Saat membuat cluster Dataproc, Anda dapat mengaktifkan Autentikasi Cluster Pribadi Dataproc agar beban kerja interaktif di cluster dapat berjalan dengan aman sebagai identitas pengguna Anda. Artinya, interaksi dengan resource Google Cloud lain seperti Cloud Storage akan diautentikasi sebagai diri Anda, bukan akun layanan cluster.
Pertimbangan
Saat Anda membuat cluster dengan Autentikasi Cluster Pribadi yang diaktifkan, cluster hanya dapat digunakan oleh identitas Anda. Pengguna lain tidak akan dapat menjalankan tugas di cluster atau mengakses endpoint Component Gateway di cluster.
Cluster dengan Autentikasi Cluster Pribadi yang diaktifkan akan memblokir akses SSH dan fitur Compute Engine seperti skrip startup di semua VM dalam cluster.
Cluster yang mengaktifkan Autentikasi Cluster Pribadi akan otomatis mengaktifkan dan mengonfigurasi Kerberos di cluster untuk komunikasi intra-cluster yang aman. Namun, semua identitas Kerberos di cluster akan berinteraksi dengan Google Cloud resource sebagai pengguna yang sama.
Cluster yang mengaktifkan Autentikasi Cluster Pribadi tidak mendukung image kustom.
Autentikasi Cluster Pribadi Dataproc tidak mendukung alur kerja Dataproc.
Autentikasi Cluster Pribadi Dataproc hanya ditujukan untuk tugas interaktif yang dijalankan oleh pengguna individu (manusia). Tugas dan operasi yang berjalan lama harus mengonfigurasi dan menggunakan identitas akun layanan yang sesuai.
Kredensial yang diteruskan diperkecil cakupannya dengan Batas Akses Kredensial. Batas akses default terbatas pada pembacaan dan penulisan objek Cloud Storage di bucket Cloud Storage yang dimiliki oleh project yang sama dengan yang berisi cluster. Anda dapat menentukan batas akses non-default saat enable_an_interactive_session.
Autentikasi Cluster Pribadi Dataproc menggunakan atribut tamu Compute Engine. Jika fitur atribut tamu dinonaktifkan, Autentikasi Cluster Pribadi akan gagal.
Tujuan
Buat cluster Dataproc dengan Autentikasi Cluster Pribadi Dataproc diaktifkan.
Mulai propagasi kredensial ke cluster.
Gunakan notebook Jupyter di cluster untuk menjalankan tugas Spark yang mengautentikasi dengan kredensial Anda.
Sebelum Memulai
Buat Project
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Dataproc API.
-
Install the Google Cloud CLI.
-
Jika Anda menggunakan penyedia identitas (IdP) eksternal, Anda harus login ke gcloud CLI dengan identitas gabungan Anda terlebih dahulu.
-
Untuk melakukan inisialisasi gcloud CLI, jalankan perintah berikut:
gcloud init -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Dataproc API.
-
Install the Google Cloud CLI.
-
Jika Anda menggunakan penyedia identitas (IdP) eksternal, Anda harus login ke gcloud CLI dengan identitas gabungan Anda terlebih dahulu.
-
Untuk melakukan inisialisasi gcloud CLI, jalankan perintah berikut:
gcloud init - Mulai sesi Cloud Shell.
- Jalankan
gcloud auth loginuntuk mendapatkan kredensial pengguna yang valid. Temukan alamat email akun aktif Anda di gcloud.
gcloud auth list --filter=status=ACTIVE --format="value(account)"
Membuat cluster.
gcloud dataproc clusters create CLUSTER_NAME \ --properties=dataproc:dataproc.personal-auth.user=your-email-address \ --enable-component-gateway \ --optional-components=JUPYTER \ --region=REGION
Aktifkan sesi propagasi kredensial untuk cluster agar mulai menggunakan kredensial pribadi Anda saat berinteraksi dengan resource Google Cloud.
gcloud dataproc clusters enable-personal-auth-session \ --region=REGION \ CLUSTER_NAME
Contoh output:
Injecting initial credentials into the cluster CLUSTER_NAME...done. Periodically refreshing credentials for cluster CLUSTER_NAME. This will continue running until the command is interrupted...
Contoh batas akses yang dipersempit: Contoh berikut mengaktifkan sesi autentikasi pribadi yang lebih ketat daripada batas akses kredensial yang dipersempit secara default. Hal ini membatasi akses ke bucket penyiapan cluster Dataproc (lihat Mengecilkan Cakupan dengan Batas Akses Kredensial untuk mengetahui informasi selengkapnya).
gcloud dataproc clusters enable-personal-auth-session \ --project=PROJECT_ID \ --region=REGION \ --access-boundary=<(echo -n "{ \ \"access_boundary\": { \ \"accessBoundaryRules\": [{ \ \"availableResource\": \"//storage.googleapis.com/projects/_/buckets/$(gcloud dataproc clusters describe --project=PROJECT_ID --region=REGION CLUSTER_NAME --format="value(config.configBucket)")\", \ \"availablePermissions\": [ \ \"inRole:roles/storage.objectViewer\", \ \"inRole:roles/storage.objectCreator\", \ \"inRole:roles/storage.objectAdmin\", \ \"inRole:roles/storage.legacyBucketReader\" \ ] \ }] \ } \ }") \ CLUSTER_NAME
Biarkan perintah tetap berjalan dan beralih ke tab Cloud Shell atau sesi terminal baru. Klien akan memperbarui kredensial saat perintah sedang berjalan.
Ketik
Ctrl-Cuntuk mengakhiri sesi.- Dapatkan detail cluster.
gcloud dataproc clusters describe CLUSTER_NAME --region=REGION
URL antarmuka Web Jupyter tercantum dalam detail cluster.
... JupyterLab: https://UUID-dot-us-central1.dataproc.googleusercontent.com/jupyter/lab/ ...
- Salin URL ke browser lokal Anda untuk meluncurkan UI Jupyter.
- Pastikan autentikasi cluster pribadi berhasil.
- Mulai terminal Jupyter.
- Jalankan
gcloud auth list - Pastikan nama pengguna Anda adalah satu-satunya akun yang aktif.
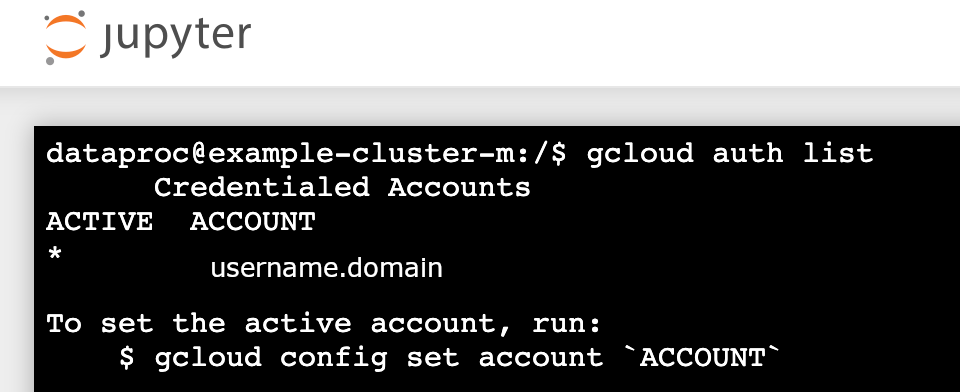
- Di terminal Jupyter, aktifkan Jupyter untuk melakukan autentikasi dengan Kerberos dan mengirimkan tugas Spark.
