Übersicht
Der Dataproc Persistent History Server (PHS) bietet Weboberflächen, um den Jobverlauf für Jobs aufzurufen, die in aktiven oder gelöschten Dataproc-Clustern ausgeführt werden. Sie ist in der Dataproc-Image-Version 1.5 und höher verfügbar und wird auf einem Dataproc-Cluster mit nur einem Knoten ausgeführt. Es bietet Weboberflächen für die folgenden Dateien und Daten:
MapReduce- und Spark-Jobverlaufsdateien
Flink-Jobverlaufsdateien (Informationen zum Erstellen eines Dataproc-Clusters zum Ausführen von Flink-Jobs finden Sie unter Optionale Flink-Komponente für Dataproc)
Anwendungstimeline-Datendateien, die von YARN Timeline Service v2 erstellt und in einer Bigtable-Instanz gespeichert werden.
YARN-Aggregationslogs

Der Persistent History Server greift auf Spark- und MapReduce-Jobverlaufsdateien, Flink-Jobverlaufsdateien und YARN-Logdateien zu, die während der Lebensdauer von Dataproc-Jobclustern in Cloud Storage geschrieben wurden, und zeigt sie an.
Beschränkungen
Die Image-Version des PHS-Clusters und die Image-Version des/der Dataproc-Jobclusters müssen übereinstimmen. Sie können beispielsweise einen PHS-Cluster mit Dataproc-Version 2.0 verwenden, um Jobverlaufsdateien von Jobs aufzurufen, die in Job-Clustern mit Dataproc-Version 2.0 ausgeführt wurden, die sich im Projekt des PHS-Clusters befanden.
Ein PHS-Cluster unterstützt weder Kerberos noch die persönliche Authentifizierung.
Dataproc-PHS-Cluster erstellen
Sie können den folgenden gcloud dataproc clusters create-Befehl in einem lokalen Terminal oder in Cloud Shell mit den folgenden Flags und Clusterattributen ausführen, um einen Dataproc Persistent History Server-Cluster mit einem Knoten zu erstellen.
gcloud dataproc clusters create CLUSTER_NAME \ --project=PROJECT \ --region=REGION \ --single-node \ --enable-component-gateway \ --optional-components=COMPONENT \ --properties=PROPERTIES
- CLUSTER_NAME: Geben Sie den Namen des PHS-Clusters an.
- PROJECT: Geben Sie das Projekt an, das mit dem PHS-Cluster verknüpft werden soll. Dieses Projekt sollte mit dem Projekt übereinstimmen, das dem Cluster zugeordnet ist, in dem Ihre Jobs ausgeführt werden (siehe Dataproc-Jobcluster erstellen).
- REGION: Geben Sie eine Compute Engine-Region an, in der sich der PHS-Cluster befinden soll.
--single-node: Ein PHS-Cluster ist ein Dataproc-Einzelknoten-Cluster.--enable-component-gateway: Dieses Flag aktiviert Component Gateway-Weboberflächen im PHS-Cluster.- COMPONENT: Verwenden Sie dieses Flag, um eine oder mehrere optionale Komponenten im Cluster zu installieren. Sie müssen die optionale Komponente
FLINKangeben, um den Flink HistoryServer-Webdienst im PHS-Cluster auszuführen und Flink-Jobverlaufsdateien aufzurufen. - PROPERTIES. Geben Sie ein oder mehrere Clusterattribute an.
Fügen Sie optional das Flag --image-version hinzu, um die PHS-Cluster-Image-Version anzugeben. Die PHS-Image-Version muss mit der Image-Version der Dataproc-Jobcluster übereinstimmen. Weitere Informationen
Hinweise:
- In den Beispielen für Attributwerte in diesem Abschnitt wird ein Sternchen als Platzhalter verwendet, damit der PHS-Server mehrere Verzeichnisse im angegebenen Bucket abgleichen kann, in die verschiedene Jobcluster geschrieben wurden. Siehe Hinweise zur Effizienz von Platzhaltern.
- Zur besseren Lesbarkeit werden in den folgenden Beispielen separate
--properties-Flags verwendet. Wenn Sie mitgcloud dataproc clusters createeinen Dataproc in Compute Engine-Cluster erstellen, empfiehlt es sich, ein--properties-Flag zu verwenden, um eine Liste von durch Kommas getrennten Eigenschaften anzugeben (siehe Formatierung von Clustereigenschaften).
