Puoi creare un avviso di Monitoring che ti avvisa quando una metrica di un cluster o di un job Dataproc supera una soglia specificata.
Crea un avviso
Apri la pagina Avvisi nella console Google Cloud .
Fai clic su + Crea policy per aprire la pagina Crea policy di avviso.
- Fai clic su Seleziona metrica.
- Nella casella di input "Filtra in base al nome della risorsa o della metrica", digita "dataproc" per elencare le metriche Dataproc. Naviga nella gerarchia delle metriche di Cloud Dataproc per selezionare una metrica di cluster, job, batch o sessione.
- Fai clic su Applica.
- Fai clic su Avanti per aprire il riquadro Configura trigger di avviso.
- Imposta un valore soglia per attivare l'avviso.
- Fai clic su Avanti per aprire il riquadro Configurare le notifiche e finalizzare l'avviso.
- Imposta i canali di notifica, la documentazione e il nome della policy di avviso.
- Fai clic su Avanti per esaminare il criterio di avviso.
- Fai clic su Crea policy per creare l'avviso.
Avvisi di esempio
Questa sezione descrive un avviso di esempio per un job inviato al servizio Dataproc e un avviso per un job eseguito come applicazione YARN.
Avviso relativo al job di Dataproc a lunga esecuzione
Dataproc emette la metrica dataproc.googleapis.com/job/state,
che monitora il tempo trascorso da un job in stati diversi. Questa metrica si trova
in Metrics Explorer della console Google Cloud nella risorsa Job Cloud Dataproc
(cloud_dataproc_job).
Puoi utilizzare questa metrica per configurare un avviso che ti avvisa quando lo stato RUNNING del job supera una soglia di durata.

Configurazione dell'avviso di durata del job
Questo esempio utilizza Monitoring Query Language (MQL) per creare una policy di avviso (vedi Creazione di policy di avviso MQL (console)).
fetch cloud_dataproc_job
| metric 'dataproc.googleapis.com/job/state'
| filter metric.state == 'RUNNING'
| group_by [resource.job_id, metric.state], 1m
| condition val() == true()
Nell'esempio seguente, l'avviso viene attivato quando un job è in esecuzione da più di 30 minuti.

Puoi modificare la query filtrando in base a resource.job_id per applicarla
a un job specifico:
fetch cloud_dataproc_job
| metric 'dataproc.googleapis.com/job/state'
| filter (resource.job_id == '1234567890') && (metric.state == 'RUNNING')
| group_by [resource.job_id, metric.state], 1m
| condition val() == true()
Avviso relativo all'applicazione YARN a lunga esecuzione
L'esempio precedente mostra un avviso attivato quando un job Dataproc viene eseguito più a lungo
di una durata specificata, ma si applica solo ai job inviati al servizio Dataproc
utilizzando la console, la Google Cloud CLI o chiamate dirette all'API
Dataproc jobs. Google Cloud Puoi anche utilizzare le metriche OSS
per configurare avvisi simili che monitorano il tempo di esecuzione delle applicazioni YARN.
Innanzitutto, un po' di contesto. YARN emette metriche del tempo di esecuzione in più bucket.
Per impostazione predefinita, YARN mantiene 60, 300 e 1440 minuti come soglie dei bucket
ed emette 4 metriche: running_0, running_60, running_300 e running_1440:
running_0registra il numero di job con un tempo di esecuzione compreso tra 0 e 60 minuti.running_60registra il numero di job con un runtime compreso tra 60 e 300 minuti.running_300registra il numero di job con un runtime compreso tra 300 e 1440 minuti.running_1440registra il numero di job con un runtime superiore a 1440 minuti.
Ad esempio, un job in esecuzione per 72 minuti verrà registrato in running_60, ma non in running_0.
Queste soglie predefinite dei bucket possono essere modificate passando nuovi valori alla
yarn:yarn.resourcemanager.metrics.runtime.buckets
proprietà cluster
durante la creazione del cluster Dataproc. Quando definisci le soglie dei bucket personalizzati,
devi anche definire gli override delle metriche. Ad esempio, per specificare le soglie dei bucket
di 30, 60 e 90 minuti, il comando gcloud dataproc clusters create
deve includere i seguenti flag:
soglie dei bucket:
‑‑properties=yarn:yarn.resourcemanager.metrics.runtime.buckets=30,60,90override delle metriche:
‑‑metric-overrides=yarn:ResourceManager:QueueMetrics:running_0, yarn:ResourceManager:QueueMetrics:running_30,yarn:ResourceManager:QueueMetrics:running_60, yarn:ResourceManager:QueueMetrics:running_90
Comando di creazione del cluster di esempio
gcloud dataproc clusters create test-cluster \ --properties ^#^yarn:yarn.resourcemanager.metrics.runtime.buckets=30,60,90 \ --metric-sources=yarn \ --metric-overrides=yarn:ResourceManager:QueueMetrics:running_0,yarn:ResourceManager:QueueMetrics:running_30,yarn:ResourceManager:QueueMetrics:running_60,yarn:ResourceManager:QueueMetrics:running_90
Queste metriche sono elencate in Metrics Explorer della console Google Cloud nella risorsa Istanza VM (gce_instance).
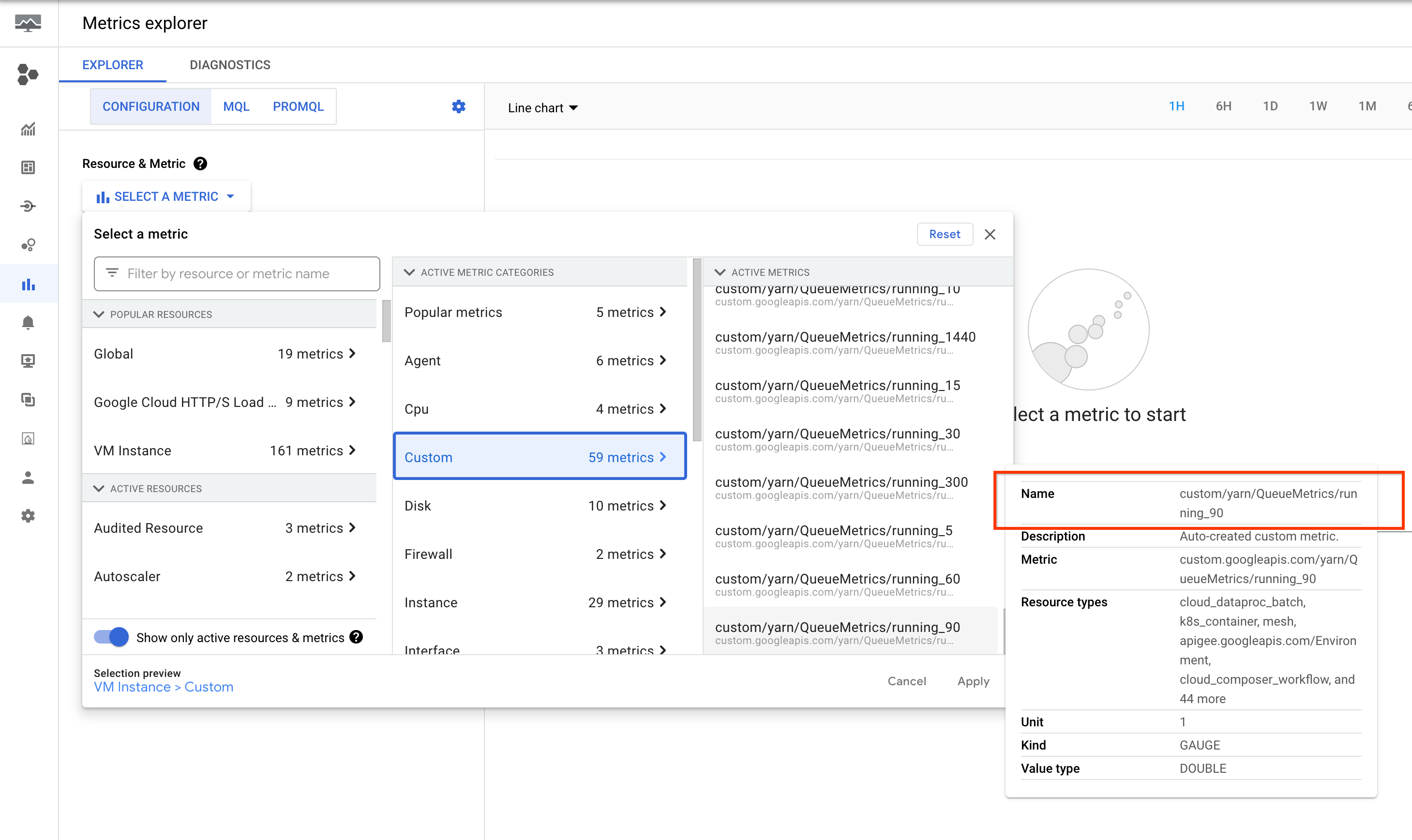
Configurazione degli avvisi per le applicazioni YARN
Crea un cluster con i bucket e le metriche richiesti abilitati .
Crea una policy di avviso che si attiva quando il numero di applicazioni in un bucket di metriche YARN supera una soglia specificata.
(Facoltativo) Aggiungi un filtro per generare avvisi sui cluster che corrispondono a un pattern.

Configura la soglia per l'attivazione dell'avviso.
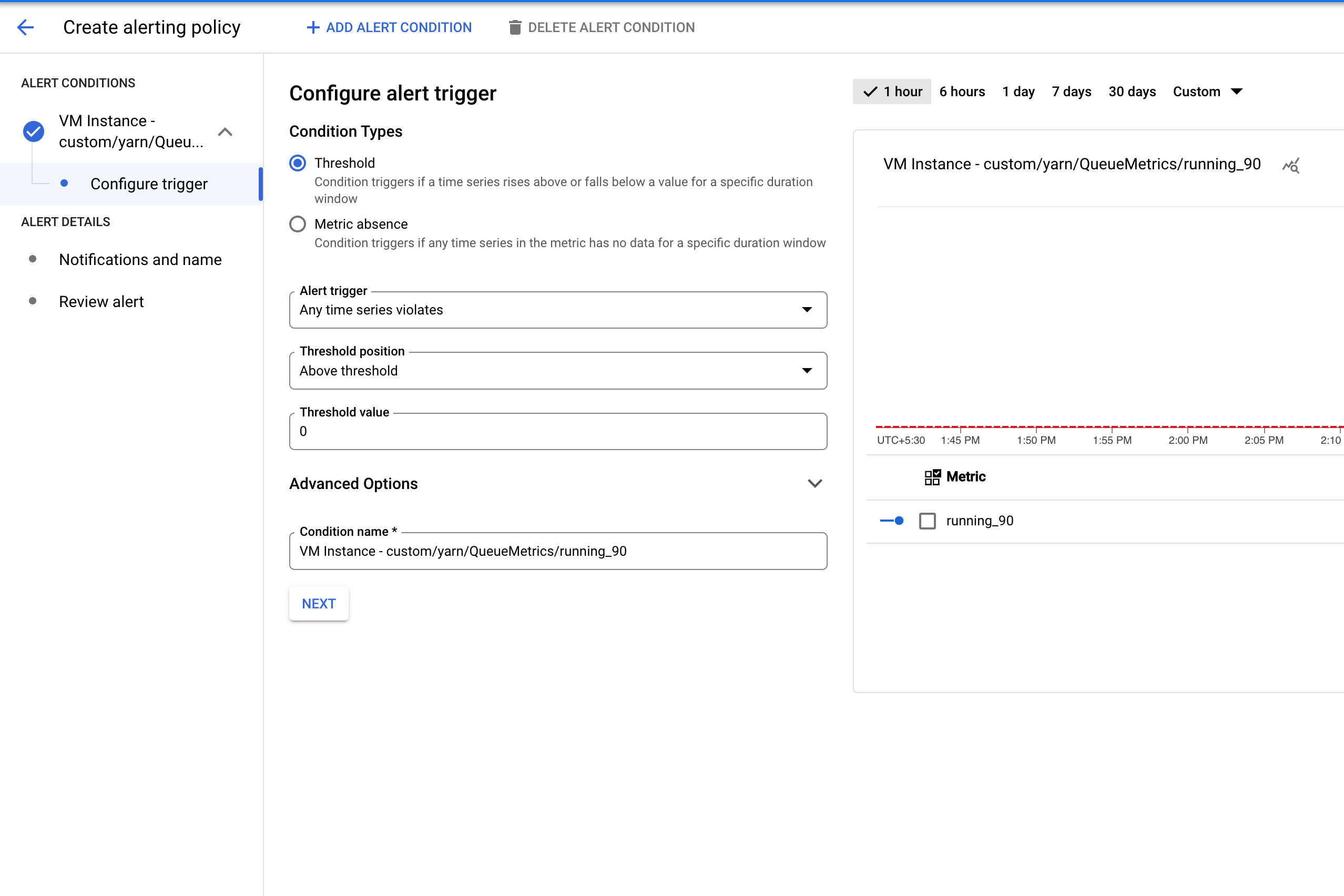
Avviso di job Dataproc non riuscito
Puoi anche utilizzare la metrica dataproc.googleapis.com/job/state
(vedi Avviso relativo ai job Dataproc di lunga durata)
per ricevere un avviso quando un job Dataproc non va a buon fine.
