您可以创建 Monitoring 提醒,以便在 Dataproc 集群或作业指标超过指定阈值时收到通知。
创建提醒
在 Google Cloud 控制台中打开提醒页面。
点击 + 创建政策以打开创建提醒政策页面。
- 点击选择指标。
- 在“按资源或指标名称进行过滤”输入框中,输入“dataproc”以列出 Dataproc 指标。浏览 Cloud Dataproc 指标的层次结构,以选择集群、作业、批处理或会话指标。
- 点击应用。
- 点击下一步,以打开配置提醒触发器窗格。
- 设置触发提醒的阈值。
- 点击下一步,以打开 Configure notifications and finalize alert 窗格。
- 设置通知渠道、文档和提醒政策名称。
- 点击下一步以查看提醒政策。
- 点击创建政策以创建提醒。
示例提醒
本部分介绍了针对提交到 Dataproc 服务的作业的示例提醒和针对以 YARN 应用形式运行的作业的提醒。
长时间运行的 Dataproc 作业提醒
Dataproc 会发出 dataproc.googleapis.com/job/state 指标,用于跟踪作业在不同状态下运行的时间。该指标位于 Google Cloud 控制台的 Metrics Explorer 中的 Cloud Dataproc 作业 (cloud_dataproc_job) 资源下。
您可以使用此指标设置提醒,以便在作业的 RUNNING 状态超过时长阈值时收到通知。
