Cuando creas un clúster de Dataproc, puedes habilitar la autenticación de clústeres personales de Dataproc para que las cargas de trabajo interactivas del clúster se ejecuten de forma segura con tu identidad de usuario. Esto significa que las interacciones con otros Google Cloud recursos, como Cloud Storage, se autenticarán como tú en lugar de como la cuenta de servicio del clúster.
Cuestiones importantes
Cuando creas un clúster con la autenticación de clúster personal habilitada, solo tu identidad podrá usarlo. Otros usuarios no podrán ejecutar trabajos en el clúster ni acceder a los endpoints de Component Gateway del clúster.
Los clústeres con la autenticación de clúster personal habilitada bloquean el acceso SSH y las funciones de Compute Engine, como las secuencias de comandos de inicio, en todas las VMs del clúster.
En los clústeres en los que está habilitada la autenticación de clústeres personales, Kerberos se habilita y configura automáticamente para que la comunicación dentro del clúster sea segura. Sin embargo, todas las identidades de Kerberos del clúster interactuarán con los recursos como el mismo usuario. Google Cloud
Los clústeres con la autenticación de clúster personal habilitada no admiten imágenes personalizadas.
La autenticación de clústeres personales de Dataproc no es compatible con los flujos de trabajo de Dataproc.
La autenticación de clústeres personales de Dataproc solo está pensada para las tareas interactivas que ejecute un usuario (una persona). Los trabajos y las operaciones de larga duración deben configurar y usar una identidad de cuenta de servicio adecuada.
Las credenciales propagadas se restringen con un límite de acceso de credenciales. El límite de acceso predeterminado se limita a la lectura y escritura de objetos de Cloud Storage en segmentos de Cloud Storage propiedad del mismo proyecto que contiene el clúster. Puedes definir un límite de acceso no predeterminado cuando enable_an_interactive_session.
La autenticación de clústeres personales de Dataproc usa atributos de invitado de Compute Engine. Si la función de atributos de invitado está inhabilitada, la autenticación de clúster personal fallará.
Objetivos
Crea un clúster de Dataproc con la autenticación de clústeres personales de Dataproc habilitada.
Inicia la propagación de credenciales al clúster.
Usa un cuaderno de Jupyter en el clúster para ejecutar tareas de Spark que se autentiquen con tus credenciales.
Antes de empezar
Crear un proyecto
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Dataproc API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Install the Google Cloud CLI.
-
Si utilizas un proveedor de identidades (IdP) externo, primero debes iniciar sesión en la CLI de gcloud con tu identidad federada.
-
Para inicializar gcloud CLI, ejecuta el siguiente comando:
gcloud init -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Dataproc API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Install the Google Cloud CLI.
-
Si utilizas un proveedor de identidades (IdP) externo, primero debes iniciar sesión en la CLI de gcloud con tu identidad federada.
-
Para inicializar gcloud CLI, ejecuta el siguiente comando:
gcloud init - Inicia una sesión de Cloud Shell.
- Ejecuta
gcloud auth loginpara obtener credenciales de usuario válidas. Busca la dirección de correo de tu cuenta activa en gcloud.
gcloud auth list --filter=status=ACTIVE --format="value(account)"
Crea un clúster.
gcloud dataproc clusters create CLUSTER_NAME \ --properties=dataproc:dataproc.personal-auth.user=your-email-address \ --enable-component-gateway \ --optional-components=JUPYTER \ --region=REGION
Habilita una sesión de propagación de credenciales para el clúster para empezar a usar tus credenciales personales al interactuar con recursos de Google Cloud.
gcloud dataproc clusters enable-personal-auth-session \ --region=REGION \ CLUSTER_NAME
Ejemplo de salida:
Injecting initial credentials into the cluster CLUSTER_NAME...done. Periodically refreshing credentials for cluster CLUSTER_NAME. This will continue running until the command is interrupted...
Ejemplo de límite de acceso con permisos reducidos: En el siguiente ejemplo, se habilita una sesión de autenticación personal que es más restrictiva que el límite de acceso de credenciales con permisos reducidos predeterminado. Restringe el acceso al contenedor de almacenamiento provisional del clúster de Dataproc (consulta Restringir permisos con límites de acceso a credenciales para obtener más información).
gcloud dataproc clusters enable-personal-auth-session \ --project=PROJECT_ID \ --region=REGION \ --access-boundary=<(echo -n "{ \ \"access_boundary\": { \ \"accessBoundaryRules\": [{ \ \"availableResource\": \"//storage.googleapis.com/projects/_/buckets/$(gcloud dataproc clusters describe --project=PROJECT_ID --region=REGION CLUSTER_NAME --format="value(config.configBucket)")\", \ \"availablePermissions\": [ \ \"inRole:roles/storage.objectViewer\", \ \"inRole:roles/storage.objectCreator\", \ \"inRole:roles/storage.objectAdmin\", \ \"inRole:roles/storage.legacyBucketReader\" \ ] \ }] \ } \ }") \ CLUSTER_NAME
Mantén el comando en ejecución y cambia a una nueva pestaña de Cloud Shell o a una sesión de terminal. El cliente actualizará las credenciales mientras se ejecuta el comando.
Escribe
Ctrl-Cpara finalizar la sesión.- Obtener detalles de clúster.
gcloud dataproc clusters describe CLUSTER_NAME --region=REGION
La URL de la interfaz web de Jupyter se indica en los detalles del clúster.
... JupyterLab: https://UUID-dot-us-central1.dataproc.googleusercontent.com/jupyter/lab/ ...
- Copia la URL en tu navegador local para iniciar la interfaz de usuario de Jupyter.
- Comprueba que la autenticación de clúster personal se haya realizado correctamente.
- Inicia una terminal de Jupyter.
- Ejecutar
gcloud auth list - Comprueba que tu nombre de usuario sea la única cuenta activa.
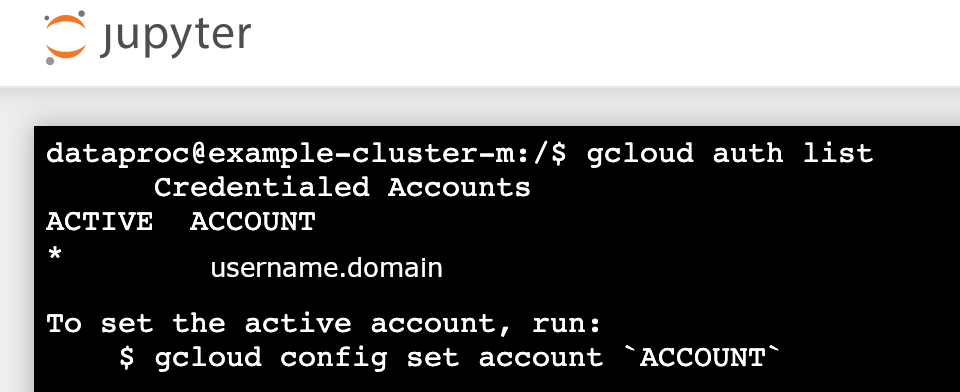
- En un terminal de Jupyter, habilita Jupyter para que se autentique con Kerberos y envíe tareas de Spark.
kinit -kt /etc/security/keytab/dataproc.service.keytab dataproc/$(hostname -f)
- Ejecuta
klistpara verificar que Jupyter ha obtenido un TGT válido.
- Ejecuta
- En un terminal de Jupyter, usa la CLI de gcloud para crear un
rose.txtarchivo en un segmento de Cloud Storage de tu proyecto.echo "A rose by any other name would smell as sweet" > /tmp/rose.txt
gcloud storage cp /tmp/rose.txt gs://bucket-name/rose.txt
- Marca el archivo como privado para que solo tu cuenta de usuario pueda leerlo o escribir en él. Jupyter usará tus credenciales personales al interactuar con Cloud Storage.
gcloud storage objects update gs://bucket-name/rose.txt --predefined-acl=private
- Verifica tu acceso privado.
gcloud storage objects describe gs://$BUCKET/rose.txt
acl:
- Marca el archivo como privado para que solo tu cuenta de usuario pueda leerlo o escribir en él. Jupyter usará tus credenciales personales al interactuar con Cloud Storage.
- email: $USER entity: user-$USER role: OWNER
- Haz clic en el enlace Jupyter de pasarela de componentes para iniciar la interfaz de usuario de Jupyter.
- Comprueba que la autenticación de clúster personal se haya realizado correctamente.
- Iniciar una terminal de Jupyter
- Ejecutar
gcloud auth list - Comprueba que tu nombre de usuario sea la única cuenta activa.
- En un terminal de Jupyter, habilita Jupyter para que se autentique con Kerberos y envíe tareas de Spark.
kinit -kt /etc/security/keytab/dataproc.service.keytab dataproc/$(hostname -f)
- Ejecuta
klistpara verificar que Jupyter ha obtenido un TGT válido.
- Ejecuta
- En un terminal de Jupyter, usa la CLI de gcloud para crear un
rose.txtarchivo en un segmento de Cloud Storage de tu proyecto.echo "A rose by any other name would smell as sweet" > /tmp/rose.txt
gcloud storage cp /tmp/rose.txt gs://bucket-name/rose.txt
- Marca el archivo como privado para que solo tu cuenta de usuario pueda leerlo o escribir en él. Jupyter usará tus credenciales personales al interactuar con Cloud Storage.
gcloud storage objects update gs://bucket-name/rose.txt --predefined-acl=private
- Verifica tu acceso privado.
gcloud storage objects describe gs://bucket-name/rose.txt
acl:
- Marca el archivo como privado para que solo tu cuenta de usuario pueda leerlo o escribir en él. Jupyter usará tus credenciales personales al interactuar con Cloud Storage.
- email: $USER entity: user-$USER role: OWNER
- Ve a una carpeta y crea un cuaderno de PySpark.
Ejecuta una tarea básica de recuento de palabras en el archivo
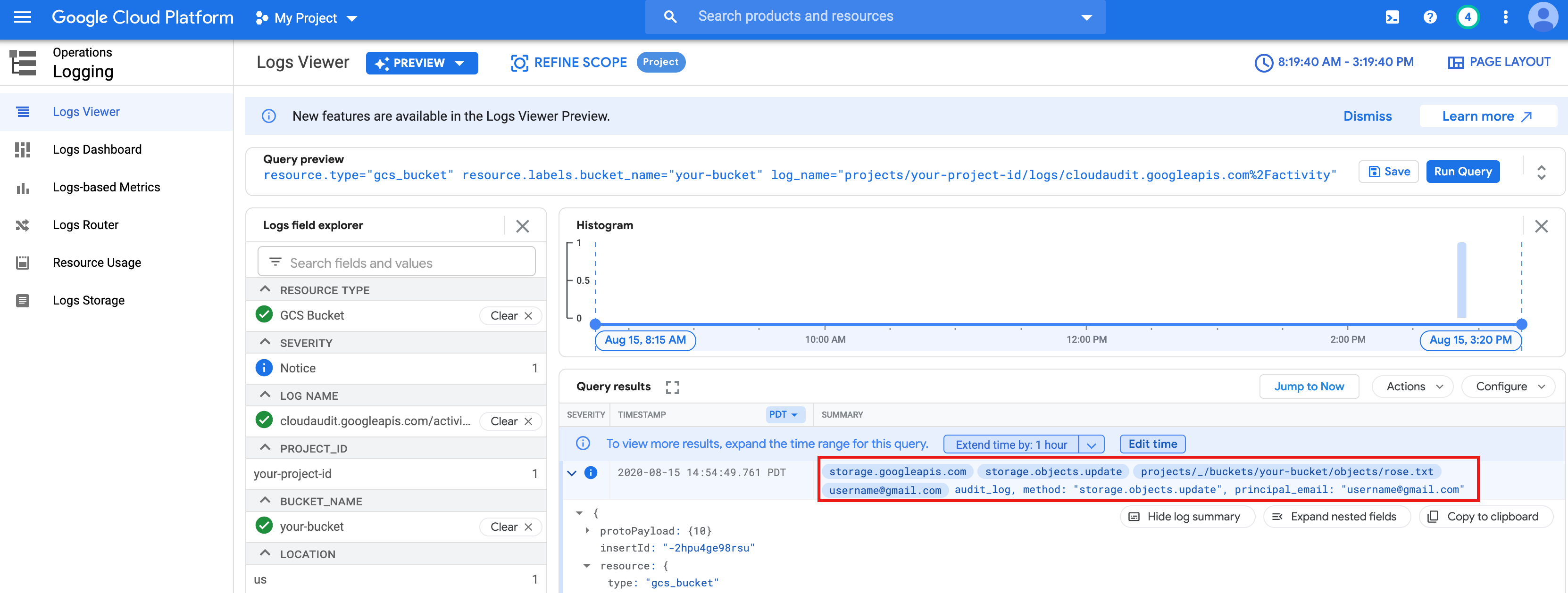
rose.txtque has creado anteriormente.text_file = sc.textFile("gs://bucket-name/rose.txt") counts = text_file.flatMap(lambda line: line.split(" ")) \ .map(lambda word: (word, 1)) \ .reduceByKey(lambda a, b: a + b) print(counts.collect())rose.txten Cloud Storage porque se ejecuta con tus credenciales de usuario.También puedes consultar los registros de auditoría del segmento de Cloud Storage para verificar que el trabajo accede a Cloud Storage con tu identidad (consulta Registros de auditoría de Cloud con Cloud Storage para obtener más información).
- Elimina el clúster de Dataproc.
gcloud dataproc clusters delete CLUSTER_NAME --region=REGION
Configurar el entorno
Configura el entorno desde Cloud Shell o un terminal local: