Le connecteur Hive-BigQuery Open Source permet à vos charges de travail Apache Hive de lire et d'écrire des données depuis et vers les tables BigQuery et BigLake. Vous pouvez stocker des données dans le stockage BigQuery ou dans des formats de données Open Source sur Cloud Storage.
Le connecteur Hive-BigQuery implémente l'API Hive Storage Handler pour permettre aux charges de travail Hive de s'intégrer aux tables BigQuery et BigLake. Le moteur d'exécution Hive gère les opérations de calcul, telles que les agrégations et les jointures, et le connecteur gère les interactions avec les données stockées dans BigQuery ou dans les buckets Cloud Storage connectés à BigLake.
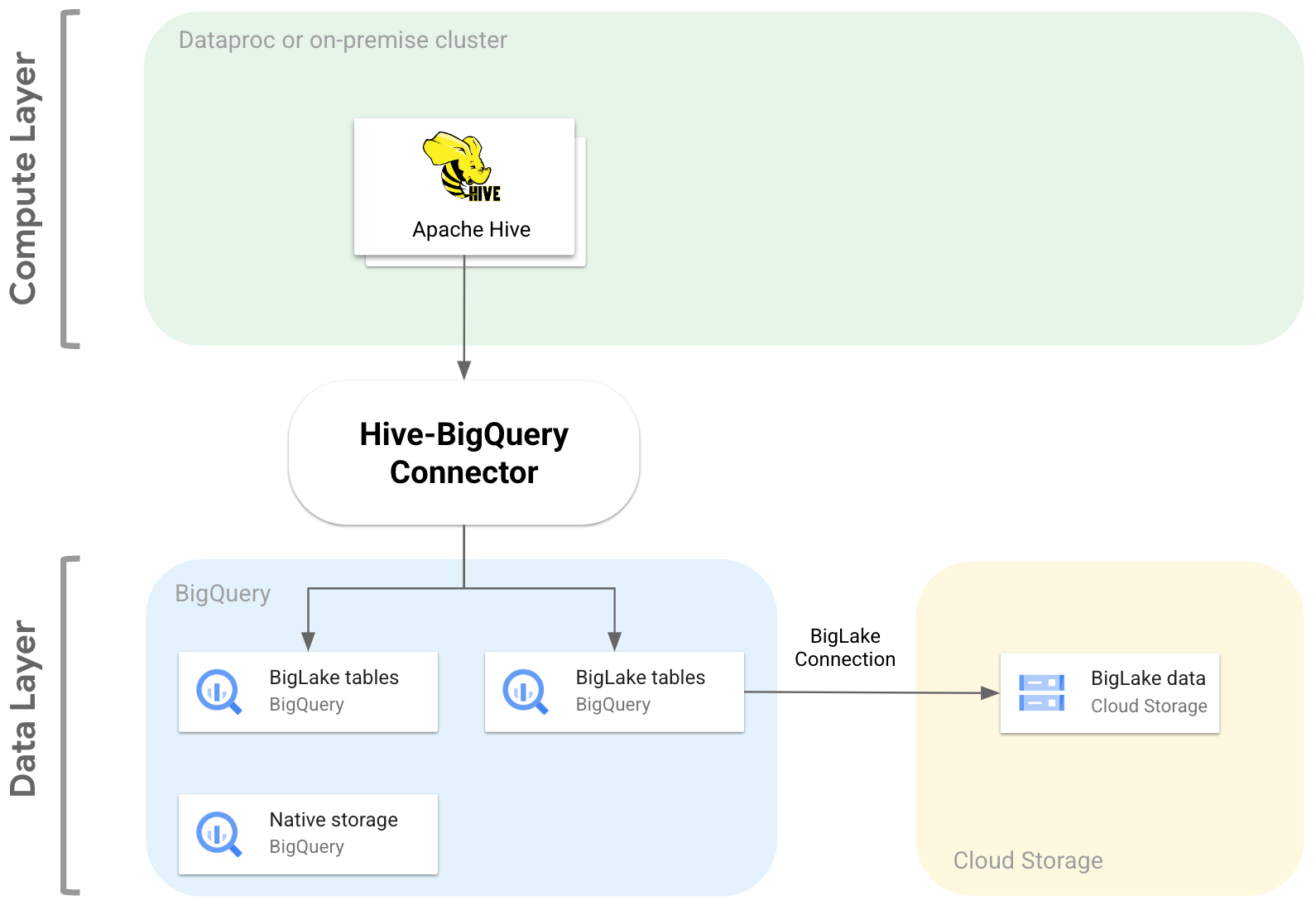
Le diagramme suivant illustre la façon dont le connecteur Hive-BigQuery s'insère entre les couches de calcul et de données.
Cas d'utilisation
Voici quelques exemples de scénarios courants basés sur les données dans lesquels le connecteur Hive-BigQuery peut vous aider :
Migration de données. Vous prévoyez de migrer votre entrepôt de données Hive vers BigQuery, puis de traduire progressivement vos requêtes Hive dans le dialecte SQL de BigQuery. Vous vous attendez à ce que la migration prenne beaucoup de temps en raison de la taille de votre entrepôt de données et du grand nombre d'applications connectées. Vous devez assurer la continuité pendant les opérations de migration. Voici le workflow :
- Vous migrez vos données vers BigQuery.
- À l'aide du connecteur, vous pouvez accéder à vos requêtes Hive d'origine et les exécuter tout en traduisant progressivement les requêtes Hive dans le dialecte SQL conforme à la norme ANSI de BigQuery.
- Une fois la migration et la traduction terminées, vous mettez hors service Hive.
Workflows Hive et BigQuery. Vous prévoyez d'utiliser Hive pour certaines tâches et BigQuery pour les charges de travail qui bénéficient de ses fonctionnalités, telles que BigQuery BI Engine ou BigQuery ML. Vous utilisez le connecteur pour joindre des tables Hive à vos tables BigQuery.
Dépendance à une pile de logiciels Open Source (OSS). Pour éviter le verrouillage du fournisseur, vous utilisez une pile OSS complète pour votre entrepôt de données. Voici votre forfait de données :
Vous migrez vos données dans leur format OSS d'origine (Avro, Parquet ou ORC, par exemple) vers des buckets Cloud Storage à l'aide d'une connexion BigLake.
Vous continuez à utiliser Hive pour exécuter et traiter vos requêtes de dialecte Hive SQL.
Vous utilisez le connecteur selon vos besoins pour vous connecter à BigQuery et bénéficier des fonctionnalités suivantes :
- Mise en cache des métadonnées pour les performances des requêtes
- Protection contre la perte de données
- Contrôle des accès au niveau des colonnes
- Le masquage dynamique des données pour la sécurité et la gouvernance à grande échelle.
Fonctionnalités
Vous pouvez utiliser le connecteur Hive-BigQuery pour travailler avec vos données BigQuery et effectuer les tâches suivantes :
- Exécutez des requêtes avec les moteurs d'exécution MapReduce et Tez.
- Créez et supprimez des tables BigQuery à partir de Hive.
- Joignez des tables BigQuery et BigLake à des tables Hive.
- Effectuer des lectures rapides à partir de tables BigQuery à l'aide des flux de l'API Storage Read et du format Apache Arrow
- Écrivez des données dans BigQuery à l'aide des méthodes suivantes :
- Écritures directes à l'aide de l'API BigQuery Storage Write en mode attente. Utilisez cette méthode pour les charges de travail qui nécessitent une faible latence d'écriture, comme les tableaux de bord en quasi-temps réel avec de courtes périodes d'actualisation.
- Écritures indirectes en transférant des fichiers Avro temporaires vers Cloud Storage, puis en chargeant les fichiers dans une table de destination à l'aide de l'API Load Job. Cette méthode est moins coûteuse que la méthode directe, car les tâches de chargement BigQuery n'entraînent pas de frais. Cette méthode étant plus lente, elle est plus adaptée aux charges de travail qui ne sont pas urgentes.
Accéder aux tables BigQuery partitionnées par date et mises en cluster. L'exemple suivant définit la relation entre une table Hive et une table partitionnée et mise en cluster dans BigQuery.
CREATE TABLE my_hive_table (int_val BIGINT, text STRING, ts TIMESTAMP) STORED BY 'com.google.cloud.hive.bigquery.connector.BigQueryStorageHandler' TBLPROPERTIES ( 'bq.table'='myproject.mydataset.mytable', 'bq.time.partition.field'='ts', 'bq.time.partition.type'='MONTH', 'bq.clustered.fields'='int_val,text' );
Supprimez les colonnes pour éviter de récupérer des colonnes inutiles de la couche de données.
Utilisez les pushdowns de prédicats pour préfiltrer les lignes de données au niveau de la couche de stockage BigQuery. Cette technique peut améliorer considérablement les performances globales des requêtes en réduisant la quantité de données transitant sur le réseau.
Convertissez automatiquement les types de données Hive en types de données BigQuery.
Consultez les vues et les instantanés de table BigQuery.
Intégrez-le à Spark SQL.
Intégration à Apache Pig et HCatalog.
Commencer
Consultez les instructions pour installer et configurer le connecteur Hive-BigQuery sur un cluster Hive.