After creating a Dataproc cluster, you can adjust ("scale") the cluster by increasing or decreasing the number of primary or secondary worker nodes (horizontal scaling) in the cluster. You can scale a Dataproc cluster at any time, even when jobs are running on the cluster. You cannot change the machine type of an existing cluster (vertical scaling). To vertically scale, create a cluster using a supported machine type, then migrate jobs to the new cluster.
You can scale a Dataproc cluster for the following:
- to increase the number of workers to make a job run faster.
- to decrease the number of workers to save money (see Graceful Decommissioning as an option to use when downsizing a cluster to avoid losing work in progress).
- to increase the number of nodes to expand available Hadoop Distributed File System (HDFS) storage.
Because clusters can be scaled more than once, you might want to increase or decrease the cluster size at one time, and then decrease or increase the size later.
Use scaling
There are three ways you can scale your Dataproc cluster:
- Use the
gcloudcommand-line tool in the gcloud CLI. - Edit the cluster configuration in the Google Cloud console.
- Use the REST API.
New workers added to a cluster will use the same
machine type
as existing workers. For example, if a cluster is created with
workers that use the n1-standard-8 machine type, new workers
will also use the n1-standard-8 machine type.
You can scale the number of primary workers or the number of secondary (preemptible) workers, or both. For example, if you only scale the number of preemptible workers, the number of primary workers remains the same.
gcloud
To scale a cluster withgcloud dataproc clusters update,
run the following command:
gcloud dataproc clusters update cluster-name \ --region=region \ [--num-workers and/or --num-secondary-workers]=new-number-of-workers
gcloud dataproc clusters update dataproc-1 \
--region=region \
--num-workers=5
...
Waiting on operation [operations/projects/project-id/operations/...].
Waiting for cluster update operation...done.
Updated [https://dataproc.googleapis.com/...].
clusterName: my-test-cluster
...
masterDiskConfiguration:
bootDiskSizeGb: 500
masterName: dataproc-1-m
numWorkers: 5
...
workers:
- my-test-cluster-w-0
- my-test-cluster-w-1
- my-test-cluster-w-2
- my-test-cluster-w-3
- my-test-cluster-w-4
...
REST API
See clusters.patch.
Example
PATCH /v1/projects/project-id/regions/us-central1/clusters/example-cluster?updateMask=config.worker_config.num_instances,config.secondary_worker_config.num_instances
{
"config": {
"workerConfig": {
"numInstances": 4
},
"secondaryWorkerConfig": {
"numInstances": 2
}
},
"labels": null
}
Console
After a cluster is created, you can scale a cluster by opening the Cluster details page for the cluster from the Google Cloud console Clusters page, then clicking the Edit button on the Configuration tab. Enter a new value for the number of Worker nodes and/or
Preemptible worker nodes (updated to "5" and " 2", respectively,
in the following screenshot).
Enter a new value for the number of Worker nodes and/or
Preemptible worker nodes (updated to "5" and " 2", respectively,
in the following screenshot).
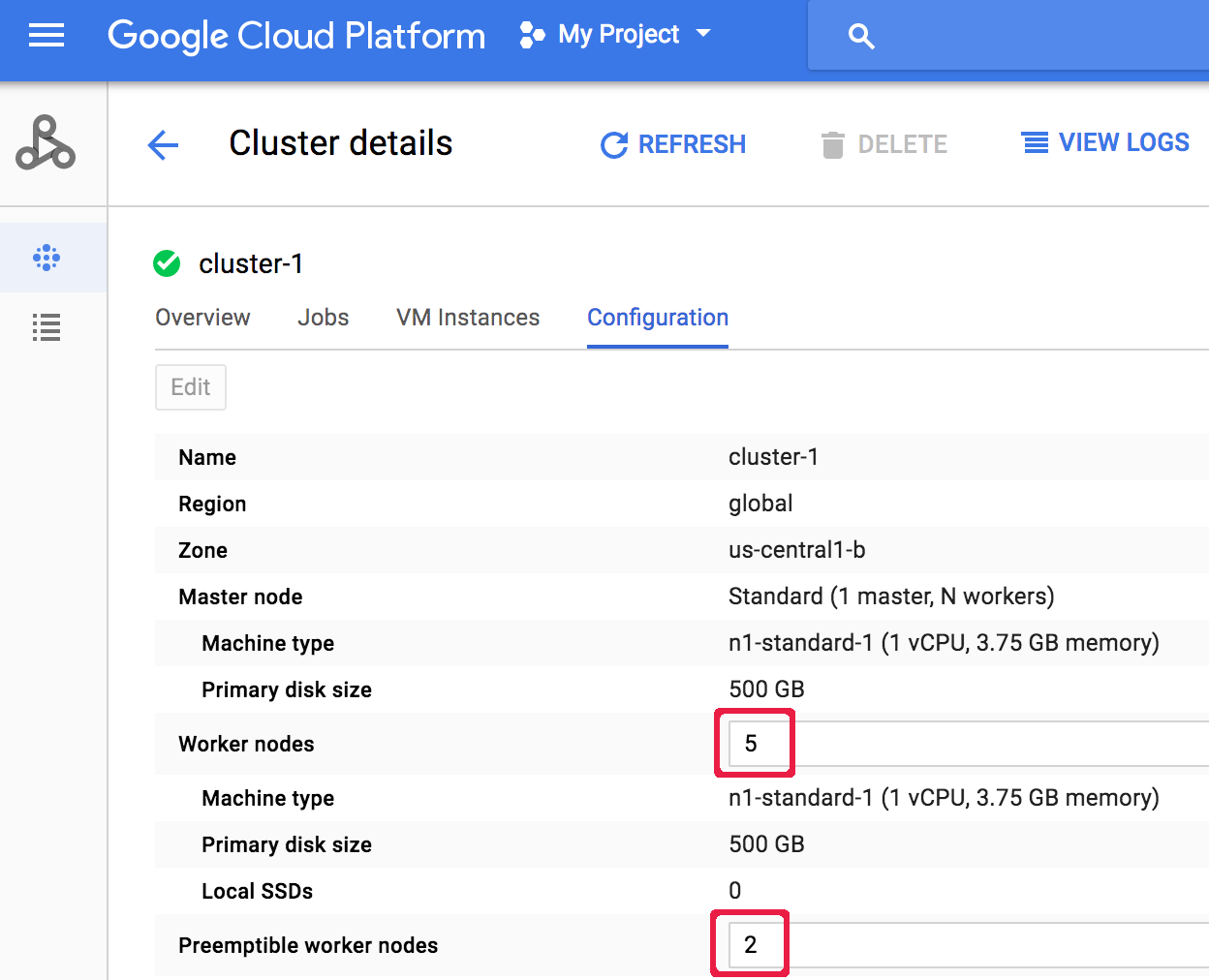 Click Save to update the cluster.
Click Save to update the cluster.
How Dataproc selects cluster nodes for removal
On clusters created with image versions 1.5.83+, 2.0.57+, and 2.1.5+, when scaling down a cluster, Dataproc attempts to minimize the impact of node removal on running YARN applications by first removing inactive, unhealthy, and idle nodes, then removing nodes with the fewest running YARN application masters and running containers.
Graceful decommissioning
When you downscale a cluster, work in progress may stop before completion. If you are using Dataproc v 1.2 or later, you can use Graceful Decommissioning, which incorporates Graceful Decommission of YARN Nodes to finish work in progress on a worker before it is removed from the Cloud Dataproc cluster.
Graceful decommissioning and secondary workers
The preemptible (secondary) worker group continues to provision or delete
workers to reach its expected size even after a cluster scaling operation
is marked complete. If you attempt to gracefully decommission a secondary worker
and receive an error message similar to the following:
"Secondary
worker group cannot be modified outside of Dataproc. If you recently
created or updated this cluster, wait a few minutes before gracefully
decommissioning to allow all secondary instances to join or leave the cluster.
Expected secondary worker group size: x, actual size: y",
wait a
few minutes then repeat the graceful decommissioning request.
Use graceful decommissioning
Dataproc Graceful Decommissioning incorporates Graceful Decommission of YARN Nodes to finish work in progress on a worker before it is removed from the Cloud Dataproc cluster. As a default, graceful decommissioning is disabled. You enable it by setting a timeout value when you update your cluster to remove one or more workers from the cluster.
gcloud
When you update a cluster to remove one or more workers, use the gcloud dataproc clusters update command with the--graceful-decommission-timeout flag. The timeout
(string) values can be a value of "0s" (the default; forceful not graceful
decommissioning) or a positive duration relative to the current time (for example, "3s").
The maximum duration is 1 day.
gcloud dataproc clusters update cluster-name \ --region=region \ --graceful-decommission-timeout="timeout-value" \ [--num-workers and/or --num-secondary-workers]=decreased-number-of-workers \ ... other args ...
REST API
See clusters.patch.gracefulDecommissionTimeout. The timeout (string) values can be a value of "0" (the default; forceful not graceful decommissioning) or a duration in seconds (for example, "3s"). The maximum duration is 1 day.Console
After a cluster is created, you can select graceful decommissioning of a cluster by opening the Cluster details page for the cluster from the Google Cloud console Clusters page, then clicking the Edit button on the Configuration tab.
In the Graceful Decommissioning section, select
Use graceful decommissioning, and then select a timeout value.
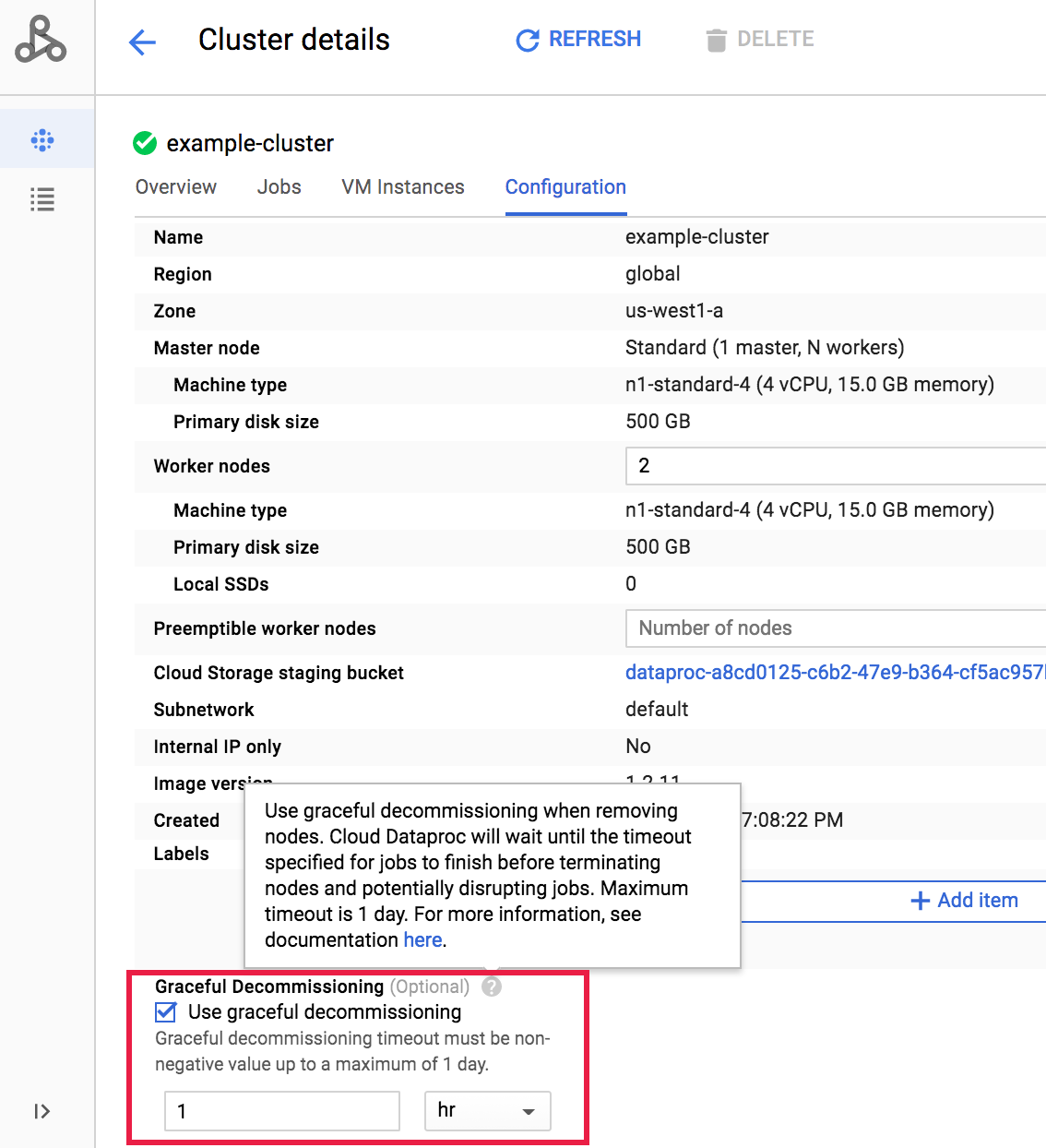 Click Save to update the cluster.
Click Save to update the cluster.
Cancel a graceful decommissioning scaledown operation
On Dataproc clusters created with image versions
2.0.57+
or 2.1.5+,
you can run the gcloud dataproc operations cancel
command or issue a Dataproc API
operations.cancel
request to cancel a graceful decommissioning scaledown operation.
When you cancel a graceful decommissioning scaledown operation:
workers in a
DECOMMISSIONINGstate are re-commissioned and becomeACTIVEat the completion of the operation's cancellation.if the scaledown operation includes label updates, the updates may not take effect.
To verify the status of the cancellation request, you can
run the gcloud dataproc operations describe
command or issue a Dataproc API
operations.get
request. If the cancel operation succeeds, the inner operation status is marked
as CANCELLED.