Attribute:
yarn:yarn.nodemanager.remote-app-log-dir=gs://bucket-name/*/yarn-logs: Fügen Sie diese Property hinzu, um den Cloud Storage-Speicherort anzugeben, an dem die PHS auf YARN-Logs zugreifen, die von Jobclustern geschrieben wurden.spark:spark.history.fs.logDirectory=gs://bucket-name/*/spark-job-history: Fügen Sie dieses Attribut hinzu, um den nichtflüchtigen Spark-Jobverlauf zu aktivieren. Dieses Attribut gibt den Speicherort an, an dem der PHS auf Spark-Jobverlaufslogs zugreift, die von Jobclustern geschrieben wurden.In Dataproc-Clustern 2.0+ müssen die folgenden beiden Attribute ebenfalls festgelegt werden, um PHS-Spark-Verlaufsprotokolle zu aktivieren (siehe Spark History Server-Konfigurationsoptionen). Der Wert
spark.history.custom.executor.log.urlist ein Literalwert, der {{PLATZHALTER}} für Variablen enthält, die vom Persistent History Server festgelegt werden. Diese Variablen werden nicht von Nutzern festgelegt. Übergeben Sie den Eigenschaftswert wie dargestellt.--properties=spark:spark.history.custom.executor.log.url.applyIncompleteApplication=false
--properties=spark:spark.history.custom.executor.log.url={{YARN_LOG_SERVER_URL}}/{{NM_HOST}}:{{NM_PORT}}/{{CONTAINER_ID}}/{{CONTAINER_ID}}/{{USER}}/{{FILE_NAME}}mapred:mapreduce.jobhistory.read-only.dir-pattern=gs://bucket-name/*/mapreduce-job-history/done: Fügen Sie diese Property hinzu, um den nichtflüchtigen MapReduce-Jobverlauf zu aktivieren. Dieses Attribut gibt den Cloud Storage-Speicherort an, an dem der PHS auf MapReduce-Jobverlaufslogs zugreift, die von Jobclustern geschrieben wurden.dataproc:yarn.atsv2.bigtable.instance=projects/project-id/instance_id/bigtable-instance-id: Nachdem Sie Yarn Timeline Service v2 konfiguriert haben, fügen Sie diese Property hinzu, um den PHS-Cluster zu verwenden, um Zeitachsendaten in den Weboberflächen YARN Application Timeline Service V2 und Tez aufzurufen (siehe Weboberflächen des Component Gateway).flink:historyserver.archive.fs.dir=gs://bucket-name/*/flink-job-history/completed-jobs: Mit dieser Eigenschaft konfigurieren Sie den Flink-HistoryServer, um eine durch Kommas getrennte Liste von Verzeichnissen zu überwachen.
Beispiele für Attribute:
--properties=spark:spark.history.fs.logDirectory=gs://bucket-name/*/spark-job-history
--properties=mapred:mapreduce.jobhistory.read-only.dir-pattern=gs://bucket-name/*/mapreduce-job-history/done
--properties=flink:flink.historyserver.archive.fs.dir=gs://bucket-name/*/flink-job-history/completed-jobs
Dataproc-Jobcluster erstellen
Sie können den folgenden Befehl in einem lokalen Terminal oder in Cloud Shell ausführen, um einen Dataproc-Jobcluster zu erstellen, der Jobs ausführt und Jobverlaufsdateien in einen Persistent History Server (PHS) schreibt.
gcloud dataproc clusters create CLUSTER_NAME \ --project=PROJECT \ --region=REGION \ --optional-components=COMPONENT \ --enable-component-gateway \ --properties=PROPERTIES \ other args ...
- CLUSTER_NAME: Geben Sie den Namen des Jobclusters an.
- PROJECT: Geben Sie das Projekt an, das dem Jobcluster zugeordnet ist.
- REGION: Geben Sie die Compute Engine-Region an, in der sich der Jobcluster befinden soll.
