Dataflow recoge métricas de tus trabajos, lo que puede ayudarte a depurar errores, solucionar problemas de rendimiento u optimizar tu flujo de procesamiento. La interfaz de monitorización de Dataflow muestra visualizaciones de estas métricas. También puedes usar Cloud Monitoring para crear alertas o generar consultas del Explorador de métricas.
Acceder a las métricas de tareas
Para ver las métricas de un trabajo, sigue estos pasos:
En la Google Cloud consola, ve a la página Dataflow > Trabajos.
Selecciona un trabajo.
Haz clic en la pestaña Métricas de los trabajos.
Selecciona una métrica para verla.
Para acceder a información adicional en los gráficos de métricas de trabajo, haga clic en Explorar datos.
Cada métrica se organiza en los siguientes paneles de control:
- Métricas de autoescalado
- Métricas de resumen
- Métricas de streaming
- Métricas de recursos
- Métricas de entrada y salida
Compatibilidad y limitaciones
Cuando utilice las métricas de Dataflow, tenga en cuenta los siguientes detalles.
A veces, los datos de los trabajos no están disponibles de forma intermitente. Cuando faltan datos, aparecen huecos en los gráficos de monitorización de tareas.
Algunos de estos gráficos son específicos de las canalizaciones de streaming.
Para escribir datos de métricas, una cuenta de servicio gestionada por el usuario debe tener el permiso de la API IAM
monitoring.timeSeries.create. Este permiso se incluye en el rol de trabajador de Dataflow.El servicio Dataflow informa del tiempo de CPU reservado después de que se completen las tareas. En el caso de los trabajos sin límites (streaming), el tiempo de CPU reservado solo se informa después de que se cancelen o fallen los trabajos. Por lo tanto, las métricas de los trabajos no incluyen el tiempo de CPU reservado para los trabajos de streaming.
Métricas de autoescalado
El autoescalado horizontal permite que Dataflow elija el número adecuado de instancias de trabajador para tu tarea, añadiendo o eliminando trabajadores según sea necesario.
En la sección Autoescalado de la pestaña Métricas de la tarea se muestra el número de trabajadores y el número objetivo de trabajadores a lo largo del tiempo. Si tu trabajo usa Streaming Engine, también se muestra el número mínimo y máximo de trabajadores.
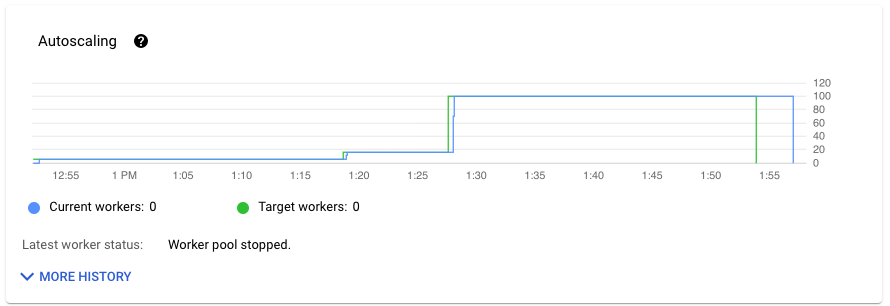
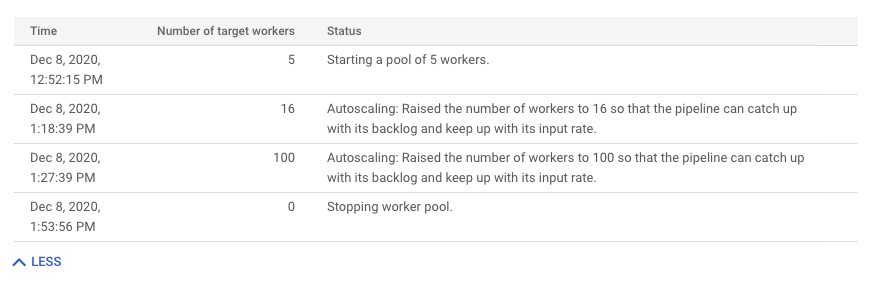
Para ver el historial de cambios del escalado automático, haga clic en Más historial. Se muestra una tabla con información sobre el historial de trabajadores de tu tarea.
Para ver más información sobre el autoescalado de las tareas de streaming, haz clic en la pestaña Autoescalado. Para obtener más información, consulta Monitorizar el autoescalado de Dataflow.
Métricas de resumen
Las siguientes métricas se muestran en Métricas de resumen.
Actualización de datos
Esta métrica solo se aplica a los trabajos de streaming.
La actualización de los datos es la diferencia entre el momento en el que se procesa un elemento de datos (tiempo de procesamiento) y la marca de tiempo del elemento de datos (tiempo del evento). Los valores más altos indican que ha habido un retraso mayor entre la hora del evento y la hora de procesamiento.
El gráfico de actualización de datos muestra el valor máximo de actualización de datos en cualquier momento. Dataflow procesa varios elementos en paralelo, por lo que el gráfico refleja el elemento con el mayor retraso en relación con su hora del evento.
Si algunos datos de entrada aún no se han procesado, la marca de agua de salida puede retrasarse, lo que afecta a la actualización de los datos. Una diferencia significativa entre la marca de tiempo y la hora del evento puede indicar que la operación es lenta o se ha bloqueado. Para obtener más información, consulta Marcas de agua y datos tardíos en la documentación de Apache Beam.
El panel de control incluye los dos gráficos siguientes:
- Actualización de datos por fases
- Actualización de datos
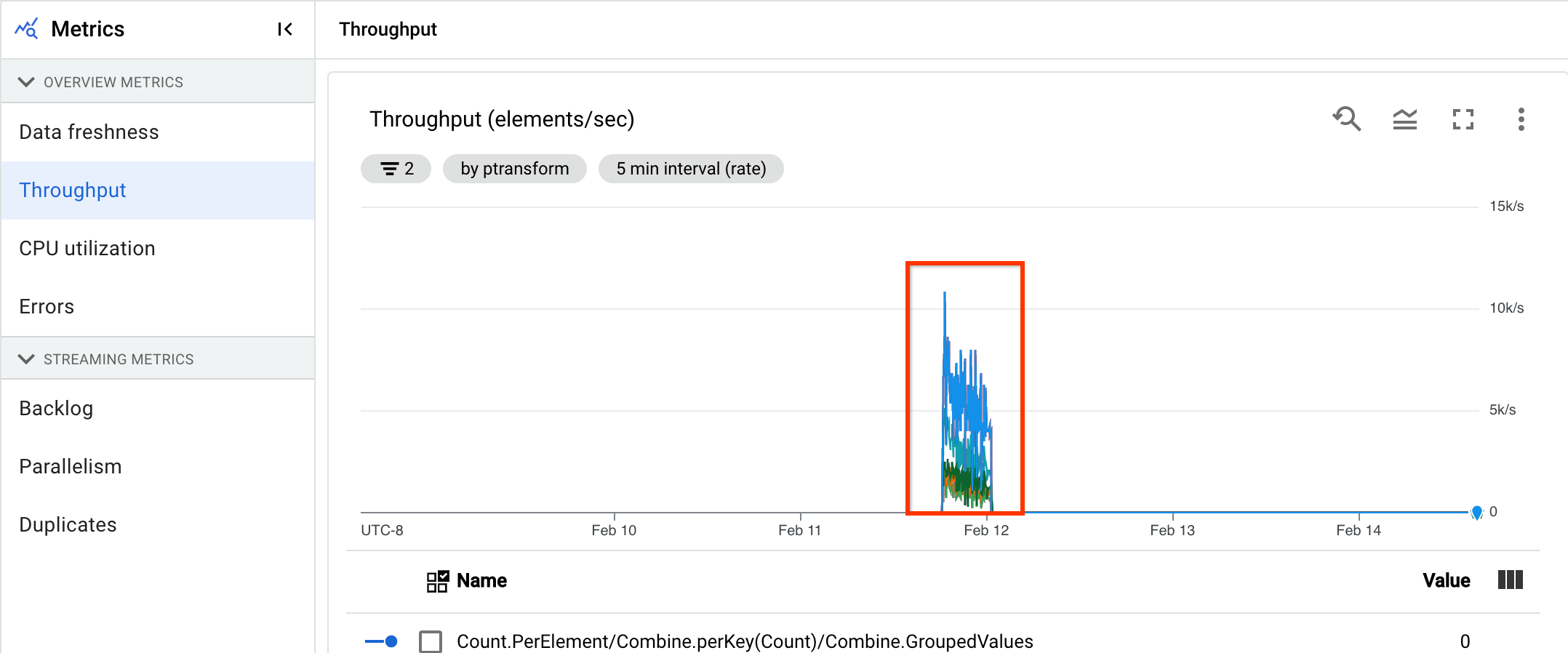
En la siguiente imagen, el área resaltada muestra una gran diferencia entre la hora del evento y la hora de la marca de agua de salida, lo que indica que la operación es lenta.
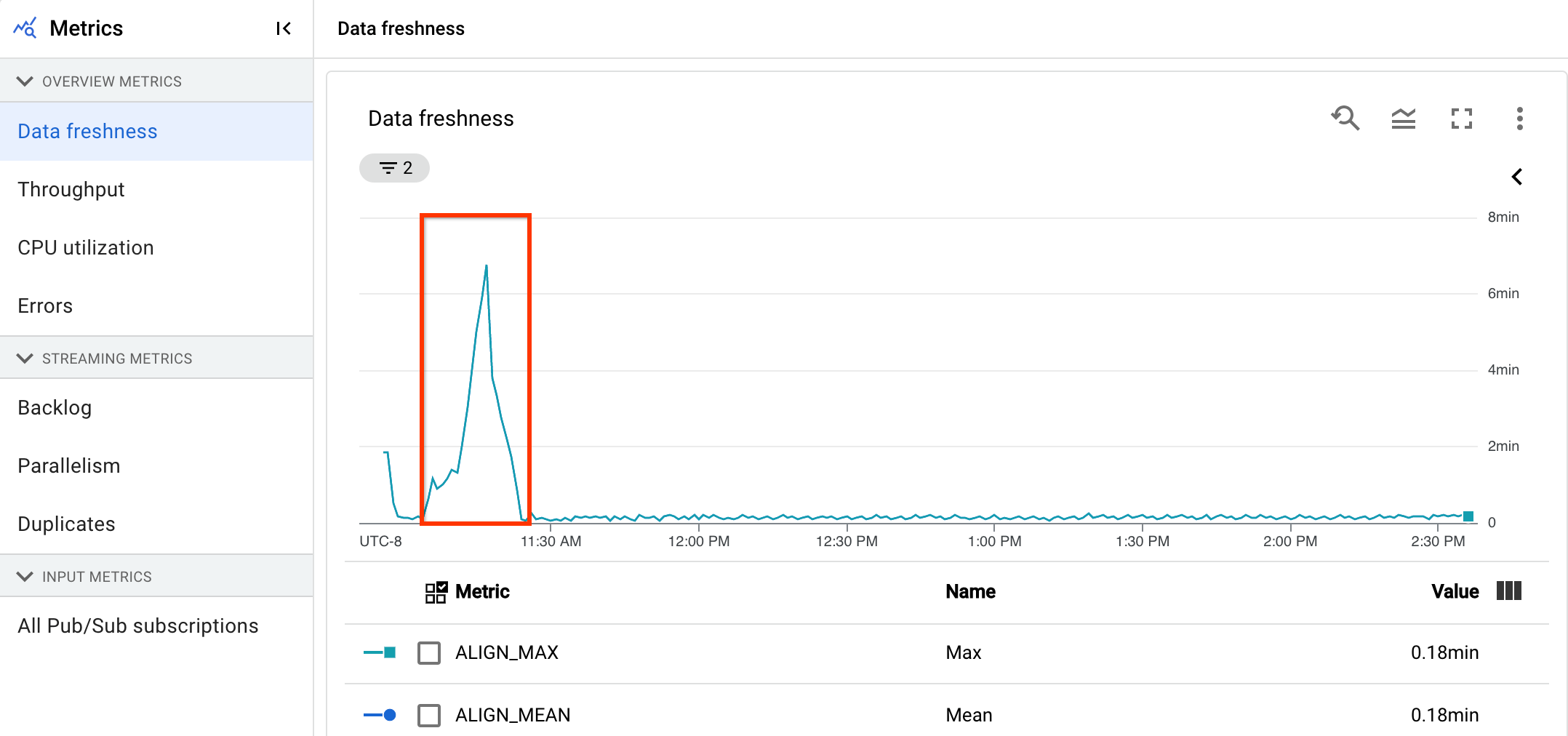
Los siguientes problemas pueden provocar valores altos en esta métrica:
- Cuellos de botella en el rendimiento: si tu canalización tiene fases con una latencia del sistema alta o registros que indican transformaciones bloqueadas, es posible que tenga problemas de rendimiento que puedan aumentar la actualización de los datos. Para investigar más a fondo, consulta Solucionar problemas de trabajos de streaming lentos o bloqueados.
- Cuellos de botella en las fuentes de datos: si sus fuentes de datos tienen una acumulación de trabajo cada vez mayor, las marcas de tiempo de los eventos de sus elementos pueden desviarse de la marca de agua mientras esperan a que se procesen. Los grandes volúmenes de trabajo pendientes suelen deberse a cuellos de botella en el rendimiento o a problemas con las fuentes de datos, que se detectan mejor monitorizando las fuentes que usa tu canalización.
- Las fuentes sin ordenar, como Pub/Sub, pueden generar marcas de agua atascadas incluso cuando la salida es alta. Esto ocurre porque los elementos no se generan en orden de marca de tiempo y la marca de agua se basa en la marca de tiempo mínima sin procesar.
- Reintentos frecuentes: si ves algún error que indique que no se pueden procesar elementos y que se están reintentando, es posible que las marcas de tiempo antiguas de los elementos reintentados estén aumentando la actualización de los datos. La lista de errores habituales de Dataflow puede ayudarte a solucionar problemas.
En el caso de los trabajos de streaming que se hayan actualizado recientemente, es posible que no se muestre información sobre el estado del trabajo ni sobre la marca de agua. La operación de actualización hace varios cambios que tardan unos minutos en propagarse a la interfaz de monitorización de Dataflow. Prueba a actualizar la interfaz de monitorización cinco minutos después de actualizar tu trabajo.
Latencia del sistema
Esta métrica solo se aplica a los trabajos de streaming.
La latencia del sistema es el número máximo de segundos que un elemento de datos se ha estado procesando o ha estado esperando a hacerlo. La métrica incluye el tiempo que esperan los elementos dentro de una fuente. Por ejemplo, si un destino de salida deja de aceptar solicitudes de escritura durante un periodo determinado, los datos pueden acumularse en la fuente, lo que provoca que aumente la latencia del sistema. Si se reanudan las operaciones de escritura y la canalización puede ponerse al día, la latencia del sistema vuelve a su nivel de referencia.
A continuación, se indican otros casos que debes tener en cuenta:
- En el caso de varias fuentes y receptores, la latencia del sistema es el tiempo máximo que espera un elemento en una fuente antes de escribirse en todos los receptores.
- A veces, una fuente no proporciona un valor para el periodo durante el que un elemento espera en la fuente. Además, es posible que el elemento no tenga metadatos para definir la hora del evento. En este caso, la latencia del sistema se calcula desde el momento en que la canalización recibe el elemento por primera vez.
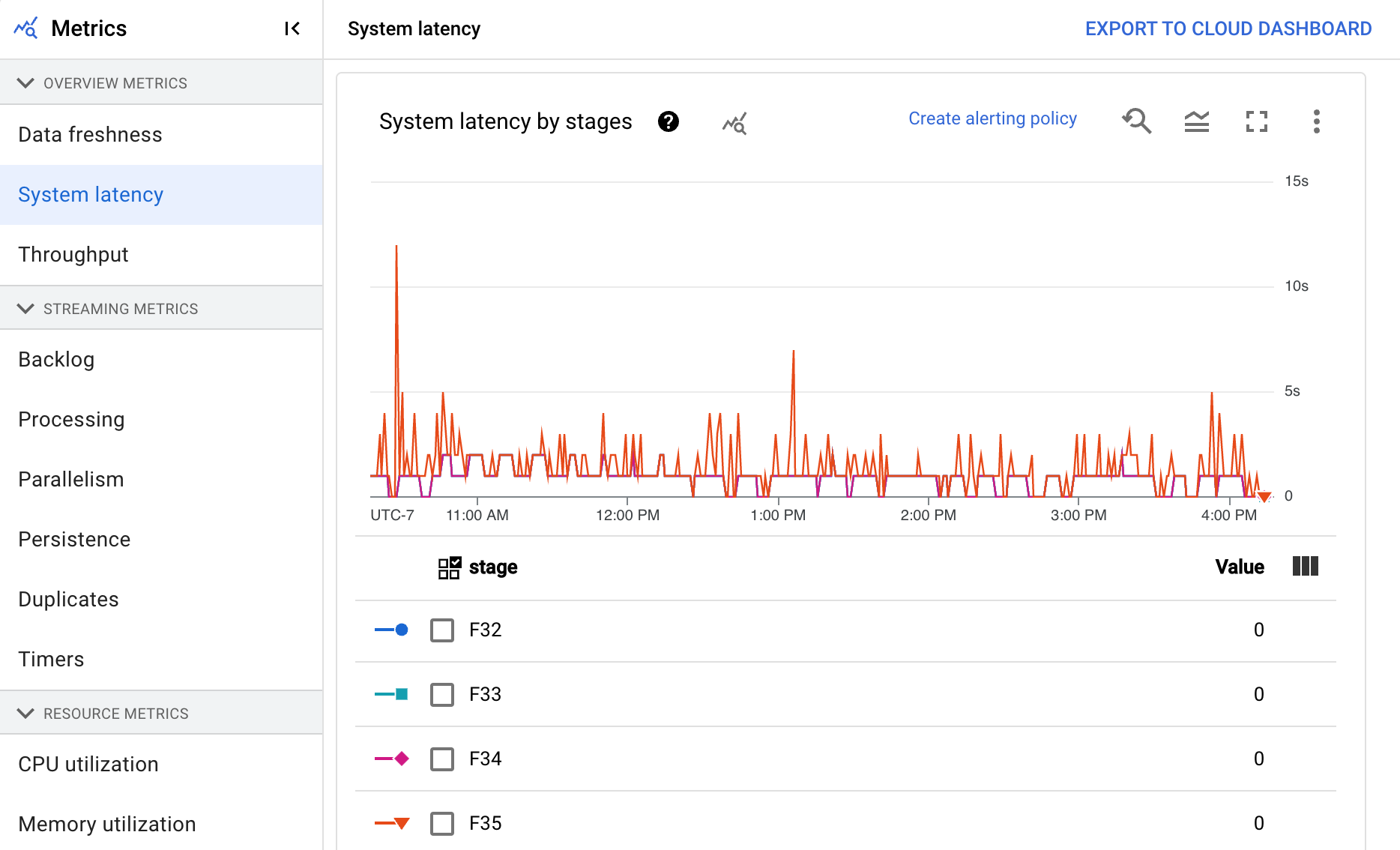
El panel de control incluye los dos gráficos siguientes:
- Latencia del sistema por fases
- Latencia del sistema
Rendimiento
El rendimiento es el volumen de datos que se procesa en cualquier momento. El panel de control incluye los siguientes gráficos:
- Rendimiento por paso en elementos por segundo
- Rendimiento por paso en bytes por segundo
Número de registros de errores del trabajador
El número de registros de errores del trabajador muestra la tasa de errores observada en todos los trabajadores en cualquier momento.

Métricas de streaming
Las siguientes métricas se encuentran en Métricas de streaming.
Backlog
Esta métrica solo se aplica a los trabajos de streaming.
El panel de control Registro proporciona información sobre los elementos que están pendientes de procesarse. El panel de control incluye los dos gráficos siguientes:
- Segundos de trabajo pendiente (solo Streaming Engine)
- Bytes de backlog (con y sin Streaming Engine)
El gráfico Segundos de trabajo pendiente muestra una estimación del tiempo en segundos necesario para consumir el trabajo pendiente actual si no llegan datos nuevos y el rendimiento no cambia. El tiempo de trabajo pendiente estimado se calcula a partir del rendimiento y los bytes de trabajo pendiente de la fuente de entrada que aún deben procesarse. La función de escalado automático de streaming usa esta métrica para determinar cuándo aumentar o reducir la escala.
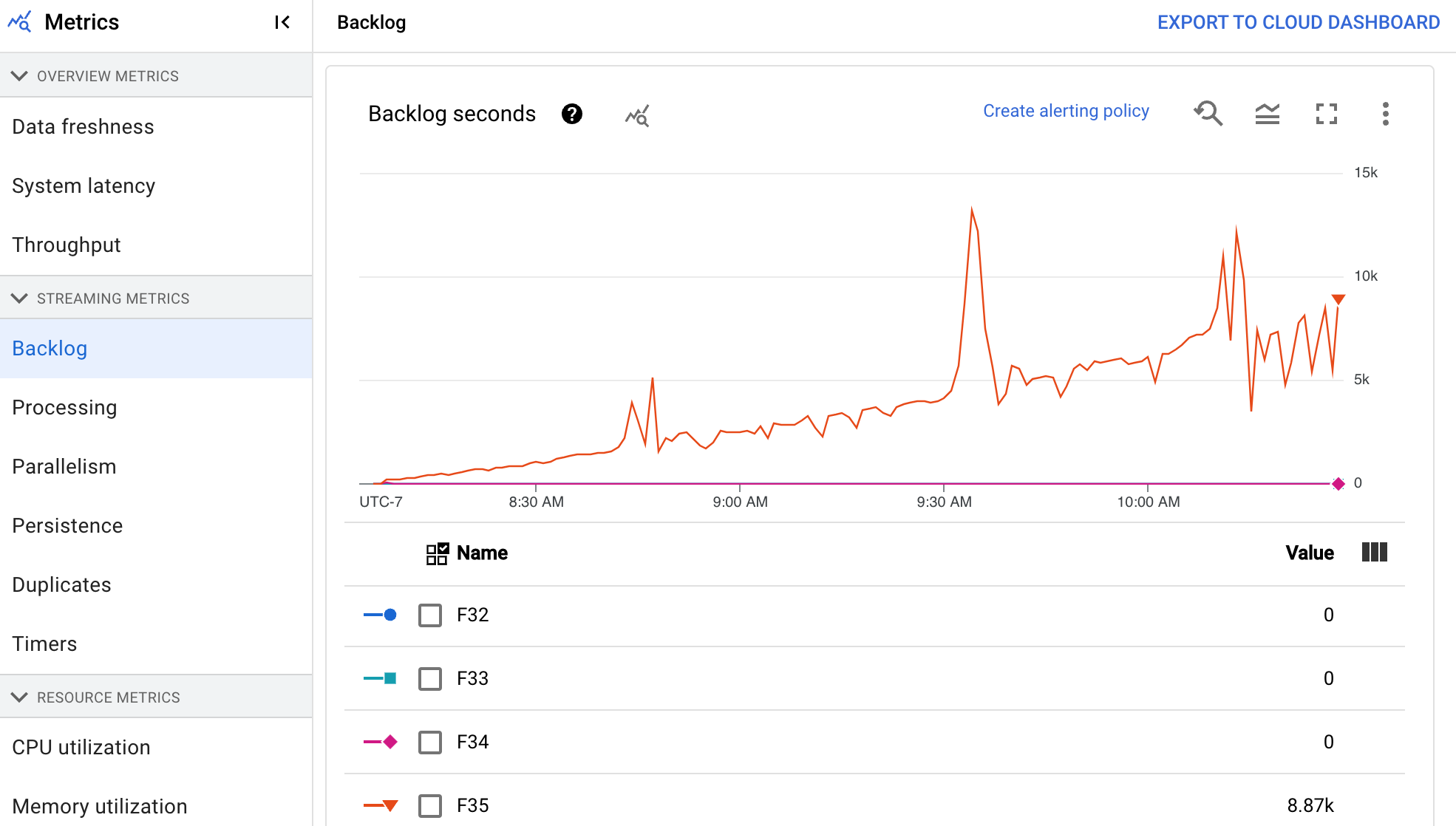
El gráfico Bytes de la lista de pendientes muestra la cantidad de entrada conocida sin procesar de una fase en bytes. Esta métrica compara los bytes restantes que debe consumir cada fase con las fases anteriores. Para que esta métrica se registre con precisión, cada fuente insertada por la canalización debe configurarse correctamente. Las fuentes integradas, como Pub/Sub y BigQuery, ya se admiten de forma predeterminada, pero las fuentes personalizadas requieren una implementación adicional. Para obtener más información, consulta Escalado automático de fuentes personalizadas sin límites.
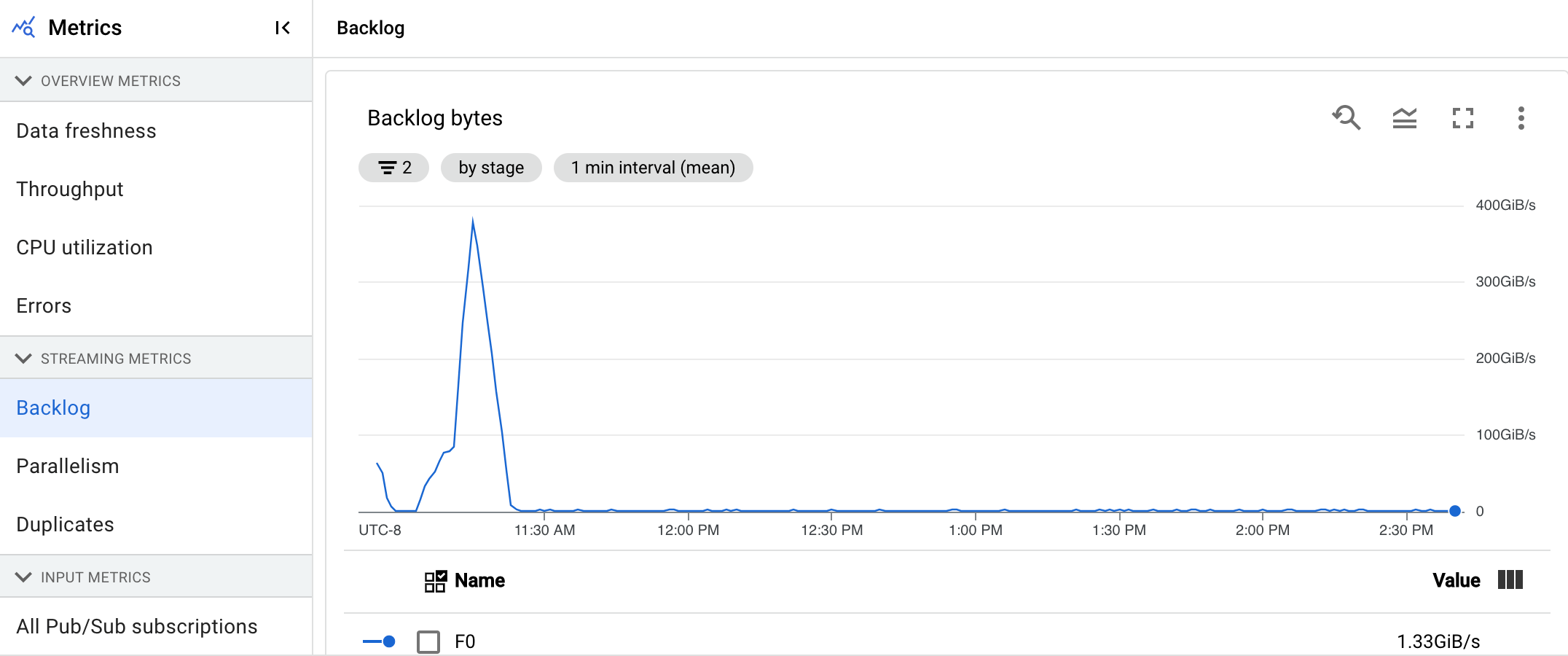
Procesamiento
Esta métrica solo se aplica a los trabajos de streaming.
Cuando ejecutas un flujo de procesamiento de Apache Beam en el servicio Dataflow, las tareas del flujo se ejecutan en máquinas virtuales de trabajador. El panel de control Procesando proporciona información sobre el tiempo que han estado procesando las tareas en las VMs de trabajador. El panel de control incluye los dos gráficos siguientes:
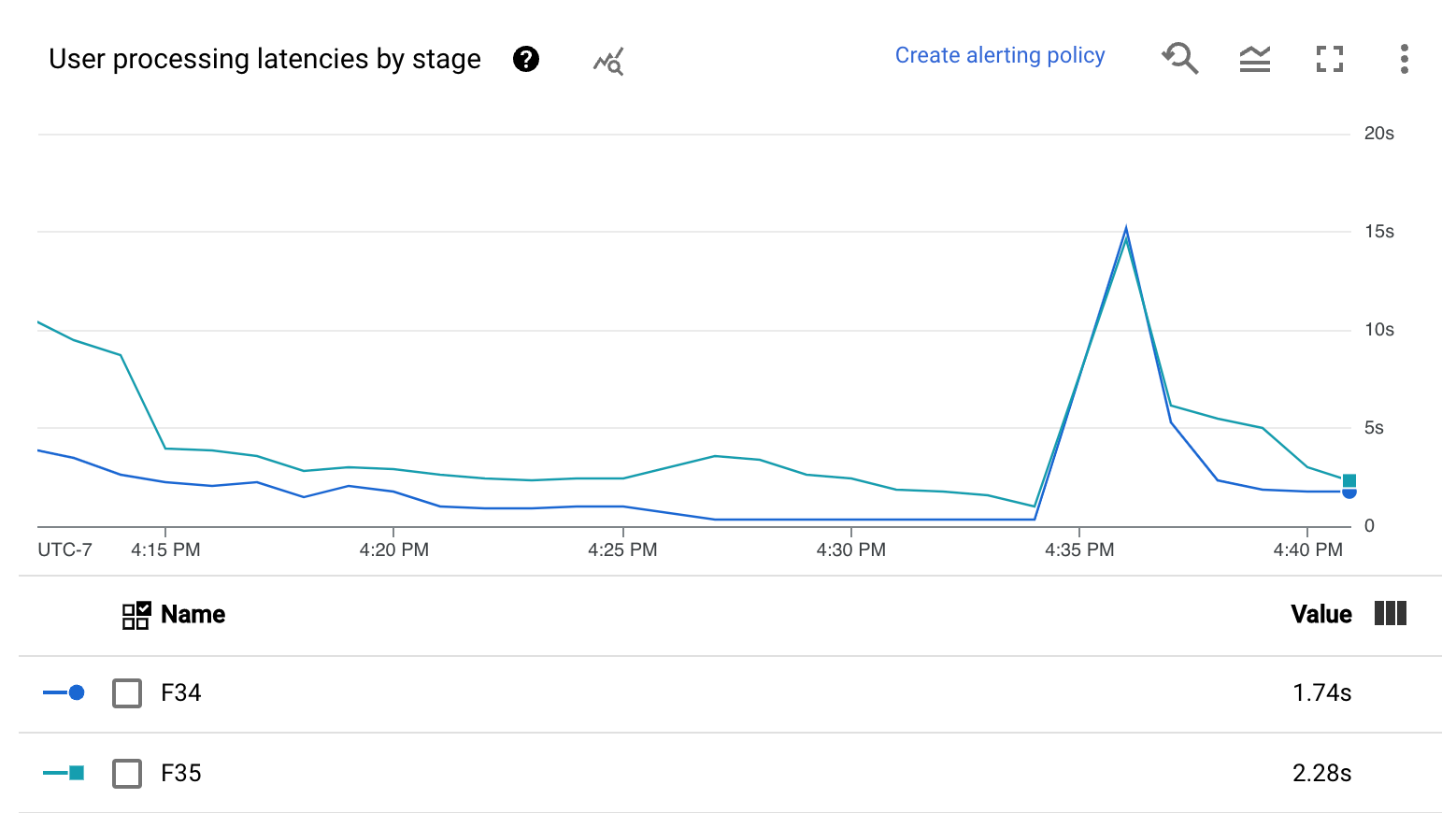
- Mapa de calor de las latencias de procesamiento de usuarios
- Latencias de procesamiento de usuarios por fase
El mapa de calor de latencias de procesamiento de usuarios muestra las latencias máximas de las operaciones en las distribuciones de los percentiles 50, 95 y 99. Usa el mapa de calor para ver si alguna operación de larga duración está provocando una latencia general alta en el sistema o está afectando negativamente a la actualización general de los datos.
Para solucionar un problema upstream antes de que se convierta en un problema downstream, define una política de alertas para latencias altas en el percentil 50.
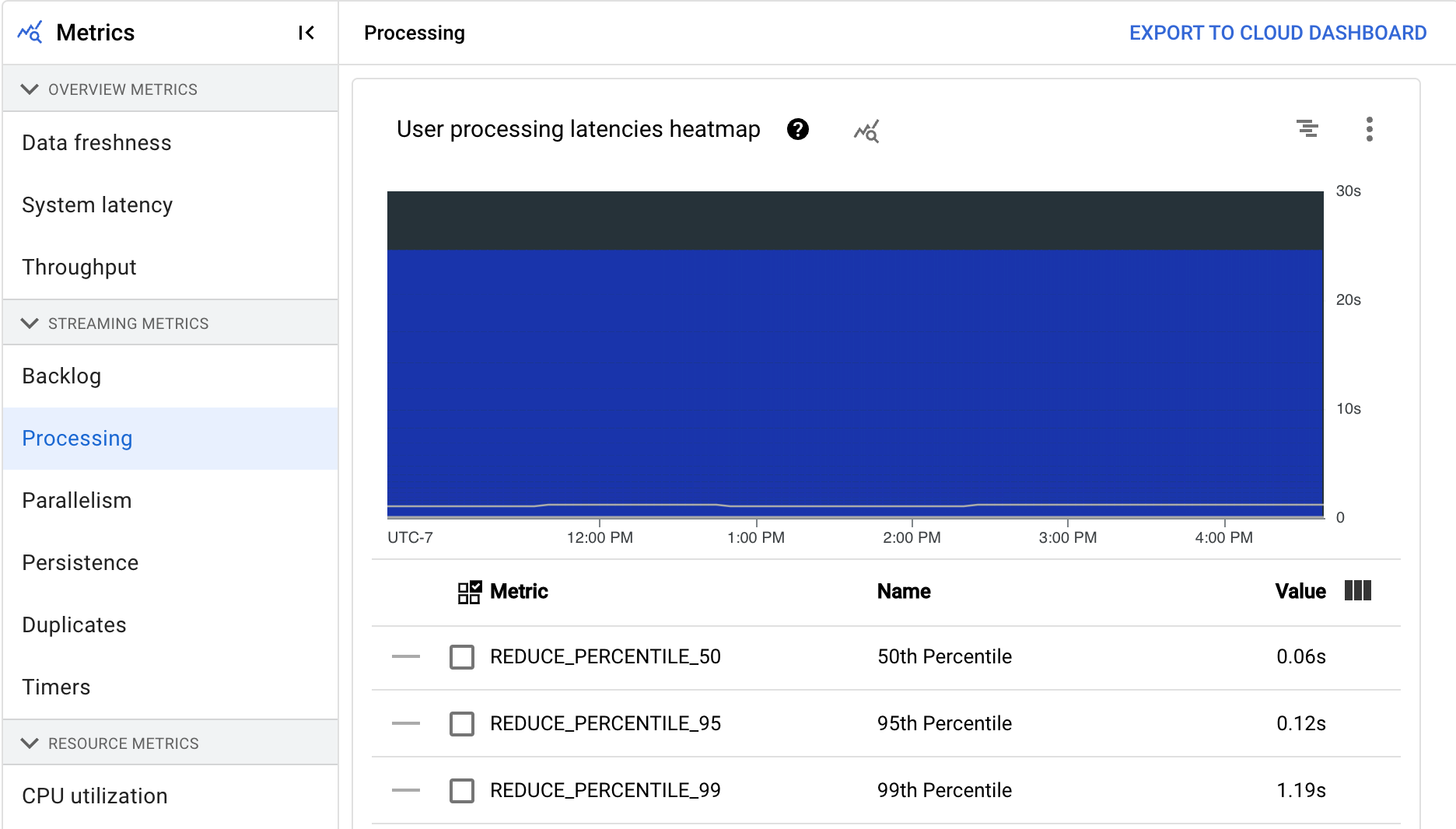
En el gráfico Latencias de procesamiento de usuarios por fase se muestra el percentil 99 de todas las tareas que están procesando los workers, desglosadas por fase. Si el código de usuario está provocando un cuello de botella, este gráfico muestra en qué fase se produce. Para depurar la canalización, sigue estos pasos:
Usa el gráfico para encontrar una fase con una latencia inusualmente alta.
En la página de detalles del trabajo, en la pestaña Detalles de la ejecución, vaya a Vista de gráfico y seleccione Flujo de trabajo de la fase. En el gráfico Flujo de trabajo de la fase, busca la fase que tenga una latencia inusualmente alta.
Para encontrar las operaciones de usuario asociadas, en el gráfico, haz clic en el nodo de esa fase.
Para obtener más información, ve a Cloud Profiler y usa Cloud Profiler para depurar el seguimiento de pila en el intervalo de tiempo correcto. Busca las operaciones de usuario que hayas identificado en el paso anterior.
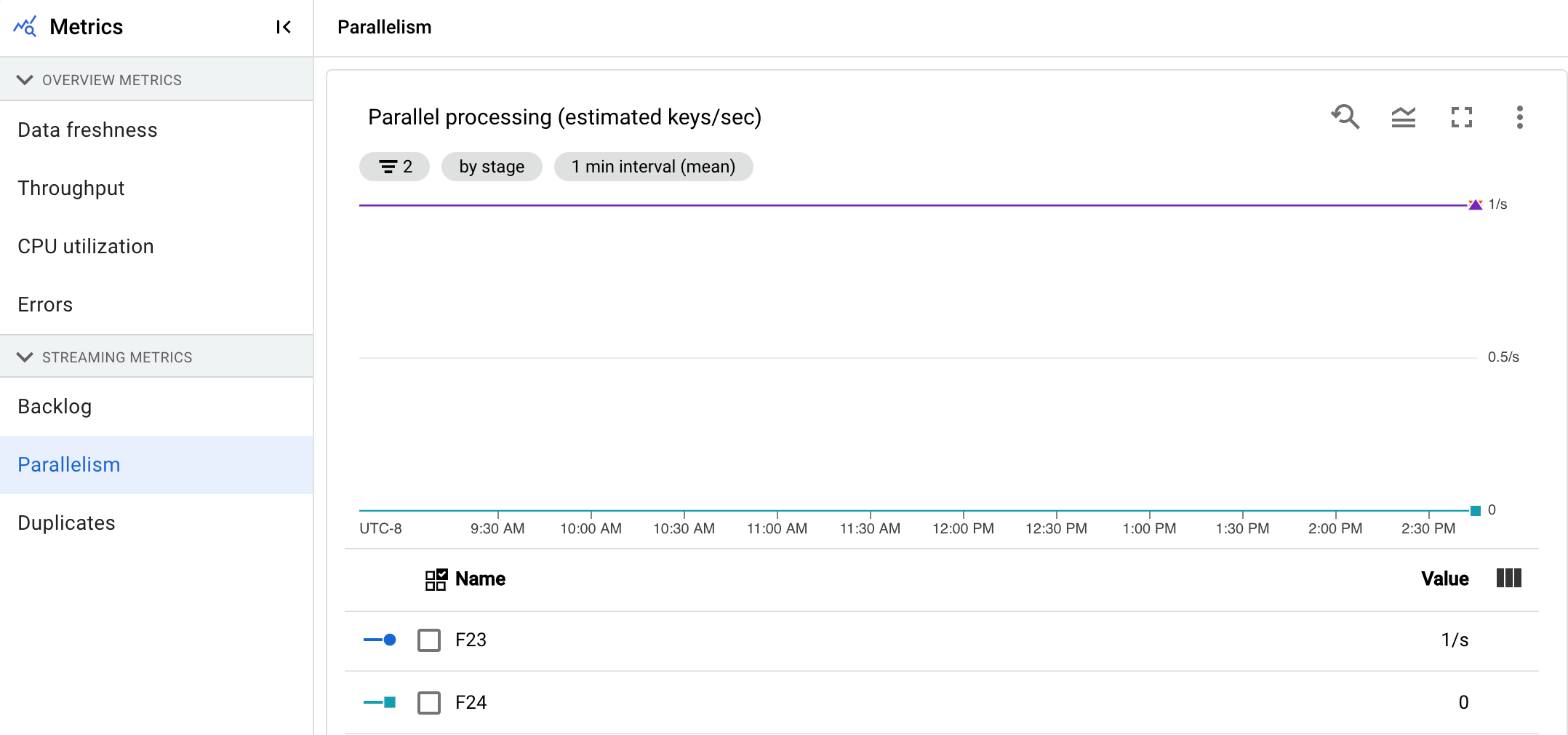
Paralelismo
Esta métrica solo se aplica a los trabajos de Streaming Engine.
El gráfico Procesamiento paralelo muestra el número aproximado de claves en uso para el procesamiento de datos de cada fase. Dataflow se escala en función del paralelismo de una canalización.
Cuando Dataflow ejecuta un flujo de procesamiento, el procesamiento se distribuye entre varias máquinas virtuales (VMs) de Compute Engine, también conocidas como trabajadores. El servicio Dataflow paraleliza y distribuye automáticamente la lógica de procesamiento de tu flujo de procesamiento entre los trabajadores. El procesamiento de cada clave se serializa, por lo que el número total de claves de una fase representa el paralelismo máximo disponible en esa fase.
Las métricas de paralelismo pueden ser útiles para encontrar teclas de acceso rápido o cuellos de botella en las canalizaciones lentas o bloqueadas.
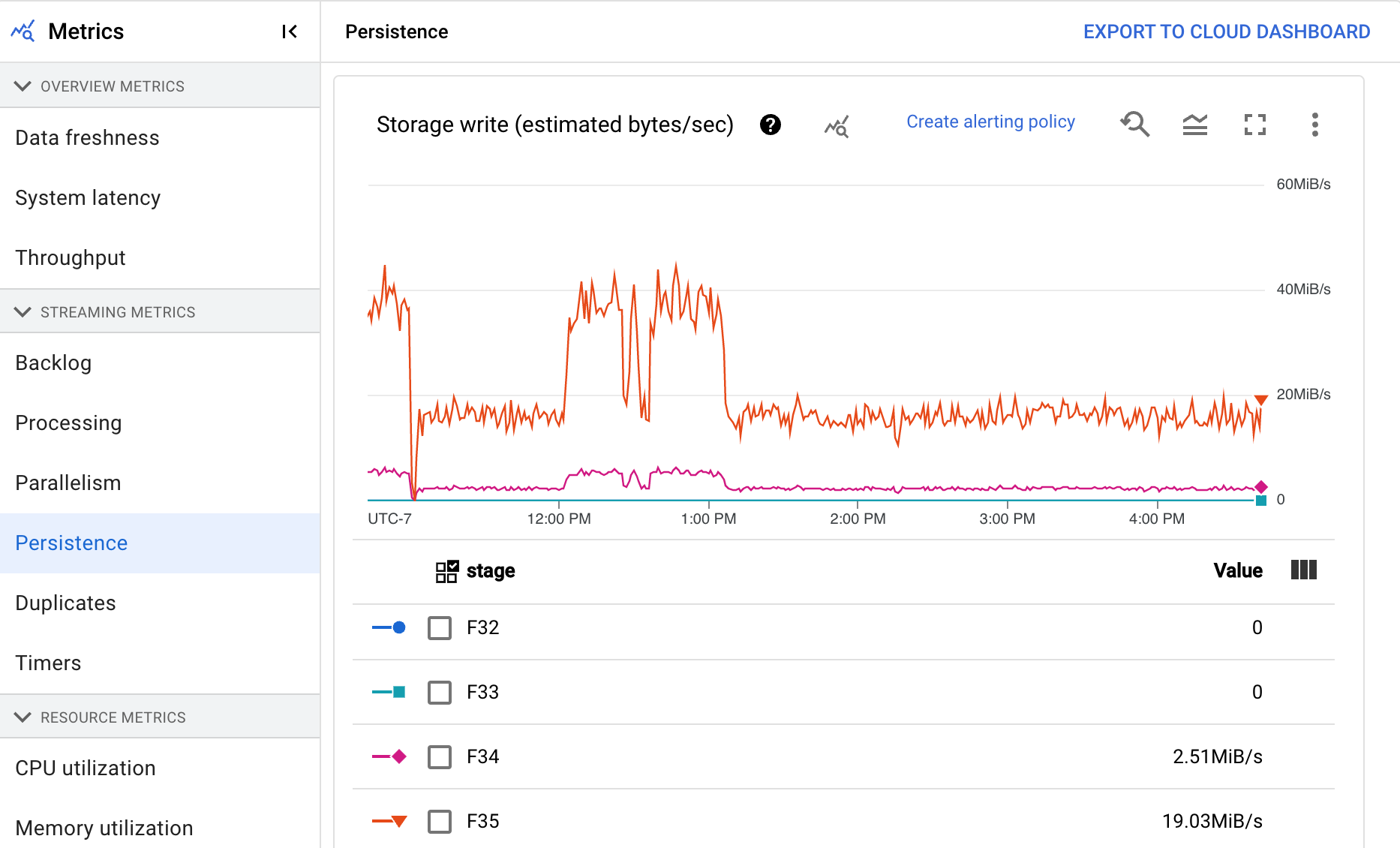
Persistencia
Esta métrica solo se aplica a los trabajos de streaming.
El panel de control Persistencia proporciona información sobre la velocidad a la que una fase concreta de la canalización escribe y lee el almacenamiento persistente en bytes por segundo. Los bytes leídos y escritos incluyen operaciones de estado de usuario y estado de mezclas persistentes, eliminación de duplicados, entradas secundarias y seguimiento de marcas de agua. Los codificadores de la canalización y el almacenamiento en caché afectan a los bytes leídos y escritos. Los bytes de almacenamiento pueden ser distintos de los bytes procesados debido al uso del almacenamiento interno y al almacenamiento en caché.
El panel de control incluye los dos gráficos siguientes:
- Escritura de almacenamiento
- Lectura de almacenamiento
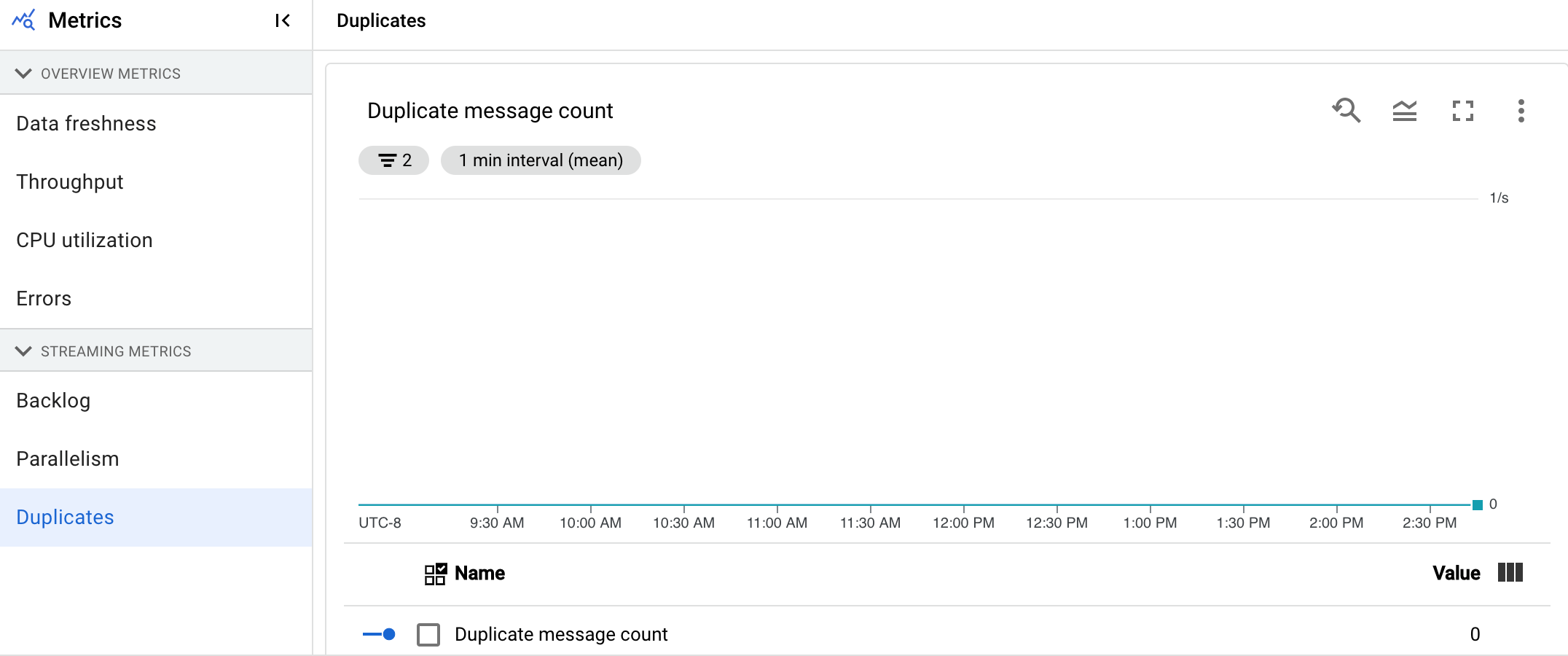
Duplicados
Esta métrica solo se aplica a los trabajos de streaming.
El gráfico Duplicados muestra el número de mensajes que se han filtrado como duplicados y que están siendo procesados por una fase concreta.
Dataflow admite muchas fuentes y receptores que garantizan la entrega at least once. El inconveniente de la entrega de at least once es que puede dar lugar a duplicados.
Dataflow garantiza la exactly once entrega, lo que significa que los duplicados se filtran automáticamente.
Las fases posteriores no tienen que volver a procesar los mismos elementos, lo que asegura que el estado y los resultados no se vean afectados.
El flujo de trabajo se puede optimizar para los recursos y el rendimiento reduciendo el número de duplicados que se producen en cada fase.
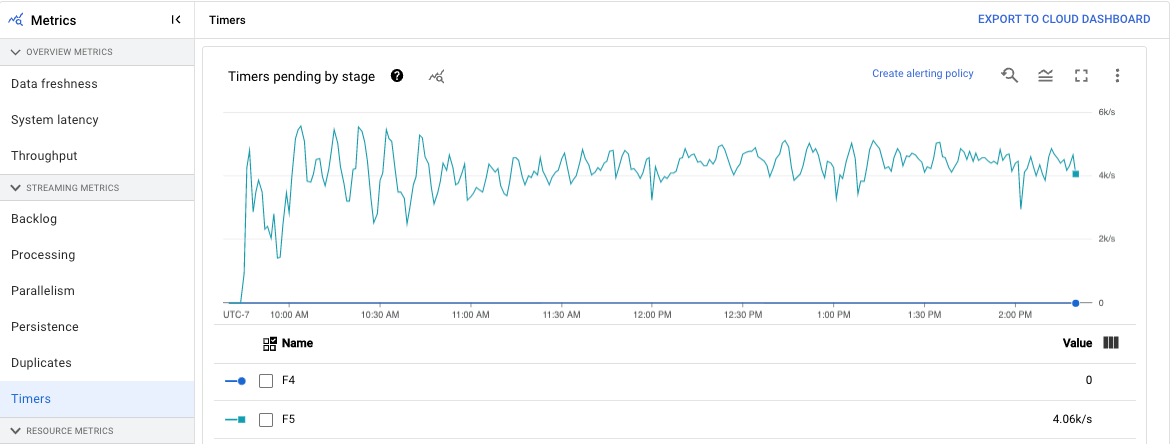
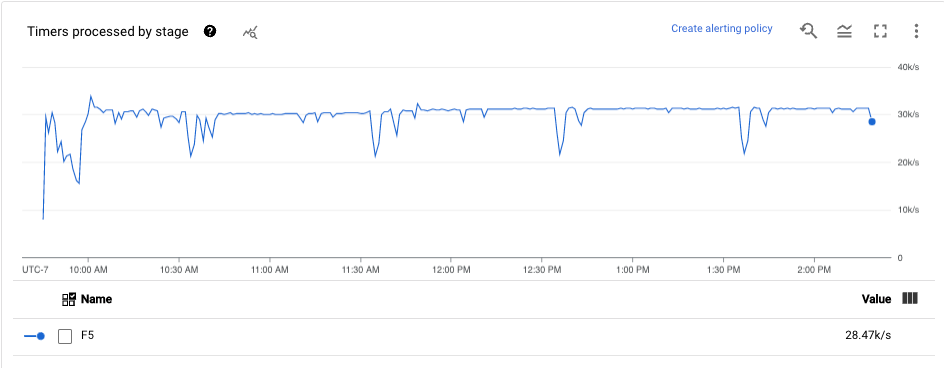
Temporizadores
Esta métrica solo se aplica a los trabajos de streaming.
El panel de control Temporizadores proporciona información sobre el número de temporizadores pendientes y el número de temporizadores que ya se han procesado en una fase concreta de la canalización. Como las ventanas dependen de los temporizadores, esta métrica le permite monitorizar el progreso de las ventanas.
El panel de control incluye los dos gráficos siguientes:
- Temporizadores pendientes por fase
- Procesamiento de temporizadores por fase
En estos gráficos se muestra el ritmo al que las ventanas están pendientes o en proceso en un momento concreto. El gráfico Temporizadores pendientes por fase indica cuántas ventanas se retrasan debido a cuellos de botella. El gráfico Temporizadores procesados por fase indica cuántas ventanas están recogiendo elementos.
En estos gráficos se muestran todos los temporizadores de tareas, por lo que, si se usan temporizadores en otras partes del código, también aparecerán en estos gráficos.
Métricas de recursos
Las siguientes métricas se encuentran en Métricas de recursos.
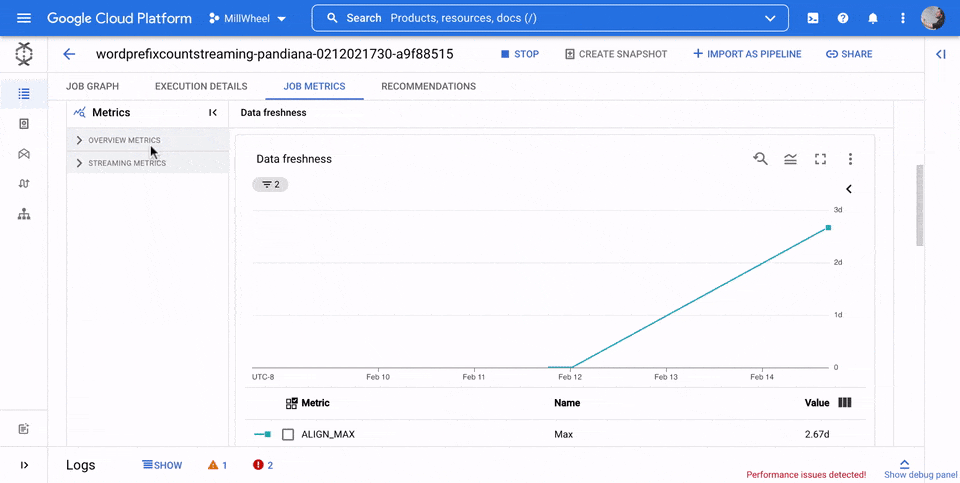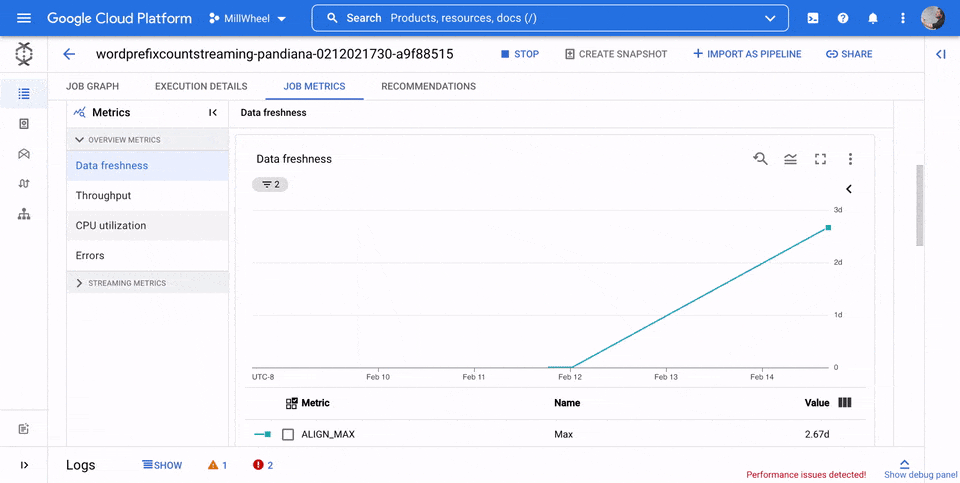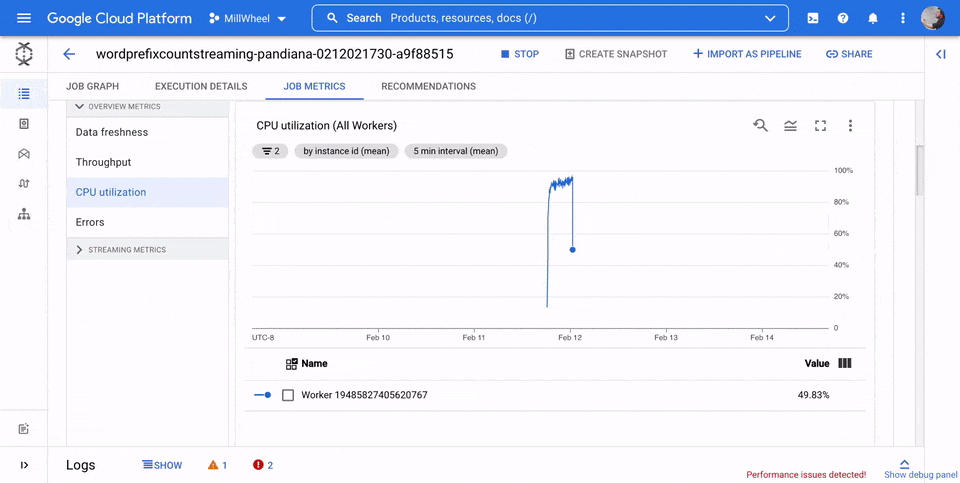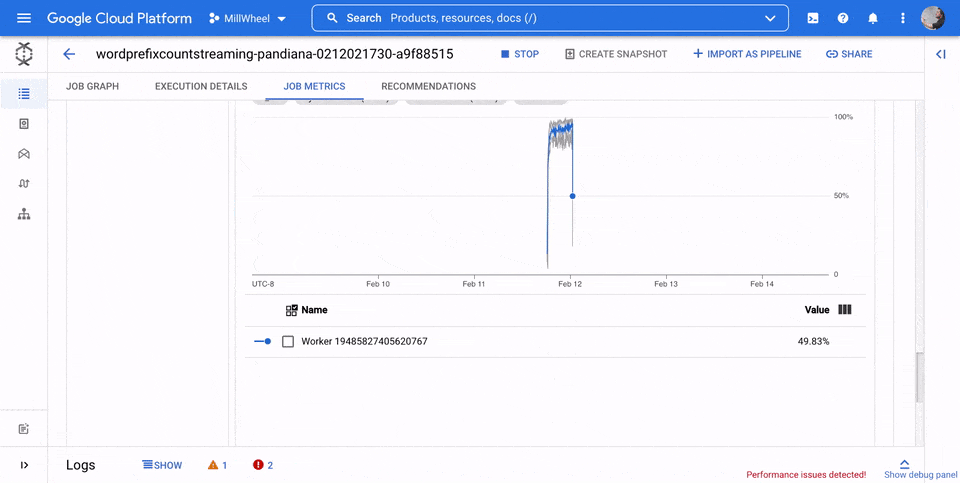
Uso de CPU
El uso de la CPU es la cantidad de CPU utilizada dividida por la cantidad de CPU disponible para el procesamiento. Esta métrica por trabajador se muestra como un porcentaje. El panel de control incluye los cuatro gráficos siguientes:
- Uso de CPU (todos los trabajadores)
- Estadísticas del uso de CPU
- Las 4 tareas con un mayor uso de CPU
- Uso de CPU (4 últimas tareas)
Uso de memoria
La utilización de memoria es la cantidad estimada de memoria utilizada por los trabajadores en bytes por segundo. El panel de control incluye los dos gráficos siguientes:
- Uso máximo de memoria de los trabajadores (bytes estimados por segundo)
- Utilización de memoria (bytes por segundo estimados)
El gráfico Uso máximo de la memoria de los trabajadores proporciona información sobre los trabajadores que usan más memoria en la tarea de Dataflow en cada momento. Si, en diferentes puntos de una tarea, cambia el trabajador que usa la cantidad máxima de memoria, la misma línea del gráfico muestra datos de varios trabajadores. Cada punto de datos de la línea muestra los datos del trabajador que utiliza la cantidad máxima de memoria en ese momento. El gráfico compara la memoria estimada que usa el trabajador con el límite de memoria en bytes.
Puedes usar este gráfico para solucionar problemas de falta de memoria. Los fallos por falta de memoria de los trabajadores no se muestran en este gráfico.
El gráfico Uso de memoria muestra una estimación de la memoria que usan todos los trabajadores de la tarea de Dataflow en comparación con el límite de memoria en bytes.
Métricas de entrada y salida
Si tu tarea de Dataflow de streaming lee o escribe registros mediante Pub/Sub, la pestaña Métricas de la tarea muestra métricas de lecturas o escrituras de Pub/Sub.
Todas las métricas de entrada del mismo tipo se combinan, al igual que todas las métricas de salida. Por ejemplo, todas las métricas de Pub/Sub se agrupan en una sección. Cada tipo de métrica se organiza en una sección independiente. Para cambiar las métricas que se muestran, seleccione la sección de la izquierda que mejor represente las métricas que busca. En las siguientes imágenes se muestran todas las secciones disponibles.
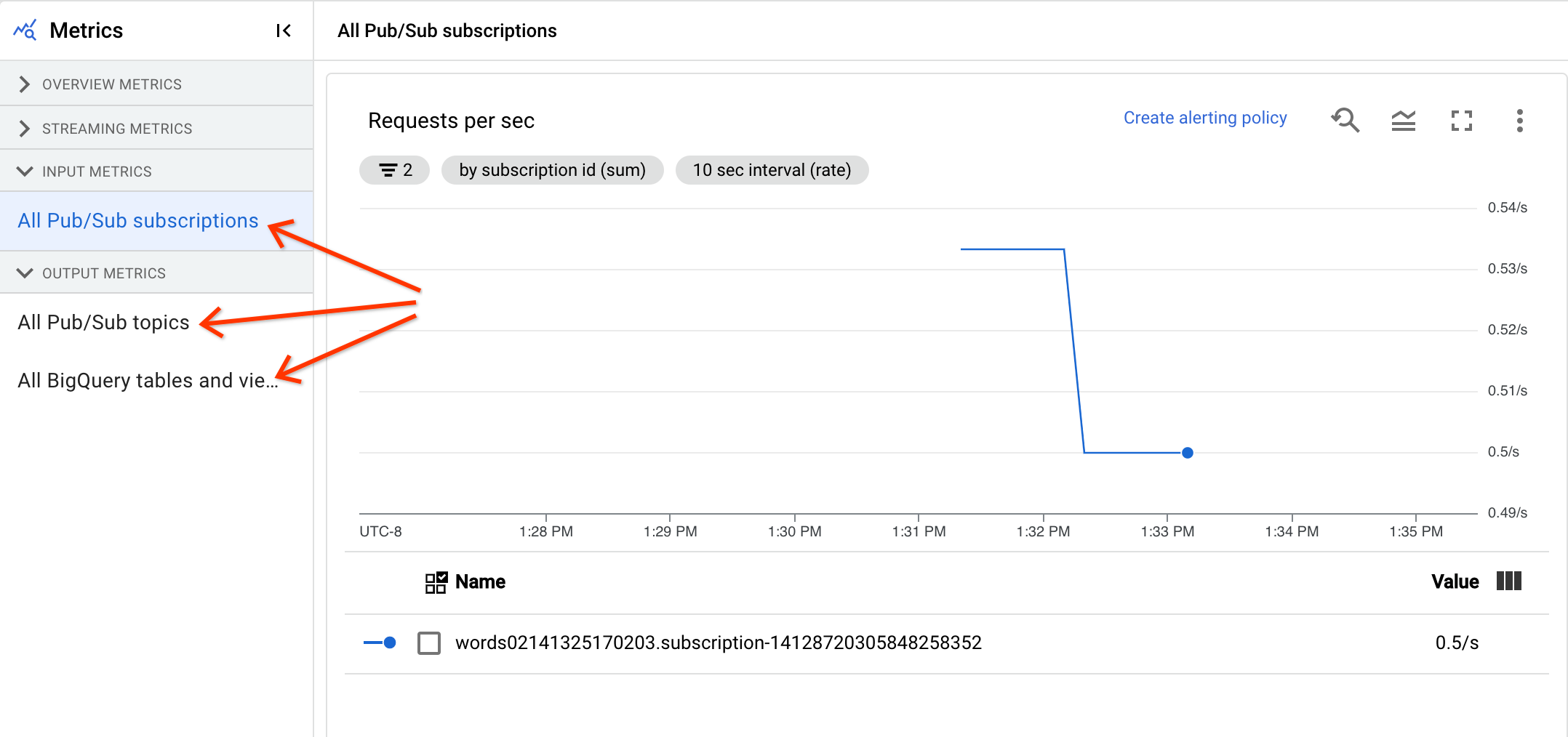
Los dos gráficos siguientes se muestran en las secciones Métricas de entrada y Métricas de salida.
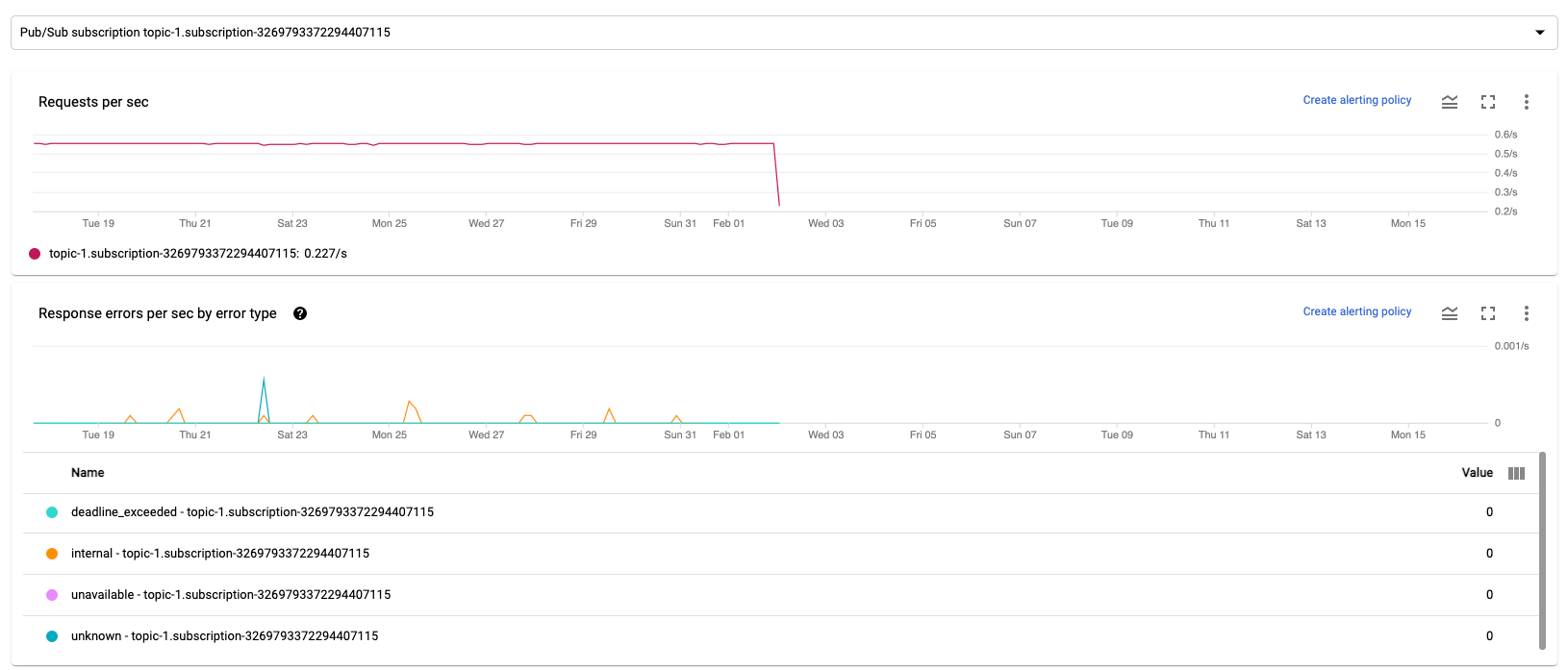
Solicitudes por segundo
Solicitudes por segundo es la frecuencia de solicitudes de la API para leer o escribir datos por la fuente o el receptor a lo largo del tiempo. Si esta tasa se reduce a cero o disminuye significativamente durante un periodo prolongado en comparación con el comportamiento esperado, es posible que la canalización no pueda realizar determinadas operaciones. Además, puede que no haya datos que leer. En ese caso, revisa los pasos del trabajo que tengan una marca de agua del sistema alta. Además, consulta los registros de los trabajadores para ver si hay errores o indicios de que el procesamiento es lento.

Errores de respuesta por segundo por tipo de error
Errores de respuesta por segundo por tipo de error es la tasa de solicitudes de API fallidas para leer o escribir datos por la fuente o el receptor a lo largo del tiempo. Si estos errores se producen con frecuencia, es posible que las solicitudes a la API ralenticen el procesamiento. Estas solicitudes a API erróneas deben investigarse. Para solucionar estos problemas, consulta los códigos de error de entrada y salida generales. También debes consultar la documentación de los códigos de error específicos que utilice la fuente o el receptor, como los códigos de error de Pub/Sub.

Para obtener más información sobre los casos en los que puedes usar estas métricas para depurar, consulta Herramientas de depuración en "Solucionar problemas de trabajos lentos o bloqueados".
Usa Cloud Monitoring
Dataflow está totalmente integrado con Cloud Monitoring. Usa Cloud Monitoring para las siguientes tareas:
- Crea alertas cuando tu trabajo supere un umbral definido por el usuario.
- Use Explorador de métricas para crear consultas y ajustar el periodo de las métricas.
- Ver métricas que no aparecen en la interfaz de monitorización de Dataflow.
Para obtener instrucciones sobre cómo crear alertas y usar el explorador de métricas, consulta el artículo Usar Cloud Monitoring en canalizaciones de Dataflow.
Para ver la lista completa de métricas de Dataflow, consulta la documentación de métricas de Google Cloud Platform.
Crear alertas de Cloud Monitoring
Cloud Monitoring te permite crear alertas cuando tu trabajo de Dataflow supera un umbral definido por el usuario. Para crear una alerta de Cloud Monitoring a partir de un gráfico de métricas, haz clic en Crear política de alertas.
Si no puedes ver los gráficos de monitorización ni crear alertas, es posible que necesites permisos de monitorización adicionales.
Ver en explorador de métricas
Puede ver los gráficos de métricas de Dataflow en Explorador de métricas, donde puede crear consultas y ajustar el periodo de las métricas.
Para ver los gráficos de Dataflow en el explorador de métricas, en la vista Métricas de trabajo, abra Más opciones de gráfico y haga clic en Ver en el explorador de métricas.
Cuando ajustas el periodo de las métricas, puedes seleccionar una duración predefinida o un intervalo de tiempo personalizado para analizar tu trabajo.
De forma predeterminada, en las tareas de streaming y en las tareas por lotes en curso, se muestran las métricas de las seis horas anteriores de esa tarea. En el caso de los trabajos de streaming detenidos o completados, la pantalla predeterminada muestra todo el tiempo de ejecución del trabajo.
Métricas de E/de Dataflow
Puede ver las siguientes métricas de E/S de Dataflow en el explorador de métricas:
job/pubsub/write_count: solicitudes de publicación de Pub/Sub de PubsubIO.Write en trabajos de Dataflow.job/pubsub/read_count: solicitudes de extracción de Pub/Sub de PubsubIO.Read en trabajos de Dataflow.job/bigquery/write_count: solicitudes de publicación de BigQuery de BigQueryIO.Write en trabajos de Dataflow. Las métricasjob/bigquery/write_countestán disponibles en las canalizaciones de Python que usan la transformación WriteToBigQuery conmethod='STREAMING_INSERTS'habilitado en Apache Beam v2.28.0 o versiones posteriores. Esta métrica está disponible tanto para las canalizaciones por lotes como para las de streaming.- Si tu canalización usa una fuente o un receptor de BigQuery, para solucionar problemas de cuota, usa las métricas de la API Storage de BigQuery.
Métricas de DoFn
En las tareas de streaming que usan Streaming Engine y no usan Runner v2, puede ver las siguientes métricas de los DoFns definidos por el usuario:
job/dofn_latency_average: Tiempo medio de procesamiento de mensajes de un soloDoFnen los últimos 3 minutos, en milisegundos.job/dofn_latency_max: Tiempo máximo de procesamiento de mensajes de un soloDoFnen los últimos 3 minutos, en milisegundos.job/dofn_latency_min: Tiempo mínimo de procesamiento de mensajes de un soloDoFnen los últimos 3 minutos, en milisegundos.job/dofn_latency_num_messages: Número de mensajes procesados por un soloDoFnen los últimos 3 minutos.job/dofn_latency_total: Tiempo total de procesamiento de todos los mensajes de un soloDoFnen los últimos 3 minutos, en milisegundos.job/oldest_active_message_age: Tiempo que lleva procesándose el mensaje activo más antiguo en unDoFn, en milisegundos.
Para usar estas métricas, se necesita la versión 2.53.0 o una posterior del SDK de Apache Beam. Para ver estas métricas, usa el explorador de métricas.
Puedes usar estas métricas para saber qué DoFns contribuyen más a la latencia de procesamiento de tus tareas. Por ejemplo, si un trabajo se bloquea, usa la métrica job/oldest_active_message_age para encontrar el DoFn con el mensaje activo más antiguo. En la siguiente imagen se muestra un DoFn con un pico importante en esta métrica:
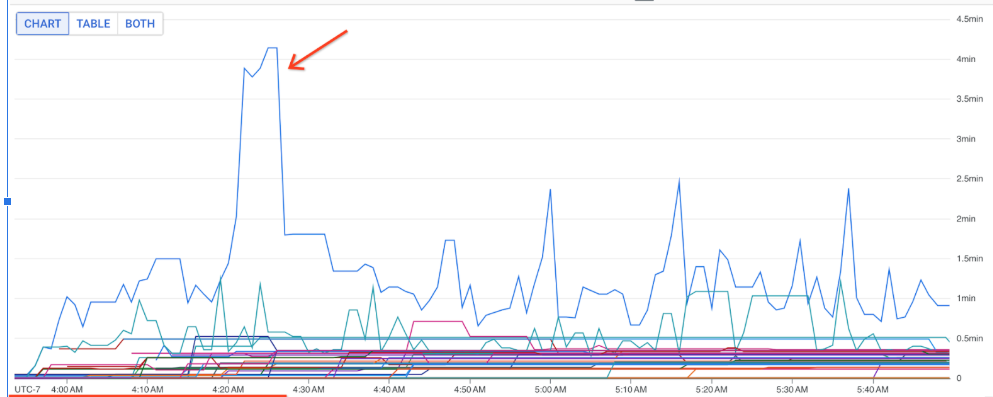
Para ver el nombre del DoFn, coloca el puntero sobre la línea del gráfico.
Siguientes pasos
- Soluciona problemas con trabajos de streaming lentos o bloqueados.
- Solucionar problemas con trabajos por lotes lentos o bloqueados
- Ajustar el autoescalado horizontal de las canalizaciones de streaming
- Optimizar costes