Panoramica
Il server di cronologia permanente (PHS) di Dataproc fornisce interfacce web per visualizzare la cronologia dei job per i job eseguiti su cluster Dataproc attivi o eliminati. È disponibile in Dataproc versione immagine 1.5 e successive e viene eseguito su un cluster Dataproc a un solo nodo. Fornisce interfacce web per i seguenti file e dati:
File della cronologia dei job MapReduce e Spark
File della cronologia dei job Flink (vedi Componente Flink facoltativo di Dataproc per creare un cluster Dataproc per eseguire i job Flink)
File di dati della cronologia delle applicazioni creati da YARN Timeline Service v2 e archiviati in un'istanza Bigtable.
Log di aggregazione YARN

Persistent History Server accede e visualizza i file della cronologia dei job Spark e MapReduce, i file della cronologia dei job Flink e i file di log YARN scritti in Cloud Storage durante il ciclo di vita dei cluster di job Dataproc.
Limitazioni
La versione dell'immagine del cluster PHS e la versione dell'immagine dei cluster dei job Dataproc devono corrispondere. Ad esempio, puoi utilizzare un cluster PHS con versione immagine Dataproc 2.0 per visualizzare i file della cronologia dei job eseguiti su cluster di job con versione immagine Dataproc 2.0 che si trovavano nel progetto in cui si trova il cluster PHS.
Un cluster PHS non supporta Kerberos e l'autenticazione personale.
Crea un cluster Dataproc PHS
Puoi eseguire il seguente comando
gcloud dataproc clusters create
in un terminale locale o in
Cloud Shell con i seguenti flag e
proprietà del cluster
per creare un cluster a nodo singolo del server di cronologia permanente Dataproc.
gcloud dataproc clusters create CLUSTER_NAME \ --project=PROJECT \ --region=REGION \ --single-node \ --enable-component-gateway \ --optional-components=COMPONENT \ --properties=PROPERTIES
- CLUSTER_NAME: specifica il nome del cluster PHS.
- PROJECT: specifica il progetto da associare al cluster PHS. Questo progetto deve essere lo stesso associato al cluster che esegue i job (vedi Creare un cluster di job Dataproc).
- REGION: specifica una regione Compute Engine in cui si troverà il cluster PHS.
--single-node: Un cluster PHS è un cluster a un solo nodo Dataproc.--enable-component-gateway: questo flag attiva le interfacce web del gateway dei componenti sul cluster PHS.- COMPONENT: utilizza questo flag per installare uno o più componenti facoltativi sul cluster. Devi specificare il componente facoltativo
FLINKper eseguire il servizio web Flink HistoryServer sul cluster PHS per visualizzare i file della cronologia dei job Flink. - PROPERTIES. Specifica una o più proprietà del cluster.
Se vuoi, aggiungi il flag --image-version per specificare la versione dell'immagine del cluster PHS. La versione immagine di PHS deve corrispondere alla versione immagine dei cluster di job Dataproc. Vedi Limitazioni.
Note:
- Gli esempi di valori delle proprietà in questa sezione utilizzano un carattere jolly "*" per consentire a PHS di corrispondere a più directory nel bucket specificato scritte da diversi cluster di job (ma vedi Considerazioni sull'efficienza dei caratteri jolly).
- Nei seguenti esempi vengono mostrati flag
--propertiesseparati per migliorare la leggibilità. La prassi consigliata quando utilizzigcloud dataproc clusters createper creare un cluster Dataproc su Compute Engine è utilizzare un flag--propertiesper specificare un elenco di proprietà separate da virgole (vedi Formattazione delle proprietà del cluster).
Proprietà:
yarn:yarn.nodemanager.remote-app-log-dir=gs://bucket-name/*/yarn-logs: aggiungi questa proprietà per specificare la posizione Cloud Storage in cui PHS accederà ai log YARN scritti dai cluster di job.spark:spark.history.fs.logDirectory=gs://bucket-name/*/spark-job-history: Aggiungi questa proprietà per abilitare la cronologia permanente dei job Spark. Questa proprietà specifica la posizione in cui PHS accederà ai log della cronologia dei job Spark scritti dai cluster di job.Nei cluster Dataproc 2.0+, devono essere impostate anche le seguenti due proprietà per attivare i log della cronologia Spark di PHS (vedi Opzioni di configurazione del server di cronologia Spark). Il valore
spark.history.custom.executor.log.urlè un valore letterale che contiene {{SEGNAPOSTI}} per le variabili che verranno impostate dal server di cronologia permanente. Queste variabili non vengono impostate dagli utenti; passa il valore della proprietà come mostrato.--properties=spark:spark.history.custom.executor.log.url.applyIncompleteApplication=false
--properties=spark:spark.history.custom.executor.log.url={{YARN_LOG_SERVER_URL}}/{{NM_HOST}}:{{NM_PORT}}/{{CONTAINER_ID}}/{{CONTAINER_ID}}/{{USER}}/{{FILE_NAME}}mapred:mapreduce.jobhistory.read-only.dir-pattern=gs://bucket-name/*/mapreduce-job-history/done: Aggiungi questa proprietà per abilitare la cronologia permanente dei job MapReduce. Questa proprietà specifica la posizione di Cloud Storage in cui PHS accederà ai log della cronologia dei job MapReduce scritti dai cluster di job.dataproc:yarn.atsv2.bigtable.instance=projects/project-id/instance_id/bigtable-instance-id: dopo aver configurato Yarn Timeline Service v2, aggiungi questa proprietà per utilizzare il cluster PHS per visualizzare i dati della cronologia nelle interfacce web di YARN Application Timeline Service V2 e Tez (vedi Interfacce web di Component Gateway).flink:historyserver.archive.fs.dir=gs://bucket-name/*/flink-job-history/completed-jobs: utilizza questa proprietà per configurare FlinkHistoryServerin modo da monitorare un elenco di directory separate da virgole.
Esempi di proprietà:
--properties=spark:spark.history.fs.logDirectory=gs://bucket-name/*/spark-job-history
--properties=mapred:mapreduce.jobhistory.read-only.dir-pattern=gs://bucket-name/*/mapreduce-job-history/done
--properties=flink:flink.historyserver.archive.fs.dir=gs://bucket-name/*/flink-job-history/completed-jobs
Crea un cluster di job Dataproc
Puoi eseguire il seguente comando in un terminale locale o in Cloud Shell per creare un cluster di job Dataproc che esegue i job e scrive i file della cronologia dei job in un server di cronologia permanente (PHS).
gcloud dataproc clusters create CLUSTER_NAME \ --project=PROJECT \ --region=REGION \ --optional-components=COMPONENT \ --enable-component-gateway \ --properties=PROPERTIES \ other args ...
- CLUSTER_NAME: specifica il nome del cluster di job.
- PROJECT: specifica il progetto associato al cluster di job.
- REGION: specifica la regione Compute Engine in cui si troverà il cluster di job.
--enable-component-gateway: questo flag attiva le interfacce web del gateway dei componenti sul cluster di job.- COMPONENT: utilizza questo flag per installare uno o più componenti facoltativi sul cluster. Specifica il componente facoltativo
FLINKper eseguire job Flink sul cluster. PROPERTIES: aggiungi una o più delle seguenti proprietà del cluster per impostare posizioni Cloud Storage non predefinite correlate a PHS e altre proprietà del cluster di job.
Note:
- Gli esempi di valori delle proprietà in questa sezione utilizzano un carattere jolly "*" per consentire a PHS di corrispondere a più directory nel bucket specificato scritte da diversi cluster di job (ma vedi Considerazioni sull'efficienza dei caratteri jolly).