Configurazione dell'avviso di nuove offerte non riuscita
Questo esempio utilizza Monitoring Query Language (MQL) per creare una policy di avviso (vedi Creazione di policy di avviso MQL (console)).
Avviso MQL
fetch cloud_dataproc_job
| metric 'dataproc.googleapis.com/job/state'
| filter metric.state == 'ERROR'
| group_by [resource.job_id, metric.state], 1m
| condition val() == true()
Configurazione del trigger di avviso
Nell'esempio seguente, l'avviso viene attivato quando un job Dataproc non va a buon fine nel tuo progetto.

Puoi modificare la query filtrando in base a resource.job_id per applicarla
a un job specifico:
fetch cloud_dataproc_job
| metric 'dataproc.googleapis.com/job/state'
| filter (resource.job_id == '1234567890') && (metric.state == 'ERROR')
| group_by [resource.job_id, metric.state], 1m
| condition val() == true()
Avviso di deviazione della capacità del cluster
Dataproc emette la metrica dataproc.googleapis.com/cluster/capacity_deviation, che indica la differenza tra il numero di nodi previsto nel cluster e il numero di nodi YARN attivi. Puoi trovare questa metrica in
Esplora metriche della consoleGoogle Cloud nella sezione
Cluster Cloud Dataproc. Puoi utilizzare questa metrica per creare un avviso che ti avvisa quando la capacità del cluster si discosta dalla capacità prevista per un periodo di tempo superiore a una durata di soglia specificata.

Le seguenti operazioni possono causare una sottostima temporanea dei nodi del cluster
nella metrica capacity_deviation. Per evitare falsi positivi, imposta
la soglia di avviso della metrica in modo da tenere conto di queste operazioni:
Creazione e aggiornamenti del cluster: la metrica
capacity_deviationnon viene emessa durante le operazioni di creazione o aggiornamento del cluster.Azioni di inizializzazione del cluster: le azioni di inizializzazione vengono eseguite dopo il provisioning di un nodo.
Aggiornamenti dei worker secondari:i worker secondari vengono aggiunti in modo asincrono al termine dell'operazione di aggiornamento.
Configurazione dell'avviso di deviazione della capacità
Questo esempio utilizza il Monitoring Query Language (MQL) per creare una policy di avviso.
fetch cloud_dataproc_cluster
| metric 'dataproc.googleapis.com/cluster/capacity_deviation'
| every 1m
| condition val() <> 0 '1'
Nell'esempio successivo, l'avviso viene attivato quando la deviazione della capacità del cluster è diversa da zero per più di 30 minuti.

Visualizza avvisi
Quando una condizione di soglia metrica attiva un avviso, Monitoring crea un incidente e un evento corrispondente. Puoi visualizzare gli incidenti dalla pagina Avvisi di Monitoring nella console Google Cloud .
Se hai definito un meccanismo di notifica nella policy di avviso, ad esempio una notifica via email o SMS, Monitoring invia una notifica dell'incidente.
Passaggi successivi
- Consulta la pagina Introduzione agli avvisi.