O conetor Hive-BigQuery de código aberto permite que as cargas de trabalho do Apache Hive leiam e escrevam dados do e para o BigQuery e as tabelas do BigLake. Pode armazenar dados no armazenamento do BigQuery ou em formatos de dados de código aberto no Cloud Storage.
O conetor Hive-BigQuery implementa a API Hive Storage Handler para permitir que as cargas de trabalho do Hive se integrem com tabelas do BigQuery e BigLake. O motor de execução do Hive processa operações de computação, como agregações e junções, e o conetor gere as interações com os dados armazenados no BigQuery ou em contentores do Cloud Storage ligados ao BigLake.
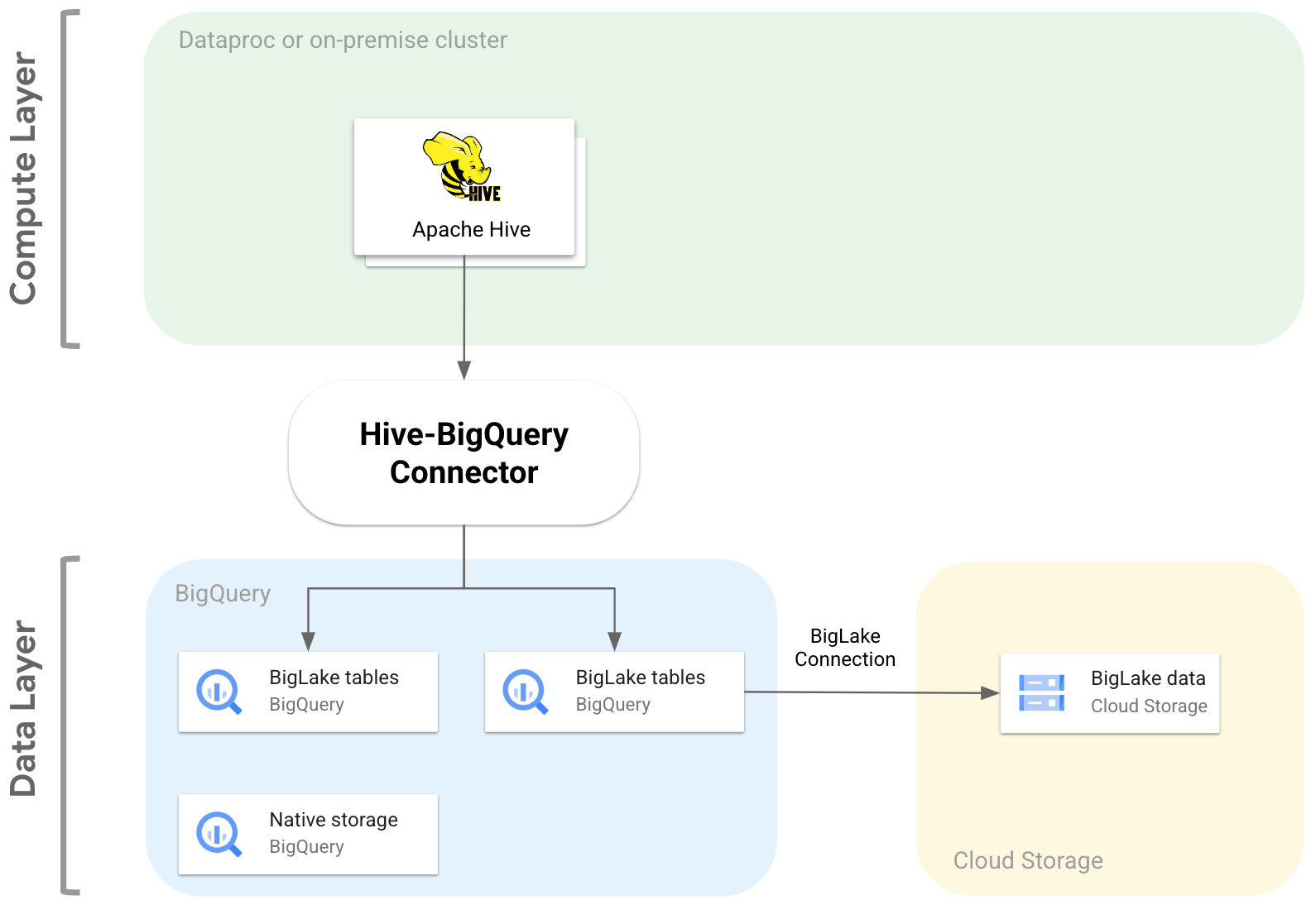
O diagrama seguinte ilustra como o conector Hive-BigQuery se encaixa entre as camadas de computação e de dados.
