When you create a Dataproc cluster, you can enable Dataproc Personal Cluster Authentication to allow interactive workloads on the cluster to securely run as your user identity. This means that interactions with other Google Cloud resources such as Cloud Storage will be authenticated as yourself instead of the cluster service account.
Considerations
When you create a cluster with Personal Cluster Authentication enabled, the cluster will only be usable by your identity. Other users won't be able to run jobs on the cluster or access Component Gateway endpoints on the cluster.
Clusters with Personal Cluster Authentication enabled block SSH access and Compute Engine features such as startup scripts on all VMs in the cluster.
Clusters with Personal Cluster Authentication enabled automatically enable and configure Kerberos on the cluster for secure intra-cluster communication. However, all Kerberos identities on the cluster will interact with Google Cloud resources as the same user.
Clusters with Personal Cluster Authentication enabled don't support custom images.
Dataproc Personal Cluster Authentication does not support Dataproc workflows.
Dataproc Personal Cluster Authentication is intended only for interactive jobs run by an individual (human) user. Long-running jobs and operations should configure and use an appropriate service account identity.
The propagated credentials are downscoped with a Credential Access Boundary. The default access boundary is limited to reading and writing Cloud Storage objects in Cloud Storage buckets owned by the same project that contains the cluster. You can define a non-default access boundary when you enable_an_interactive_session.
Dataproc Personal Cluster Authentication uses Compute Engine guest attributes. If the guest attributes feature is disabled, Personal Cluster Authentication will fail.
Objectives
Create a Dataproc cluster with Dataproc Personal Cluster Authentication enabled.
Start credential propagation to the cluster.
Use a Jupyter notebook on the cluster to run Spark jobs that authenticate with your credentials.
Before You Begin
Create a Project
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Dataproc API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Install the Google Cloud CLI.
-
If you're using an external identity provider (IdP), you must first sign in to the gcloud CLI with your federated identity.
-
To initialize the gcloud CLI, run the following command:
gcloud init -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Dataproc API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Install the Google Cloud CLI.
-
If you're using an external identity provider (IdP), you must first sign in to the gcloud CLI with your federated identity.
-
To initialize the gcloud CLI, run the following command:
gcloud init
Configure the Environment
Configure the environment from Cloud Shell or a local terminal:
Cloud Shell
- Start a Cloud Shell session.
Local terminal
- Run
gcloud auth loginto obtain valid user credentials.
Create a cluster and enable an interactive session
Find the email address of your active account in gcloud.
gcloud auth list --filter=status=ACTIVE --format="value(account)"
Create a cluster.
gcloud dataproc clusters create CLUSTER_NAME \ --properties=dataproc:dataproc.personal-auth.user=your-email-address \ --enable-component-gateway \ --optional-components=JUPYTER \ --region=REGION
Enable a credential propagation session for the cluster to start using your personal credentials when interacting with Google Cloud resources.
gcloud dataproc clusters enable-personal-auth-session \ --region=REGION \ CLUSTER_NAME
Sample output:
Injecting initial credentials into the cluster CLUSTER_NAME...done. Periodically refreshing credentials for cluster CLUSTER_NAME. This will continue running until the command is interrupted...
Downscoped access boundary example: The following example enables a personal auth session that is more restrictive than the default downscoped credential access boundary. It restricts access to the Dataproc cluster's staging bucket (see Downscope with Credential Access Boundaries for more information).
gcloud dataproc clusters enable-personal-auth-session \ --project=PROJECT_ID \ --region=REGION \ --access-boundary=<(echo -n "{ \ \"access_boundary\": { \ \"accessBoundaryRules\": [{ \ \"availableResource\": \"//storage.googleapis.com/projects/_/buckets/$(gcloud dataproc clusters describe --project=PROJECT_ID --region=REGION CLUSTER_NAME --format="value(config.configBucket)")\", \ \"availablePermissions\": [ \ \"inRole:roles/storage.objectViewer\", \ \"inRole:roles/storage.objectCreator\", \ \"inRole:roles/storage.objectAdmin\", \ \"inRole:roles/storage.legacyBucketReader\" \ ] \ }] \ } \ }") \ CLUSTER_NAME
Keep the command running and switch to a new Cloud Shell tab or terminal session. The client will refresh the credentials while the command is running.
Type
Ctrl-Cto end the session.
Access Jupyter on the cluster
gcloud
- Get cluster details.
gcloud dataproc clusters describe CLUSTER_NAME --region=REGION
The Jupyter Web interface URL is listed in cluster details.
... JupyterLab: https://UUID-dot-us-central1.dataproc.googleusercontent.com/jupyter/lab/ ...
- Copy the URL into your local browser to launch the Jupyter UI.
- Check that personal cluster authentication was successful.
- Start a Jupyter terminal.
- Run
gcloud auth list - Verify that your username is the only active account.
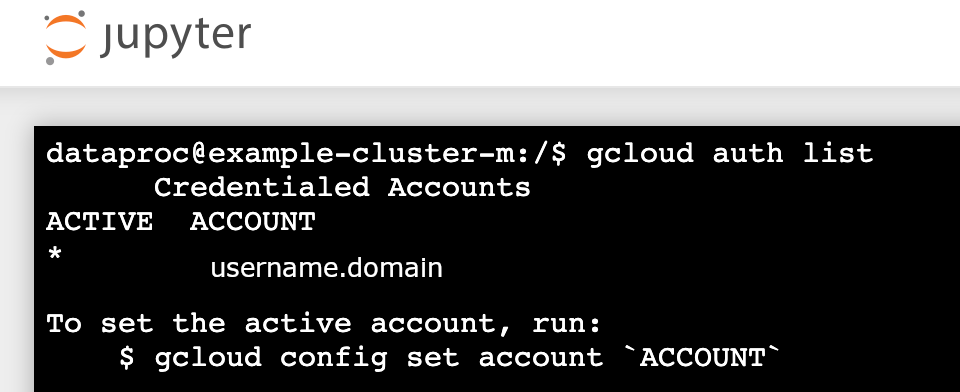
- In a Jupyter terminal, enable Jupyter to authenticate with Kerberos and submit Spark jobs.
kinit -kt /etc/security/keytab/dataproc.service.keytab dataproc/$(hostname -f)
- Run
klistto verify that Jupyter obtained a valid TGT.
- Run
- In a Juypter terminal, use the gcloud CLI to create a
rose.txtfile in a Cloud Storage bucket in your project.echo "A rose by any other name would smell as sweet" > /tmp/rose.txt
gcloud storage cp /tmp/rose.txt gs://bucket-name/rose.txt
- Mark the file as private so that only your user account can read from or
write to it. Jupyter will use your personal credentials when interacting
with Cloud Storage.
gcloud storage objects update gs://bucket-name/rose.txt --predefined-acl=private
- Verify your private access.
gcloud storage objects describe gs://$BUCKET/rose.txt
acl:
- Mark the file as private so that only your user account can read from or
write to it. Jupyter will use your personal credentials when interacting
with Cloud Storage.
- email: $USER entity: user-$USER role: OWNER
Console
- Click the Component Gateway Jupyter link to launch the Jupyter UI.
- Check that personal cluster authentication was successful.
- Start a Jupyter terminal
- Run
gcloud auth list - Verify that your username is the only active account.
- In a Jupyter terminal, enable Jupyter to authenticate with Kerberos and submit Spark jobs.
kinit -kt /etc/security/keytab/dataproc.service.keytab dataproc/$(hostname -f)
- Run
klistto verify that Jupyter obtained a valid TGT.
- Run
- In a Jupyter terminal, use the gcloud CLI to create a
rose.txtfile in a Cloud Storage bucket in your project.echo "A rose by any other name would smell as sweet" > /tmp/rose.txt
gcloud storage cp /tmp/rose.txt gs://bucket-name/rose.txt
- Mark the file as private so that only your user account can read from or
write to it. Jupyter will use your personal credentials when interacting
with Cloud Storage.
gcloud storage objects update gs://bucket-name/rose.txt --predefined-acl=private
- Verify your private access.
gcloud storage objects describe gs://bucket-name/rose.txt
acl:
- Mark the file as private so that only your user account can read from or
write to it. Jupyter will use your personal credentials when interacting
with Cloud Storage.
- email: $USER entity: user-$USER role: OWNER
Run a PySpark job from Jupyter
- Navigate to a folder, then create a PySpark notebook.
Run a basic word count job against the
rose.txtfile you created above.text_file = sc.textFile("gs://bucket-name/rose.txt") counts = text_file.flatMap(lambda line: line.split(" ")) \ .map(lambda word: (word, 1)) \ .reduceByKey(lambda a, b: a + b) print(counts.collect())rose.txtfile in Cloud Storage because it runs with your user credentials.You can also check the Cloud Storage Bucket Audit Logs to verify that the job is accessing Cloud Storage with your identity (see Cloud Audit Logs with Cloud Storage for more information).

Cleanup
- Delete the Dataproc cluster.
gcloud dataproc clusters delete CLUSTER_NAME --region=REGION