- Nei seguenti esempi vengono mostrati flag
--propertiesseparati per migliorare la leggibilità. La prassi consigliata quando utilizzigcloud dataproc clusters createper creare un cluster Dataproc su Compute Engine è utilizzare un flag--propertiesper specificare un elenco di proprietà separate da virgole (vedi Formattazione delle proprietà del cluster).
Proprietà:
yarn:yarn.nodemanager.remote-app-log-dir: Per impostazione predefinita, i log YARN aggregati sono abilitati nei cluster di job Dataproc e vengono scritti nel bucket temporaneo del cluster. Aggiungi questa proprietà per specificare una posizione Cloud Storage diversa in cui il cluster scriverà i log di aggregazione per l'accesso da parte del server di cronologia permanente.--properties=yarn:yarn.nodemanager.remote-app-log-dir=gs://bucket-name/directory-name/yarn-logs
spark:spark.history.fs.logDirectoryespark:spark.eventLog.dir: Per impostazione predefinita, i file della cronologia dei job Spark vengono salvati nel clustertemp bucketnella directory/spark-job-history. Puoi aggiungere queste proprietà per specificare diverse posizioni Cloud Storage per questi file. Se vengono utilizzate entrambe le proprietà, devono puntare a directory nello stesso bucket.--properties=spark:spark.history.fs.logDirectory=gs://bucket-name/directory-name/spark-job-history
--properties=spark:spark.eventLog.dir=gs://bucket-name/directory-name/spark-job-history
mapred:mapreduce.jobhistory.done-diremapred:mapreduce.jobhistory.intermediate-done-dir: Per impostazione predefinita, i file della cronologia dei job MapReduce vengono salvati nel clustertemp bucketnelle directory/mapreduce-job-history/donee/mapreduce-job-history/intermediate-done. La posizione intermediamapreduce.jobhistory.intermediate-done-dirè uno spazio di archiviazione temporaneo; i file intermedi vengono spostati nella posizionemapreduce.jobhistory.done-diral termine del job MapReduce. Puoi aggiungere queste proprietà per specificare diverse posizioni Cloud Storage per questi file. Se vengono utilizzate entrambe le proprietà, devono puntare a directory nello stesso bucket.--properties=mapred:mapreduce.jobhistory.done-dir=gs://bucket-name/directory-name/mapreduce-job-history/done
--properties=mapred:mapreduce.jobhistory.intermediate-done-dir=gs://bucket-name/directory-name/mapreduce-job-history/intermediate-done
spark:spark.history.fs.gs.outputstream.type: questa proprietà si applica ai cluster di versioni delle immagini2.0e2.1che utilizzano la versione2.0.xdel connettore Cloud Storage (la versione predefinita del connettore per i cluster di versioni delle immagini2.0e2.1). Controlla il modo in cui i job Spark inviano i dati a Cloud Storage. L'impostazione predefinita èBASIC, che invia i dati a Cloud Storage al termine del job. Se impostato suFLUSHABLE_COMPOSITE, i dati vengono copiati in Cloud Storage a intervalli regolari durante l'esecuzione del job, come impostato daspark:spark.history.fs.gs.outputstream.sync.min.interval.ms.--properties=spark:spark.history.fs.gs.outputstream.type=FLUSHABLE_COMPOSITE
spark:spark.history.fs.gs.outputstream.sync.min.interval.ms: Questa proprietà si applica ai cluster di versioni delle immagini2.0e2.1che utilizzano il connettore Cloud Storage versione2.0.x(la versione predefinita del connettore per i cluster di versioni delle immagini2.0e2.1). Controlla la frequenza in millisecondi con cui i dati vengono trasferiti a Cloud Storage quandospark:spark.history.fs.gs.outputstream.typeè impostato suFLUSHABLE_COMPOSITE. L'intervallo di tempo predefinito è5000ms. Il valore dell'intervallo di tempo in millisecondi può essere specificato con o senza l'aggiunta del suffissoms.--properties=spark:spark.history.fs.gs.outputstream.sync.min.interval.ms=INTERVALms
spark:spark.history.fs.gs.outputstream.sync.min.interval: Questa proprietà si applica ai cluster di versioni delle immagini2.2e successive che utilizzano il connettore Cloud Storage versione3.0.x(la versione predefinita del connettore per i cluster di versioni delle immagini2.2). Sostituisce la precedente proprietàspark:spark.history.fs.gs.outputstream.sync.min.interval.mse supporta valori con suffisso temporale, ad esempioms,sem. Controlla la frequenza con cui i dati vengono trasferiti a Cloud Storage quandospark:spark.history.fs.gs.outputstream.typeè impostato suFLUSHABLE_COMPOSITE.--properties=spark:spark.history.fs.gs.outputstream.sync.min.interval=INTERVAL
dataproc:yarn.atsv2.bigtable.instance: dopo aver configurato Yarn Timeline Service v2, aggiungi questa proprietà per scrivere i dati della cronologia YARN nell'istanza Bigtable specificata per la visualizzazione nel cluster PHS YARN Application Timeline Service V2 e nelle interfacce web Tez. Nota: la creazione del cluster non andrà a buon fine se l'istanza Bigtable non esiste.--properties=dataproc:yarn.atsv2.bigtable.instance=projects/project-id/instance_id/bigtable-instance-id
flink:jobhistory.archive.fs.dir: gli archivi di Flink JobManager completano i job Flink caricando le informazioni archiviate dei job in una directory del file system. Utilizza questa proprietà per impostare la directory dell'archivio inflink-conf.yaml.--properties=flink:jobmanager.archive.fs.dir=gs://bucket-name/job-cluster-1/flink-job-history/completed-jobs
Utilizzare PHS con i carichi di lavoro batch Spark
Per utilizzare il server di cronologia permanente con Dataproc Serverless per i carichi di lavoro batch Spark:
Seleziona o specifica il cluster PHS quando invii un carico di lavoro batch Spark.
Utilizzare PHS con Dataproc su Google Kubernetes Engine
Per utilizzare il server di cronologia permanente con Dataproc su GKE:
Seleziona o specifica il cluster PHS quando crei un cluster virtuale Dataproc su GKE.
Interfacce web del gateway dei componenti
Nella console Google Cloud , nella pagina Cluster di Dataproc, fai clic sul nome del cluster PHS per aprire la pagina Dettagli cluster. Nella scheda Interfacce web, seleziona i link del gateway dei componenti per aprire le interfacce web in esecuzione sul cluster PHS.

Interfaccia web del server di cronologia Spark
Lo screenshot seguente mostra l'interfaccia web di Spark History Server che visualizza i link
ai job Spark eseguiti su job-cluster-1 e job-cluster-2 dopo aver configurato
le posizioni spark.history.fs.logDirectory e spark:spark.eventLog.dir dei job cluster
e spark.history.fs.logDirectory del cluster PHS nel seguente modo:
| job-cluster-1 | gs://example-cloud-storage-bucket/job-cluster-1/spark-job-history |
| job-cluster-2 | gs://example-cloud-storage-bucket/job-cluster-2/spark-job-history |
| phs-cluster | gs://example-cloud-storage-bucket/*/spark-job-history |

Ricerca del nome dell'app
Puoi elencare i job per nome dell'app nell'interfaccia web Spark History Server inserendo un nome dell'app nella casella di ricerca. Il nome dell'app può essere impostato in uno dei seguenti modi (elencati in ordine di priorità):
- Impostato all'interno del codice dell'applicazione durante la creazione del contesto Spark
- Impostato dalla proprietà spark.app.name quando viene inviato il job
- Impostato da Dataproc sul nome completo della risorsa REST per
il job (
projects/project-id/regions/region/jobs/job-id)
Gli utenti possono inserire un termine con il nome di un'app o di una risorsa nella casella Cerca per trovare e elencare i lavori.

Log eventi
L'interfaccia web di Spark History Server fornisce un pulsante Log eventi su cui puoi fare clic per scaricare i log eventi Spark. Questi log sono utili per esaminare il ciclo di vita dell'applicazione Spark.
Job Spark
Le applicazioni Spark sono suddivise in più job, che a loro volta sono suddivisi in più fasi. Ogni fase può avere più attività, che vengono eseguite sui nodi di esecuzione (worker).
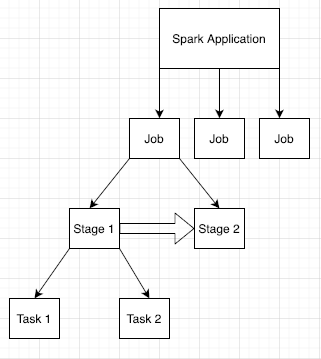
Fai clic su un ID app Spark nell'interfaccia web per aprire la pagina Job Spark, che fornisce una cronologia degli eventi e un riepilogo dei job all'interno dell'applicazione.
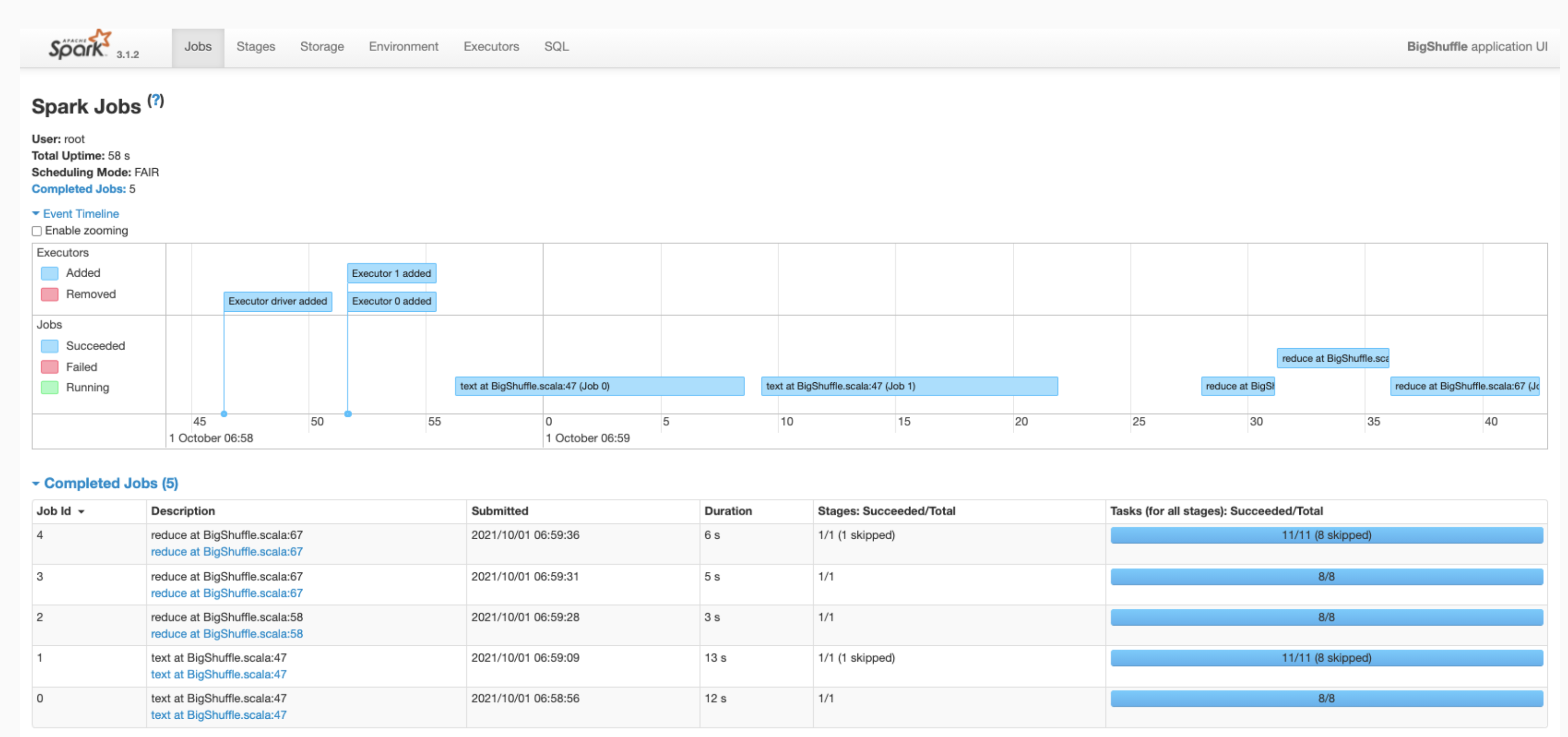
Fai clic su un job per aprire una pagina Dettagli job con un grafo aciclico orientato (DAG) e un riepilogo delle fasi del job.
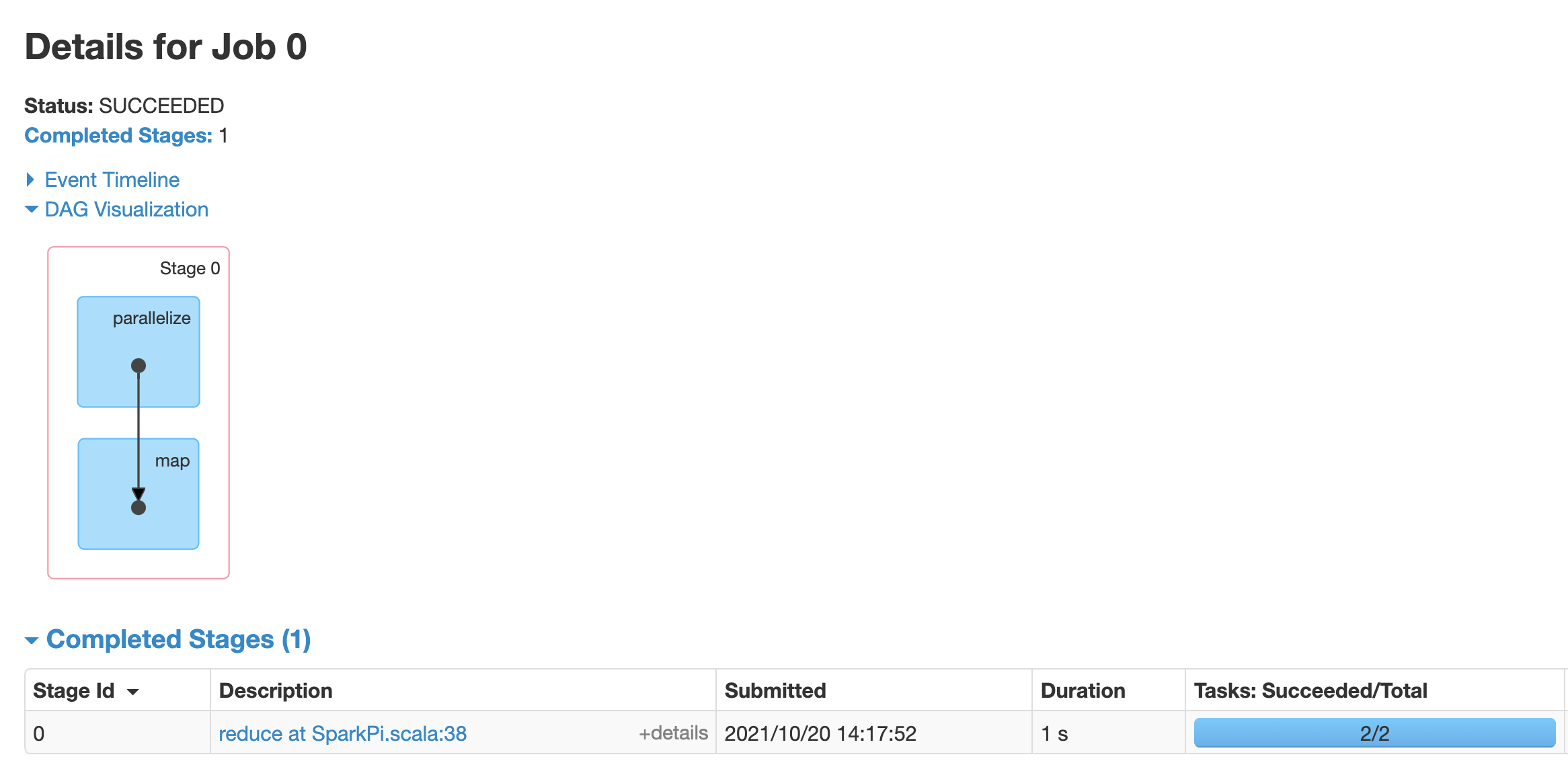
Fai clic su una fase o utilizza la scheda Fasi per selezionarne una e aprire la pagina Dettagli fase.
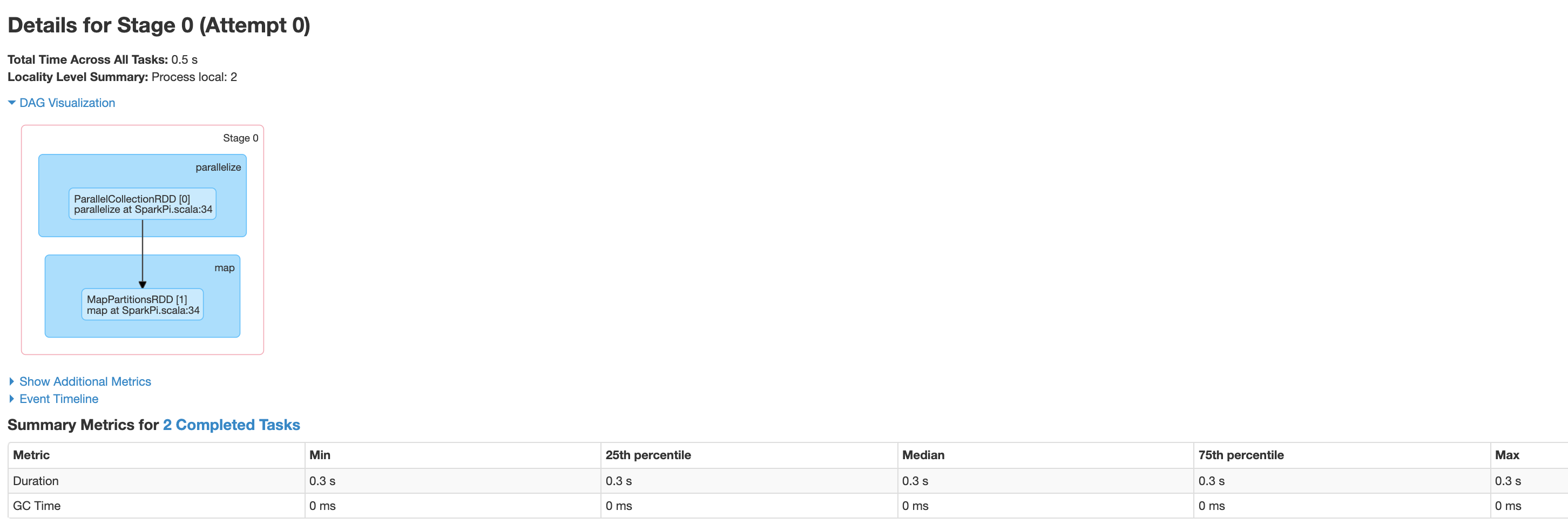
I dettagli della fase includono una visualizzazione DAG, una sequenza temporale degli eventi e metriche per le attività all'interno della fase. Puoi utilizzare questa pagina per risolvere i problemi relativi a attività bloccate, ritardi dello scheduler ed errori di esaurimento della memoria. Il visualizzatore DAG mostra la riga di codice da cui deriva lo stage, aiutandoti a risalire al codice per risolvere i problemi.
Fai clic sulla scheda Esecutori per informazioni sui nodi driver ed esecutore dell'applicazione Spark.

Le informazioni importanti in questa pagina includono il numero di core e il numero di attività eseguite su ogni executor.
Interfaccia web di Tez
Tez è il motore di esecuzione predefinito per Hive e Pig su Dataproc. L'invio di un job Hive su un cluster di job Dataproc avvia un'applicazione Tez.
Se hai configurato Yarn Timeline Service v2 e impostato la proprietà dataproc:yarn.atsv2.bigtable.instance quando hai creato i cluster di job PHS e Dataproc, YARN scrive i dati della cronologia dei job Hive e Pig generati nell'istanza Bigtable specificata per il recupero e la visualizzazione nell'interfaccia web Tez in esecuzione sul server PHS.

Interfaccia web YARN Application Timeline V2
Se hai configurato Yarn Timeline Service v2 e impostato la proprietà dataproc:yarn.atsv2.bigtable.instance quando hai creato i cluster di job PHS e Dataproc, YARN scrive i dati della cronologia dei job generati nell'istanza Bigtable specificata per il recupero e la visualizzazione nell'interfaccia web di YARN Application Timeline Service in esecuzione sul server PHS. I job Dataproc sono elencati nella scheda Attività flusso
dell'interfaccia web.

Configura Yarn Timeline Service v2
Per configurare Yarn Timeline Service v2, configura un'istanza Bigtable e, se necessario, controlla i ruoli del account di servizio, come segue:
Se necessario, controlla i ruoli del account di servizio. Il service account VM predefinito utilizzato dalle VM del cluster Dataproc dispone delle autorizzazioni necessarie per creare e configurare l'istanza Bigtable per YARN Timeline Service. Se crei il job o il cluster PHS con un service account VM personalizzato, l'account deve avere il ruolo Bigtable
AdministratoroBigtable User.
Schema della tabella richiesto
Il supporto di Dataproc PHS per
YARN Timeline Service v2
richiede uno schema specifico creato nell'istanza Bigtable. Dataproc crea lo schema
richiesto quando viene creato un cluster di job o un cluster PHS con la proprietà
dataproc:yarn.atsv2.bigtable.instance impostata in modo che punti all'istanza
Bigtable.
Di seguito è riportato lo schema dell'istanza Bigtable richiesto:
| Tabelle | Famiglie di colonne |
|---|---|
| prod.timelineservice.application | c,i,m |
| prod.timelineservice.app_flow | m |
| prod.timelineservice.entity | c,i,m |
| prod.timelineservice.flowactivity | i |
| prod.timelineservice.flowrun | i |
| prod.timelineservice.subapplication | c,i,m |
Garbage collection di Bigtable
Puoi configurare la garbage collection di Bigtable in base all'età per le tabelle ATSv2:
Installa cbt, (inclusa la creazione di
.cbrtc file).Crea la policy di garbage collection basata sull'età ATSv2:
export NUMBER_OF_DAYS = number \
cbt setgcpolicy prod.timelineservice.application c maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.application i maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.application m maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.app_flow m maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.entity c maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.entity i maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.entity m maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.flowactivity i maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.flowrun i maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.subapplication c maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.subapplication i maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.subapplication m maxage=${NUMBER_OF_DAYS}
Note:
NUMBER_OF_DAYS: il numero massimo di giorni è 30d.