadoop.hdfs.StateChange filename: hadoop-hdfs-namenode-test-dataproc-resize-cluster-20190410-38an-m-0.log ,,, logName: projects/project-id/logs/hadoop-hdfs-namenode --- jsonPayload: class: SecurityLogger.org.apache.hadoop.security.authorize.ServiceAuthorizationManager filename: cluster-name-dataproc-resize-cluster-20190410-38an-m-0.log ... logName: projects/google.com:hadoop-cloud-dev/logs/hadoop-hdfs-namenode
REST API
Logging REST API를 사용하여 로그 항목을 나열할 수 있습니다(entries.list 참조).
로깅의 Dataproc 클러스터 로그
Dataproc은 다음 Apache Hadoop, Spark, Hive, Zookeeper, 기타 Dataproc 클러스터 로그를 Cloud Logging으로 내보냅니다.
| 로그 유형 | 로그 이름 | 설명 |
|---|---|---|
| 마스터 데몬 로그 | hadoop-hdfs hadoop-hdfs-namenode hadoop-hdfs-secondary namenode hadoop-hdfs-zkfc hadoop-yarn-resourcemanager hadoop-yarn-timelineserver hive-metastore hive-server2 mapred-mapred-historyserver zookeeper |
저널 노드 HDFS 이름 노드 HDFS 보조 이름 노드 Zookeeper 장애 조치 컨트롤러 YARN 리소스 관리자 YARN 타임라인 서버 Hive metastore Hive 서버2 맵리듀스 작업 기록 서버 Zookeeper 서버 |
| 작업자 데몬 로그 |
hadoop-hdfs-datanode hadoop-yarn-nodemanager |
HDFS 데이터 노드 YARN 노드 관리자 |
| 시스템 로그 |
autoscaler google.dataproc.agent google.dataproc.startup |
Dataproc 자동 확장 처리 로그 Dataproc 에이전트 로그 Dataproc 시작 스크립트 로그 + 초기화 작업 로그 |
| 확장(추가) 로그 |
knox gateway-audit zeppelin ranger-usersync jupyter_notebook jupyter_kernel_gateway spark-history-server |
다음과 일치하는 /var/log/ 하위 디렉터리 내의 모든 로그:knox(gateway-audit.log 포함) zeppelin ranger-usersync jupyter_notebook jupyter_kernel_gateway spark-history-server |
| VM syslog |
syslog |
클러스터의 마스터 및 작업자 노드의 syslog |
Cloud Logging에서 클러스터 로그 액세스
로그 탐색기, gcloud logging 명령어 또는 Logging API를 사용하여 Dataproc 클러스터 로그에 액세스할 수 있습니다.
콘솔
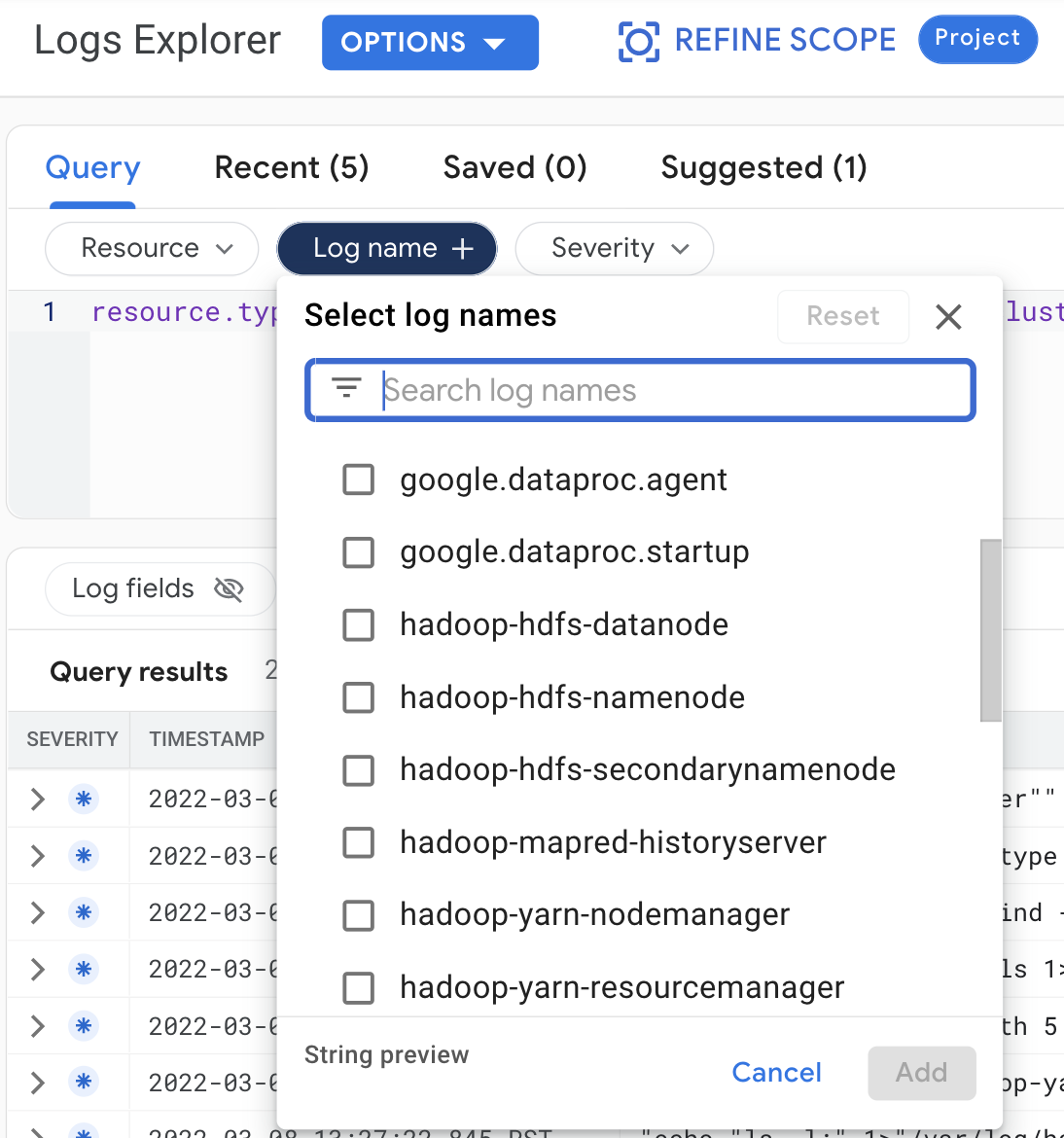
로그 탐색기에서 클러스터 로그를 보려면 다음 쿼리를 선택합니다.
- 리소스:
Cloud Dataproc Cluster - 로그 이름: log name
gcloud
gcloud 로깅 읽기 명령어를 사용하여 클러스터 로그 항목을 읽을 수 있습니다. 리소스 인수는 따옴표로 묶어야 합니다("..."). 다음 명령어는 클러스터 라벨을 사용하여 반환된 로그 항목을 필터링합니다.
gcloud logging read <<'EOF' "resource.type=cloud_dataproc_cluster resource.labels.region=cluster-region resource.labels.cluster_name=cluster-name resource.labels.cluster_uuid=cluster-uuid" EOF
샘플 출력(부분):
jsonPayload: class: org.apache.hadoop.yarn.server.resourcemanager.ResourceTrackerService filename: hadoop-yarn-resourcemanager-cluster-name-m.log ... logName: projects/project-id/logs/hadoop-yarn-resourcemanager --- jsonPayload: class: org.apache.hadoop.yarn.server.resourcemanager.ResourceTrackerService filename: hadoop-yarn-resourcemanager-component-gateway-cluster-m.log ... logName: projects/project-id/logs/hadoop-yarn-resourcemanager
REST API
Logging REST API를 사용하여 로그 항목을 나열할 수 있습니다(entries.list 참조).
권한
Logging에 로그를 작성하려면 Dataproc VM 서비스 계정에 logging.logWriter IAM 역할이 있어야 합니다. 기본 Dataproc 서비스 계정에 이 역할이 있습니다. 커스텀 서비스 계정을 사용하는 경우 이 역할을 서비스 계정에 할당해야 합니다.
로그 보호
기본적으로 Logging의 로그는 암호화됩니다. 고객 관리 암호화 키(CMEK)를 사용 설정하여 로그를 암호화할 수 있습니다. CMEK 지원에 대한 자세한 내용은 로그 라우터 데이터를 보호하는 키 관리 및 Logging 스토리지 데이터를 보호하는 키 관리를 참조하세요.