--enable-component-gateway: Mit diesem Flag werden Component Gateway-Weboberflächen im Jobcluster aktiviert.- COMPONENT: Verwenden Sie dieses Flag, um eine oder mehrere optionale Komponenten im Cluster zu installieren. Geben Sie die optionale Komponente
FLINKan, um Flink-Jobs im Cluster auszuführen. PROPERTIES: Fügen Sie eine oder mehrere der folgenden Clustereigenschaften hinzu, um nicht standardmäßige Cloud Storage-Speicherorte und andere Jobclustereigenschaften für PHS festzulegen.
Hinweise:
- In den Beispielen für Attributwerte in diesem Abschnitt wird ein Sternchen als Platzhalter verwendet, damit der PHS-Server mehrere Verzeichnisse im angegebenen Bucket abgleichen kann, in die verschiedene Jobcluster geschrieben wurden. Siehe Hinweise zur Effizienz von Platzhaltern.
- Zur besseren Lesbarkeit werden in den folgenden Beispielen separate
--properties-Flags verwendet. Wenn Sie mitgcloud dataproc clusters createeinen Dataproc in Compute Engine-Cluster erstellen, empfiehlt es sich, ein--properties-Flag zu verwenden, um eine Liste von durch Kommas getrennten Eigenschaften anzugeben (siehe Formatierung von Clustereigenschaften).
Attribute:
yarn:yarn.nodemanager.remote-app-log-dir: Standardmäßig sind aggregierte YARN-Logs in Dataproc-Jobclustern aktiviert und werden in den temporären Bucket des Clusters geschrieben. Fügen Sie dieses Attribut hinzu, um einen anderen Cloud Storage-Speicherort anzugeben, an dem der Cluster Aggregationslogs für den Zugriff durch den Persistent History Server schreibt.--properties=yarn:yarn.nodemanager.remote-app-log-dir=gs://bucket-name/directory-name/yarn-logs
spark:spark.history.fs.logDirectoryundspark:spark.eventLog.dir: Standardmäßig werden Spark-Jobverlaufsdateien im Clustertemp bucketim Verzeichnis/spark-job-historygespeichert. Sie können diese Eigenschaften hinzufügen, um verschiedene Cloud Storage-Speicherorte für diese Dateien anzugeben. Wenn beide Eigenschaften verwendet werden, müssen sie auf Verzeichnisse im selben Bucket verweisen.--properties=spark:spark.history.fs.logDirectory=gs://bucket-name/directory-name/spark-job-history
--properties=spark:spark.eventLog.dir=gs://bucket-name/directory-name/spark-job-history
mapred:mapreduce.jobhistory.done-dirundmapred:mapreduce.jobhistory.intermediate-done-dir: Standardmäßig werden MapReduce-Jobverlaufsdateien im Clustertemp bucketin den Verzeichnissen/mapreduce-job-history/doneund/mapreduce-job-history/intermediate-donegespeichert. Im Zwischenspeichermapreduce.jobhistory.intermediate-done-dirwird vorübergehend gespeichert. Zwischendateien werden nach Abschluss des MapReduce-Jobs an den Speicherortmapreduce.jobhistory.done-dirverschoben. Sie können diese Attribute hinzufügen, um verschiedene Cloud Storage-Speicherorte für diese Dateien anzugeben. Wenn beide Attribute verwendet werden, müssen sie auf Verzeichnisse im selben Bucket verweisen.--properties=mapred:mapreduce.jobhistory.done-dir=gs://bucket-name/directory-name/mapreduce-job-history/done
--properties=mapred:mapreduce.jobhistory.intermediate-done-dir=gs://bucket-name/directory-name/mapreduce-job-history/intermediate-done
spark:spark.history.fs.gs.outputstream.type: Diese Eigenschaft gilt für2.0- und2.1-Cluster mit Image-Versionen, die die Cloud Storage-Connector-Version2.0.xverwenden (die Standard-Connector-Version für2.0- und2.1-Cluster mit Image-Versionen). Damit wird gesteuert, wie Spark-Jobs Daten an Cloud Storage senden. Die Standardeinstellung istBASIC. In diesem Fall werden Daten nach Abschluss des Jobs an Cloud Storage gesendet. WennFLUSHABLE_COMPOSITEfestgelegt ist, werden Daten in regelmäßigen Abständen in Cloud Storage kopiert, während der Job ausgeführt wird. Die Intervalle werden durchspark:spark.history.fs.gs.outputstream.sync.min.interval.msfestgelegt.--properties=spark:spark.history.fs.gs.outputstream.type=FLUSHABLE_COMPOSITE
spark:spark.history.fs.gs.outputstream.sync.min.interval.ms: Diese Eigenschaft gilt für2.0- und2.1-Cluster mit Image-Versionen, die die Cloud Storage-Connector-Version2.0.xverwenden (die Standard-Connector-Version für2.0- und2.1-Cluster mit Image-Versionen). Sie steuert die Häufigkeit in Millisekunden, mit der Daten in Cloud Storage übertragen werden, wennspark:spark.history.fs.gs.outputstream.typeaufFLUSHABLE_COMPOSITEfestgelegt ist. Das Standardzeitintervall ist5000ms. Der Wert für das Zeitintervall in Millisekunden kann mit oder ohne das Suffixmsangegeben werden.--properties=spark:spark.history.fs.gs.outputstream.sync.min.interval.ms=INTERVALms
spark:spark.history.fs.gs.outputstream.sync.min.interval: Diese Eigenschaft gilt für Cluster mit der Image-Version2.2und höher, die die Cloud Storage-Connector-Version3.0.xverwenden (die Standard-Connector-Version für Cluster mit der Image-Version2.2). Es ersetzt das vorherige Attributspark:spark.history.fs.gs.outputstream.sync.min.interval.msund unterstützt Werte mit Zeitangabe wiems,sundm. Sie steuert die Häufigkeit, mit der Daten in Cloud Storage übertragen werden, wennspark:spark.history.fs.gs.outputstream.typeaufFLUSHABLE_COMPOSITEfestgelegt ist.--properties=spark:spark.history.fs.gs.outputstream.sync.min.interval=INTERVAL
dataproc:yarn.atsv2.bigtable.instance: Nachdem Sie YARN Timeline Service v2 konfigurieren haben, fügen Sie diese Property hinzu, um YARN-Zeitachsendaten in die angegebene Bigtable-Instanz zu schreiben, damit sie in den Web-Schnittstellen YARN Application Timeline Service V2 und Tez des PHS-Clusters angezeigt werden können. Hinweis: Die Clustererstellung schlägt fehl, wenn die Bigtable-Instanz nicht vorhanden ist.--properties=dataproc:yarn.atsv2.bigtable.instance=projects/project-id/instance_id/bigtable-instance-id
flink:jobhistory.archive.fs.dir: Der Flink JobManager archiviert abgeschlossene Flink-Jobs, indem er archivierte Jobinformationen in ein Dateisystemverzeichnis hochlädt. Mit diesem Attribut können Sie das Archivverzeichnis inflink-conf.yamlfestlegen.--properties=flink:jobmanager.archive.fs.dir=gs://bucket-name/job-cluster-1/flink-job-history/completed-jobs
PHS mit Spark-Batcharbeitslasten verwenden
So verwenden Sie den Persistent History Server mit serverlosen Dataproc-Batcharbeitslasten für Spark:
Wählen Sie den PHS-Cluster aus oder geben Sie ihn an, wenn Sie eine Spark-Batcharbeitslast senden.
PHS mit Dataproc in Google Kubernetes Engine verwenden
So verwenden Sie den Persistent History Server mit Dataproc in GKE:
Wählen Sie den PHS-Cluster aus oder geben Sie ihn an, wenn Sie einen virtuellen Dataproc-Cluster in GKE erstellen.
Component Gateway-Weboberflächen
Klicken Sie in der Google Cloud Console auf der Dataproc-Seite Cluster auf den Namen des PHS-Clusters, um die Seite Clusterdetails zu öffnen. Wählen Sie auf dem Tab Weboberflächen die Component Gateway-Links aus, um Weboberflächen zu öffnen, die im PHS-Cluster ausgeführt werden.

Weboberfläche des Spark-Verlaufsservers
Der folgende Screenshot zeigt die Web-UI des Spark-History Servers mit Links zu Spark-Jobs, die auf job-cluster-1 und job-cluster-2 ausgeführt werden, nachdem die spark.history.fs.logDirectory und spark:spark.eventLog.dir der Jobcluster und die spark.history.fs.logDirectory-Speicherorte des PHS-Clusters folgendermaßen erstellt wurden:
| job-cluster-1 | gs://example-cloud-storage-bucket/job-cluster-1/spark-job-history |
| job-cluster-2 | gs://example-cloud-storage-bucket/job-cluster-2/spark-job-history |
| phs-cluster | gs://example-cloud-storage-bucket/*/spark-job-history |

Suche nach App-Namen
Sie können Jobs nach Anwendungsname in der Weboberfläche des Spark-Verlaufsservers auflisten, indem Sie einen Anwendungsnamen in das Suchfeld eingeben. App-Namen können auf eine der folgenden Arten festgelegt werden (nach Priorität aufgelistet):
- Wird im Anwendungscode beim Erstellen des Spark-Kontexts festgelegt
- Wird vom Attribut spark.app.name festgelegt, wenn der Job gesendet wird
- Setzen Sie von Dataproc den vollständigen REST-Ressourcennamen für den Job (
projects/project-id/regions/region/jobs/job-id).
Nutzer können einen Begriff für den Namen einer App oder Ressource in das Feld Suchen eingeben, um Jobs zu finden und aufzulisten.
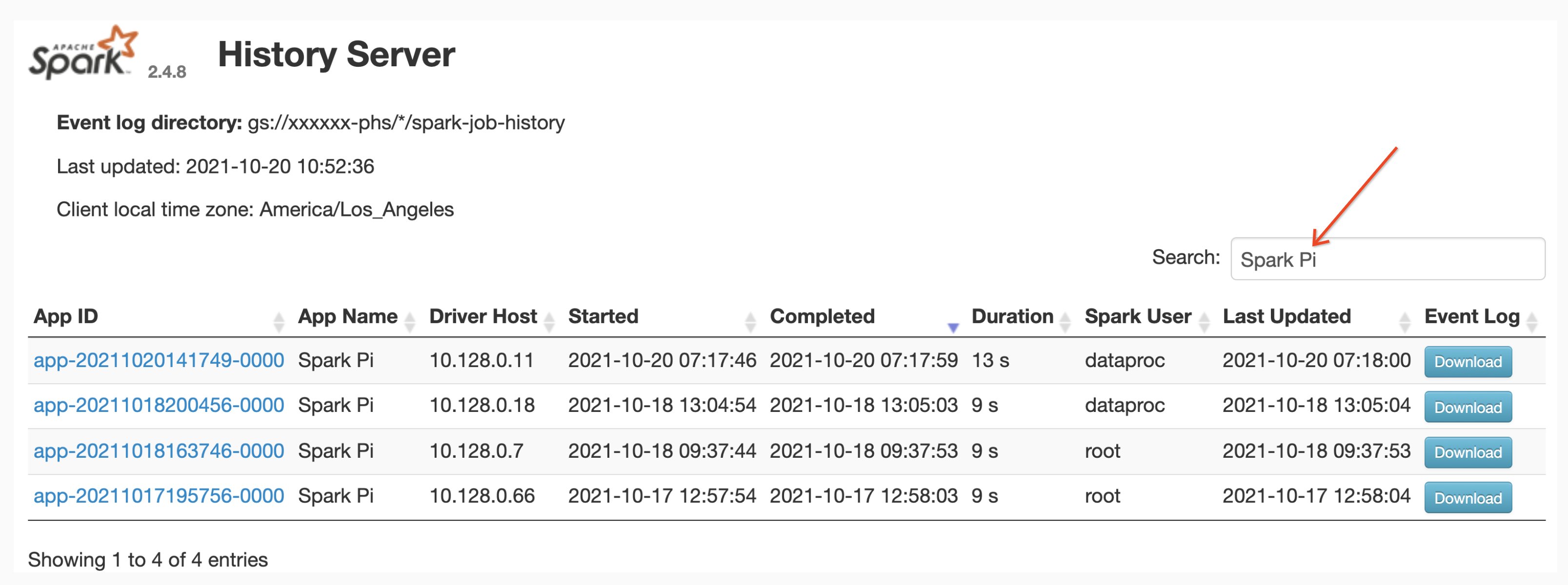
Ereignisprotokolle
Die Web-Benutzeroberfläche des Spark History Server bietet eine Schaltfläche Ereignislog, auf die Sie klicken können, um Spark-Ereignislogs herunterzuladen. Diese Logs sind nützlich, um den Lebenszyklus der Spark-Anwendung zu untersuchen.
