Konektor Hive-BigQuery open source memungkinkan beban kerja Apache Hive Anda membaca dan menulis data dari dan ke tabel BigQuery dan BigLake. Anda dapat menyimpan data di penyimpanan BigQuery atau dalam format data open source di Cloud Storage.
Konektor Hive-BigQuery menerapkan Hive Storage Handler API untuk memungkinkan workload Hive berintegrasi dengan tabel BigQuery dan BigLake. Mesin eksekusi Hive menangani operasi komputasi, seperti agregasi dan gabungan, dan konektor mengelola interaksi dengan data yang disimpan di BigQuery atau di bucket Cloud Storage yang terhubung dengan BigLake.
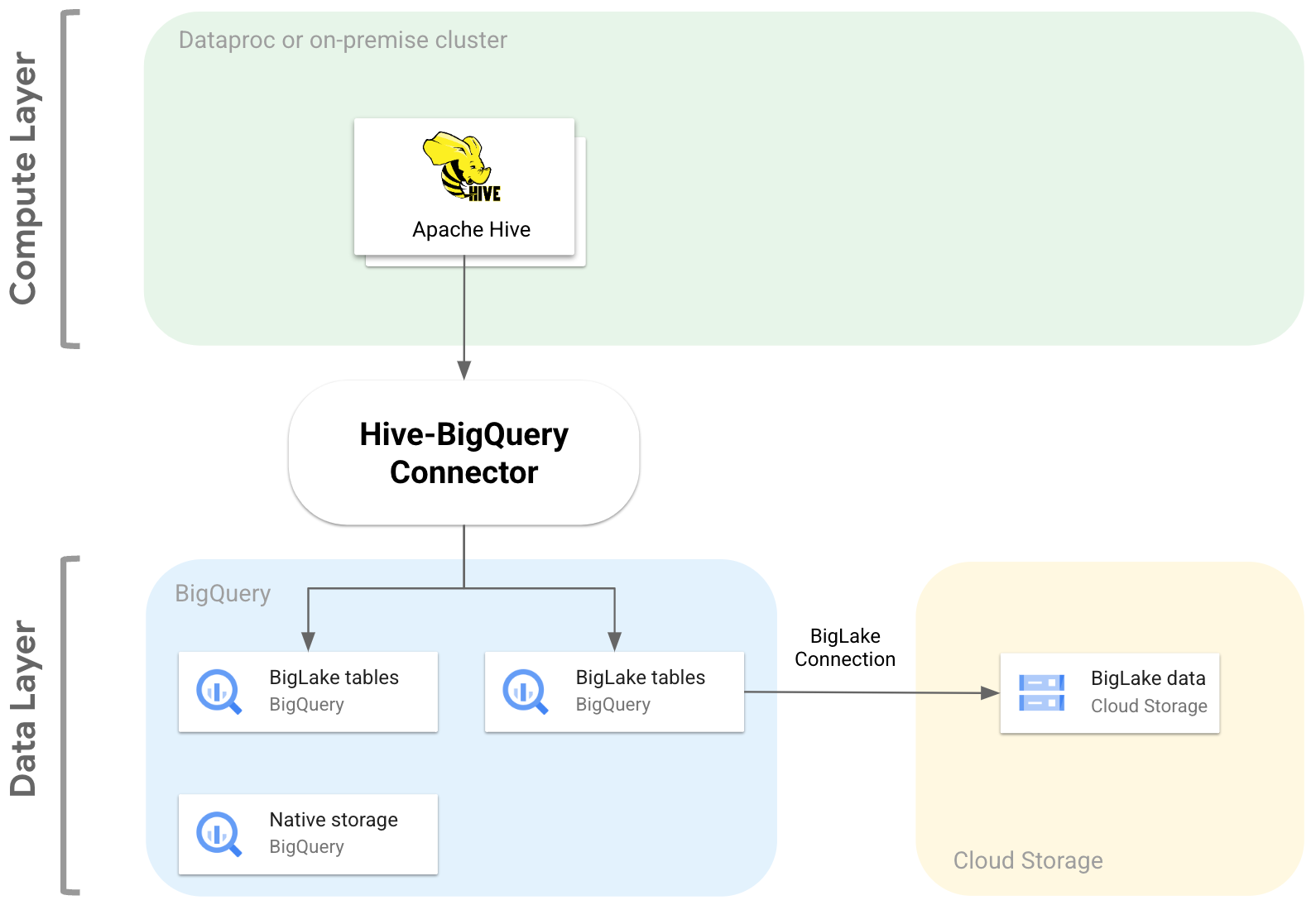
Diagram berikut menggambarkan cara konektor Hive-BigQuery cocok di antara lapisan komputasi dan data.
