Cuando usas el servicio de Dataproc para crear clústeres y ejecutar trabajos en ellos, el servicio configura los roles y permisos de Dataproc necesarios en tu proyecto para acceder a los recursos de Google Cloud que necesita para realizar estas tareas y usarlos. Sin embargo, si realizas un trabajo entre proyectos, por ejemplo, para acceder a los datos de otro proyecto, deberás configurar las funciones y los permisos necesarios a fin de acceder a los recursos entre proyectos.
Para ayudarte a realizar el trabajo entre proyectos de manera correcta, en este documento se enumeran los diferentes principales que usan el servicio de Dataproc y las funciones que contienen los permisos necesarios para que esos principales usen y accedan a los recursos de Google Cloud .
Existen tres principales (identidades) que acceden y usan Dataproc:
- Identidad de usuario
- Identidad del plano de control
Identidad del plano de datos
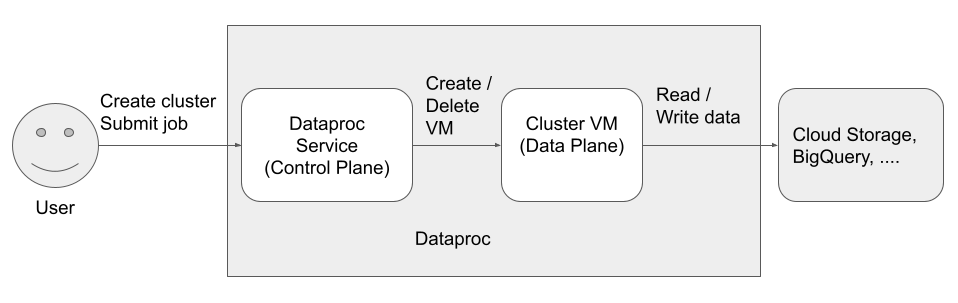
Usuario de la API de Dataproc (identidad del usuario)
Ejemplo: username@example.com
Este es el usuario que llama al servicio de Dataproc para crear clústeres, enviar trabajos y realizar otras solicitudes al servicio. El usuario suele ser un individuo, pero también puede ser una cuenta de servicio si se invoca a Dataproc a través de un cliente de API o de otroGoogle Cloud servicio, como Compute Engine, Cloud Run Functions o Cloud Composer.
Funciones relacionadas
Notas
- Los trabajos enviados por la API de Dataproc se ejecutan como
rooten Linux. Los clústeres de Dataproc heredan los metadatos SSH de Compute Engine en todo el proyecto, a menos que se bloqueen explícitamente mediante la configuración de
--metadata=block-project-ssh-keys=truecuando creas el clúster (consulta metadatos de clústeres).Los directorios de usuarios HDFS se crean para cada usuario SSH a nivel de proyecto. Estos directorios HDFS se crean en el momento de la implementación del clúster, y nuevo un usuario SSH (posterior a la implementación) no recibe un directorio HDFS en los clústeres existentes.
Agente del servicio de Dataproc (identidad del plano de control)
Ejemplo: service-project-number@dataproc-accounts.iam.gserviceaccount.com
La cuenta de servicio del agente de servicio de Dataproc se usa para realizar un amplio conjunto de operaciones del sistema en los recursos ubicados en el proyecto en el que se crea un clúster de Dataproc, incluidos los siguientes:
- Crear recursos de Compute Engine, que incluyen instancias de VM, grupos de instancias y plantillas de instancias
- Operaciones
getylistpara confirmar la configuración de recursos como imágenes, firewalls, acciones de inicialización de Dataproc y buckets de Cloud Storage - Crear de forma automática los buckets temporales y de etapa de pruebas de Dataproc si el usuario no los especificó
- Escribir metadatos de configuración de clústeres en el bucket de etapa de pruebas
- Acceder a redes de VPC en un proyecto host
Funciones relacionadas
Cuenta de servicio de VM de Dataproc (identidad del plano de datos)
Ejemplo: project-number-compute@developer.gserviceaccount.com
El código de la aplicación se ejecuta como la cuenta de servicio de VM en las VM de Dataproc. A los trabajos de usuario se les otorgan los roles (con sus permisos asociados) de esta cuenta de servicio.
La cuenta de servicio de la VM hace lo siguiente:
- Se comunica con el plano de control de Dataproc.
- Lee y escribe datos desde y hacia los buckets temporales y de etapa de pruebas de Dataproc.
- Según sea necesario para tus trabajos de Dataproc, lee y escribe datos desde y hacia Cloud Storage, BigQuery, Cloud Logging y otros Google Cloud recursos.
Funciones relacionadas
¿Qué sigue?
- Obtén más información sobre los roles y permisos de Dataproc.
- Obtén más información sobre las cuentas de servicio de Dataproc.
- Consulta Control de acceso a BigQuery.
- Consulta las opciones de control de acceso de Cloud Storage.