Spark-Jobs
Spark-Anwendungen sind in mehrere Jobs unterteilt, die weiter in mehrere Phasen unterteilt werden. Jede Phase kann mehrere Aufgaben enthalten, die auf Executor-Knoten (Workern) ausgeführt werden.

Klicken Sie in der Weboberfläche auf eine Spark-Anwendungs-ID, um die Seite „Spark-Jobs“ zu öffnen, die eine Ereigniszeitachse und eine Zusammenfassung der Jobs innerhalb der Anwendung enthält.

Klicken Sie auf einen Job, um die Seite "Jobdetails" mit einem gerichteten azyklischen Graphen (Directed Acyclic Graph, DAG) und einer Zusammenfassung der Jobphasen zu öffnen.

Klicken Sie auf eine Phase oder verwenden Sie den Tab „Phasen“, um eine Phase auszuwählen und die Seite „Phasendetails“ zu öffnen.
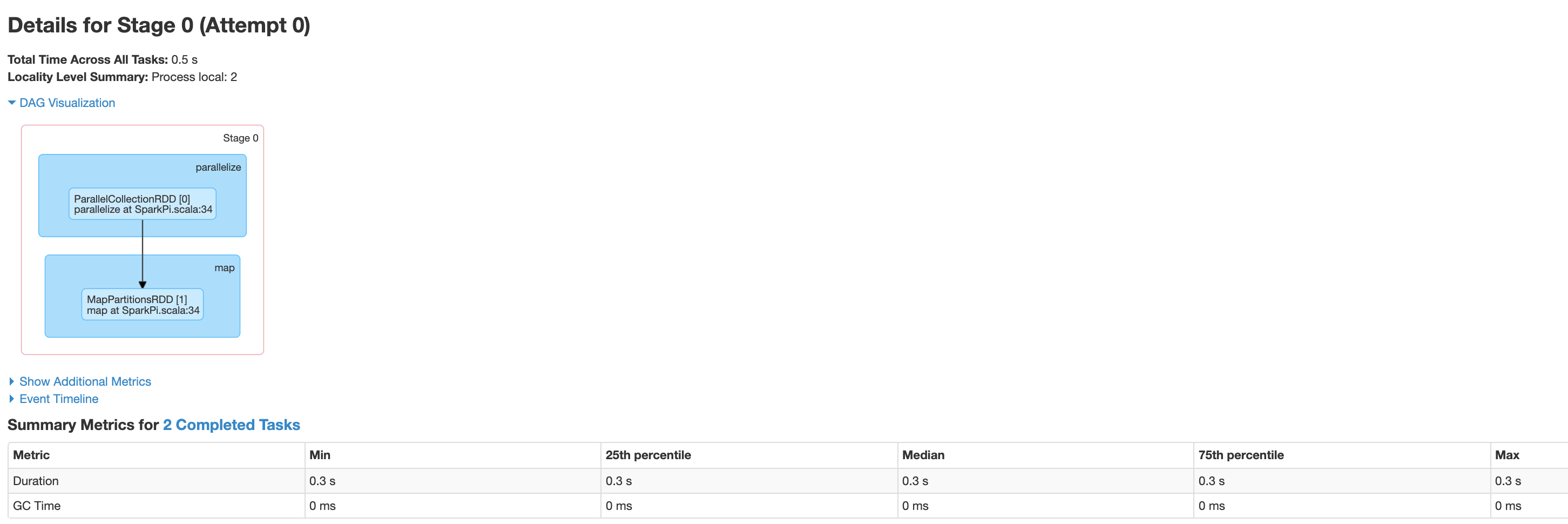
Stage Details umfassen eine DAG-Visualisierung, eine Ereigniszeitachse und Messwerte für die Aufgaben innerhalb der Phase. Auf dieser Seite können Sie Probleme mit strangulierten Aufgaben, Planerverzögerungen und Speichermangel beheben. Der DAG-Visualisierer zeigt die Codezeile, aus der die Phase abgeleitet ist, sodass Sie Probleme wieder im Code verfolgen können.
Klicken Sie auf den Tab „Executors“, um Informationen zu den Treiber- und Executor-Knoten der Spark-Anwendung aufzurufen.

Wichtige Informationen auf dieser Seite umfassen die Anzahl der Kerne und die Anzahl der Aufgaben, die auf jedem Executor ausgeführt wurden.
Tez-Weboberfläche
Tez ist die Standard-Ausführungs-Engine für Hive und Pig in Dataproc. Wenn Sie einen Hive-Job in einem Dataproc-Jobcluster senden, wird eine Tez-Anwendung gestartet.
Wenn Sie Yarn Timeline Service v2 konfiguriert und das Attribut dataproc:yarn.atsv2.bigtable.instance beim Erstellen des PHS- und des Dataproc-Jobclusters festgelegt haben, schreibt YARN generierte Zeitachsendaten für Hive- und Pig-Jobs in die angegebene Bigtable-Instanz, damit sie in der Tez-Weboberfläche abgerufen und angezeigt werden können, die auf dem PHS-Server ausgeführt wird.

Weboberfläche für YARN Application Timeline V2
Wenn Sie YARN Timeline Service v2 konfiguriert und das Attribut dataproc:yarn.atsv2.bigtable.instance beim Erstellen des PHS- und Dataproc-Jobclusters festgelegt haben, schreibt YARN generierte Jobzeitachsendaten in die angegebene Bigtable-Instanz, damit sie abgerufen und in der Weboberfläche des YARN Application Timeline Service angezeigt werden können, die auf dem PHS-Server ausgeführt wird. Dataproc-Jobs werden in der Weboberfläche auf dem Tab Flow Activity (Ablaufaktivität) aufgeführt.

Yarn Timeline Service v2 konfigurieren
So konfigurieren Sie den Yarn Timeline Service v2: Richten Sie eine Bigtable-Instanz ein und prüfen Sie bei Bedarf die Dienstkontorollen.
Prüfen Sie bei Bedarf die Rollen des Dienstkontos. Das standardmäßige VM-Dienstkonto, das von Dataproc-Cluster-VMs verwendet wird, hat die Berechtigungen, die zum Erstellen und Konfigurieren der Bigtable-Instanz für den YARN Timeline Service erforderlich sind. Wenn Sie Ihren Job oder PHS-Cluster mit einem benutzerdefinierten VM-Dienstkonto erstellen, muss das Konto entweder die Bigtable-Rolle
AdministratoroderBigtable Userhaben.
Erforderliches Tabellenschema
Die Dataproc-PHS-Unterstützung für YARN Timeline Service v2 erfordert ein bestimmtes Schema, das in der Bigtable-Instanz erstellt wurde. Dataproc erstellt das erforderliche Schema, wenn ein Jobcluster oder PHS-Cluster mit dem Attribut dataproc:yarn.atsv2.bigtable.instance erstellt wird, das auf die Bigtable-Instanz verweist.
Das erforderliche Bigtable-Instanzschema:
| Tabellen | Spaltenfamilien |
|---|---|
| prod.timelineservice.application | c,i,m |
| prod.timelineservice.app_flow | m |
| prod.timelineservice.entity | c,i,m |
| prod.timelineservice.flowactivity | i |
| prod.timelineservice.flowrun | i |
| prod.timelineservice.subapplication | c,i,m |
Automatische Speicherbereinigung in Bigtable
Sie können die altersbasierte automatische Speicherbereinigung von Bigtable für ATSv2-Tabellen konfigurieren:
Installieren Sie cbt (einschließlich der Erstellung des
.cbrtc file).Erstellen Sie die altersbasierte Richtlinie zur automatischen Speicherbereinigung für ATSv2:
export NUMBER_OF_DAYS = number \
cbt setgcpolicy prod.timelineservice.application c maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.application i maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.application m maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.app_flow m maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.entity c maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.entity i maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.entity m maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.flowactivity i maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.flowrun i maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.subapplication c maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.subapplication i maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.subapplication m maxage=${NUMBER_OF_DAYS}
Hinweise:
NUMBER_OF_DAYS: Die maximale Anzahl von Tagen beträgt 30d.