Exemplos de utilização
Seguem-se algumas das formas como o conetor Hive-BigQuery pode ajudar em cenários comuns baseados em dados:
Migração de dados. Planeia mover o seu armazém de dados do Hive para o BigQuery e, em seguida, traduzir incrementalmente as suas consultas do Hive para o dialeto de SQL do BigQuery. Espera que a migração demore um período significativo devido à dimensão do seu data warehouse e ao grande número de aplicações ligadas, e precisa de garantir a continuidade durante as operações de migração. Segue-se o fluxo de trabalho:
- Move os seus dados para o BigQuery
- Com o conetor, acede e executa as suas consultas Hive originais enquanto traduz gradualmente as consultas Hive para o dialeto SQL em conformidade com a norma ANSI do BigQuery.
- Depois de concluir a migração e a tradução, desativa o Hive.
Fluxos de trabalho do Hive e do BigQuery. Planeia usar o Hive para algumas tarefas e o BigQuery para cargas de trabalho que beneficiam das respetivas funcionalidades, como o BigQuery BI Engine ou o BigQuery ML. Usa o conetor para juntar tabelas do Hive às suas tabelas do BigQuery.
Confiança numa pilha de software de código aberto (OSS). Para evitar a dependência de fornecedores, usa uma pilha de software livre completa para o seu armazém de dados. Segue-se o seu plano de dados:
Migra os seus dados no formato OSS original, como Avro, Parquet ou ORC, para contentores do Cloud Storage através de uma ligação do BigLake.
Continua a usar o Hive para executar e processar as suas consultas de dialeto Hive SQL.
Use o conetor conforme necessário para estabelecer ligação ao BigQuery e beneficiar das seguintes funcionalidades:
- Colocação em cache de metadados para o desempenho das consultas
- Prevenção contra a perda de dados
- Controlo de acesso ao nível da coluna
- Anulação da apresentação dinâmica de dados para segurança e governação em grande escala.
Funcionalidades
Pode usar o conetor Hive-BigQuery para trabalhar com os seus dados do BigQuery e realizar as seguintes tarefas:
- Executar consultas com motores de execução MapReduce e Tez.
- Criar e eliminar tabelas do BigQuery a partir do Hive.
- Junte tabelas do BigQuery e do BigLake a tabelas do Hive.
- Efetue leituras rápidas de tabelas do BigQuery através das streams da API Storage Read e do formato Apache Arrow
- Escreva dados no BigQuery através dos seguintes métodos:
- Escritas diretas através da API Storage Write do BigQuery no modo pendente. Use este método para cargas de trabalho que requerem uma latência de escrita baixa, como painéis de controlo quase em tempo real com janelas de atualização curtas.
- Escritas indiretas através da preparação de ficheiros Avro temporários no Cloud Storage e, em seguida, do carregamento dos ficheiros numa tabela de destino através da API Load Job. Este método é menos dispendioso do que o método direto, uma vez que os trabalhos de carregamento do BigQuery não acumulam custos. Uma vez que este método é mais lento e é mais útil em cargas de trabalho que não são urgentes
Aceder a tabelas particionadas por tempo e agrupadas do BigQuery. O exemplo seguinte define a relação entre uma tabela do Hive e uma tabela particionada e agrupada no BigQuery.
CREATE TABLE my_hive_table (int_val BIGINT, text STRING, ts TIMESTAMP) STORED BY 'com.google.cloud.hive.bigquery.connector.BigQueryStorageHandler' TBLPROPERTIES ( 'bq.table'='myproject.mydataset.mytable', 'bq.time.partition.field'='ts', 'bq.time.partition.type'='MONTH', 'bq.clustered.fields'='int_val,text' );
Elimine colunas para evitar a obtenção de colunas desnecessárias da camada de dados.
Use pushdowns de predicados para pré-filtrar linhas de dados na camada de armazenamento do BigQuery. Esta técnica pode melhorar significativamente o desempenho geral das consultas reduzindo a quantidade de dados que atravessam a rede.
Converta automaticamente os tipos de dados do Hive em tipos de dados do BigQuery.
Ler vistas do BigQuery e cópias instantâneas de tabelas.
Integre com o Spark SQL.
Faça a integração com o Apache Pig e o HCatalog.
Começar
Consulte as instruções para instalar e configurar o conetor Hive-BigQuery num cluster Hive.