Dataproc 서비스를 사용하여 클러스터를 만들고 클러스터에서 작업을 실행하면 서비스는 프로젝트에서 이러한 태스크를 수행하는 데 필요한 Google Cloud 리소스에 액세스하고 사용하기 위한 필수 Dataproc 권한 및 역할을 설정합니다. 하지만 다른 프로젝트의 데이터에 액세스하는 경우처럼 프로젝트 간 작업을 수행하는 경우에는 사용자가 프로젝트 간 리소스에 액세스하는 데 필요한 역할과 권한을 설정해야 합니다.
사용자가 프로젝트 간 작업을 성공적으로 수행할 수 있도록 이 문서에는 Dataproc 서비스를 사용하는 다양한 주 구성원과 함께, 이러한 주 구성원이 Google Cloud 리소스에 액세스하고 이를 사용하는 데 필요한 권한을 포함하는 역할이 나열됩니다.
Dataproc에 액세스하고 Dataproc을 사용하는 세 가지 주 구성원(ID)이 있습니다.
- 사용자 ID
- 제어 영역 ID
데이터 영역 ID
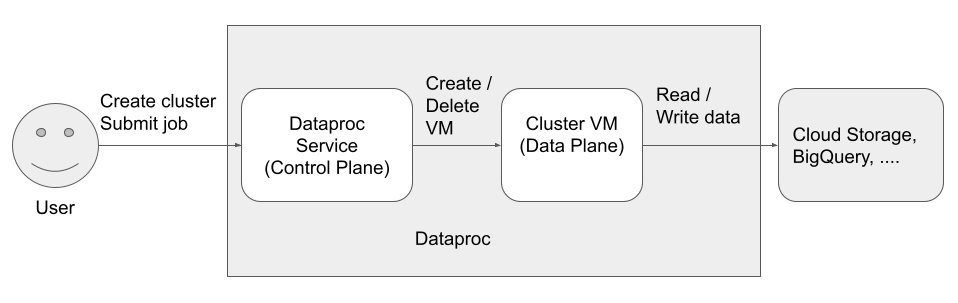
Dataproc API 사용자(사용자 ID)
예: username@example.com
이 사용자는 Dataproc 서비스를 호출하여 클러스터를 만들고, 작업을 제출하고, 서비스에 다른 요청을 합니다. 사용자는 보통 개인이지만 Dataproc이 API 클라이언트를 통해 또는 Compute Engine, Cloud Run Functions 또는 Cloud Composer와 같은 다른Google Cloud 서비스에서 호출되는 경우에는 서비스 계정일 수도 있습니다.
관련 역할
참고
- Dataproc API 제출 작업은 Linux에서
root로 실행됩니다. Dataproc 클러스터는 클러스터를 만들 때
--metadata=block-project-ssh-keys=true를 설정하여 명시적으로 차단하지 않는 한 프로젝트 전체의 Compute Engine SSH 메타데이터를 상속합니다(클러스터 메타데이터 참조).HDFS 사용자 디렉터리는 프로젝트 수준 SSH 사용자별로 생성됩니다. 이러한 HDFS 디렉터리는 클러스터 배포 시 생성되며 새로운(배포 후) SSH 사용자에게는 기존 클러스터의 HDFS 디렉터리가 제공되지 않습니다.
Dataproc 서비스 에이전트(제어 영역 ID)
예: service-project-number@dataproc-accounts.iam.gserviceaccount.com
Dataproc 서비스 에이전트 서비스 계정은 다음을 포함하여 Dataproc 클러스터가 생성된 프로젝트에 있는 리소스에 대한 광범위한 시스템 작업을 수행하는 데 사용됩니다.
- VM 인스턴스, 인스턴스 그룹 및 인스턴스 템플릿을 비롯한 Compute Engine 리소스 생성
- 이미지, 방화벽, Dataproc 초기화 작업, Cloud Storage 버킷과 같은 리소스의 구성을 확인하기 위한
get및list작업 - Dataproc 스테이징 및 임시 버킷의 자동 생성(사용자가 스테이징 또는 임시 버킷을 지정하지 않은 경우)
- 스테이징 버킷에 클러스터 구성 메타데이터 쓰기
- 호스트 프로젝트의 VPC 네트워크에 액세스
관련 역할
Dataproc VM 서비스 계정(데이터 영역 ID)
예: project-number-compute@developer.gserviceaccount.com
애플리케이션 코드는 Dataproc VM에서 VM 서비스 계정으로 실행됩니다. 사용자 작업에는 이 서비스 계정의 역할(연결된 권한 포함)이 부여됩니다.
VM 서비스 계정은 다음을 수행합니다.
- Dataproc 컨트롤 플레인과 통신
- Dataproc 스테이징 및 임시 버킷에(서) 데이터 읽기 및 쓰기
- Dataproc 작업상 필요하면 Cloud Storage, BigQuery, Cloud Logging, 기타 Google Cloud 리소스에(서) 데이터를 읽고 씁니다.
관련 역할
다음 단계
- Dataproc 역할 및 권한에 대해 자세히 알아보기
- Dataproc 서비스 계정에 대해 자세히 알아보기
- BigQuery 액세스 제어 참고하기
- Cloud Storage 액세스 제어 옵션 참고하기