Quando você usa o serviço do Dataproc para criar clusters e executar jobs neles, o serviço configura as permissões e os papéis do Dataproc necessários no projeto para acessar e usar os recursos do Google Cloud de que ele precisa para realizar essas tarefas. No entanto, se fizer um trabalho entre projetos, por exemplo, para acessar dados em outro projeto, você precisará configurar os papéis e as permissões necessários para acessar recursos entre projetos.
Para ajudar no trabalho entre projetos, este documento lista os diferentes principais que usam o serviço Dataproc e os papéis que contêm as permissões necessárias para que eles acessem e usem os recursos do Google Cloud .
Há três principais (identidades) que acessam e usam o Dataproc:
- Identidade do usuário
- Identidade do plano de controle
Identidade do plano de dados
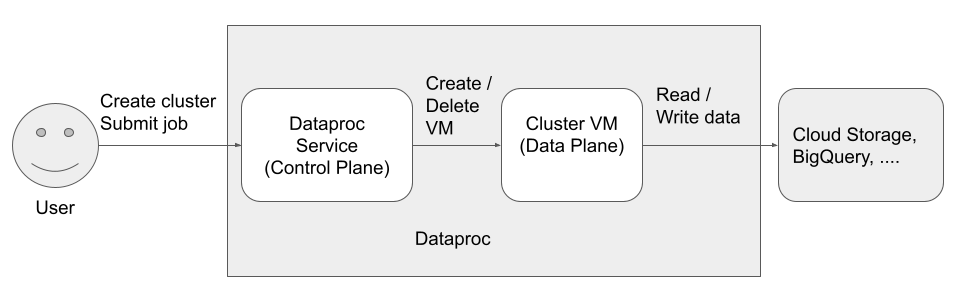
Usuário da API Dataproc (identidade do usuário)
Exemplo: username@example.com
Esse é o usuário que chama o serviço Dataproc para criar clusters, enviar jobs e fazer outras solicitações ao serviço. O usuário costuma ser um indivíduo, mas também pode ser uma conta de serviço caso o Dataproc seja invocado por meio de um cliente da API ou de outroGoogle Cloud serviço, como Compute Engine, funções do Cloud Run ou Cloud Composer.
Funções relacionadas
Observações
- Os jobs enviados pela API Dataproc são executados como
rootno Linux. Os clusters do Dataproc herdam os metadados SSH do Compute Engine em todo o projeto, a menos que sejam explicitamente bloqueados definindo
--metadata=block-project-ssh-keys=trueao criar o cluster. Consulte Metadados do cluster.Os diretórios de usuários do HDFS são criados para cada usuário SSH no nível do projeto. Esses diretórios HDFS são criados no momento da implantação do cluster, e um novo usuário SSH (pós-implantação) não recebe um diretório HDFS em clusters existentes.
Agente de serviço do Dataproc (identidade do plano de controle)
Exemplo: service-project-number@dataproc-accounts.iam.gserviceaccount.com
A conta de serviço do agente de serviço do Dataproc é usada para executar um amplo conjunto de operações do sistema em recursos localizados no projeto em que um cluster do Dataproc é criado, incluindo:
- criar recursos do Compute Engine, inclusive instâncias de VM, grupos de instâncias e modelos de instâncias.
getelistoperações para confirmar a configuração de recursos, como imagens, firewalls, ações de inicialização do Dataproc e buckets do Cloud Storage- a criação automática dos buckets temporários e de preparo do Dataproc se o bucket de preparo ou temporário não for especificado pelo usuário;
- gravar metadados de configuração do cluster no bucket de preparo;
- Como acessar redes VPC em um projeto host
Funções relacionadas
Conta de serviço da VM do Dataproc (identidade do plano de dados)
Exemplo: project-number-compute@developer.gserviceaccount.com
O código do aplicativo é executado como a conta de serviço da VM nas VMs do Dataproc. Os jobs do usuário recebem os papéis (com as permissões associadas) dessa conta de serviço.
A conta de serviço da VM faz o seguinte:
- se comunica com o plano de controle do Dataproc;
- Lê e grava dados de e para os buckets temporários e de preparo do Dataproc.
- Conforme necessário para os jobs do Dataproc, lê e grava dados de e para o Cloud Storage, o BigQuery, o Cloud Logging e outros recursos Google Cloud .
Funções relacionadas
A seguir
- Saiba mais sobre papéis e permissões do Dataproc.
- Saiba mais sobre as contas de serviço do Dataproc.
- Consulte Controle de acesso do BigQuery.
- Consulte Opções de controle de acesso do Cloud Storage.