Quando utilizzi il servizio Dataproc per creare cluster ed eseguire job sui tuoi cluster, il servizio configura i ruoli e le autorizzazioni Dataproc necessari nel tuo progetto per accedere e utilizzare le risorse Google Cloud necessarie per svolgere queste attività. Tuttavia, se lavori su più progetti, ad esempio per accedere ai dati in un altro progetto, dovrai configurare i ruoli e le autorizzazioni necessari per accedere alle risorse tra progetti.
Per aiutarti a svolgere correttamente il lavoro tra progetti, questo documento elenca i diversi principali che utilizzano il servizio Dataproc e i ruoli che contengono le autorizzazioni necessarie per consentire a questi principali di accedere e utilizzare Google Cloud le risorse.
Esistono tre entità (identità) che accedono e utilizzano Dataproc:
- Identità utente
- Identità del control plane
Identità del piano dati
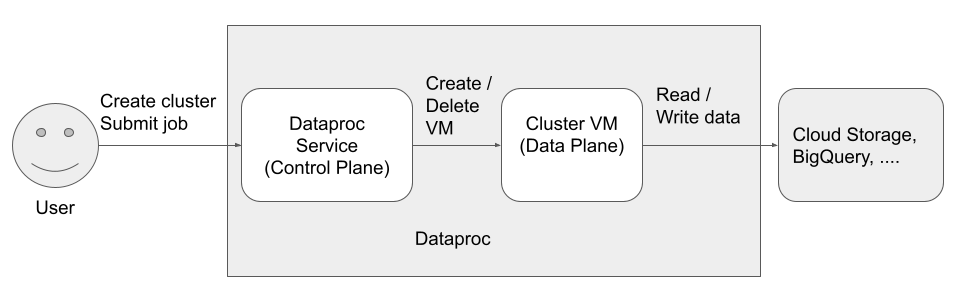
Utente API Dataproc (identità utente)
Esempio: username@example.com
Questo è l'utente che chiama il servizio Dataproc per creare cluster, inviare job ed effettuare altre richieste al servizio. L'utente è in genere una persona, ma può anche essere un service account se Dataproc viene richiamato tramite un client API o da un altro Google Cloud servizio come Compute Engine, funzioni Cloud Run o Cloud Composer.
Ruoli correlati
Note
- I job inviati tramite l'API Dataproc vengono eseguiti come
rootsu Linux. I cluster Dataproc ereditano i metadati SSH di Compute Engine a livello di progetto, a meno che non siano bloccati esplicitamente impostando
--metadata=block-project-ssh-keys=truedurante la creazione del cluster (vedi Metadati del cluster).Le directory utente HDFS vengono create per ogni utente SSH a livello di progetto. Queste directory HDFS vengono create al momento del deployment del cluster e a un nuovo utente SSH (post-deployment) non viene assegnata una directory HDFS sui cluster esistenti.
Dataproc Service Agent (identità del control plane)
Esempio: service-project-number@dataproc-accounts.iam.gserviceaccount.com
Il service account dell'agente di servizio Dataproc viene utilizzato per eseguire un ampio insieme di operazioni di sistema sulle risorse che si trovano nel progetto in cui viene creato un cluster Dataproc, tra cui:
- Creazione di risorse Compute Engine, tra cui istanze VM, gruppi di istanze e modelli di istanza
- operazioni
getelistper confermare la configurazione di risorse come immagini, firewall, azioni di inizializzazione di Dataproc e bucket Cloud Storage - Creazione automatica dei bucket temporanei e di gestione temporanea di Dataproc se il bucket temporaneo o di gestione temporanea non è specificato dall'utente
- Scrittura dei metadati di configurazione del cluster nel bucket di gestione temporanea
- Accesso alle reti VPC in un progetto host
Ruoli correlati
Account di servizio VM Dataproc (identità del piano dati)
Esempio: project-number-compute@developer.gserviceaccount.com
Il codice dell'applicazione viene eseguito come service account VM sulle VM Dataproc. Ai job utente vengono concessi i ruoli (con le relative autorizzazioni) di questo account di servizio.
Il account di servizio VM esegue le seguenti operazioni:
- Comunica con il piano di controllo Dataproc.
- Legge e scrive dati da e verso i bucket temporanei e di gestione temporanea di Dataproc.
- In base alle esigenze dei job Dataproc, legge e scrive dati da e verso Cloud Storage, BigQuery, Cloud Logging e altre risorse Google Cloud .
Ruoli correlati
Passaggi successivi
- Scopri di più su ruoli e autorizzazioni Dataproc.
- Scopri di più sui service account Dataproc.
- Consulta la sezione Controllo dell'accesso a BigQuery.
- Consulta le opzioni di controllo dell'accesso di Cloud Storage.