您可以在 Cloud Logging 中查看、搜索、过滤和归档 Dataproc 作业和集群日志。
如需了解费用,请参阅 Google Cloud Observability 价格。
如需了解日志保留,请参阅日志保留期限。
如需停用所有日志或从 Logging 中排除日志,请参阅日志排除。
如需将日志从 Logging 路由到 Cloud Storage、BigQuery 或 Pub/Sub,请参阅路由和存储概览。
组件日志记录级别
在创建集群时,使用组件特有的 log4j 集群属性(例如 hadoop-log4j)设置 Spark、Hadoop、Flink 和其他 Dataproc 组件日志记录级别。基于集群的组件日志记录级别适用于服务守护程序(例如 YARN ResourceManager)以及在集群上运行的作业。
如果某个组件(例如 Presto 组件)不支持 log4j 属性,请编写一个初始化操作来修改该组件的 log4j.properties 或 log4j2.properties 文件。
作业特有的组件日志记录级别:您还可以在提交作业时设置组件日志记录级别。这些日志记录级别会应用于作业,并优先于您在创建集群时设置的日志记录级别。如需了解详情,请参阅集群与作业属性。
Spark 和 Hive 组件版本日志记录级别:
Spark 3.3.X 和 Hive 3.X 组件使用 log4j2 属性,而这些组件的先前版本使用 log4j 属性(请参阅 Apache Log4j2)。使用 spark-log4j: 前缀可在集群上设置 Spark 日志记录级别。
示例:Spark 3.1 设置为
log4j.logger.org.apache.spark的 Dataproc 映像版本 2.0:gcloud dataproc clusters create ... \ --properties spark-log4j:log4j.logger.org.apache.spark=DEBUG
示例:Spark 3.3 设置为
logger.sparkRoot.level的 Dataproc 映像版本 2.1:gcloud dataproc clusters create ...\ --properties spark-log4j:logger.sparkRoot.level=debug
作业驱动程序日志记录级别
Dataproc 为作业驱动程序使用默认日志记录级别 INFO。您可以使用 gcloud dataproc jobs submit --driver-log-levels 标志为一个或多个软件包更改此设置。
示例:
在提交读取 Cloud Storage 文件的 Spark 作业时设置 DEBUG 日志记录级别。
gcloud dataproc jobs submit spark ...\ --driver-log-levels org.apache.spark=DEBUG,com.google.cloud.hadoop.gcsio=DEBUG
示例:
将 root 日志记录器级别设置为 WARN,将 com.example 日志记录器级别设置为 INFO。
gcloud dataproc jobs submit hadoop ...\ --driver-log-levels root=WARN,com.example=INFO
Spark 执行器日志记录级别
如需配置 Spark 执行器日志记录级别,请执行以下操作:
准备 log4j 配置文件,然后将其上传到 Cloud Storage
。提交作业时,引用您的配置文件。
示例:
gcloud dataproc jobs submit spark ...\ --file gs://my-bucket/path/spark-log4j.properties \ --properties spark.executor.extraJavaOptions=-Dlog4j.configuration=file:spark-log4j.properties
Spark 将 Cloud Storage 属性文件下载到作业的本地工作目录(在 -Dlog4j.configuration 中引用为 file:<name>)。
Logging 中的 Dataproc 作业日志
如需了解如何在 Logging 中启用 Dataproc 作业驱动程序日志,请参阅 Dataproc 作业输出和日志。
访问 Logging 中的作业日志
使用 Logs Explorer、gcloud logging 命令或 Logging API 访问 Dataproc 作业日志。
控制台
Dataproc 作业驱动程序日志和 YARN 容器日志列在 Cloud Dataproc 作业资源下。
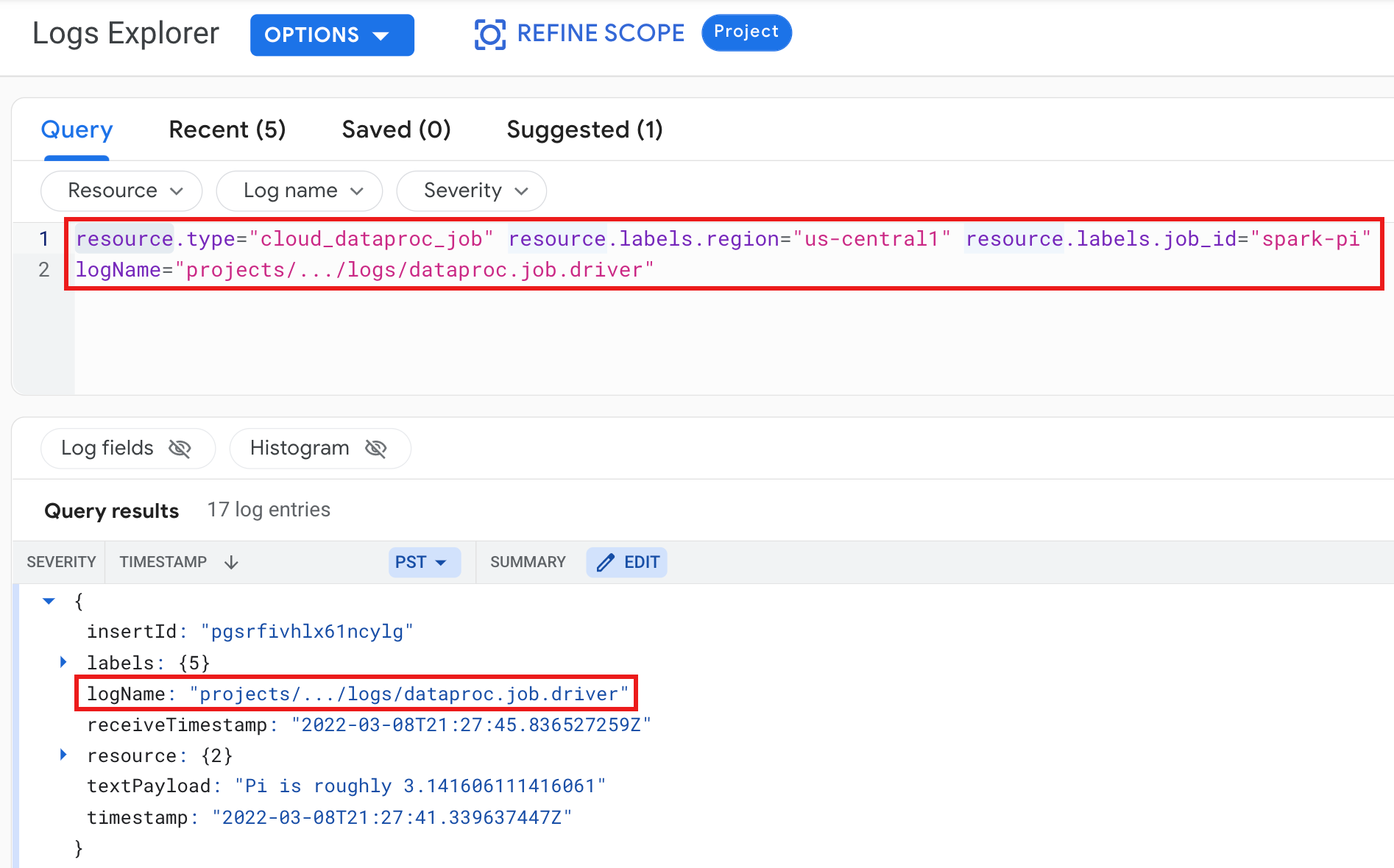
示例:运行选择了以下内容的 Logs Explorer 查询后的作业驱动程序日志:
- 资源:
Cloud Dataproc Job - 日志名称:
dataproc.job.driver
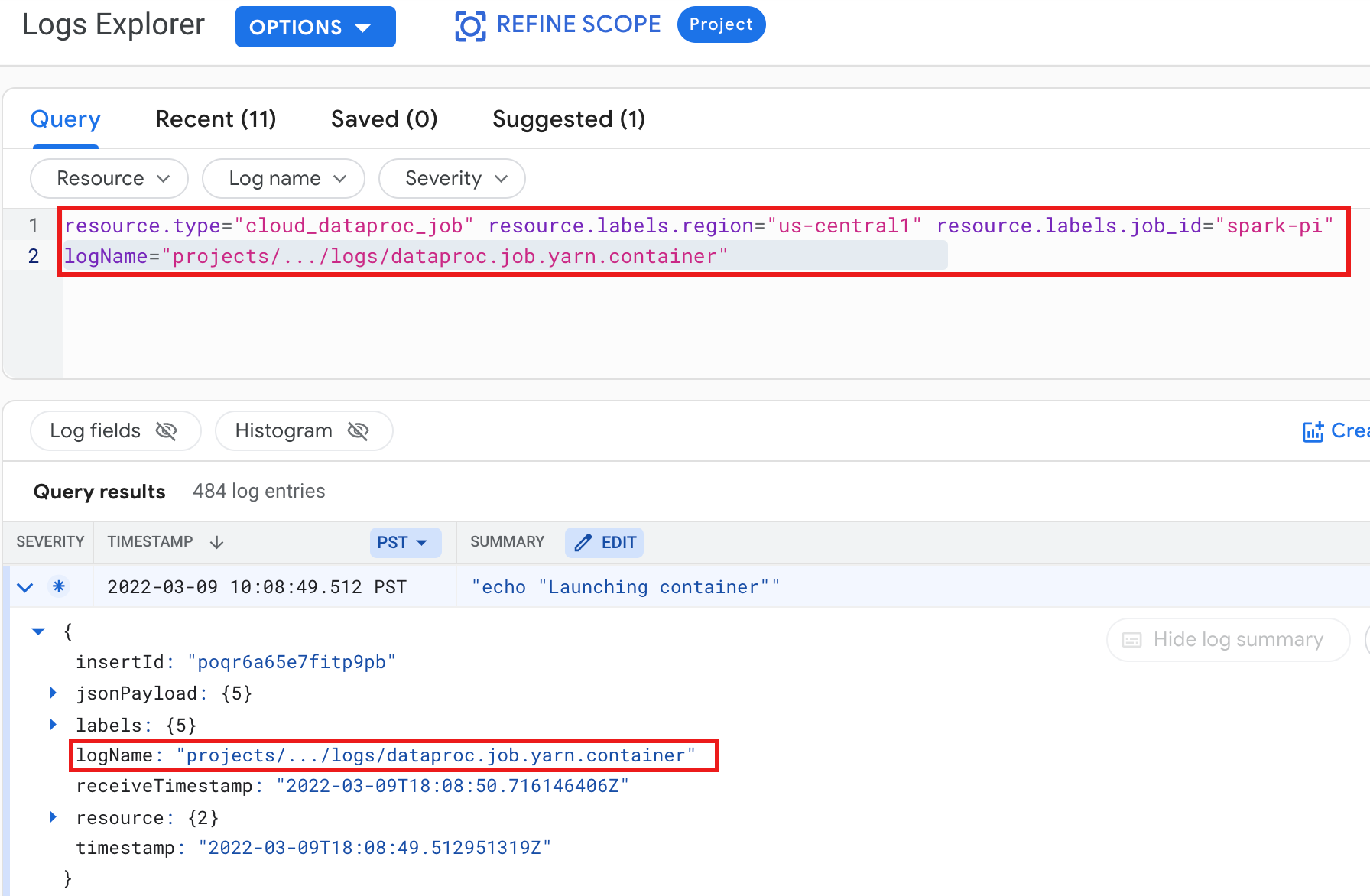
示例:运行选择了以下内容的 Logs Explorer 查询后的 YARN 容器日志:
- 资源:
Cloud Dataproc Job - 日志名称:
dataproc.job.yarn.container
gcloud
您可以使用 gcloud logging read 命令来读取作业日志条目。资源参数必须括在英文引号 ("...") 中。 以下命令使用集群标签来过滤返回的日志条目。
gcloud logging read \ "resource.type=cloud_dataproc_job \ resource.labels.region=cluster-region \ resource.labels.job_id=my-job-id"
示例输出(部分):