kinit -kt /etc/security/keytab/dataproc.service.keytab dataproc/$(hostname -f)
- Jalankan
klistuntuk memverifikasi bahwa Jupyter mendapatkan TGT yang valid.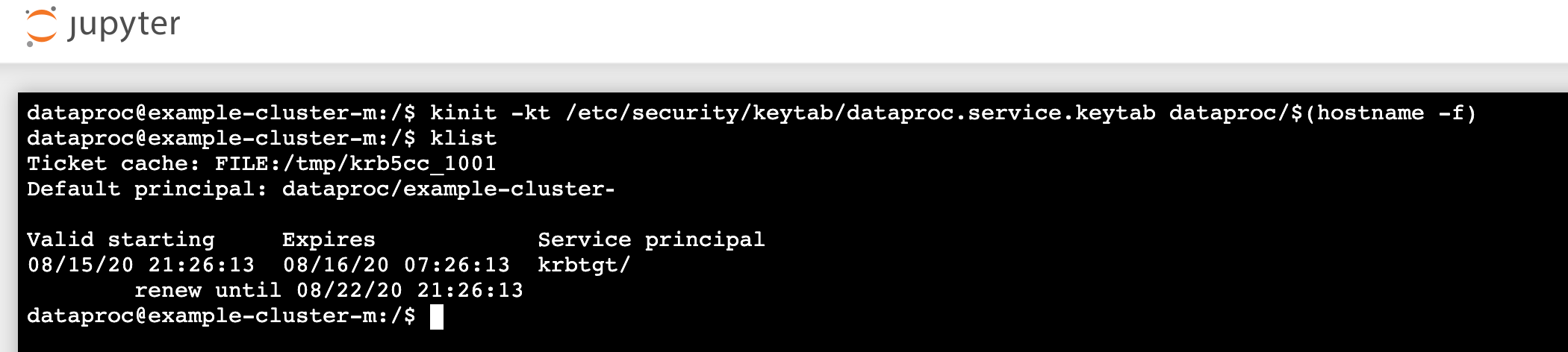
- Jalankan
- Di terminal Juypter, gunakan gcloud CLI untuk membuat file
rose.txtdi bucket Cloud Storage dalam project Anda.echo "A rose by any other name would smell as sweet" > /tmp/rose.txt
gcloud storage cp /tmp/rose.txt gs://bucket-name/rose.txt
- Tandai file sebagai pribadi sehingga hanya akun pengguna Anda yang dapat membaca atau
menulisnya. Jupyter akan menggunakan kredensial pribadi Anda saat berinteraksi dengan Cloud Storage.
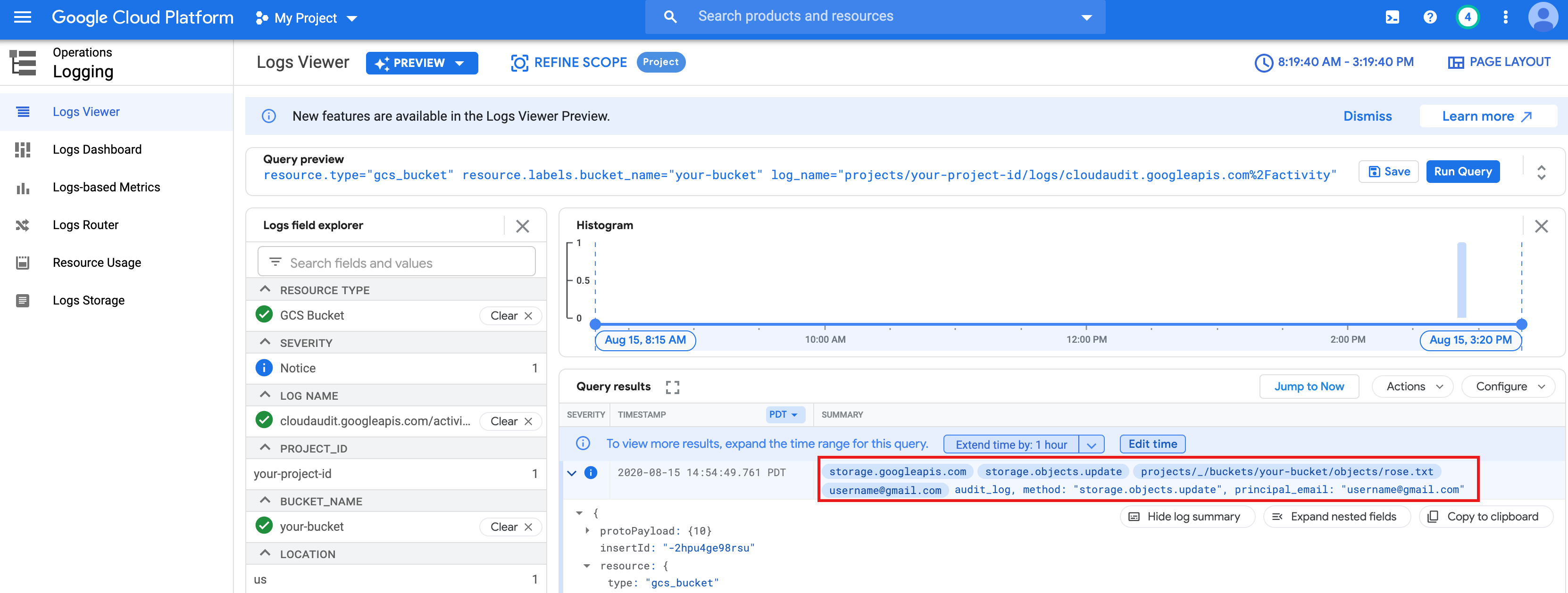
gcloud storage objects update gs://bucket-name/rose.txt --predefined-acl=private
- Verifikasi akses pribadi Anda.