Kasus penggunaan
Berikut beberapa cara konektor Hive-BigQuery dapat membantu Anda dalam skenario umum berbasis data:
Migrasi data. Anda berencana memindahkan data warehouse Hive ke BigQuery, lalu menerjemahkan kueri Hive secara bertahap ke dialek SQL BigQuery. Anda memperkirakan migrasi akan memakan waktu yang cukup lama karena ukuran data warehouse dan banyaknya aplikasi yang terhubung, dan Anda perlu memastikan kelangsungan selama operasi migrasi. Berikut alur kerjanya:
- Anda memindahkan data ke BigQuery
- Dengan menggunakan konektor, Anda dapat mengakses dan menjalankan kueri Hive asli sambil menerjemahkan kueri Hive secara bertahap ke dialek SQL yang sesuai dengan ANSI BigQuery.
- Setelah menyelesaikan migrasi dan terjemahan, Anda akan menghentikan penggunaan Hive.
Alur kerja Hive dan BigQuery. Anda berencana menggunakan Hive untuk beberapa tugas, dan BigQuery untuk workload yang diuntungkan dari fiturnya, seperti BigQuery BI Engine atau BigQuery ML. Anda menggunakan konektor untuk menggabungkan tabel Hive ke tabel BigQuery Anda.
Ketergantungan pada stack software open source (OSS). Untuk menghindari ketergantungan pada vendor, Anda menggunakan stack OSS lengkap untuk data warehouse. Berikut paket data Anda:
Anda memigrasikan data dalam format OSS aslinya, seperti Avro, Parquet, atau ORC, ke bucket Cloud Storage menggunakan koneksi BigLake.
Anda terus menggunakan Hive untuk menjalankan dan memproses kueri dialek Hive SQL.
Anda menggunakan konektor sesuai kebutuhan untuk terhubung ke BigQuery guna memanfaatkan fitur berikut:
- Penyimpanan cache metadata untuk performa kueri
- Pencegahan kebocoran data
- Kontrol akses tingkat kolom
- Penyamaran data dinamis untuk keamanan dan tata kelola dalam skala besar.
Fitur
Anda dapat menggunakan konektor Hive-BigQuery untuk menggunakan data BigQuery dan menyelesaikan tugas berikut:
- Menjalankan kueri dengan mesin eksekusi MapReduce dan Tez.
- Membuat dan menghapus tabel BigQuery dari Hive.
- Gabungkan tabel BigQuery dan BigLake dengan tabel Hive.
- Lakukan pembacaan cepat dari tabel BigQuery menggunakan streaming Storage Read API dan format Apache Arrow
- Tulis data ke BigQuery menggunakan metode berikut:
- Penulisan langsung menggunakan BigQuery Storage Write API dalam mode tertunda. Gunakan metode ini untuk workload yang memerlukan latensi penulisan rendah, seperti dasbor near-real-time dengan jangka waktu refresh yang singkat.
- Penulisan tidak langsung dengan menyiapkan file Avro sementara ke Cloud Storage, lalu memuat file ke tabel tujuan menggunakan Load Job API. Metode ini lebih murah daripada metode langsung, karena tugas pemuatan BigQuery tidak dikenai biaya. Karena metode ini lebih lambat, dan paling baik digunakan dalam workload yang tidak memerlukan waktu yang mendesak
Akses tabel berpartisi menurut waktu dan dikelompokkan BigQuery. Contoh berikut menentukan hubungan antara tabel Hive dan tabel yang dipartisi dan dikelompokkan di BigQuery.
CREATE TABLE my_hive_table (int_val BIGINT, text STRING, ts TIMESTAMP) STORED BY 'com.google.cloud.hive.bigquery.connector.BigQueryStorageHandler' TBLPROPERTIES ( 'bq.table'='myproject.mydataset.mytable', 'bq.time.partition.field'='ts', 'bq.time.partition.type'='MONTH', 'bq.clustered.fields'='int_val,text' );
Pangkas kolom untuk menghindari pengambilan kolom yang tidak perlu dari lapisan data.
Gunakan pushdown predikat untuk memfilter terlebih dahulu baris data di lapisan penyimpanan BigQuery. Teknik ini dapat meningkatkan performa kueri secara keseluruhan secara signifikan dengan mengurangi jumlah data yang melintasi jaringan.
Mengonversi jenis data Hive ke jenis data BigQuery secara otomatis.
Baca tampilan BigQuery dan snapshot tabel.
Berintegrasi dengan Spark SQL.
Berintegrasi dengan Apache Pig dan HCatalog.
Mulai
Lihat petunjuk untuk menginstal dan mengonfigurasi konektor Hive-BigQuery di cluster Hive.