jsonPayload: class: org.apache.hadoop.hdfs.StateChange filename: hadoop-hdfs-namenode-test-dataproc-resize-cluster-20190410-38an-m-0.log ,,, logName: projects/project-id/logs/hadoop-hdfs-namenode --- jsonPayload: class: SecurityLogger.org.apache.hadoop.security.authorize.ServiceAuthorizationManager filename: cluster-name-dataproc-resize-cluster-20190410-38an-m-0.log ... logName: projects/google.com:hadoop-cloud-dev/logs/hadoop-hdfs-namenode
REST API
您可以使用 Logging REST API 列出日志条目(请参阅 entries.list)。
Logging 中的 Dataproc 集群日志
Dataproc 会将以下 Apache Hadoop、Spark、Hive、Zookeeper 和其他 Dataproc 集群日志导出到 Cloud Logging。
| 日志类型 | 日志名称 | 说明 | 备注 |
|---|---|---|---|
| 主守护进程日志 | hadoop-hdfs hadoop-hdfs-namenode hadoop-hdfs-secondarynamenode hadoop-hdfs-zkfc hadoop-yarn-resourcemanager hadoop-yarn-timelineserver hive-metastore hive-server2 mapred-mapred-historyserver zookeeper |
日志节点 HDFS 名称节点 HDFS 辅助名称节点 Zookeeper 故障切换控制器 YARN 资源管理器 YARN 时间轴服务器 Hive metastore Hive server2 Mapreduce 作业历史记录服务器 Zookeeper 服务器 |
|
| 工作器守护进程日志 |
hadoop-hdfs-datanode hadoop-yarn-nodemanager |
HDFS 数据节点 YARN 节点管理器 |
|
| 系统日志 |
autoscaler google.dataproc.agent google.dataproc.startup |
Dataproc 自动调节程序日志 Dataproc 代理日志 Dataproc 启动脚本日志 + 初始化操作日志 |
|
| 扩展(其他)日志 |
knox gateway-audit zeppelin ranger-usersync jupyter_notebook jupyter_kernel_gateway spark-history-server |
/var/log/ 子目录中与以下各项匹配的所有日志:knox(包括 gateway-audit.log) zeppelin ranger-usersync jupyter_notebook jupyter_kernel_gateway spark-history-server |
设置
dataproc:dataproc.logging.extended.enabled=false 属性会停用集群上的扩展日志收集功能