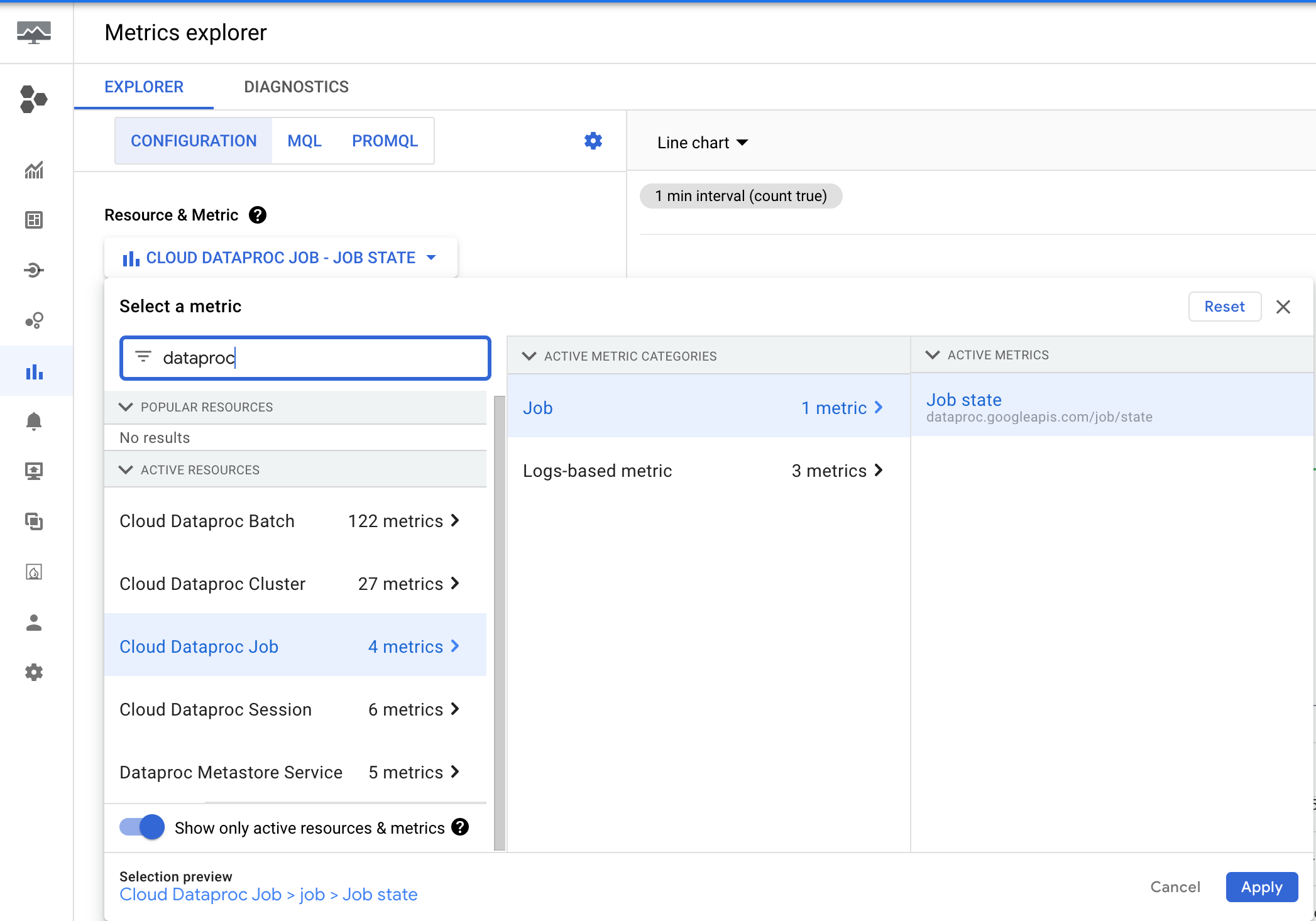
作业时长提醒设置
此示例使用 Monitoring Query Language (MQL) 创建提醒政策(请参阅创建 MQL 提醒政策 [控制台])。
fetch cloud_dataproc_job
| metric 'dataproc.googleapis.com/job/state'
| filter metric.state == 'RUNNING'
| group_by [resource.job_id, metric.state], 1m
| condition val() == true()
在以下示例中,当作业运行时间超过 30 分钟时,系统会触发提醒。
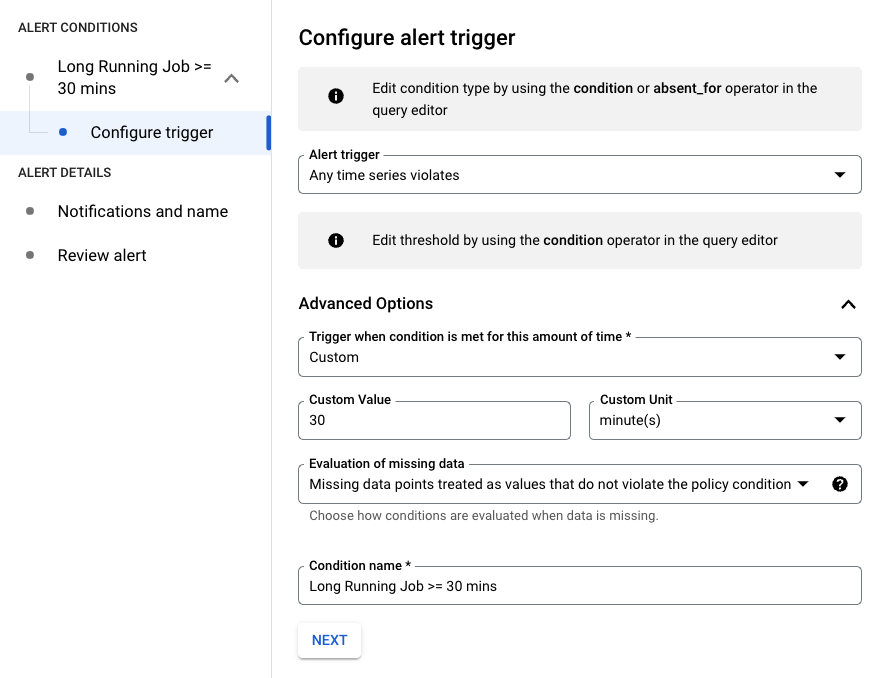
您可以通过过滤 resource.job_id 来修改查询,以将其应用于特定作业:
fetch cloud_dataproc_job
| metric 'dataproc.googleapis.com/job/state'
| filter (resource.job_id == '1234567890') && (metric.state == 'RUNNING')
| group_by [resource.job_id, metric.state], 1m
| condition val() == true()
长时间运行的 YARN 应用提醒
上述示例展示了在 Dataproc 作业运行时间超过指定时长时触发的提醒,但它仅适用于使用 Google Cloud 控制台、Google Cloud CLI 或直接调用 Dataproc jobs API 向 Dataproc 服务提交的作业。您还可以使用 OSS 指标设置类似的提醒,以监控 YARN 应用的运行时间。
首先,我们来了解一些背景知识。YARN 会将运行时间指标发出到多个存储桶中。默认情况下,YARN 会保持 60 分钟、300 分钟和 1440 分钟作为存储桶阈值,并发出 4 个指标 running_0、running_60、running_300 和 running_1440:
running_0记录运行时间介于 0 到 60 分钟之间的作业数量。running_60记录运行时间介于 60 到 300 分钟之间的作业数量。running_300记录运行时间介于 300 到 1440 分钟之间的作业数量。running_1440记录运行时间超过 1440 分钟的作业数量。
例如,运行时间长达 72 分钟的作业会记录在 running_60 中,但不会记录在 running_0 中。
在创建 Dataproc 集群期间,可以通过向 yarn:yarn.resourcemanager.metrics.runtime.buckets 集群属性传递新值来修改这些默认存储桶阈值。定义自定义存储桶阈值时,您还必须定义指标替换项。例如,如需指定 30 分钟、60 分钟和 90 分钟作为存储桶阈值,gcloud dataproc clusters create 命令应包含以下标志:
存储桶阈值:
‑‑properties=yarn:yarn.resourcemanager.metrics.runtime.buckets=30,60,90指标替换项:
‑‑metric-overrides=yarn:ResourceManager:QueueMetrics:running_0, yarn:ResourceManager:QueueMetrics:running_30,yarn:ResourceManager:QueueMetrics:running_60, yarn:ResourceManager:QueueMetrics:running_90
gcloud dataproc clusters create test-cluster \ --properties ^#^yarn:yarn.resourcemanager.metrics.runtime.buckets=30,60,90 \ --metric-sources=yarn \ --metric-overrides=yarn:ResourceManager:QueueMetrics:running_0,yarn:ResourceManager:QueueMetrics:running_30,yarn:ResourceManager:QueueMetrics:running_60,yarn:ResourceManager:QueueMetrics:running_90
这些指标列在 Google Cloud 控制台的 Metrics Explorer 中的虚拟机实例 (gce_instance) 资源下。
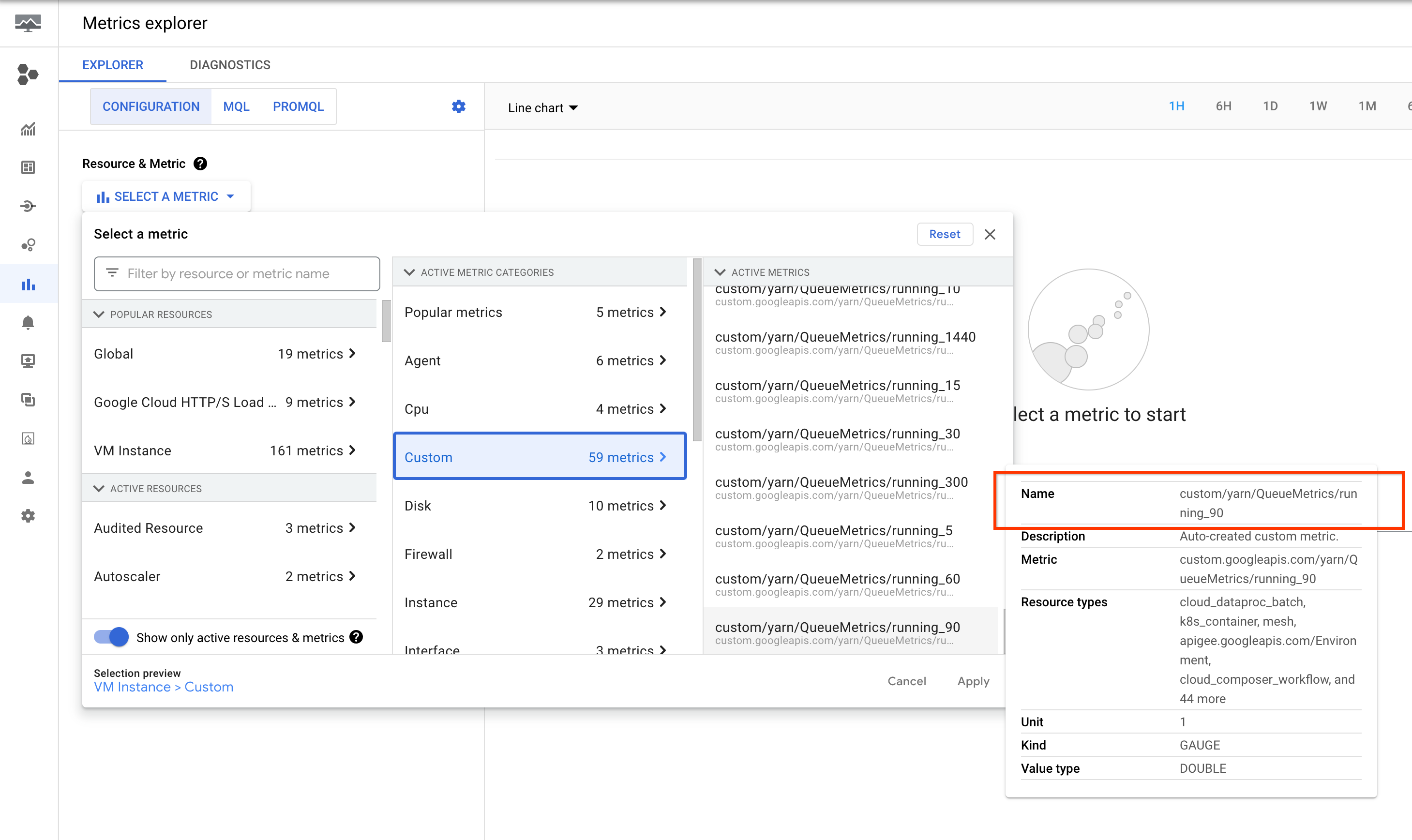
YARN 应用提醒设置
创建提醒政策,以便在 YARN 指标存储桶中的应用数量超过指定阈值时触发。
(可选)添加过滤条件,以针对与某个模式匹配的集群发出提醒。

配置触发提醒的阈值。
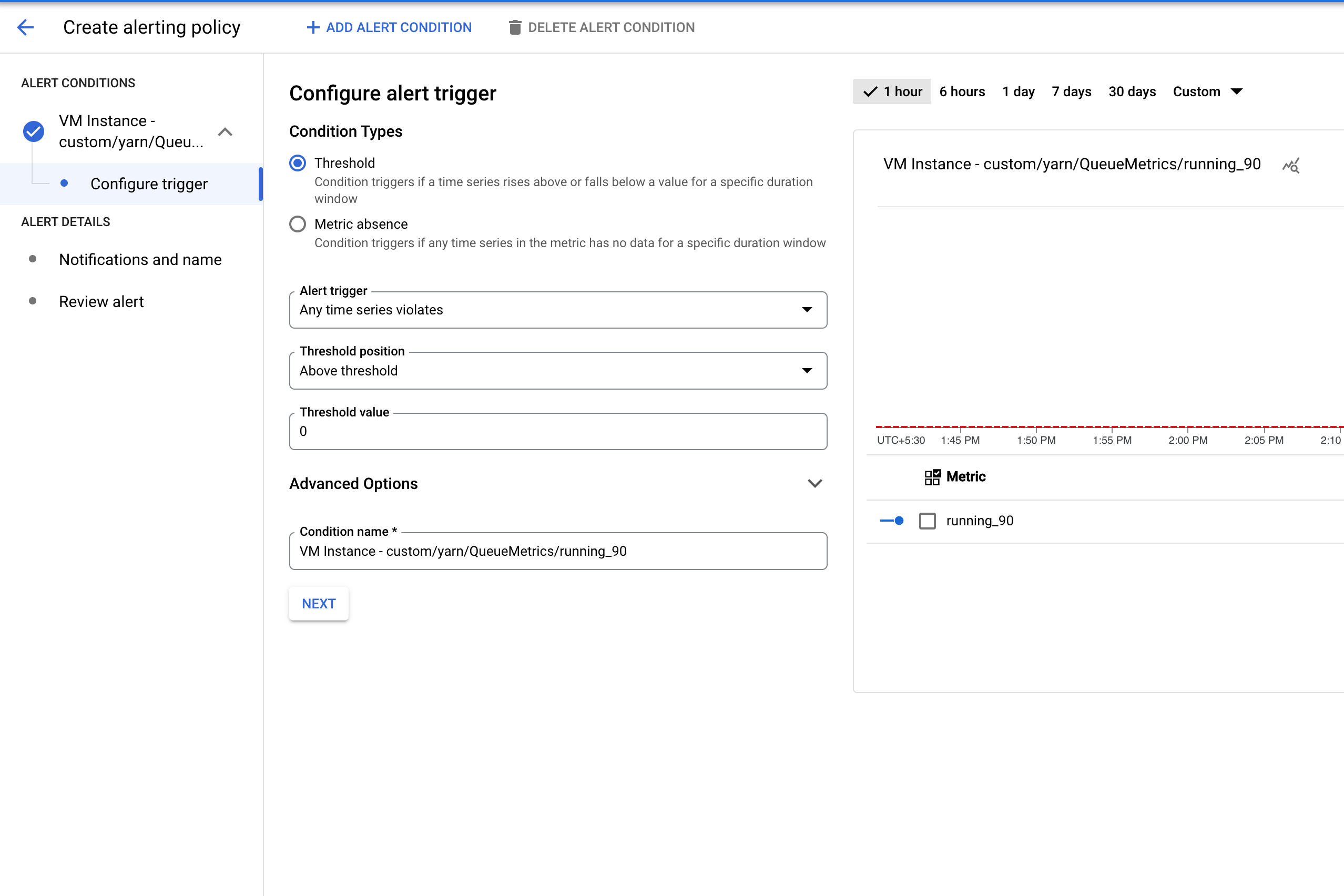
Dataproc 作业失败提醒
您还可以使用 dataproc.googleapis.com/job/state 指标(请参阅长时间运行的 Dataproc 作业提醒),以便在 Dataproc 作业失败时收到提醒。
失败的作业提醒设置
此示例使用 Monitoring Query Language (MQL) 创建提醒政策(请参阅创建 MQL 提醒政策 [控制台])。
提醒 MQL
fetch cloud_dataproc_job
| metric 'dataproc.googleapis.com/job/state'
| filter metric.state == 'ERROR'
| group_by [resource.job_id, metric.state], 1m
| condition val() == true()
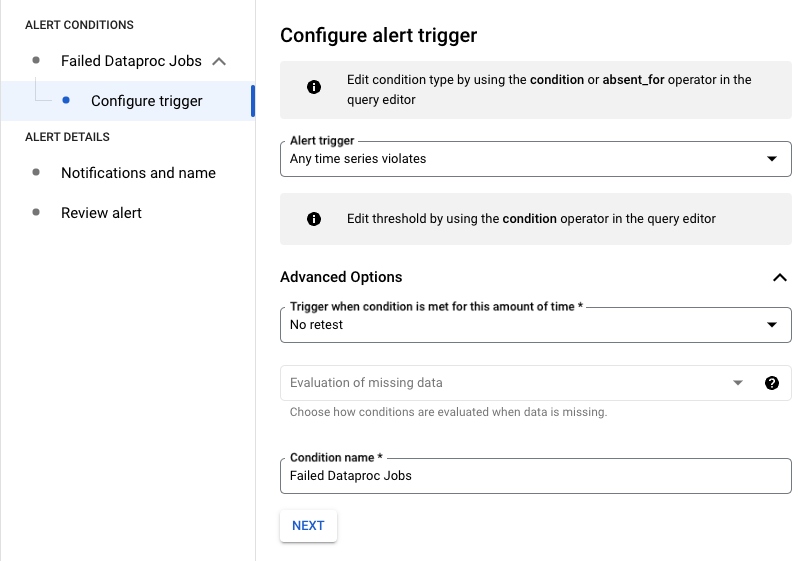
提醒触发器配置
在以下示例中,当项目中的任何 Dataproc 作业失败时,系统都会触发提醒。
您可以通过过滤 resource.job_id 来修改查询,以将其应用于特定作业:
fetch cloud_dataproc_job
| metric 'dataproc.googleapis.com/job/state'
| filter (resource.job_id == '1234567890') && (metric.state == 'ERROR')
| group_by [resource.job_id, metric.state], 1m
| condition val() == true()
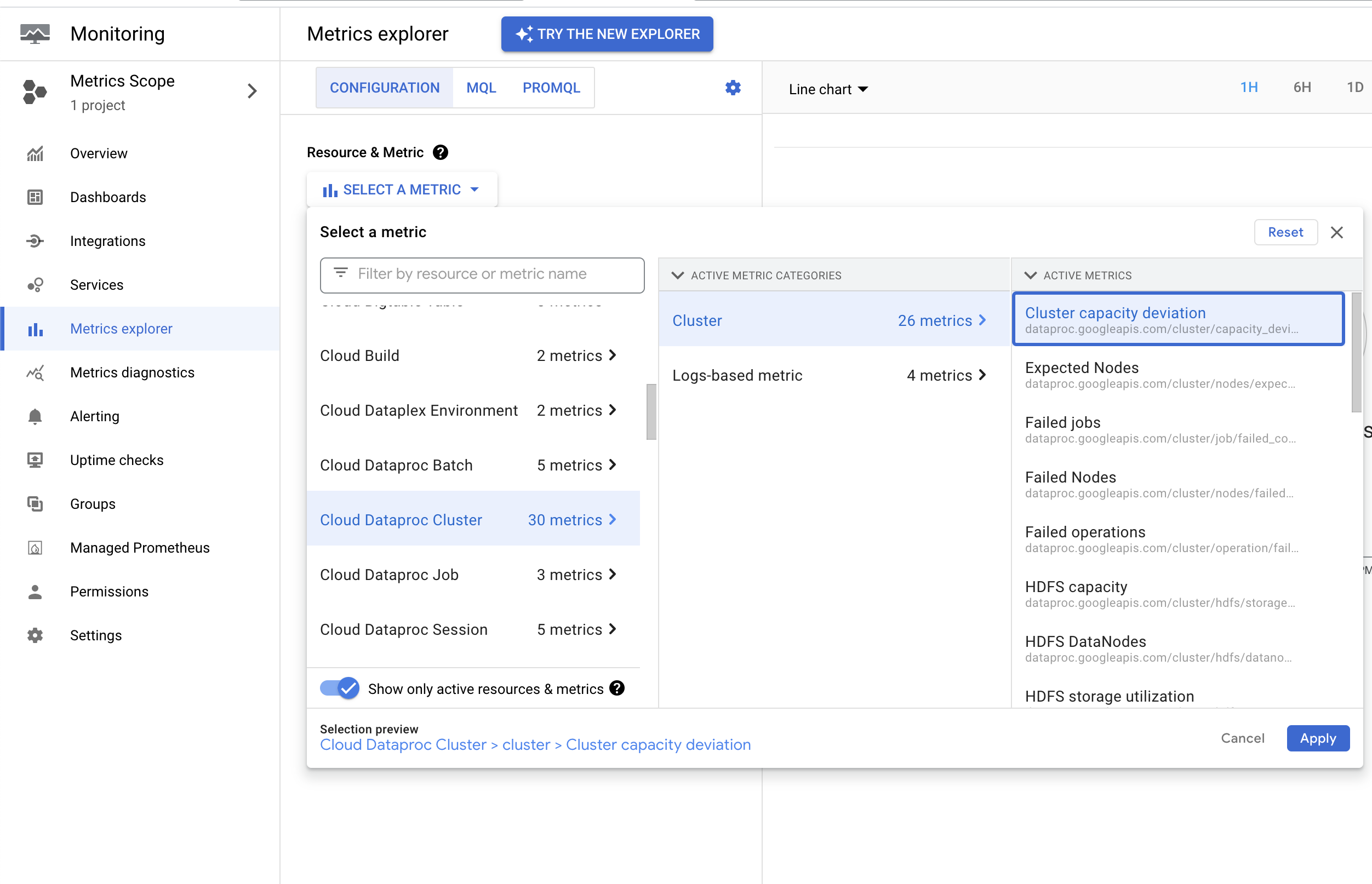
集群容量偏差提醒
Dataproc 会发出 dataproc.googleapis.com/cluster/capacity_deviation 指标,该指标报告集群中的预期节点数与活跃 YARN 节点数之间的差异。您可以在Google Cloud 控制台 Metrics Explorer 中的 Cloud Dataproc 集群资源下找到此指标。您可以使用此指标创建提醒,以便在集群容量偏离预期容量的时长超过指定的阈值时长时收到通知。
以下操作可能会导致 capacity_deviation 指标中的集群节点暂时未报告。为避免误报提醒,请设置指标提醒阈值,以将以下操作考虑在内:
集群创建和更新:在集群创建或更新操作期间,系统不会发出
capacity_deviation指标。集群初始化操作:初始化操作会在预配节点后执行。
辅助工作器更新:辅助工作器会在更新操作完成后异步添加。
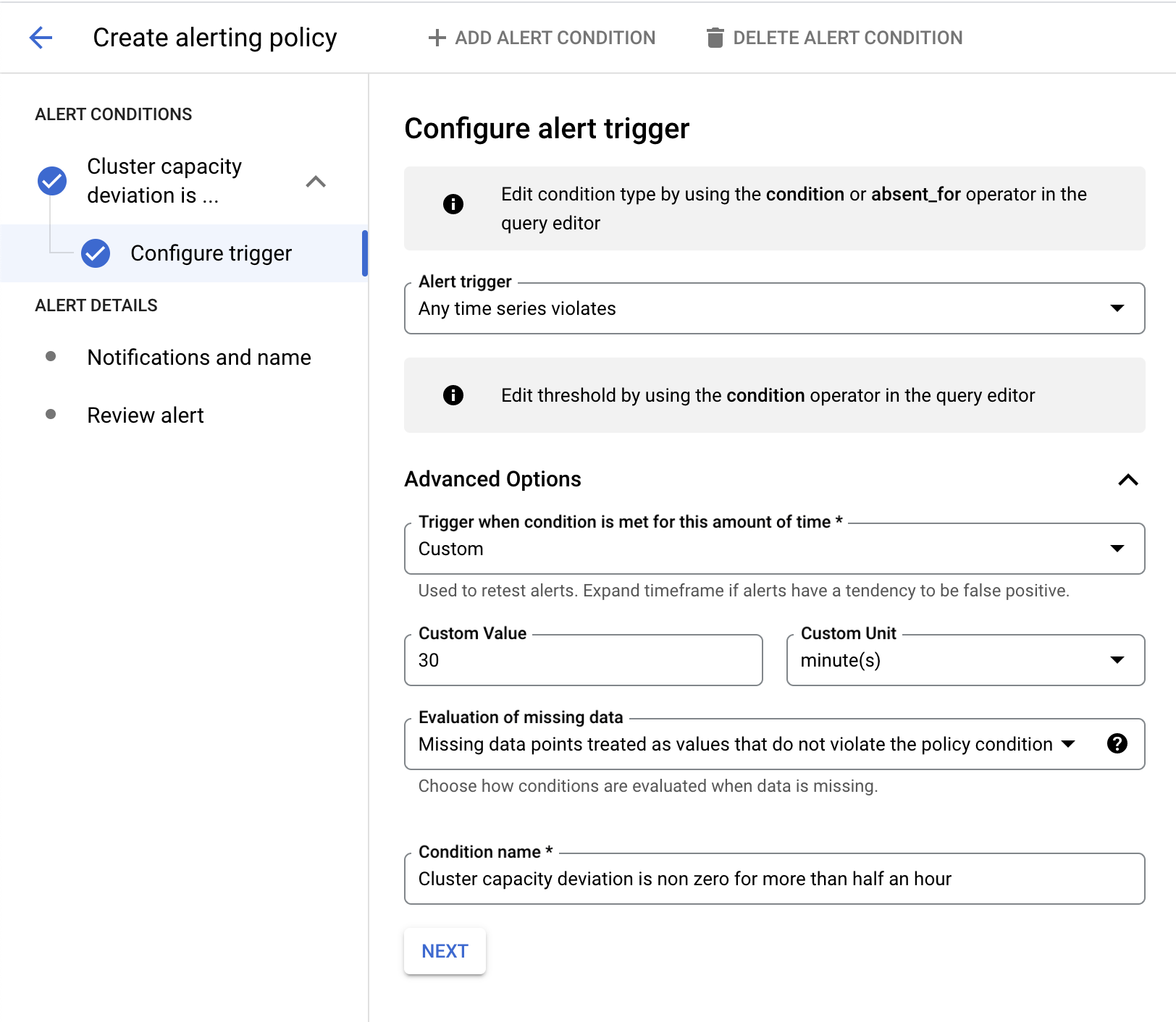
设置容量偏差提醒
此示例使用 Monitoring Query Language (MQL) 创建提醒政策。
fetch cloud_dataproc_cluster
| metric 'dataproc.googleapis.com/cluster/capacity_deviation'
| every 1m
| condition val() <> 0 '1'
在以下示例中,当集群容量偏差超过 30 分钟不为零时,系统会触发提醒。
查看提醒
每次指标阈值条件触发提醒时,Monitoring 都会创建一个突发事件和相应的事件。您可以在 Google Cloud 控制台的 Monitoring 提醒页面中查看突发事件。
如果您在提醒政策中定义了通知机制(例如电子邮件或短信通知),Monitoring 会发送突发事件通知。
后续步骤
- 请参阅提醒简介。