É possível criar um alerta do Monitoring para notificar quando a métrica de um job ou cluster do Dataproc ultrapassar um limite especificado.
Criar um alerta
Abra a página Alertas no console do Google Cloud .
Clique em + Criar política para abrir a página Criar política de alertas.
- Clique em Selecionar métrica.
- Na caixa de entrada "Filtrar por nome do recurso ou da métrica", digite "dataproc" para listar as métricas do Dataproc. Navegue pela hierarquia de métricas do Cloud Dataproc para selecionar uma métrica de cluster, job, lote ou sessão.
- Clique em Aplicar.
- Clique em Próxima para abrir o painel Configurar o gatilho de alertas.
- Defina um valor limite para acionar o alerta.
- Clique em Próxima para abrir o painel Configurar notificações e finalizar o alerta.
- Defina canais de notificação, documentação e o nome da política de alertas.
- Clique em Próxima para revisar a política de alertas.
- Clique em Criar política para criar o alerta.
Exemplos de alertas
Nesta seção, descrevemos um alerta de exemplo para um job enviado ao serviço do Dataproc e um alerta para um job executado como um aplicativo YARN.
Alerta de job do Dataproc de longa duração
O Dataproc emite a métrica dataproc.googleapis.com/job/state, que rastreia há quanto tempo um job está em diferentes estados. Essa métrica está no Metrics Explorer do console Google Cloud , no recurso Job do Cloud Dataproc (cloud_dataproc_job).
Use essa métrica para configurar um alerta que notifique você quando o estado RUNNING do job exceder um limite de duração.
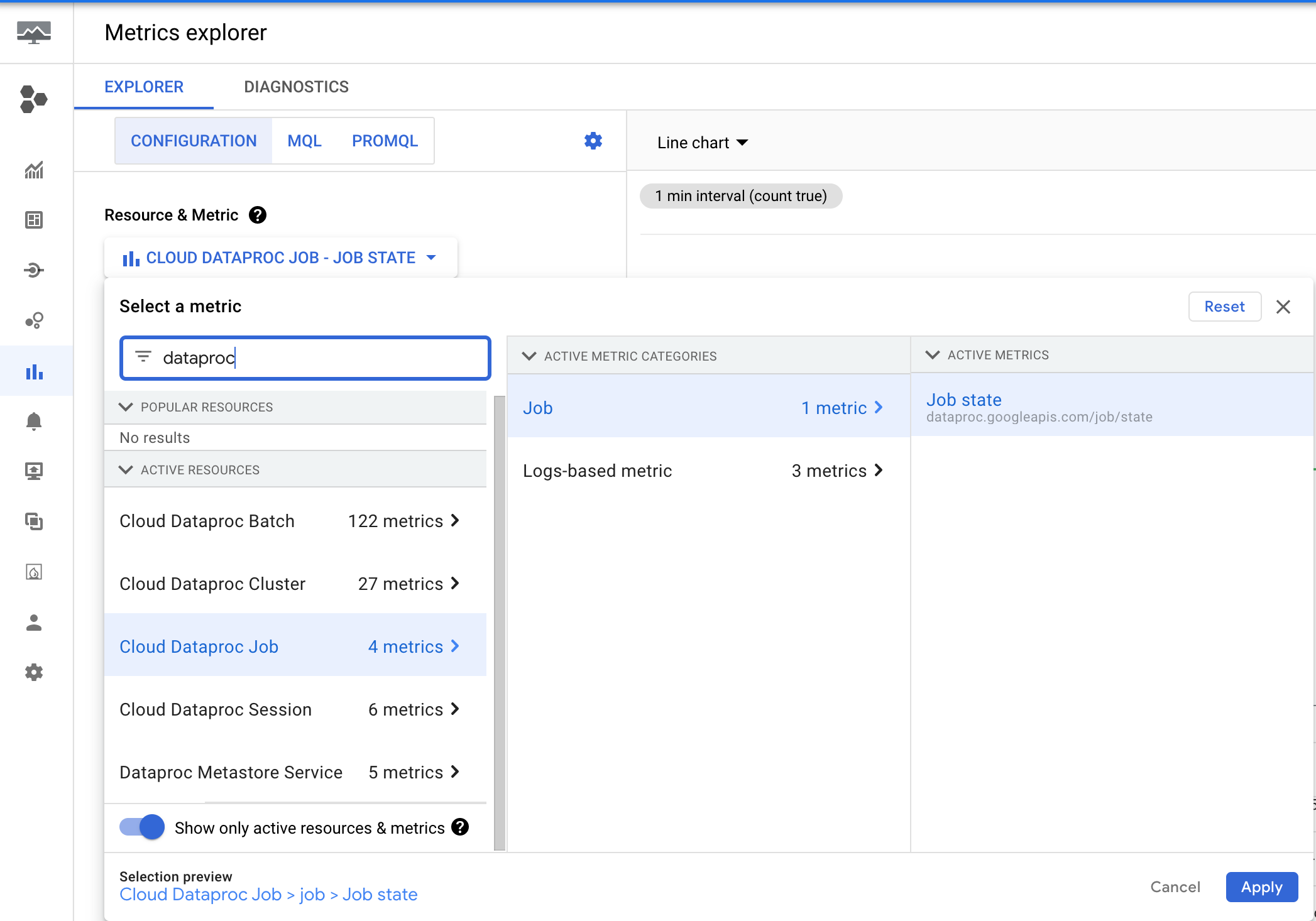
Configuração de alerta de duração do job
Este exemplo usa a linguagem de consulta do Monitoring (MQL) para criar uma política de alertas. Consulte Como criar políticas de alertas da MQL (console).
fetch cloud_dataproc_job
| metric 'dataproc.googleapis.com/job/state'
| filter metric.state == 'RUNNING'
| group_by [resource.job_id, metric.state], 1m
| condition val() == true()
No exemplo a seguir, o alerta é acionado quando um job está em execução há mais de 30 minutos.

Para modificar a consulta, filtre por resource.job_id e aplique a um job específico:
fetch cloud_dataproc_job
| metric 'dataproc.googleapis.com/job/state'
| filter (resource.job_id == '1234567890') && (metric.state == 'RUNNING')
| group_by [resource.job_id, metric.state], 1m
| condition val() == true()
Alerta de aplicativo YARN de longa duração
O exemplo anterior mostra um alerta que é acionado quando um job do Dataproc é executado por mais tempo do que uma duração especificada, mas ele só se aplica a jobs enviados ao serviço do Dataproc usando o console Google Cloud , a Google Cloud CLI ou chamadas diretas à API jobs do Dataproc. Também é possível usar métricas de OSS
para configurar alertas semelhantes que monitoram o tempo de execução de aplicativos YARN.
Primeiro, um pouco de contexto. O YARN emite métricas de tempo de execução em vários grupos.
Por padrão, o YARN mantém 60, 300 e 1440 minutos como limites de bucket e emite quatro métricas: running_0, running_60, running_300 e running_1440:
running_0registra o número de jobs com um tempo de execução entre 0 e 60 minutos.running_60registra o número de jobs com um tempo de execução entre 60 e 300 minutos.running_300registra o número de jobs com um tempo de execução entre 300 e 1.440 minutos.running_1440registra o número de jobs com um tempo de execução maior que 1.440 minutos.
Por exemplo, um job executado por 72 minutos será registrado em running_60, mas não em running_0.
Esses limites padrão de intervalos podem ser modificados transmitindo novos valores para a
yarn:yarn.resourcemanager.metrics.runtime.buckets
propriedade do cluster
durante a criação do cluster do Dataproc. Ao definir limites de intervalos personalizados, você também precisa definir substituições de métricas. Por exemplo, para especificar limites de bucket de 30, 60 e 90 minutos, o comando gcloud dataproc clusters create precisa incluir as seguintes flags:
limites de bucket:
‑‑properties=yarn:yarn.resourcemanager.metrics.runtime.buckets=30,60,90substituições de métricas:
‑‑metric-overrides=yarn:ResourceManager:QueueMetrics:running_0, yarn:ResourceManager:QueueMetrics:running_30,yarn:ResourceManager:QueueMetrics:running_60, yarn:ResourceManager:QueueMetrics:running_90
Exemplo de comando de criação de cluster
gcloud dataproc clusters create test-cluster \ --properties ^#^yarn:yarn.resourcemanager.metrics.runtime.buckets=30,60,90 \ --metric-sources=yarn \ --metric-overrides=yarn:ResourceManager:QueueMetrics:running_0,yarn:ResourceManager:QueueMetrics:running_30,yarn:ResourceManager:QueueMetrics:running_60,yarn:ResourceManager:QueueMetrics:running_90
Essas métricas estão listadas no Metrics Explorer do console Google Cloud no recurso Instância de VM (gce_instance).

Configuração de alertas de aplicativos YARN
Crie um cluster com os intervalos e as métricas necessários ativados .
Crie uma política de alertas que seja acionada quando o número de aplicativos em um bucket de métricas do YARN exceder um limite especificado.
Se quiser, adicione um filtro para gerar alertas sobre clusters que correspondem a um padrão.
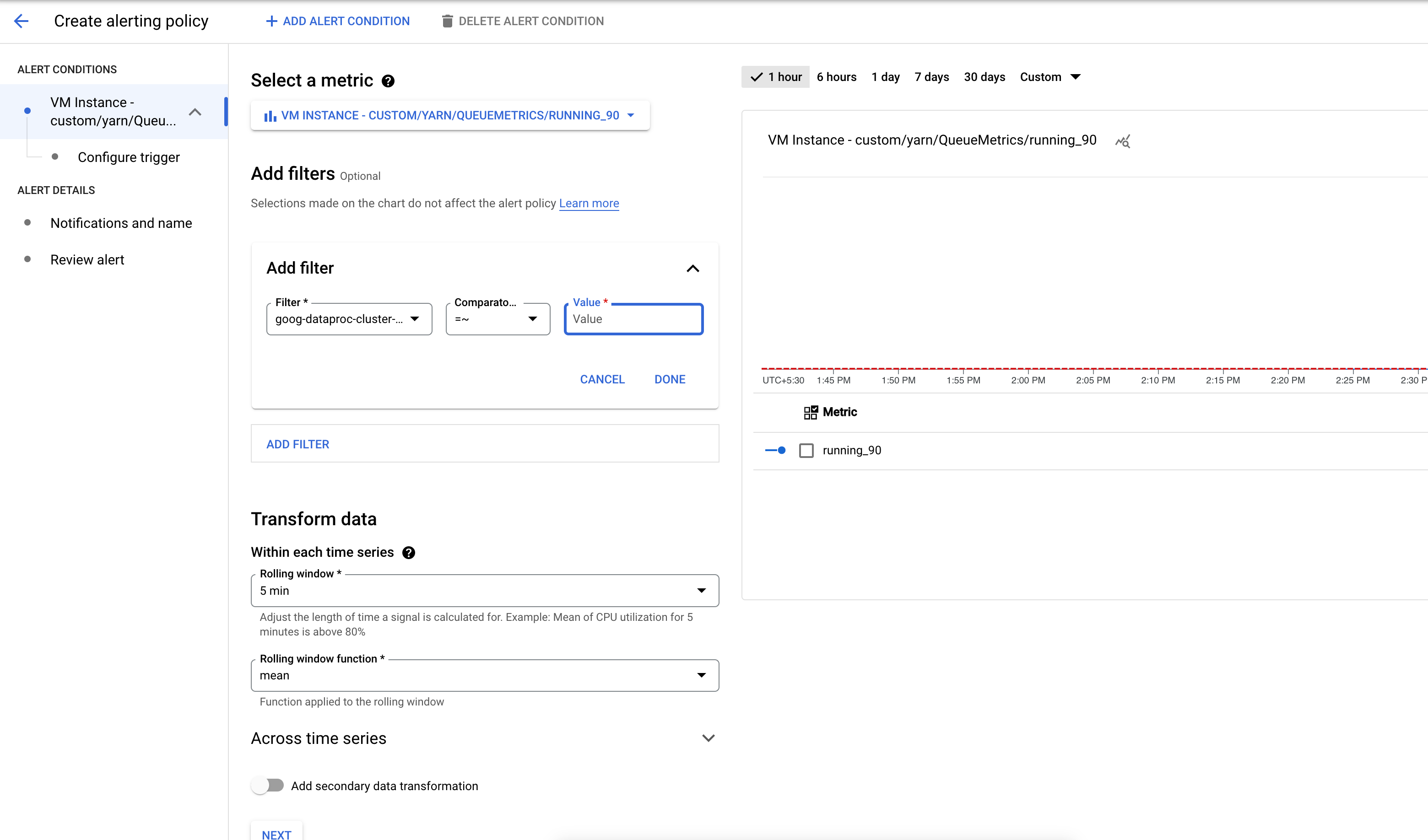
Configure o limite para acionar o alerta.

Alerta de falha em jobs do Dataproc
Também é possível usar a métrica dataproc.googleapis.com/job/state (consulte Alerta de job do Dataproc de longa duração) para alertar quando um job do Dataproc falhar.
Falha na configuração do alerta de vagas
Este exemplo usa a linguagem de consulta do Monitoring (MQL) para criar uma política de alertas. Consulte Como criar políticas de alertas da MQL (console).
Alerta MQL
fetch cloud_dataproc_job
| metric 'dataproc.googleapis.com/job/state'
| filter metric.state == 'ERROR'
| group_by [resource.job_id, metric.state], 1m
| condition val() == true()
Configuração do gatilho de alerta
No exemplo a seguir, o alerta é acionado quando um job do Dataproc falha no seu projeto.

Para modificar a consulta, filtre por resource.job_id e aplique a um job específico:
fetch cloud_dataproc_job
| metric 'dataproc.googleapis.com/job/state'
| filter (resource.job_id == '1234567890') && (metric.state == 'ERROR')
| group_by [resource.job_id, metric.state], 1m
| condition val() == true()
Alerta de desvio de capacidade do cluster
O Dataproc emite a métrica dataproc.googleapis.com/cluster/capacity_deviation, que informa a diferença entre a contagem de nós esperada no cluster e a contagem de nós ativos do YARN. Você pode encontrar essa métrica no
Google Cloud console Metrics Explorer no recurso
Cluster do Cloud Dataproc. Você pode usar essa métrica para criar um alerta que notifique quando a capacidade do cluster divergir da capacidade esperada por mais tempo do que uma duração de limite especificada.

As operações a seguir podem causar um subregistro temporário de nós de cluster na métrica capacity_deviation. Para evitar alertas de falso positivo, defina o limite do alerta de métrica para considerar estas operações:
Criação e atualizações de cluster:a métrica
capacity_deviationnão é emitida durante as operações de criação ou atualização de cluster.Ações de inicialização do cluster:são realizadas depois que um nó é provisionado.
Atualizações de workers secundários:os workers secundários são adicionados de forma assíncrona, após a conclusão da operação de atualização.
Configuração de alerta de desvio de capacidade
Este exemplo usa a linguagem de consulta do Monitoring (MQL) para criar uma política de alertas.
fetch cloud_dataproc_cluster
| metric 'dataproc.googleapis.com/cluster/capacity_deviation'
| every 1m
| condition val() <> 0 '1'
No exemplo a seguir, o alerta é acionado quando o desvio da capacidade do cluster é diferente de zero por mais de 30 minutos.

Ver alertas
Quando um alerta é acionado por uma condição de limite de métrica, o Monitoring cria um incidente e um evento correspondente. Você pode ver os incidentes na página Alertas do Monitoring no console Google Cloud .
O Monitoring também envia uma notificação do incidente se tiver sido definido na política de alerta algum mecanismo de notificação, como notificações por e-mail ou por SMS.

A seguir
- Consulte a Introdução a alertas.