|
| 虚拟机 syslog |
syslog |
来自集群主节点和工作器节点的 Syslog |
设置
dataproc:dataproc.logging.syslog.enabled=false 属性会停用集群上虚拟机Syslog的收集功能
|
访问 Cloud Logging 中的集群日志
您可以使用 Logs Explorer、gcloud logging 命令或 Logging API 访问 Dataproc 集群日志。
控制台
如需在 Logs Explorer 中查看集群日志,请进行以下查询选择:
- 资源:
Cloud Dataproc Cluster - 日志名称:log name
gcloud
您可以使用 gcloud logging read 命令来读取集群日志条目。资源参数必须括在英文引号 ("...") 中。 以下命令使用集群标签来过滤返回的日志条目。
gcloud logging read <<'EOF' "resource.type=cloud_dataproc_cluster resource.labels.region=cluster-region resource.labels.cluster_name=cluster-name resource.labels.cluster_uuid=cluster-uuid" EOF
示例输出(部分):
jsonPayload: class: org.apache.hadoop.yarn.server.resourcemanager.ResourceTrackerService filename: hadoop-yarn-resourcemanager-cluster-name-m.log ... logName: projects/project-id/logs/hadoop-yarn-resourcemanager --- jsonPayload: class: org.apache.hadoop.yarn.server.resourcemanager.ResourceTrackerService filename: hadoop-yarn-resourcemanager-component-gateway-cluster-m.log ... logName: projects/project-id/logs/hadoop-yarn-resourcemanager
REST API
您可以使用 Logging REST API 列出日志条目(请参阅 entries.list)。
权限
如需将日志写入 Logging,Dataproc 虚拟机服务账号必须具有 logging.logWriter IAM 角色。默认 Dataproc 服务账号具有此角色。如果使用自定义服务账号,则您必须将此角色分配给该服务账号。
保护日志
默认情况下,Logging 中的日志会经过静态加密。您可以启用客户管理的加密密钥 (CMEK) 来加密日志。如需详细了解 CMEK 支持,请参阅管理用于保护日志路由器数据的密钥和管理用于保护 Logging 存储数据的密钥。