gcloud storage objects describe gs://$BUCKET/rose.txt
acl:
- Tandai file sebagai pribadi sehingga hanya akun pengguna Anda yang dapat membaca atau
menulisnya. Jupyter akan menggunakan kredensial pribadi Anda saat berinteraksi dengan Cloud Storage.
- email: $USER entity: user-$USER role: OWNER
- Klik link Component Gateway Jupyter untuk meluncurkan UI Jupyter.
- Pastikan autentikasi cluster pribadi berhasil.
- Mulai terminal Jupyter
- Jalankan
gcloud auth list - Pastikan nama pengguna Anda adalah satu-satunya akun yang aktif.
- Di terminal Jupyter, aktifkan Jupyter untuk melakukan autentikasi dengan Kerberos dan mengirimkan tugas Spark.
kinit -kt /etc/security/keytab/dataproc.service.keytab dataproc/$(hostname -f)
- Jalankan
klistuntuk memverifikasi bahwa Jupyter mendapatkan TGT yang valid.
- Jalankan
- Di terminal Jupyter, gunakan gcloud CLI untuk membuat file
rose.txtdi bucket Cloud Storage dalam project Anda.echo "A rose by any other name would smell as sweet" > /tmp/rose.txt
gcloud storage cp /tmp/rose.txt gs://bucket-name/rose.txt
- Tandai file sebagai pribadi sehingga hanya akun pengguna Anda yang dapat membaca atau
menulisnya. Jupyter akan menggunakan kredensial pribadi Anda saat berinteraksi dengan Cloud Storage.
gcloud storage objects update gs://bucket-name/rose.txt --predefined-acl=private
- Verifikasi akses pribadi Anda.
gcloud storage objects describe gs://bucket-name/rose.txt
acl:
- Tandai file sebagai pribadi sehingga hanya akun pengguna Anda yang dapat membaca atau
menulisnya. Jupyter akan menggunakan kredensial pribadi Anda saat berinteraksi dengan Cloud Storage.
- email: $USER entity: user-$USER role: OWNER
- Buka folder, lalu buat notebook PySpark.
Jalankan tugas penghitungan kata dasar terhadap file
rose.txtyang Anda buat di atas.text_file = sc.textFile("gs://bucket-name/rose.txt") counts = text_file.flatMap(lambda line: line.split(" ")) \ .map(lambda word: (word, 1)) \ .reduceByKey(lambda a, b: a + b) print(counts.collect())rose.txtdi Cloud Storage karena berjalan dengan kredensial pengguna Anda.Anda juga dapat memeriksa Log Audit Bucket Cloud Storage untuk memverifikasi bahwa tugas mengakses Cloud Storage dengan identitas Anda (lihat Cloud Audit Logs dengan Cloud Storage untuk mengetahui informasi selengkapnya).
- Hapus cluster Dataproc.
gcloud dataproc clusters delete CLUSTER_NAME --region=REGION
Mengonfigurasi Lingkungan
Konfigurasi lingkungan dari Cloud Shell atau terminal lokal: