Quando cria um cluster do Dataproc, pode ativar a autenticação pessoal do cluster do Dataproc para permitir que as cargas de trabalho interativas no cluster sejam executadas em segurança como a sua identidade de utilizador. Isto significa que as interações com outros Google Cloud recursos, como o Cloud Storage, são autenticadas como suas em vez da conta de serviço do cluster.
Considerações
Quando cria um cluster com a autenticação de cluster pessoal ativada, o cluster só pode ser usado pela sua identidade. Os outros utilizadores não vão poder executar tarefas no cluster nem aceder aos pontos finais do Component Gateway no cluster.
Os clusters com a autenticação de cluster pessoal ativada bloqueiam o acesso SSH e as funcionalidades do Compute Engine, como scripts de arranque, em todas as VMs no cluster.
Os clusters com a autenticação de cluster pessoal ativada ativam e configuram automaticamente o Kerberos no cluster para uma comunicação segura entre clusters. No entanto, todas as identidades Kerberos no cluster interagem com os recursos como o mesmo utilizador. Google Cloud
Os clusters com a autenticação de cluster pessoal ativada não suportam imagens personalizadas.
A autenticação de cluster pessoal do Dataproc não suporta fluxos de trabalho do Dataproc.
A autenticação pessoal de clusters do Dataproc destina-se apenas a tarefas interativas executadas por um utilizador individual (humano). As tarefas e as operações de longa duração devem configurar e usar uma identidade de conta de serviço adequada.
As credenciais propagadas são restritas com um limite de acesso às credenciais. O limite de acesso predefinido está limitado à leitura e escrita de objetos do Cloud Storage em contentores do Cloud Storage pertencentes ao mesmo projeto que contém o cluster. Pode definir um limite de acesso não predefinido quando enable_an_interactive_session.
A autenticação de clusters pessoais do Dataproc usa atributos de convidado do Compute Engine. Se a funcionalidade de atributos de hóspedes estiver desativada, a autenticação de cluster pessoal falha.
Objetivos
Crie um cluster do Dataproc com a autenticação de cluster pessoal do Dataproc ativada.
Inicie a propagação de credenciais para o cluster.
Use um bloco de notas do Jupyter no cluster para executar tarefas do Spark que autenticam com as suas credenciais.
Antes de começar
Crie um projeto
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Dataproc API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Install the Google Cloud CLI.
-
Se estiver a usar um fornecedor de identidade (IdP) externo, tem primeiro de iniciar sessão na CLI gcloud com a sua identidade federada.
-
Para inicializar a CLI gcloud, execute o seguinte comando:
gcloud init -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Dataproc API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Install the Google Cloud CLI.
-
Se estiver a usar um fornecedor de identidade (IdP) externo, tem primeiro de iniciar sessão na CLI gcloud com a sua identidade federada.
-
Para inicializar a CLI gcloud, execute o seguinte comando:
gcloud init - Inicie uma sessão do Cloud Shell.
- Execute
gcloud auth loginpara obter credenciais de utilizador válidas. Encontre o endereço de email da sua conta ativa no gcloud.
gcloud auth list --filter=status=ACTIVE --format="value(account)"
Crie um cluster.
gcloud dataproc clusters create CLUSTER_NAME \ --properties=dataproc:dataproc.personal-auth.user=your-email-address \ --enable-component-gateway \ --optional-components=JUPYTER \ --region=REGION
Ative uma sessão de propagação de credenciais para o cluster começar a usar as suas credenciais pessoais quando interagir com os recursos Google Cloud.
gcloud dataproc clusters enable-personal-auth-session \ --region=REGION \ CLUSTER_NAME
Exemplo de saída:
Injecting initial credentials into the cluster CLUSTER_NAME...done. Periodically refreshing credentials for cluster CLUSTER_NAME. This will continue running until the command is interrupted...
Exemplo de limite de acesso com âmbito reduzido: O exemplo seguinte ativa uma sessão de autenticação pessoal mais restritiva do que o limite de acesso de credenciais com âmbito reduzido predefinido. Restringe o acesso ao contentor de preparação do cluster do Dataproc (consulte o artigo Reduza o âmbito com limites de acesso às credenciais para mais informações).
gcloud dataproc clusters enable-personal-auth-session \ --project=PROJECT_ID \ --region=REGION \ --access-boundary=<(echo -n "{ \ \"access_boundary\": { \ \"accessBoundaryRules\": [{ \ \"availableResource\": \"//storage.googleapis.com/projects/_/buckets/$(gcloud dataproc clusters describe --project=PROJECT_ID --region=REGION CLUSTER_NAME --format="value(config.configBucket)")\", \ \"availablePermissions\": [ \ \"inRole:roles/storage.objectViewer\", \ \"inRole:roles/storage.objectCreator\", \ \"inRole:roles/storage.objectAdmin\", \ \"inRole:roles/storage.legacyBucketReader\" \ ] \ }] \ } \ }") \ CLUSTER_NAME
Mantenha o comando em execução e mude para um novo separador do Cloud Shell ou uma sessão de terminal. O cliente atualiza as credenciais enquanto o comando está a ser executado.
Escreva
Ctrl-Cpara terminar a sessão.- Obtenha detalhes do cluster.
gcloud dataproc clusters describe CLUSTER_NAME --region=REGION
O URL da interface Web do Jupyter está listado nos detalhes do cluster.
... JupyterLab: https://UUID-dot-us-central1.dataproc.googleusercontent.com/jupyter/lab/ ...
- Copie o URL para o seu navegador local para iniciar a IU do Jupyter.
- Verifique se a autenticação do cluster pessoal foi bem-sucedida.
- Inicie um terminal do Jupyter.
- Execução
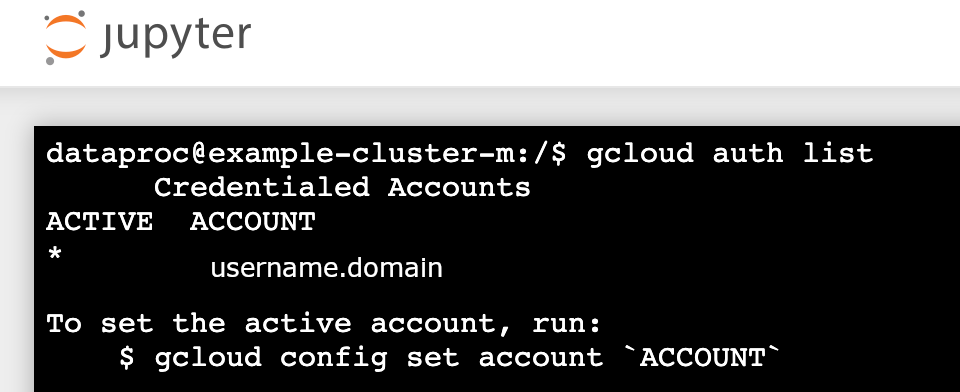
gcloud auth list - Verifique se o seu nome de utilizador é a única conta ativa.
- Num terminal do Jupyter, ative o Jupyter para autenticar com o Kerberos e enviar tarefas do Spark.
kinit -kt /etc/security/keytab/dataproc.service.keytab dataproc/$(hostname -f)
- Execute
klistpara verificar se o Jupyter obteve um TGT válido.
- Execute
- Num terminal do Jupyter, use a CLI gcloud para criar um ficheiro
rose.txtnum contentor do Cloud Storage no seu projeto.echo "A rose by any other name would smell as sweet" > /tmp/rose.txt
gcloud storage cp /tmp/rose.txt gs://bucket-name/rose.txt
- Marque o ficheiro como privado para que apenas a sua conta de utilizador possa ler ou escrever no mesmo. O Jupyter usa as suas credenciais pessoais quando interage com o Cloud Storage.
gcloud storage objects update gs://bucket-name/rose.txt --predefined-acl=private
- Valide o seu acesso privado.
gcloud storage objects describe gs://$BUCKET/rose.txt
acl:
- Marque o ficheiro como privado para que apenas a sua conta de utilizador possa ler ou escrever no mesmo. O Jupyter usa as suas credenciais pessoais quando interage com o Cloud Storage.
- email: $USER entity: user-$USER role: OWNER
- Clique no link Component Gateway Jupyter para iniciar a IU do Jupyter.
- Verifique se a autenticação do cluster pessoal foi bem-sucedida.
- Inicie um terminal do Jupyter
- Execução
gcloud auth list - Verifique se o seu nome de utilizador é a única conta ativa.
- Num terminal do Jupyter, ative o Jupyter para autenticar com o Kerberos e enviar tarefas do Spark.
kinit -kt /etc/security/keytab/dataproc.service.keytab dataproc/$(hostname -f)
- Execute
klistpara verificar se o Jupyter obteve um TGT válido.
- Execute
- Num terminal do Jupyter, use a CLI gcloud para criar um ficheiro
rose.txtnum contentor do Cloud Storage no seu projeto.echo "A rose by any other name would smell as sweet" > /tmp/rose.txt
gcloud storage cp /tmp/rose.txt gs://bucket-name/rose.txt
- Marque o ficheiro como privado para que apenas a sua conta de utilizador possa ler ou escrever no mesmo. O Jupyter usa as suas credenciais pessoais quando interage com o Cloud Storage.
gcloud storage objects update gs://bucket-name/rose.txt --predefined-acl=private
- Valide o seu acesso privado.
gcloud storage objects describe gs://bucket-name/rose.txt
acl:
- Marque o ficheiro como privado para que apenas a sua conta de utilizador possa ler ou escrever no mesmo. O Jupyter usa as suas credenciais pessoais quando interage com o Cloud Storage.
- email: $USER entity: user-$USER role: OWNER
- Navegue para uma pasta e, em seguida, crie um bloco de notas PySpark.
Execute uma tarefa de contagem de palavras básica no ficheiro
rose.txtque criou acima.text_file = sc.textFile("gs://bucket-name/rose.txt") counts = text_file.flatMap(lambda line: line.split(" ")) \ .map(lambda word: (word, 1)) \ .reduceByKey(lambda a, b: a + b) print(counts.collect())rose.txtno Cloud Storage porque é executado com as suas credenciais de utilizador.Também pode verificar os registos de auditoria do contentor do Cloud Storage para confirmar que a tarefa está a aceder ao Cloud Storage com a sua identidade (consulte os registos de auditoria do Cloud com o Cloud Storage para mais informações).

- Elimine o cluster do Dataproc.
gcloud dataproc clusters delete CLUSTER_NAME --region=REGION
Configure o ambiente
Configure o ambiente a partir do Cloud Shell ou de um terminal local: