Dataproc 이미지 버전 1.5 및 2.0에서 사용할 수 있는 Dataproc Ranger Cloud Storage 플러그인은 각 Dataproc 클러스터 VM에서 승인 서비스를 활성화합니다. 승인 서비스는 Ranger 정책에 대해 Cloud Storage 커넥터의 요청을 평가하고, 요청이 허용되는 경우 클러스터 VM 서비스 계정의 액세스 토큰을 반환합니다.
Ranger Cloud Storage 플러그인은 인증에 Kerberos를 사용하며 위임 토큰용 Cloud Storage 커넥터 지원과 통합됩니다. 위임 토큰은 클러스터 마스터 노드의 MySQL 데이터베이스에 저장됩니다. 데이터베이스의 루트 비밀번호는 Dataproc 클러스터를 만들 때 클러스터 속성을 통해 지정됩니다.
시작하기 전에
프로젝트의 Dataproc VM 서비스 계정에 서비스 계정 토큰 생성자 역할 및IAM 역할 관리자 역할을 부여합니다.
Ranger Cloud Storage 플러그인 설치
로컬 터미널 창 또는 Cloud Shell에서 다음 명령어를 실행하여 Dataproc 클러스터를 만들 때 Ranger Cloud Storage 플러그인을 설치합니다.
환경 변수 설정하기
export CLUSTER_NAME=new-cluster-name \ export REGION=region \ export KERBEROS_KMS_KEY_URI=Kerberos-KMS-key-URI \ export KERBEROS_PASSWORD_URI=Kerberos-password-URI \ export RANGER_ADMIN_PASSWORD_KMS_KEY_URI=Ranger-admin-password-KMS-key-URI \ export RANGER_ADMIN_PASSWORD_GCS_URI=Ranger-admin-password-GCS-URI \ export RANGER_GCS_PLUGIN_MYSQL_KMS_KEY_URI=MySQL-root-password-KMS-key-URI \ export RANGER_GCS_PLUGIN_MYSQL_PASSWORD_URI=MySQL-root-password-GCS-URI
참고:
- CLUSTER_NAME: 새 클러스터의 이름입니다.
- REGION: 클러스터가 만들어질 리전(예:
us-west1)입니다. - KERBEROS_KMS_KEY_URI 및 KERBEROS_PASSWORD_URI: Kerberos 루트 주 구성원 비밀번호 설정을 참조하세요.
- RANGER_ADMIN_PASSWORD_KMS_KEY_URI 및 RANGER_ADMIN_PASSWORD_GCS_URI: Ranger 관리자 비밀번호 설정을 참조하세요.
- RANGER_GCS_PLUGIN_MYSQL_KMS_KEY_URI 및 RANGER_GCS_PLUGIN_MYSQL_PASSWORD_URI: Ranger 관리자 비밀번호를 설정할 때와 동일한 절차를 따라 MySQL 비밀번호를 설정합니다.
Dataproc 클러스터 만들기
다음 명령어를 실행하여 Dataproc 클러스터를 만들고 클러스터에 Ranger Cloud Storage 플러그인을 설치합니다.
gcloud dataproc clusters create ${CLUSTER_NAME} \
--region=${REGION} \
--scopes cloud-platform \
--enable-component-gateway \
--optional-components=SOLR,RANGER \
--kerberos-kms-key=${KERBEROS_KMS_KEY_URI} \
--kerberos-root-principal-password-uri=${KERBEROS_PASSWORD_URI} \
--properties="dataproc:ranger.gcs.plugin.enable=true, \
dataproc:ranger.kms.key.uri=${RANGER_ADMIN_PASSWORD_KMS_KEY_URI}, \
dataproc:ranger.admin.password.uri=${RANGER_ADMIN_PASSWORD_GCS_URI}, \
dataproc:ranger.gcs.plugin.mysql.kms.key.uri=${RANGER_GCS_PLUGIN_MYSQL_KMS_KEY_URI}, \
dataproc:ranger.gcs.plugin.mysql.password.uri=${RANGER_GCS_PLUGIN_MYSQL_PASSWORD_URI}"
참고:
- 1.5 이미지 버전: 1.5 이미지 버전 클러스터를 만드는 경우(버전 선택 참조)
--metadata=GCS_CONNECTOR_VERSION="2.2.6" or higher플래그를 추가하여 필요한 커넥터 버전을 설치합니다.
Ranger Cloud Storage 플러그인 설치 확인
클러스터 생성이 완료되면 gcs-dataproc이라는 GCS 서비스 유형이 Ranger 관리자 웹 인터페이스에 표시됩니다.
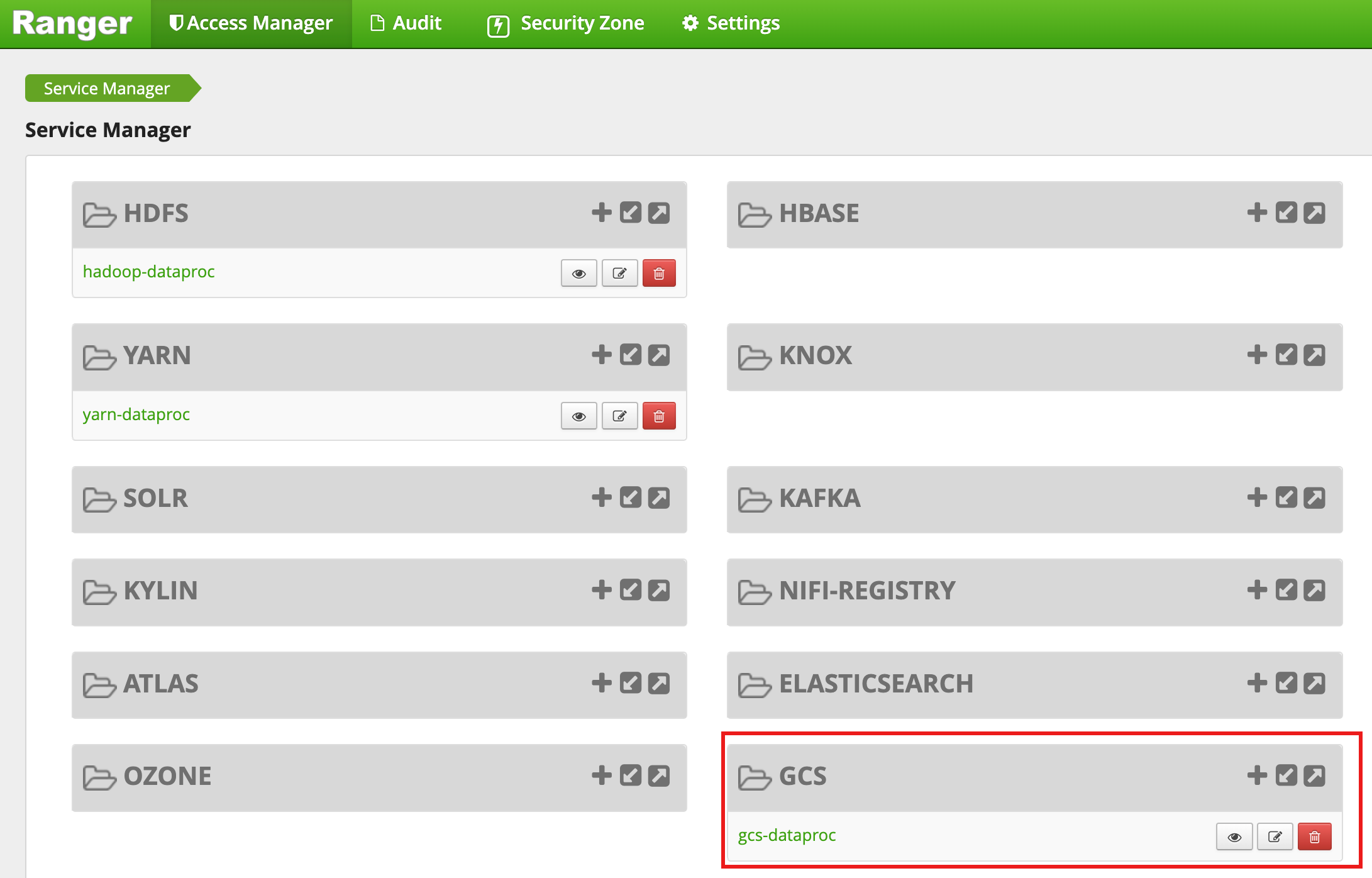
Ranger Cloud Storage 플러그인 기본 정책
기본 gcs-dataproc 서비스에는 다음 정책이 포함됩니다.
Dataproc 클러스터 스테이징 및 임시 버킷에서 읽고 쓰는 정책
all - bucket, object-path정책: 모든 사용자가 모든 객체의 메타데이터에 액세스할 수 있습니다. 이 액세스는 Cloud Storage 커넥터가 HCFS(Hadoop 호환 파일 시스템) 작업을 수행할 수 있도록 하는 데 필요합니다.
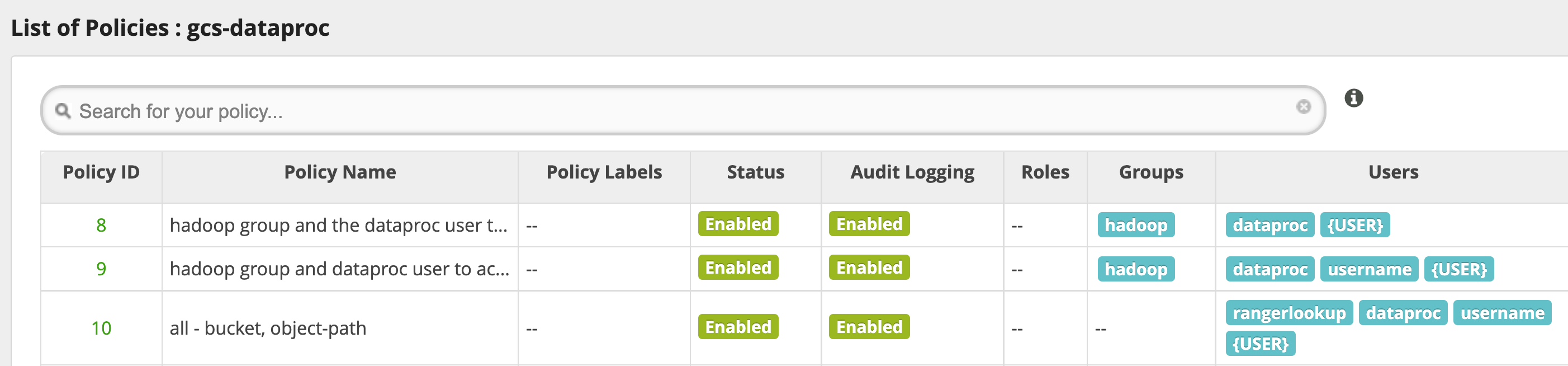
사용 도움말
버킷 폴더에 대한 앱 액세스 권한
Cloud Storage 버킷에 중간 파일을 만드는 앱을 수용하려면 Cloud Storage 버킷 경로에 Modify Objects, List Objects, Delete Objects 권한을 부여한 후 recursive 모드를 사용하여 지정된 경로의 하위 경로로 해당 권한을 확장합니다.
보호 조치
플러그인 우회를 방지하려면 다음 안내를 따르세요.
VM 서비스 계정에 Cloud Storage 버킷의 리소스에 대한 액세스 권한을 부여하여 범위가 축소된 액세스 토큰으로 해당 리소스에 대한 액세스 권한을 부여합니다(Cloud Storage에 대한 IAM 권한 참조). 또한 사용자가 버킷 리소스에 대한 액세스 권한을 삭제하여 사용자가 버킷에 직접 액세스하지 못하게 합니다.
sudoer파일 업데이트를 포함한 클러스터 VM에서sudo및 기타 루트 액세스 방법을 사용 중지하여 인증 및 승인 설정의 명의 도용 또는 변경을 방지합니다. 자세한 내용은sudo사용자 권한 추가/삭제에 대한 Linux 안내를 참조하세요.iptable을 사용하여 클러스터 VM에서 Cloud Storage에 대한 직접 액세스 요청을 차단합니다. 예를 들어 VM 메타데이터 서버 액세스를 차단하여 Cloud Storage에 대한 액세스를 인증 및 승인하는 데 사용되는 VM 서비스 계정 사용자 인증 정보 또는 액세스 토큰에 대한 액세스를 차단할 수 있습니다(iptable규칙을 사용하여 VM 메타데이터 서버로의 액세스를 차단하는 초기화 스크립트인block_vm_metadata_server.sh참조).
Spark, Hive-on-MapReduce, Hive-on-Tez 작업
민감한 사용자 인증 세부정보를 보호하고 키 배포 센터(KDC)의 부하를 줄이기 위해 Spark 드라이버는 실행자에 Kerberos 사용자 인증 정보를 배포하지 않습니다. 대신 Spark 드라이버는 Ranger Cloud Storage 플러그인에서 위임 토큰을 가져온 후 실행자에 위임 토큰을 배포합니다. 실행자는 위임 토큰을 사용하여 Ranger Cloud Storage 플러그인에 인증하고 Cloud Storage에 대한 액세스를 허용하는 Google 액세스 토큰으로 거래합니다.
Hive-on-MapReduce 및 Hive-on-Tez 작업도 토큰을 사용하여 Cloud Storage에 액세스합니다. 다음 작업 유형을 제출할 때 다음 속성을 사용하여 지정된 Cloud Storage 버킷에 액세스할 수 있는 토큰을 얻으세요.
Spark 작업:
--conf spark.yarn.access.hadoopFileSystems=gs://bucket-name,gs://bucket-name,...
Hive-on-MapReduce 작업:
--hiveconf "mapreduce.job.hdfs-servers=gs://bucket-name,gs://bucket-name,..."
Hive-on-Tez 작업:
--hiveconf "tez.job.fs-servers=gs://bucket-name,gs://bucket-name,..."
Spark 작업 시나리오
Ranger Cloud Storage 플러그인이 설치된 Dataproc 클러스터 VM의 터미널 창에서 실행하면 Spark WordCount 작업이 실패합니다.
spark-submit \
--conf spark.yarn.access.hadoopFileSystems=gs://${FILE_BUCKET} \
--class org.apache.spark.examples.JavaWordCount \
/usr/lib/spark/examples/jars/spark-examples.jar \
gs://bucket-name/wordcount.txt
참고:
- FILE_BUCKET: Spark 액세스를 위한 Cloud Storage 버킷입니다.
오류 출력:
Caused by: com.google.gcs.ranger.client.shaded.io.grpc.StatusRuntimeException: PERMISSION_DENIED: Access denied by Ranger policy: User: '<USER>', Bucket: '<dataproc_temp_bucket>', Object Path: 'a97127cf-f543-40c3-9851-32f172acc53b/spark-job-history/', Action: 'LIST_OBJECTS'
참고:
- Kerberos 지원 환경에는
spark.yarn.access.hadoopFileSystems=gs://${FILE_BUCKET}이 필요합니다.
오류 출력:
Caused by: java.lang.RuntimeException: Failed creating a SPNEGO token. Make sure that you have run `kinit` and that your Kerberos configuration is correct. See the full Kerberos error message: No valid credentials provided (Mechanism level: No valid credentials provided)
Ranger 관리자 웹 인터페이스에서 액세스 관리자를 사용하여 정책을 편집하고 List Objects 및 기타 temp 버킷 권한이 있는 사용자 목록에 username을 추가합니다.
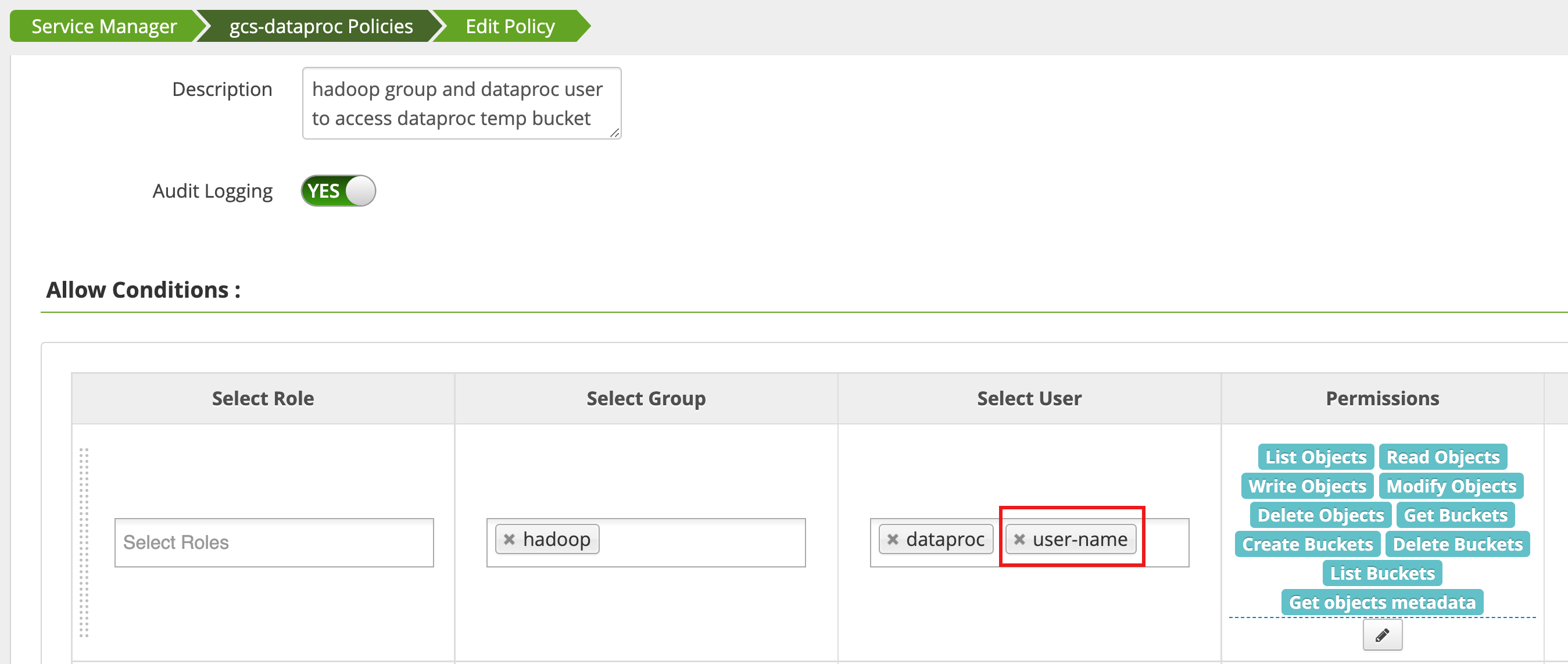
작업을 실행하면 새로운 오류가 발생합니다.
오류 출력:
com.google.gcs.ranger.client.shaded.io.grpc.StatusRuntimeException: PERMISSION_DENIED: Access denied by Ranger policy: User: <USER>, Bucket: '<file-bucket>', Object Path: 'wordcount.txt', Action: 'READ_OBJECTS'
사용자에게 wordcount.text Cloud Storage 경로에 대한 읽기 액세스 권한을 부여하기 위해 정책이 추가됩니다.
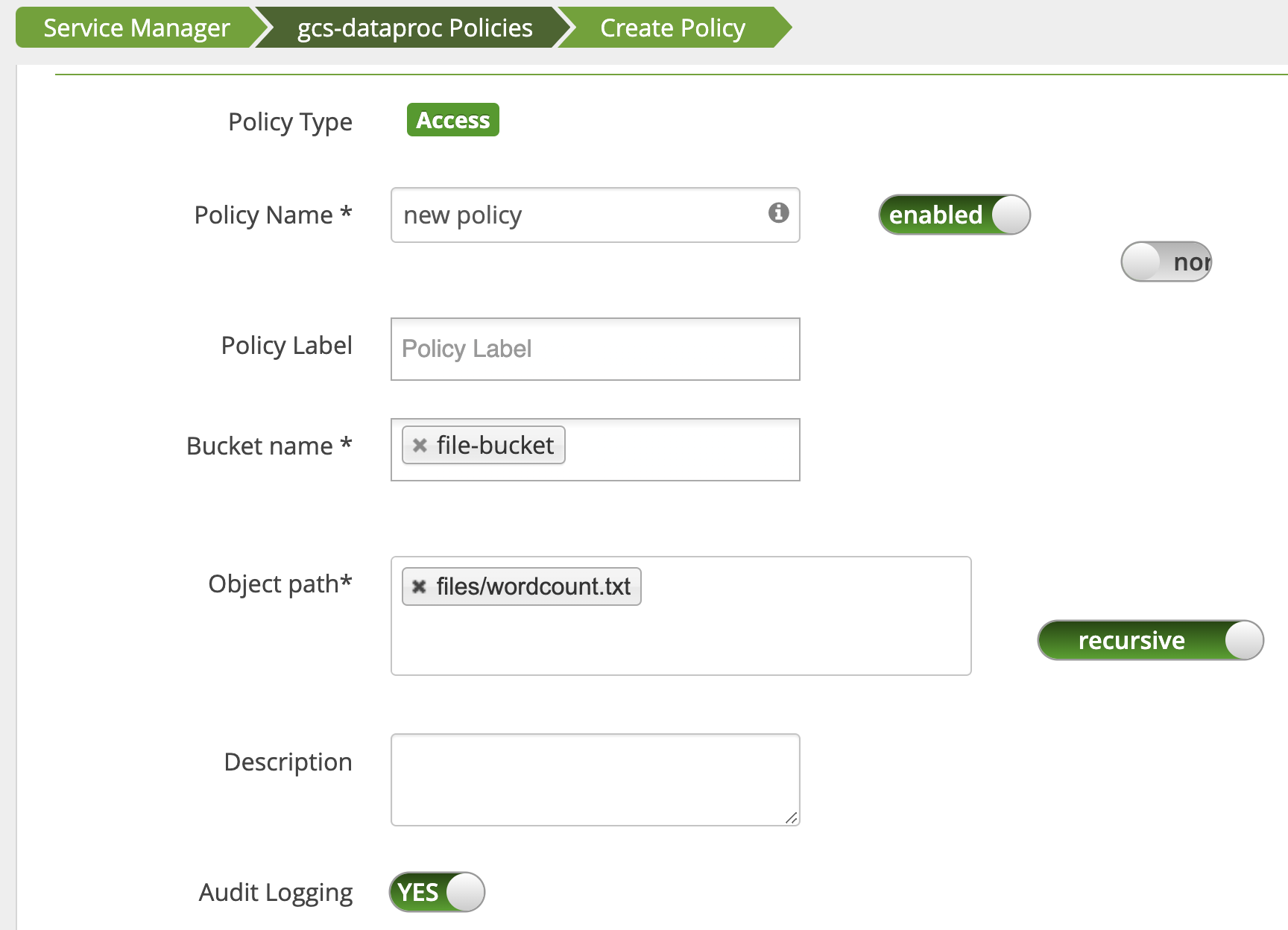
작업이 실행되고 완료됩니다.
INFO com.google.cloud.hadoop.fs.gcs.auth.GcsDelegationTokens: Using delegation token RangerGCSAuthorizationServerSessionToken owner=<USER>, renewer=yarn, realUser=, issueDate=1654116824281, maxDate=0, sequenceNumber=0, masterKeyId=0 this: 1 is: 1 a: 1 text: 1 file: 1 22/06/01 20:54:13 INFO org.sparkproject.jetty.server.AbstractConnector: Stopped