Quando crei un cluster Dataproc, puoi abilitare l'autenticazione cluster personale di Dataproc per consentire l'esecuzione sicura dei carichi di lavoro interattivi sul cluster con la tua identità utente. Ciò significa che le interazioni con altre risorse Google Cloud come Cloud Storage verranno autenticate come tue anziché come account di servizio del cluster.
Considerazioni
Quando crei un cluster con l'autenticazione cluster personale abilitata, il cluster sarà utilizzabile solo dalla tua identità. Gli altri utenti non potranno eseguire job sul cluster o accedere agli endpoint del Component Gateway sul cluster.
I cluster con l'autenticazione cluster personale abilitata bloccano l'accesso SSH e le funzionalità di Compute Engine come gli script di avvio su tutte le VM del cluster.
I cluster con l'autenticazione cluster personale abilitata attivano e configurano automaticamente Kerberos sul cluster per una comunicazione intracluster sicura. Tuttavia, tutte le identità Kerberos sul cluster interagiranno con Google Cloud le risorse come lo stesso utente.
I cluster con l'autenticazione cluster personale abilitata non supportano immagini personalizzate.
L'autenticazione cluster personale di Dataproc non supporta i workflow Dataproc.
L'autenticazione cluster personale di Dataproc è destinata solo ai job interattivi eseguiti da un singolo utente (persona). I job e le operazioni a lunga esecuzione devono configurare e utilizzare un'identità account di servizio appropriata.
Le credenziali propagate vengono ridotte con un limite di accesso alle credenziali. Il limite di accesso predefinito è limitato alla lettura e alla scrittura di oggetti Cloud Storage nei bucket Cloud Storage di proprietà dello stesso progetto che contiene il cluster. Puoi definire un limite di accesso non predefinito quando enable_an_interactive_session.
L'autenticazione cluster personale di Dataproc utilizza gli attributi guest di Compute Engine. Se la funzionalità degli attributi guest è disattivata, l'autenticazione cluster personale non andrà a buon fine.
Obiettivi
Crea un cluster Dataproc con l'autenticazione cluster personale di Dataproc abilitata.
Avvia la propagazione delle credenziali al cluster.
Utilizza un notebook Jupyter sul cluster per eseguire job Spark che si autenticano con le tue credenziali.
Prima di iniziare
Crea un progetto
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Dataproc API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Install the Google Cloud CLI.
-
Se utilizzi un provider di identità (IdP) esterno, devi prima accedere a gcloud CLI con la tua identità federata.
-
Per inizializzare gcloud CLI, esegui questo comando:
gcloud init -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Dataproc API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Install the Google Cloud CLI.
-
Se utilizzi un provider di identità (IdP) esterno, devi prima accedere a gcloud CLI con la tua identità federata.
-
Per inizializzare gcloud CLI, esegui questo comando:
gcloud init - Avvia una sessione di Cloud Shell.
- Esegui
gcloud auth loginper ottenere credenziali utente valide. Trova l'indirizzo email del tuo account attivo in gcloud.
gcloud auth list --filter=status=ACTIVE --format="value(account)"
Creare un cluster.
gcloud dataproc clusters create CLUSTER_NAME \ --properties=dataproc:dataproc.personal-auth.user=your-email-address \ --enable-component-gateway \ --optional-components=JUPYTER \ --region=REGION
Abilita una sessione di propagazione delle credenziali per il cluster per iniziare a utilizzare le tue credenziali personali quando interagisci con le risorse Google Cloud.
gcloud dataproc clusters enable-personal-auth-session \ --region=REGION \ CLUSTER_NAME
Esempio di output:
Injecting initial credentials into the cluster CLUSTER_NAME...done. Periodically refreshing credentials for cluster CLUSTER_NAME. This will continue running until the command is interrupted...
Esempio di limite di accesso con ambito ridotto: L'esempio seguente abilita una sessione di autenticazione personale più restrittiva rispetto al limite di accesso predefinito delle credenziali con ambito ridotto. Limita l'accesso al bucket di staging del cluster Dataproc (per ulteriori informazioni, consulta Riduzione dell'ambito mediante confini per l'accesso con credenziali ).
gcloud dataproc clusters enable-personal-auth-session \ --project=PROJECT_ID \ --region=REGION \ --access-boundary=<(echo -n "{ \ \"access_boundary\": { \ \"accessBoundaryRules\": [{ \ \"availableResource\": \"//storage.googleapis.com/projects/_/buckets/$(gcloud dataproc clusters describe --project=PROJECT_ID --region=REGION CLUSTER_NAME --format="value(config.configBucket)")\", \ \"availablePermissions\": [ \ \"inRole:roles/storage.objectViewer\", \ \"inRole:roles/storage.objectCreator\", \ \"inRole:roles/storage.objectAdmin\", \ \"inRole:roles/storage.legacyBucketReader\" \ ] \ }] \ } \ }") \ CLUSTER_NAME
Mantieni in esecuzione il comando e passa a una nuova scheda di Cloud Shell o a una nuova sessione del terminale. Il client aggiornerà le credenziali durante l'esecuzione del comando.
Digita
Ctrl-Cper terminare la sessione.- Recupera i dettagli del cluster.
gcloud dataproc clusters describe CLUSTER_NAME --region=REGION
L'URL dell'interfaccia web di Jupyter è elencato nei dettagli del cluster.
... JupyterLab: https://UUID-dot-us-central1.dataproc.googleusercontent.com/jupyter/lab/ ...
- Copia l'URL nel browser locale per avviare la GUI di Jupyter.
- Controlla che l'autenticazione del cluster personale sia andata a buon fine.
- Avvia un terminale Jupyter.
- Esegui
gcloud auth list - Verifica che il tuo nome utente sia l'unico account attivo.
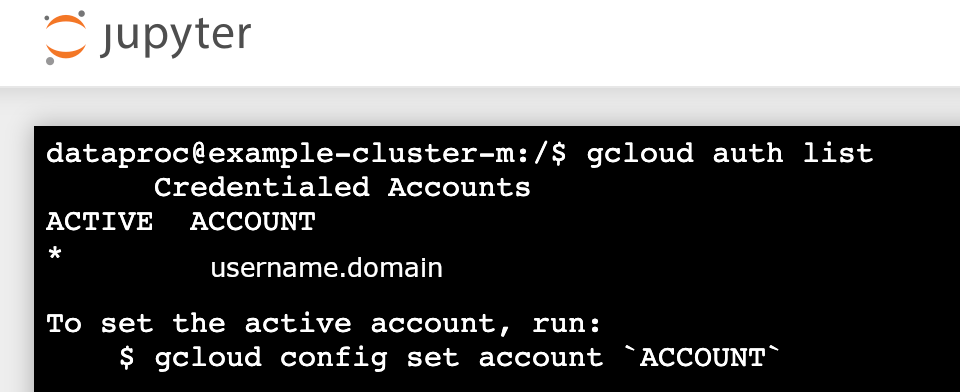
- In un terminale Jupyter, abilita Jupyter per l'autenticazione con Kerberos e invia job Spark.
kinit -kt /etc/security/keytab/dataproc.service.keytab dataproc/$(hostname -f)
- Esegui
klistper verificare che Jupyter abbia ottenuto un TGT valido.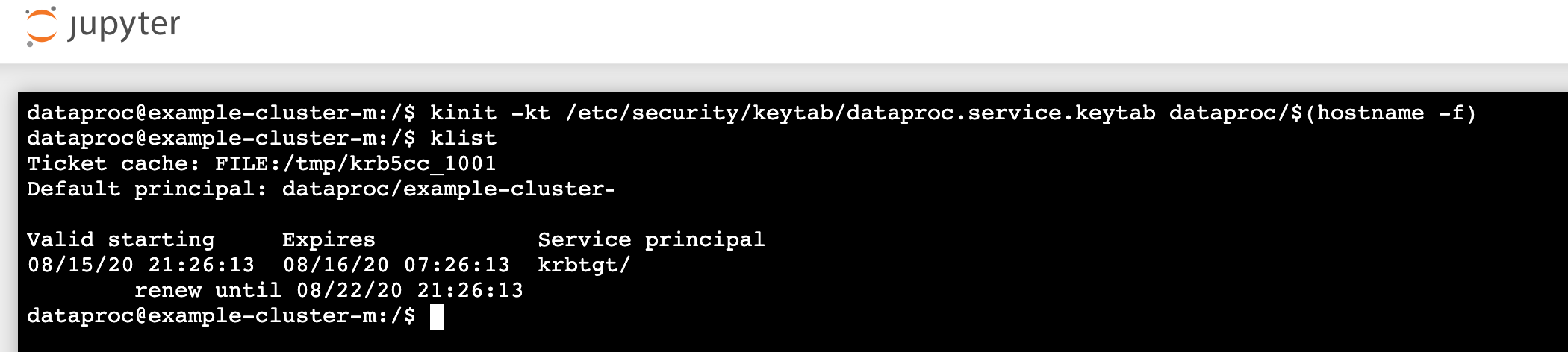
- Esegui
- In un terminale Jupyter, utilizza gcloud CLI per creare un file
rose.txtin un bucket Cloud Storage nel tuo progetto.echo "A rose by any other name would smell as sweet" > /tmp/rose.txt
gcloud storage cp /tmp/rose.txt gs://bucket-name/rose.txt
- Contrassegna il file come privato in modo che solo il tuo account utente possa leggerlo o
scriverlo. Jupyter utilizzerà le tue credenziali personali quando interagisce
con Cloud Storage.
gcloud storage objects update gs://bucket-name/rose.txt --predefined-acl=private
- Verifica l'accesso privato.
gcloud storage objects describe gs://$BUCKET/rose.txt
acl:
- Contrassegna il file come privato in modo che solo il tuo account utente possa leggerlo o
scriverlo. Jupyter utilizzerà le tue credenziali personali quando interagisce
con Cloud Storage.
- email: $USER entity: user-$USER role: OWNER
- Fai clic sul link Component Gateway Jupyter per avviare l'interfaccia utente di Jupyter.
- Controlla che l'autenticazione del cluster personale sia andata a buon fine.
- Avvia un terminale Jupyter
- Esegui
gcloud auth list - Verifica che il tuo nome utente sia l'unico account attivo.
- In un terminale Jupyter, abilita Jupyter per l'autenticazione con Kerberos e invia job Spark.
kinit -kt /etc/security/keytab/dataproc.service.keytab dataproc/$(hostname -f)
- Esegui
klistper verificare che Jupyter abbia ottenuto un TGT valido.
- Esegui
- In un terminale Jupyter, utilizza gcloud CLI per creare un file
rose.txtin un bucket Cloud Storage nel tuo progetto.echo "A rose by any other name would smell as sweet" > /tmp/rose.txt
gcloud storage cp /tmp/rose.txt gs://bucket-name/rose.txt
- Contrassegna il file come privato in modo che solo il tuo account utente possa leggerlo o
scriverlo. Jupyter utilizzerà le tue credenziali personali quando interagisce
con Cloud Storage.
gcloud storage objects update gs://bucket-name/rose.txt --predefined-acl=private
- Verifica l'accesso privato.
gcloud storage objects describe gs://bucket-name/rose.txt
acl:
- Contrassegna il file come privato in modo che solo il tuo account utente possa leggerlo o
scriverlo. Jupyter utilizzerà le tue credenziali personali quando interagisce
con Cloud Storage.
- email: $USER entity: user-$USER role: OWNER
- Vai a una cartella, poi crea un notebook PySpark.
Esegui un job di conteggio delle parole di base sul file
rose.txtche hai creato sopra.text_file = sc.textFile("gs://bucket-name/rose.txt") counts = text_file.flatMap(lambda line: line.split(" ")) \ .map(lambda word: (word, 1)) \ .reduceByKey(lambda a, b: a + b) print(counts.collect())rose.txtin Cloud Storage perché viene eseguito con le tue credenziali utente.Puoi anche controllare gli audit log del bucket Cloud Storage per verificare che il job acceda a Cloud Storage con la tua identità (per ulteriori informazioni, vedi Audit log di Cloud con Cloud Storage).
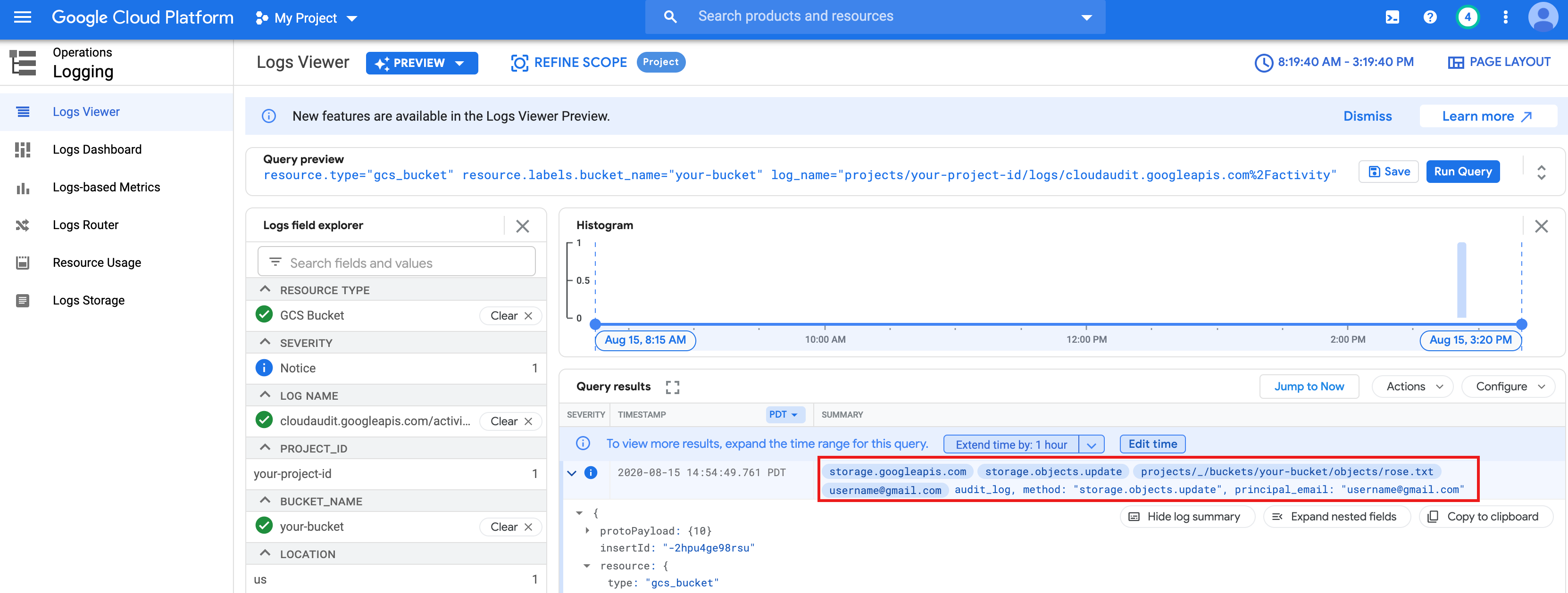
- Elimina il cluster Dataproc.
gcloud dataproc clusters delete CLUSTER_NAME --region=REGION
Configura l'ambiente
Configura l'ambiente da Cloud Shell o da un terminale locale: