Si tienes problemas con una canalización o un trabajo de Dataflow, en esta página se enumeran los mensajes de error que pueden aparecer y se proporcionan sugerencias para corregir cada error.
Los errores en los tipos de registros dataflow.googleapis.com/worker-startup, dataflow.googleapis.com/harness-startup y dataflow.googleapis.com/kubelet indican problemas de configuración con un trabajo. También pueden indicar condiciones que evitan que la ruta de registro normal funcione.
Tu canalización puede arrojar excepciones durante el procesamiento de datos. Algunos de estos errores son transitorios, por ejemplo, cuando se produce una dificultad temporal para acceder a un servicio externo. Algunos de estos errores son permanentes, como los errores causados por datos de entrada corruptos o no analizables, o punteros nulos durante el procesamiento.
Dataflow procesa los elementos en paquetes arbitrarios y vuelve a probar el paquete completo cuando se arroja un error de cualquier elemento de ese paquete. Cuando se ejecutan en modo por lotes, los paquetes que incluyen un artículo defectuoso se reintentan cuatro veces. Si un paquete individual falla cuatro veces, la canalización fallará por completo. Cuando se ejecuta en modo de transmisión, un paquete que incluye un elemento defectuoso se reintenta de forma indefinida, lo que puede hacer que la canalización se estanque de forma permanente.
Las excepciones en el código del usuario, por ejemplo, tus instancias de DoFn, se informan en la interfaz de supervisión de Dataflow.
Si ejecutas tu canalización con BlockingDataflowPipelineRunner, también verás que se muestran mensajes de error en tu ventana de terminal o consola.
Se recomienda que agregue controladores de excepciones para protegerse contra los errores del código. Por ejemplo, si deseas descartar elementos que producen fallas en una validación de entrada personalizada en ParDo, usa un bloque try/catch dentro de tu ParDo para manejar la excepción y registrar y descartar el elemento. Para las cargas de trabajo de producción, implementa un patrón de mensajes sin procesar. Para realizar un seguimiento del recuento de errores, debes usar transformaciones de agregación.
Archivos de registro faltantes
Si no ves ningún registro para tus trabajos, quita los filtros de exclusión que contengan resource.type="dataflow_step" de todos tus receptores del enrutador de registros de Cloud Logging.
Para obtener más detalles sobre cómo quitar las exclusiones de registros, consulta la guía Quita exclusiones.
Duplicados en los resultados
Cuando ejecutas un trabajo de Dataflow, el resultado contiene registros duplicados.
Este problema puede ocurrir cuando tu trabajo de Dataflow usa el modo de transmisión de canalización al menos una vez. Este modo garantiza que los registros se procesen al menos una vez. Sin embargo, es posible que se dupliquen los registros con este modo.
Si tu flujo de trabajo no puede tolerar registros duplicados, usa el modo de transmisión “exactamente una vez”. Este modo ayuda a garantizar que los registros no se descarten ni se dupliquen a medida que los datos se mueven a través de la canalización.
Para verificar qué modo de transmisión usa tu trabajo, consulta Visualiza el modo de transmisión de un trabajo.
Para obtener más información sobre los modos de transmisión, consulta Configura el modo de transmisión de la canalización.
Errores de canalización
Las siguientes secciones contienen errores de canalización comunes que puedes encontrar y los pasos para resolver o solucionar problemas de errores.
Algunas API de Cloud deben estar habilitadas
Cuando intentas ejecutar un trabajo de Dataflow, se produce el siguiente error:
Some Cloud APIs need to be enabled for your project in order for Cloud Dataflow to run this job.
Este problema se produce porque algunas API obligatorias no están habilitadas en tu proyecto.
Para resolver este problema y ejecutar un trabajo de Dataflow, habilita las siguientes APIs en tu proyecto:Google Cloud
- API de Compute Engine (Compute Engine)
- API de Cloud Logging
- Cloud Storage
- API de Cloud Storage JSON
- API de BigQuery
- Pub/Sub
- API de Datastore
Para obtener instrucciones detalladas, consulta la sección Comienza a habilitar las APIs de Google Cloud .
"@*" y "@N" son especificaciones de fragmentación reservadas
Cuando intentas ejecutar un trabajo, aparece el siguiente error en los archivos de registro y el trabajo falla:
Workflow failed. Causes: "@*" and "@N" are reserved sharding specs. Filepattern must not contain any of them.
Este error se produce si el nombre de archivo de la ruta de Cloud Storage para los archivos temporales (tempLocation o temp_location) tiene un signo arroba (@) seguido de un número o un asterisco (*).
Para resolver este problema, cambia el nombre del archivo de modo que el signo arroba esté seguido de un carácter admitido.
Solicitud incorrecta
Cuando ejecutas un trabajo de Dataflow, los registros de Cloud Monitoring muestran una serie de advertencias similares a las siguientes:
Unable to update setup work item STEP_ID error: generic::invalid_argument: Http(400) Bad Request
Update range task returned 'invalid argument'. Assuming lost lease for work with id LEASE_ID
with expiration time: TIMESTAMP, now: TIMESTAMP. Full status: generic::invalid_argument: Http(400) Bad Request
Las advertencias de solicitud incorrecta se producen si la información del estado del trabajador está inactiva o no está sincronizada debido a retrasos de procesamiento. A menudo, tu trabajo de Dataflow tiene éxito a pesar de las advertencias de solicitud incorrecta. Si ese es el caso, ignora las advertencias.
No es posible leer y escribir en ubicaciones diferentes
Cuando ejecutas un trabajo de Dataflow, es posible que veas el siguiente error en los archivos de registro:
message:Cannot read and write in different locations: source: SOURCE_REGION, destination: DESTINATION_REGION,reason:invalid
Este error ocurre cuando el origen y el destino están en regiones diferentes. También puede ocurrir cuando la ubicación y el destino de la etapa de pruebas se encuentran en diferentes regiones. Por ejemplo, si el trabajo lee de Pub/Sub y, luego, escribe en un bucket temp de Cloud Storage antes de escribir en una tabla de BigQuery, el bucket de Cloud Storage temp y la tabla de BigQuery deben estar en la misma región.
Las ubicaciones multirregionales se consideran diferentes de las ubicaciones de una sola región, incluso si la única región está dentro del alcance de la ubicación multirregional.
Por ejemplo, us (multiple regions in the United States) y us-central1 son regiones diferentes.
Para resolver este problema, ten tus ubicaciones de destino, origen y etapa de pruebas en la misma región. Las ubicaciones de los buckets de Cloud Storage no se pueden cambiar, por lo que es posible que debas crear un bucket de Cloud Storage nuevo en la región correcta.
Se ha superado el tiempo de espera de conexión.
Cuando ejecutas un trabajo de Dataflow, es posible que veas el siguiente error en los archivos de registro:
org.springframework.web.client.ResourceAccessException: I/O error on GET request for CONNECTION_PATH: Connection timed out (Connection timed out); nested exception is java.net.ConnectException: Connection timed out (Connection timed out)
Este problema se produce cuando los trabajadores de Dataflow no pueden establecer ni mantener una conexión con la fuente de datos o el destino.
Para resolver este problema, sigue estos pasos:
- Verifica que la fuente de datos se esté ejecutando.
- Verifica que el destino esté en ejecución.
- Revisa los parámetros de conexión que se usan en la configuración de la canalización de Dataflow.
- Verifica que los problemas de rendimiento no afecten a la fuente ni el destino.
- Asegúrate de que las reglas de firewall no bloqueen la conexión.
No existe el objeto
Cuando ejecutas tus trabajos de Dataflow, es posible que veas el siguiente error en los archivos de registro:
..., 'server': 'UploadServer', 'status': '404'}>, <content <No such object:...
Estos errores suelen ocurrir cuando algunos de tus trabajos de Dataflow en ejecución usan la misma temp_location para almacenar en etapa intermedia los archivos de trabajo temporales creados cuando se ejecuta la canalización. Cuando varios trabajos simultáneos comparten la misma temp_location, estos trabajos pueden tener pasos en los datos temporales entre sí, y puede ocurrir una condición de carrera. A fin de evitar este problema, se recomienda usar una temp_location única para cada trabajo.
Dataflow no puede determinar el trabajo pendiente
Cuando se ejecuta una canalización de transmisión desde Pub/Sub, se produce la siguiente advertencia:
Dataflow is unable to determine the backlog for Pub/Sub subscription
Cuando una canalización de Dataflow extrae datos de Pub/Sub, Dataflow necesita solicitar información de Pub/Sub de forma repetida. Esta información incluye la cantidad de tareas pendientes en la suscripción y la antigüedad del mensaje no confirmado más antiguo. En ocasiones, Dataflow no puede recuperar esta información de Pub/Sub debido a problemas internos del sistema, lo que puede causar una acumulación transitoria de tareas pendientes.
Para obtener más información, consulta Transmite con Cloud Pub/Sub.
DEADLINE_EXCEEDED o El servidor no responde
Cuando ejecutas tus trabajos, puedes encontrar excepciones de tiempo de espera de RPC o uno de los siguientes errores:
DEADLINE_EXCEEDED
O:
Server Unresponsive
Por lo general, estos errores ocurren por uno de los siguientes motivos:
The Virtual Private Cloud (VPC) network used for your job might be missing a firewall rule. The firewall rule needs to enable all TCP traffic among VMs in the VPC network you specified in your pipeline options. For more information, see Firewall rules for Dataflow.
En algunos casos, los trabajadores no pueden comunicarse entre sí. Cuando ejecutas un trabajo de Dataflow que no usa Dataflow Shuffle o Streaming Engine, los trabajadores deben comunicarse entre sí mediante los puertos TCP
12345y12346dentro de la red de VPC. En esta situación, el error incluye el nombre del agente de trabajo y el puerto TCP que está bloqueado. El error se parecerá a uno de los siguientes ejemplos:DEADLINE_EXCEEDED: (g)RPC timed out when SOURCE_WORKER_HARNESS talking to DESTINATION_WORKER_HARNESS:12346.Rpc to WORKER_HARNESS:12345 completed with error UNAVAILABLE: failed to connect to all addresses Server unresponsive (ping error: Deadline Exceeded, UNKNOWN: Deadline Exceeded...)Para resolver este problema, usa la marca reglas
gcloud compute firewall-rules createpara permitir el tráfico de red a los puertos12345y12346. En el siguiente ejemplo, se muestra el comando de Google Cloud CLI:gcloud compute firewall-rules create FIREWALL_RULE_NAME \ --network NETWORK \ --action allow \ --direction IN \ --target-tags dataflow \ --source-tags dataflow \ --priority 0 \ --rules tcp:12345-12346Reemplaza lo siguiente:
FIREWALL_RULE_NAME: Es el nombre de tu regla de firewall.NETWORK: el nombre de tu red
Tu trabajo se delimita aleatoriamente.
Para resolver este problema, realiza uno o más de los siguientes cambios.
Java
- Si el trabajo no usa un objeto Shuffle basado en servicios, cambia para usar Dataflow Shuffle basado en servicios mediante la configuración de
--experiments=shuffle_mode=service. Para obtener detalles y disponibilidad, consulta Dataflow Shuffle. - Agrega más trabajadores. Prueba configurar
--numWorkerscon un valor mayor cuando ejecutes tu canalización. - Aumenta el tamaño del disco conectado para los trabajadores. Prueba configurar
--diskSizeGbcon un valor mayor cuando ejecutes tu canalización. - Usa un disco persistente respaldado por SSD. Prueba configurar
--workerDiskType="compute.googleapis.com/projects/PROJECT_ID/zones/ZONE/diskTypes/pd-ssd"cuando ejecutes tu canalización.
Python
- Si el trabajo no usa un objeto Shuffle basado en servicios, cambia para usar Dataflow Shuffle basado en servicios mediante la configuración de
--experiments=shuffle_mode=service. Para obtener detalles y disponibilidad, consulta Dataflow Shuffle. - Agrega más trabajadores. Prueba configurar
--num_workerscon un valor mayor cuando ejecutes tu canalización. - Aumenta el tamaño del disco conectado para los trabajadores. Prueba configurar
--disk_size_gbcon un valor mayor cuando ejecutes tu canalización. - Usa un disco persistente respaldado por SSD. Prueba configurar
--worker_disk_type="compute.googleapis.com/projects/PROJECT_ID/zones/ZONE/diskTypes/pd-ssd"cuando ejecutes tu canalización.
Go
- Si el trabajo no usa un objeto Shuffle basado en servicios, cambia para usar Dataflow Shuffle basado en servicios mediante la configuración de
--experiments=shuffle_mode=service. Para obtener detalles y disponibilidad, consulta Dataflow Shuffle. - Agrega más trabajadores. Prueba configurar
--num_workerscon un valor mayor cuando ejecutes tu canalización. - Aumenta el tamaño del disco conectado para los trabajadores. Prueba configurar
--disk_size_gbcon un valor mayor cuando ejecutes tu canalización. - Usa un disco persistente respaldado por SSD. Prueba configurar
--disk_type="compute.googleapis.com/projects/PROJECT_ID/zones/ZONE/diskTypes/pd-ssd"cuando ejecutes tu canalización.
- Si el trabajo no usa un objeto Shuffle basado en servicios, cambia para usar Dataflow Shuffle basado en servicios mediante la configuración de
Errores de codificación, IOExceptions o un comportamiento inesperado en el código de usuario.
Los SDK de Apache Beam y los trabajadores de Dataflow dependen de componentes comunes de terceros. Estos componentes importan dependencias adicionales. Los conflictos de versiones pueden causar que el servicio se comporte de manera inesperada. Además, algunas bibliotecas no son compatibles con versiones futuras. Es posible que necesites fijar las versiones anteriores que se encuentran dentro del alcance durante la ejecución. SDK y dependencias de trabajadores contiene una lista de dependencias y sus versiones obligatorias.
Se produjo un error mientras se ejecutaba LookupEffectiveGuestPolicies
Cuando ejecutas un trabajo de Dataflow, es posible que veas el siguiente error en los archivos de registro:
OSConfigAgent Error policies.go:49: Error running LookupEffectiveGuestPolicies:
error calling LookupEffectiveGuestPolicies: code: "Unauthenticated",
message: "Request is missing required authentication credential.
Expected OAuth 2 access token, login cookie or other valid authentication credential.
Este error se produce si la Administración de configuración del SO está habilitada para todo el proyecto.
Para resolver este problema, inhabilita las políticas de VM Manager que se aplican a todo el proyecto. Si no es posible inhabilitar las políticas de VM Manager para todo el proyecto, puedes ignorar este error y filtrarlo en las herramientas de supervisión de registros.
Java Runtime Environment detectó un error irrecuperable.
El siguiente error ocurre durante el inicio de un trabajador:
A fatal error has been detected by the Java Runtime Environment
Este error se produce si la canalización usa la interfaz nativa de Java (JNI) para ejecutar código que no es de Java y ese código o las vinculaciones de JNI contienen un error.
Error en la clave del atributo googclient_deliveryattempt
Tu trabajo de Dataflow falla con uno de los siguientes errores:
The request contains an attribute key that is not valid (key=googclient_deliveryattempt). Attribute keys must be non-empty and must not begin with 'goog' (case-insensitive).
O:
Invalid extensions name: googclient_deliveryattempt
Este error ocurre cuando tu trabajo de Dataflow tiene las siguientes características:
- El trabajo de Dataflow usa Streaming Engine.
- La canalización tiene un receptor de Pub/Sub.
- The pipeline uses a pull subscription.
- La canalización usa una de las APIs del servicio de Pub/Sub para publicar mensajes en lugar de usar el receptor de E/S de Pub/Sub integrado.
- Pub/Sub usa la biblioteca cliente de Java o C#.
- La suscripción a Pub/Sub tiene un tema de mensajes no entregados.
Este error se produce porque cuando usas la biblioteca cliente de Java o C# de Pub/Sub y se habilita un tema de mensajes no entregados para una suscripción, los intentos de entrega se encuentran en el atributo de mensaje googclient_deliveryattempt en lugar del campo delivery_attempt. Para obtener más información, consulta Cómo hacer un seguimiento de los intentos de entrega en la página "Cómo controlar las fallas de los mensajes".
Para resolver este problema, realiza uno o más de los siguientes cambios.
- Inhabilita Streaming Engine.
- Usa el conector
PubSubIOde Apache Beam integrado en lugar de la API de servicio de Pub/Sub. - Usa un tipo diferente de suscripción a Pub/Sub.
- Quita el tema de mensajes no entregados.
- Don't use the Java or C# client library with your Pub/Sub pull subscription. For other options, see Client library code samples.
- En el código de tu canalización, cuando las claves de atributos comiencen con
goog, borra los atributos del mensaje antes de publicar los mensajes.
Se detectó una clave de acceso rápido ...
Se produce el siguiente error:
A hot key HOT_KEY_NAME was detected in...
Estos errores se producen si tus datos contienen una clave de acceso rápido. Una clave de acceso rápido es una clave con suficientes elementos para impactar negativamente en el rendimiento de la canalización. Estas claves limitan la capacidad de Dataflow de procesar elementos en paralelo, lo que aumenta el tiempo de ejecución.
Para imprimir la clave legible en los registros cuando se detecta una clave de acceso rápido en la canalización, usa la opción de canalización de clave de acceso rápido.
Para resolver este problema, verifica que tus datos estén distribuidos de manera uniforme. Si una clave tiene muchos valores de forma desproporcionada, considera las siguientes medidas:
- Cambia la clave de tus datos. Aplica una transformación de
ParDopara generar pares clave-valor nuevos. - Para trabajos de Java, usa la transformación de
Combine.PerKey.withHotKeyFanout. - Para trabajos de Python, usa la transformación de
CombinePerKey.with_hot_key_fanout. - Habilita Dataflow Shuffle.
Para ver las teclas de acceso rápido en la interfaz de supervisión de Dataflow, consulta Solución de problemas de demora en trabajos por lotes.
Especificación de tabla no válida en Data Catalog
Cuando usas Dataflow SQL para crear trabajos de Dataflow SQL, es posible que el trabajo falle con el siguiente error en los archivos de registro:
Invalid table specification in Data Catalog: Could not resolve table in Data Catalog
Este error se produce si la cuenta de servicio de Dataflow no tiene acceso a la API de Data Catalog.
Para resolver este problema, habilita la API de Data Catalog en el Google Cloud proyectoque usas para escribir y ejecutar consultas.
Como alternativa, asigna la función roles/datacatalog.viewer a la
cuenta de servicio de Dataflow.
El grafo del trabajo es demasiado grande
Tu trabajo puede fallar con el siguiente error:
The job graph is too large. Please try again with a smaller job graph,
or split your job into two or more smaller jobs.
Este error se produce si el tamaño del grafo de tu trabajo supera los 10 MB. Algunas condiciones en tu canalización pueden provocar que el grafo del trabajo supere el límite. Entre las condiciones comunes, se incluyen las siguientes:
- Una transformación
Createque incluye una gran cantidad de datos en memoria. - Una instancia
DoFnde gran tamaño que se serializa para la transmisión a trabajadores remotos. DoFncomo una instancia de clase interna anónima que (posiblemente de forma involuntaria) incorpora gran cantidad de datos para serializarse.- Un grafo acíclico dirigido (DAG) se usa como parte de un bucle programático que enumera una lista grande.
Para evitar estas condiciones, considera reestructurar tu canalización.
La confirmación de claves es demasiado grande
Cuando ejecutas un trabajo de transmisión, aparece el siguiente error en los archivos de registro del trabajador:
KeyCommitTooLargeException
Este error ocurre en situaciones de transmisión si una gran cantidad de datos se agrupa sin usar una transformación Combine o si se produce una gran cantidad de datos a partir de un solo elemento de entrada.
Para reducir la posibilidad de encontrar este error, usa las siguientes estrategias:
- Asegúrate de que procesar un solo elemento no pueda dar lugar a que las salidas o las modificaciones de estado superen el límite.
- Si se agruparon varios elementos por clave, considera aumentar el espacio de claves para reducir los elementos agrupados por clave.
- Si los elementos de una clave se emiten a una frecuencia alta durante un período corto, es posible que muchos GB de eventos de esa clave se ejecuten en ventanas. Vuelve a escribir la canalización para detectar claves como esta y solo emite un resultado que indique que la clave estaba presente con frecuencia en esa ventana.
- Usa transformaciones
Combinede espacio sublineal para operaciones conmutativas y de asociación. No uses un combinador si no reduce el espacio. Por ejemplo, el combinador para strings que solo agrega strings es peor que no usar el combinador.
Rechazo de mensaje por encima de 7,168,000
Cuando ejecutas un trabajo de Dataflow creado a partir de una plantilla, el trabajo puede fallar con el siguiente error:
Error: CommitWork failed: status: APPLICATION_ERROR(3): Pubsub publish requests are limited to 10MB, rejecting message over 7168K (size MESSAGE_SIZE) to avoid exceeding limit with byte64 request encoding.
Este error ocurre cuando los mensajes escritos en una cola de mensajes no entregados superan el límite de tamaño de 7,168,000. Como solución alternativa, habilita Streaming Engine, que tiene un límite de tamaño más alto. Para habilitar Streaming Engine, usa la siguiente opción de canalización.
Java
--enableStreamingEngine=true
Python
--enable_streaming_engine=true
La entidad de la solicitud es muy grande
Cuando envías tu trabajo, aparece uno de los siguientes errores en tu ventana de terminal o consola:
413 Request Entity Too Large
The size of serialized JSON representation of the pipeline exceeds the allowable limit
Failed to create a workflow job: Invalid JSON payload received
Failed to create a workflow job: Request payload exceeds the allowable limit
Cuando encuentras un error sobre la carga útil de JSON cuando envías tu trabajo, la representación JSON de tu canalización supera el tamaño máximo solicitado de 20 MB.
El tamaño de tu trabajo se relaciona con la representación JSON de la canalización. Una canalización mayor implica una solicitud mayor. Actualmente, Dataflow tiene una limitación de 20 MB para las solicitudes.
Para estimar el tamaño de la solicitud JSON de tu canalización, ejecuta tu canalización con la siguiente opción:
Java
--dataflowJobFile=PATH_TO_OUTPUT_FILE
Python
--dataflow_job_file=PATH_TO_OUTPUT_FILE
Go
En Go, no se admite la salida de tu trabajo como JSON.
Este comando escribe una representación JSON de tu trabajo en un archivo. El tamaño del archivo serializado es una estimación apropiada del tamaño de la solicitud. El tamaño real es un poco mayor debido a que se incluye información adicional en la solicitud.
Algunas condiciones en tu canalización pueden provocar que la representación JSON supere el límite. Entre las condiciones comunes, se incluyen las siguientes:
- Una transformación
Createque incluye una gran cantidad de datos en memoria. - Una instancia
DoFnde gran tamaño que se serializa para la transmisión a trabajadores remotos. DoFncomo una instancia de clase interna anónima que (posiblemente de forma involuntaria) incorpora gran cantidad de datos para serializarse.
Para evitar estas condiciones, considera reestructurar tu canalización.
Las opciones de canalización del SDK o la lista de archivos de etapa de pruebas superan el límite de tamaño
Cuando ejecutas una canalización, se produce uno de los siguientes errores:
SDK pipeline options or staging file list exceeds size limit.
Please keep their length under 256K Bytes each and 512K Bytes in total.
O:
Value for field 'resource.properties.metadata' is too large: maximum size
Estos errores ocurren si no se pudo iniciar la canalización debido a que se superaron los límites de metadatos de Compute Engine. Los límites no se pueden cambiar. Dataflow usa metadatos de Compute Engine para las opciones de canalización. El límite se documenta en las limitaciones de metadatos personalizados de Compute Engine.
Las siguientes situaciones pueden provocar que la representación JSON supere el límite:
- Hay demasiados archivos JAR para habilitar la etapa.
- El campo de solicitud
sdkPipelineOptionses demasiado grande.
Para estimar el tamaño de la solicitud JSON de tu canalización, ejecuta tu canalización con la siguiente opción:
Java
--dataflowJobFile=PATH_TO_OUTPUT_FILE
Python
--dataflow_job_file=PATH_TO_OUTPUT_FILE
Go
En Go, no se admite la salida de tu trabajo como JSON.
El tamaño del archivo de salida de este comando debe ser inferior a 256 KB. Los 512 KB en el mensaje de error se refieren al tamaño total del archivo de salida y a las opciones de metadatos personalizados para la instancia de VM de Compute Engine.
Puedes obtener una estimación aproximada de la opción de metadatos personalizados para la instancia de VM a partir de la ejecución de trabajos de Dataflow en el proyecto. Elige cualquier trabajo de Dataflow en ejecución. Toma una instancia de VM y, luego, navega a la página de detalles de la instancia de VM de Compute Engine para esa VM a fin de verificar la sección de metadatos personalizados. La longitud total de los metadatos personalizados y el archivo debe ser inferior a 512 KB. No es posible hacer una estimación precisa del trabajo con errores, ya que las VMs no se inician para trabajos con errores.
Si tu lista de JAR alcanza el límite de 256 KB, revísala y reduce los archivos JAR innecesarios. Si aún es demasiado grande, intenta ejecutar el trabajo de Dataflow con un uber JAR. Para ver un ejemplo que muestra cómo crear y usar un uber JAR, consulta Compila e implementa un archivo uber JAR.
Si el campo de solicitud sdkPipelineOptions es demasiado grande, incluye la siguiente opción cuando ejecutes tu canalización. La opción de canalización es la misma para Java, Python y Go.
--experiments=no_display_data_on_gce_metadata
La clave Shuffle es demasiado grande
El siguiente error aparece en los archivos de registro del trabajador:
Shuffle key too large
Este error se produce si la clave serializada emitida a un (Co-)GroupByKey específico es demasiado grande después de aplicar el codificador correspondiente. Dataflow tiene un límite para las claves shuffle serializadas.
Para resolver este problema, reduce el tamaño de las claves o usa codificadores que ahorren más espacio.
Para obtener más información, consulta los límites de producción de Dataflow.
La cantidad total de objetos BoundedSource ... es mayor que el límite permitido
Uno de los siguientes errores puede ocurrir cuando ejecutas trabajos con Java:
Total number of BoundedSource objects generated by splitIntoBundles() operation is larger than the allowable limit
O:
Total size of the BoundedSource objects generated by splitIntoBundles() operation is larger than the allowable limit
Java
Este error puede ocurrir si lees a partir de una gran cantidad de archivos mediante TextIO, AvroIO, BigQueryIO a través de EXPORTAR o alguna otra fuente basada en archivos. El límite específico depende de los detalles de tu fuente, pero es de alrededor de decenas de miles de archivos en una canalización. Por ejemplo, el esquema incorporado en AvroIO.Read permite menos archivos.
Este error también puede ocurrir si creaste una fuente de datos personalizada para tu canalización y el método splitIntoBundles de tu fuente mostró una lista de objetos BoundedSource que necesita más de 20 MB cuando se serializa.
El límite permitido para el tamaño total de los objetos BoundedSource generados por la operación splitIntoBundles() de tu fuente personalizada es de 20 MB.
Para evitar esta limitación, realiza uno de los siguientes cambios:
Habilita Runner V2. Runner v2 convierte las fuentes en DoFn divisibles que no tienen este límite de división de origen.
Modifica tu subclase
BoundedSourcepersonalizada para que el tamaño total de los objetosBoundedSourcegenerados sea menor que el límite de 20 MB. Por ejemplo, en un principio, tu fuente puede generar menos divisiones y usar un Rebalanceo dinámico del trabajo para seguir dividiendo entradas a pedido.
NameError
Cuando ejecutas tu canalización con el servicio de Dataflow, se produce el siguiente error:
NameError
Este error no se produce cuando ejecutas de forma local, como cuando ejecutas con DirectRunner.
Este error se produce si los objetos DoFn usan valores en el espacio de nombres global que no están disponibles en el trabajador de Dataflow.
Las importaciones globales, las funciones y las variables definidas en la sesión principal no se guardan durante la serialización de un trabajo de Dataflow de forma predeterminada.
Para resolver este problema, usa uno de los siguientes métodos. Si tus DoFn se definen en el archivo principal y hacen referencias a importaciones y funciones del espacio de nombres global, establece la opción de canalización --save_main_session en True. Este cambio selecciona el estado del espacio de nombres global y lo carga en el trabajador de Dataflow.
Si tienes objetos en tu espacio de nombres global que no pueden serializarse, se produce un error de serialización. Si el error está relacionado con un módulo que debería estar disponible en la distribución de Python, importa el módulo localmente, que es el lugar en que se usa.
Por ejemplo, en lugar de hacer lo siguiente:
import re … def myfunc(): # use re module
utiliza esto:
def myfunc(): import re # use re module
De manera alternativa, si tus DoFn abarcan varios archivos, debes usar un enfoque diferente para empaquetar el flujo de trabajo y administrar las dependencias.
El objeto está sujeto a la política de retención del bucket
Cuando tienes un trabajo de Dataflow que escribe en un bucket de Cloud Storage, el trabajo falla con el siguiente error:
Object 'OBJECT_NAME' is subject to bucket's retention policy or object retention and cannot be deleted or overwritten
Es posible que también veas el siguiente error:
Unable to rename "gs://BUCKET"
El primer error ocurre cuando se habilita la retención de objetos en el bucket de Cloud Storage en el que escribe el trabajo de Dataflow. Para obtener más información, consulta Habilita y usa parámetros de configuración de retención de objetos.
Para resolver este problema, usa una de las siguientes soluciones alternativas:
Escribe en un bucket de Cloud Storage que no tenga una política de retención en la carpeta
temp.Quita la política de retención del bucket en el que escribe el trabajo. Para obtener más información, consulta Cómo establecer la configuración de retención de un objeto.
El segundo error puede indicar que la retención de objetos está habilitada en el bucket de Cloud Storage o que la cuenta de servicio de trabajador de Dataflow no tiene permiso para escribir en el bucket de Cloud Storage.
Si ves el segundo error y la retención de objetos está habilitada en el bucket de Cloud Storage, prueba las soluciones alternativas que se describieron anteriormente. Si la retención de objetos no está habilitada en el bucket de Cloud Storage, verifica si la cuenta de servicio de trabajador de Dataflow tiene permiso de escritura en el bucket de Cloud Storage. Para obtener más información, consulta Cómo acceder a buckets de Cloud Storage.
El procesamiento se atascó o la operación está en curso
Si Dataflow dedica más tiempo a ejecutar una DoFn que el tiempo especificado en TIME_INTERVAL sin mostrar un resultado, se muestra el siguiente mensaje.
Java
Cualquiera de los dos siguientes mensajes de registro, según la versión:
Processing stuck in step STEP_NAME for at least TIME_INTERVAL
Operation ongoing in bundle BUNDLE_ID for at least TIME_INTERVAL without outputting or completing: at STACK_TRACE
Python
Operation ongoing for over TIME_INTERVAL in state STATE in step STEP_ID without returning. Current Traceback: TRACEBACK
Go
Operation ongoing in transform TRANSFORM_ID for at least TIME_INTERVAL without outputting or completing in state STATE
Este comportamiento tiene dos causas posibles:
- Tu código
DoFnes lento o espera que se complete una operación externa lenta. - Es posible que tu código
DoFnesté atascado, interbloqueado o sea demasiado lento para terminar de procesarse.
Para determinar cuál es el caso, expande la entrada de registro de Cloud Monitoring a fin de ver un seguimiento de pila. Busca mensajes que indiquen que el código DoFn está bloqueado o que tiene problemas. Si no hay mensajes presentes, el problema podría ser la velocidad de ejecución del código DoFn. Considera usar Cloud Profiler o alguna otra herramienta para investigar el rendimiento de tu código.
Si tu canalización está compilada en la VM de Java (mediante Java o Scala), puedes investigar la causa de que tu código se atasque. Realiza un volcado completo de los subprocesos de toda la JVM (no solo del subproceso atascado) mediante estos pasos:
- Toma nota del nombre del trabajador de la entrada de registro.
- En la sección de Compute Engine de la Google Cloud consola, busca la instancia de Compute Engine con el nombre del trabajador que anotaste.
- Usa SSH para conectarte a la instancia con ese nombre.
Ejecuta el siguiente comando:
curl http://localhost:8081/threadz
Operación en curso en el paquete
Cuando ejecutas una canalización que lee desde JdbcIO, las lecturas particionadas de JdbcIO son lentas y aparece el siguiente mensaje en los archivos de registro del trabajador:
Operation ongoing in bundle process_bundle-[0-9-]* for PTransform{id=Read from JDBC with Partitions\/JdbcIO.Read\/JdbcIO.ReadAll\/ParDo\(Read\)\/ParMultiDo\(Read\).*, state=process} for at least (0[1-9]h[0-5][0-9]m[0-5][0-9]s) without outputting or completing:
Para resolver este problema, realiza uno o más de los siguientes cambios en tu canalización:
Usa particiones para aumentar el paralelismo del trabajo. Lee con más particiones más pequeñas para mejorar el escalamiento.
Verifica si la columna de partición es una columna de índice o una columna de partición real en la fuente. Activa la indexación y la partición en esta columna de la base de datos de origen para obtener el mejor rendimiento.
Usa los parámetros
lowerBoundyupperBoundpara omitir la búsqueda de los límites.
Errores de cuota de Pub/Sub
Cuando se ejecuta una canalización de transmisión desde Pub/Sub, se producen los siguientes errores:
429 (rateLimitExceeded)
O:
Request was throttled due to user QPS limit being reached
Estos errores se producen si el proyecto tiene una cuota de Pub/Sub insuficiente.
Para averiguar si tu proyecto tiene una cuota insuficiente, sigue estos pasos a fin de verificar si hay errores del cliente:
- Ve a la consola deGoogle Cloud .
- En el menú de la izquierda, selecciona API y servicios.
- En el Cuadro de búsqueda, busca Cloud Pub/Sub.
- Haz clic en la pestaña Uso.
- Marca Códigos de respuesta y busca códigos de error de cliente
(4xx).
La política de la organización prohíbe la solicitud
Cuando ejecutas una canalización, se produce el siguiente error:
Error trying to get gs://BUCKET_NAME/FOLDER/FILE:
{"code":403,"errors":[{"domain":"global","message":"Request is prohibited by organization's policy","reason":"forbidden"}],
"message":"Request is prohibited by organization's policy"}
Este error se produce si el bucket de Cloud Storage está fuera del perímetro de servicio.
Para resolver este problema, crea una regla de salida que permita el acceso al bucket fuera del perímetro de servicio.
No se puede acceder al paquete ... publicado en etapa de pruebas
Los trabajos que se usaron correctamente pueden fallar con el siguiente error:
Staged package...is inaccessible
Para solucionar este problema, sigue estos pasos:
- Verifica que el bucket de Cloud Storage utilizado para la etapa de pruebas no tenga una configuración de TTL que haga que los paquetes en etapa de pruebas se borren.
Verifica que la cuenta de servicio del trabajador de tu proyecto de Dataflow tenga permiso para acceder al bucket de Cloud Storage que se usó en la etapa de pruebas. Las brechas en los permisos pueden deberse a cualquiera de los siguientes motivos:
- El bucket de Cloud Storage que se usa para la etapa de pruebas está presente en un proyecto diferente.
- El bucket de Cloud Storage que se usó para la etapa de pruebas migró de acceso detallado al acceso uniforme a nivel del depósito. Debido a la inconsistencia entre las políticas de IAM y LCA, migrar el bucket de etapa de pruebas al acceso uniforme a nivel de depósito no permite LCA para recursos de Cloud Storage. Las LCA incluyen los permisos que mantiene la cuenta de servicio del trabajador del proyecto de Dataflow a través del bucket de etapa de pruebas.
Para obtener más información, consulta Cómo acceder a buckets de Cloud Storage en todos los proyectos. Google Cloud
Un elemento de trabajo falló 4 veces
El siguiente error ocurre cuando falla un trabajo por lotes:
The job failed because a work item has failed 4 times.
Este error ocurre si una sola operación en un trabajo por lotes hace que el código del trabajador falle cuatro veces. Dataflow hace que falle el trabajo y se muestra este mensaje.
Cuando se ejecuta en modo de transmisión, un paquete que incluye un elemento defectuoso se reintenta de forma indefinida, lo que puede hacer que la canalización se estanque de forma permanente.
No puedes configurar este umbral de falla. Para obtener más detalles, consulta control de excepciones y errores de canalización.
Para resolver este problema, busca las cuatro fallas individuales en los registros de Cloud Monitoring del trabajo. En los registros del trabajador, busca las entradas de registro Nivel de error o Nivel fatal que muestren excepciones o errores. La excepción o error debería aparecer al menos cuatro veces. Si los registros solo contienen errores genéricos de tiempo de espera relacionados con el acceso a recursos externos, como MongoDB, verifica que la cuenta de servicio de trabajador tenga permiso para acceder a la subred del recurso.
Tiempo de espera en el archivo de resultados de sondeo
Para obtener información completa sobre cómo solucionar el error "Se agotó el tiempo de espera en el archivo de resultados de la sondeo", consulta Soluciona problemas de plantillas flexibles.
Falló la escritura correcta de archivo/Write/WriteImpl/PreFinalize
Cuando ejecutas un trabajo, este falla de forma intermitente y se produce el siguiente error:
Workflow failed. Causes: S27:Write Correct File/Write/WriteImpl/PreFinalize failed., Internal Issue (ID): ID:ID, Unable to expand file pattern gs://BUCKET_NAME/temp/FILE
Este error ocurre cuando se usa la misma subcarpeta como la ubicación de almacenamiento temporal para varios trabajos que se ejecutan de forma simultánea.
A fin de resolver este problema, no uses la misma subcarpeta que la ubicación de almacenamiento temporal para varias canalizaciones. En cada canalización, proporciona una subcarpeta única para usar como ubicación de almacenamiento temporal.
El elemento excede el tamaño máximo de los mensajes protobuf
Cuando ejecutas trabajos de Dataflow y tu canalización tiene elementos grandes, es posible que veas errores similares a los siguientes ejemplos:
Exception serializing message!
ValueError: Message org.apache.beam.model.fn_execution.v1.Elements exceeds maximum protobuf size of 2GB
O:
Buffer size ... exceeds GRPC limit 2147483548. This is likely due to a single element that is too large.
Es posible que también veas una advertencia similar a la del siguiente ejemplo:
Data output stream buffer size ... exceeds 536870912 bytes. This is likely due to a large element in a PCollection.
Estos errores se producen cuando la canalización contiene elementos grandes.
Para resolver este problema, si usas el SDK de Python, actualiza a la versión 2.57.0 o posterior de Apache Beam. Las versiones del SDK de Python 2.57.0 y posteriores mejoran el procesamiento de elementos grandes y agregan registros relevantes.
Si los errores persisten después de la actualización o si no usas el SDK de Python, identifica el paso del trabajo en el que se produce el error y, luego, intenta reducir el tamaño de los elementos en ese paso.
Cuando los objetos PCollection en tu canalización tienen elementos grandes, aumentan los requisitos de RAM para la canalización.
Los elementos grandes también pueden causar errores en el entorno de ejecución, en especial cuando cruzan los límites de las etapas fusionadas.
Los elementos grandes pueden ocurrir cuando una canalización materializa de forma involuntaria un iterable grande. Por ejemplo, una canalización que pasa la salida de
una operación GroupByKey en una operación Reshuffle innecesaria
materializa las listas como elementos únicos. Estas listas podrían contener una gran cantidad de valores para cada clave.
Si el error se produce en un paso que usa una entrada complementaria, ten en cuenta que el uso de entradas complementarias puede generar una barrera de fusión. Comprueba si la transformación que produce un elemento grande y la transformación que lo consume pertenecen a la misma etapa.
Cuando construyas tu canalización, sigue estas prácticas recomendadas:
- En
PCollections, usa varios elementos pequeños en lugar de un solo elemento grande. - Almacena BLOB grandes en sistemas de almacenamiento externo. Usa
PCollectionspara pasar sus metadatos o usa un codificador personalizado que reduzca el tamaño del elemento. - Si debes pasar una PCollection que pueda exceder los 2 GB como una entrada complementaria, usa vistas iterables, como
AsIterableyAsMultiMap.
El tamaño máximo de un solo elemento en un trabajo de Dataflow está limitado a 2 GB. Para obtener más información, consulta Cuotas y límites.
Dataflow no puede procesar las transformaciones administradas…
Las canalizaciones que usan E/S administrada pueden fallar con este error si Dataflow no puede actualizar automáticamente las transformaciones de E/S a la versión compatible más reciente. El URN y los nombres de los pasos proporcionados en el error deben especificar qué transformaciones exactas no pudo actualizar Dataflow.
Es posible que encuentres detalles adicionales sobre este error en el Explorador de registros en los nombres de registro de Dataflow managed-transforms-worker y managed-transforms-worker-startup.
Si el Explorador de registros no proporciona información adecuada para solucionar el error, comunícate con Atención al cliente de Cloud.
Archiva errores de trabajos
Las siguientes secciones contienen errores comunes que puedes encontrar cuando intentas archivar un trabajo de Dataflow con la API.
No se proporciona ningún valor
Cuando intentas archivar un trabajo de Dataflow con la API, es posible que se produzca el siguiente error:
The field mask specifies an update for the field job_metadata.user_display_properties.archived in job JOB_ID, but no value is provided. To update a field, please provide a field for the respective value.
Este error ocurre por uno de los siguientes motivos:
La ruta especificada para el campo
updateMaskno sigue el formato correcto. Este problema puede deberse a errores tipográficos.No se especificó correctamente
JobMetadata. En el campoJobMetadata, parauserDisplayProperties, usa el par clave-valor"archived":"true".
Para resolver este error, verifica que el comando que pasas a la API coincida con el formato requerido. Para obtener más detalles, consulta Archiva un trabajo.
La API no reconoce el valor
Cuando intentas archivar un trabajo de Dataflow con la API, es posible que se produzca el siguiente error:
The API does not recognize the value VALUE for the field job_metadata.user_display_properties.archived for job JOB_ID. REASON: Archived display property can only be set to 'true' or 'false'
Este error se produce cuando el valor proporcionado en el par clave-valor de los trabajos de archivo no es
un valor admitido. Los valores admitidos para el par clave-valor de trabajos de archivo son
"archived":"true" y "archived":"false".
Para resolver este error, verifica que el comando que pasas a la API coincida con el formato requerido. Para obtener más detalles, consulta Archiva un trabajo.
No se pueden actualizar el estado y la máscara
Cuando intentas archivar un trabajo de Dataflow con la API, es posible que se produzca el siguiente error:
Cannot update both state and mask.
Este error ocurre cuando intentas actualizar el estado del trabajo y el estado del archivo en la misma llamada a la API. No puedes realizar actualizaciones al estado del trabajo ni al parámetro de consulta updateMask en la misma llamada a la API.
Para resolver este error, actualiza el estado del trabajo en una llamada a la API independiente. Actualiza el estado del trabajo antes de actualizar el estado del archivo del trabajo.
Se produjo un error en la modificación del flujo de trabajo
Cuando intentas archivar un trabajo de Dataflow con la API, es posible que se produzca el siguiente error:
Workflow modification failed.
Por lo general, este error ocurre cuando intentas archivar un trabajo que se está ejecutando.
Para resolver este error, espera a que se complete el trabajo antes de archivarlo. Los trabajos completados tienen uno de los siguientes estados del trabajo:
JOB_STATE_CANCELLEDJOB_STATE_DRAINEDJOB_STATE_DONEJOB_STATE_FAILEDJOB_STATE_UPDATED
Para obtener más información, consulta Detecta la finalización de un trabajo de Dataflow.
Errores de imagen de contenedor
Las siguientes secciones contienen errores comunes que puedes encontrar cuando usas contenedores personalizados y pasos para resolver los errores. Por lo general, los errores tienen el siguiente mensaje como prefijo:
Unable to pull container image due to error: DETAILED_ERROR_MESSAGE
Permiso "containeranalysis.occurrences.list" denegado
En tus archivos de registro, aparece el siguiente error:
Error getting old patchz discovery occurrences: generic::permission_denied: permission "containeranalysis.occurrences.list" denied for project "PROJECT_ID", entity ID "" [region="REGION" projectNum=PROJECT_NUMBER projectID="PROJECT_ID"]
La API de Container Analysis es necesaria para el análisis de vulnerabilidades.
Para obtener más información, consulta la descripción general del análisis del SO y la configuración del control de acceso en la documentación de Artifact Analysis.
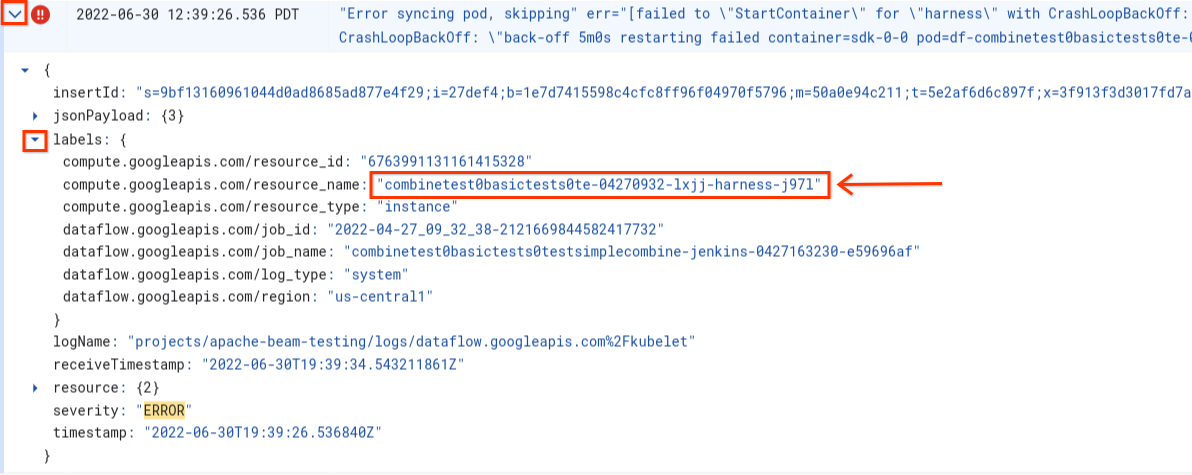
No se pudo sincronizar el pod… no se pudo “StartContainer”.
El siguiente error ocurre durante el inicio de un trabajador:
Error syncing pod POD_ID, skipping: [failed to "StartContainer" for CONTAINER_NAME with CrashLoopBackOff: "back-off 5m0s restarting failed container=CONTAINER_NAME pod=POD_NAME].
Un Pod es un grupo ubicado en el mismo lugar de contenedores de Docker que se ejecutan en un trabajador de Dataflow. Este error ocurre cuando uno de los contenedores de Docker en el pod no se inicia. Si la falla no se puede recuperar, el trabajador de Dataflow no puede iniciarse y los trabajos por lotes de Dataflow eventualmente generan errores como los siguientes:
The Dataflow job appears to be stuck because no worker activity has been seen in the last 1h.
Por lo general, este error ocurre cuando uno de los contenedores falla de forma continua durante el inicio.
Para comprender la causa raíz, busca los registros captados inmediatamente antes de la falla. Para analizar los registros, usa el Explorador de registros. En el visor de registros, limita los archivos de registro a las entradas emitidas por el trabajador con errores de inicio del contenedor. Para limitar las entradas de registro, completa los siguientes pasos:
- En el visor de registros, busca la entrada de registro
Error syncing pod. - Para ver las etiquetas asociadas con la entrada de registro, expande la entrada de registro.
- Haz clic en la etiqueta asociada con la
resource_namey, luego, en Mostrar entradas coincidentes.
En el explorador de registros, los registros de Dataflow están organizados en varias transmisiones de registros. El mensaje Error syncing pod se emite en el registro llamado kubelet. Sin embargo, los registros del contenedor con errores podrían estar en una transmisión de registros diferente. Cada contenedor tiene un nombre. Usa la siguiente tabla para determinar qué transmisión de registro puede contener registros relevantes al contenedor que falla.
| Nombre del contenedor | Nombres de registro |
|---|---|
| sdk, sdk0, sdk1, sdk-0-0 y similares | docker |
| agente | agente, agente-inicio |
| Python, java-batch, java-streaming | trabajador-inicio, trabajador |
| artefacto | artefacto |
Cuando consultes el explorador de registros, asegúrate de que la consulta incluya los nombres de registro relevantes en la interfaz del compilador de consultas o que no tenga restricciones en el nombre del registro.
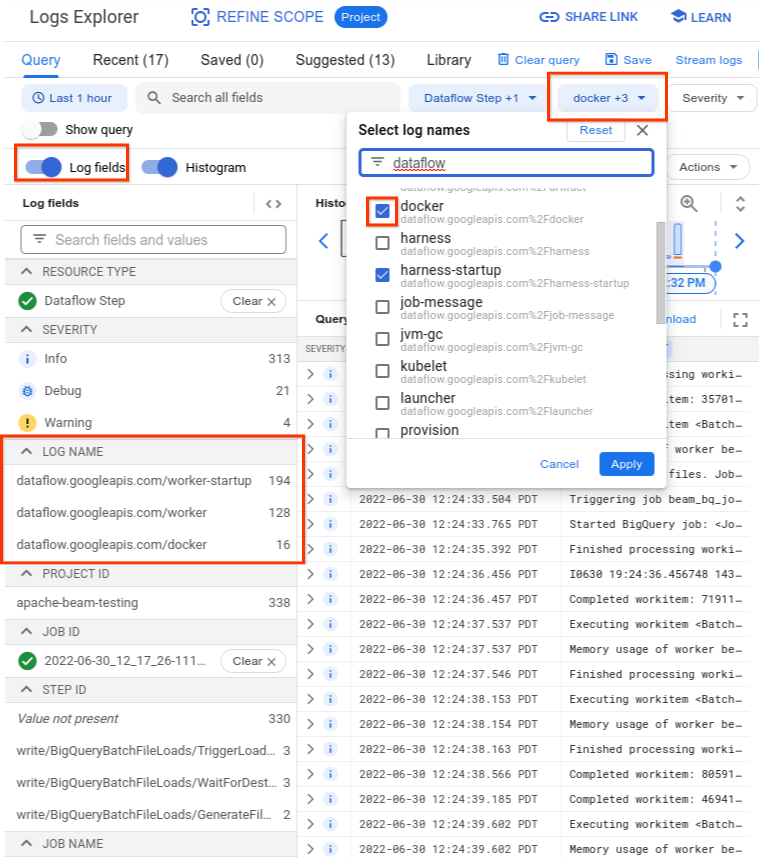
Después de seleccionar los registros relevantes, el resultado de la consulta podría verse como el siguiente ejemplo:
resource.type="dataflow_step"
resource.labels.job_id="2022-06-29_08_02_54-JOB_ID"
labels."compute.googleapis.com/resource_name"="testpipeline-jenkins-0629-DATE-cyhg-harness-8crw"
logName=("projects/apache-beam-testing/logs/dataflow.googleapis.com%2Fdocker"
OR
"projects/apache-beam-testing/logs/dataflow.googleapis.com%2Fworker-startup"
OR
"projects/apache-beam-testing/logs/dataflow.googleapis.com%2Fworker")
Debido a que los registros que informan el síntoma de la falla del contenedor a veces se informan como INFO, incluye registros INFO en tu análisis.
Las causas típicas de las fallas del contenedor son las siguientes:
- Tu canalización de Python tiene dependencias adicionales que se instalan en el entorno de ejecución, y la instalación no se realiza correctamente. Es posible que veas errores como
pip install failed with error. Este problema puede deberse a requisitos conflictivos o a una configuración de red restringida que evita que un trabajador de Dataflow extraiga una dependencia externa de un repositorio público a través de Internet. Un trabajador falla en el medio de la ejecución de la canalización debido a un error de memoria insuficiente. Es posible que veas un error como uno de los siguientes:
java.lang.OutOfMemoryError: Java heap spaceShutting down JVM after 8 consecutive periods of measured GC thrashing. Memory is used/total/max = 24453/42043/42043 MB, GC last/max = 58.97/99.89 %, #pushbacks=82, gc thrashing=true. Heap dump not written.
Para depurar un problema de memoria insuficiente, consulta Soluciona problemas de errores de memoria insuficientes de Dataflow.
Dataflow no puede extraer la imagen del contenedor. Para obtener más información, consulta La solicitud de extracción de imágenes falló con un error.
El contenedor que se usa no es compatible con la arquitectura de CPU de la VM de trabajador. En los registros de inicio del agente, es posible que veas un error como el siguiente:
exec /opt/apache/beam/boot: exec format error. Para verificar la arquitectura de la imagen de contenedor, ejecutadocker image inspect $IMAGE:$TAGy busca la palabra claveArchitecture. Si diceError: No such image: $IMAGE:$TAG, es posible que primero debas extraer la imagen mediante la ejecución dedocker pull $IMAGE:$TAG. Para obtener información sobre cómo compilar imágenes de varias arquitecturas, consulta Compila una imagen de contenedor de varias arquitecturas.
Después de identificar el error que hace que el contenedor falle, intenta solucionarlo y, luego, vuelve a enviar la canalización.
Se produjo un error en la imagen solicitud de extracción
Durante el inicio del trabajador, aparece uno de los siguientes errores en los registros del trabajador o del trabajo:
Image pull request failed with error
pull access denied for IMAGE_NAME
manifest for IMAGE_NAME not found: manifest unknown: Failed to fetch
Get IMAGE_NAME: Service Unavailable
Estos errores ocurren si un trabajador no puede iniciarse porque el trabajador no puede extraer una imagen de contenedor de Docker. Este problema ocurre en las siguientes situaciones:
- La URL de la imagen del contenedor de SDK personalizado es incorrecta
- El trabajador no tiene acceso de red o credenciales para la imagen remota
Para solucionar este problema, sigue estos pasos:
- Si usas una imagen de contenedor personalizada con tu trabajo, verifica que la URL de tu imagen sea correcta y que tenga una etiqueta o un resumen válidos. Los trabajadores de Dataflow también necesitan acceder a la imagen.
- Verifica que las imágenes públicas se puedan extraer de forma local mediante la ejecución de
docker pull $imagedesde una máquina no autenticada.
Para imágenes privadas o trabajadores privados:
- Si usas Container Registry para alojar la imagen de contenedor, se recomienda usar Artifact Registry. Container Registry se dio de baja el 15 de mayo de 2023. Si usas Container Registry, puedes migrar a Artifact Registry. Si tus imágenes están en un proyecto diferente del que se usó para ejecutar tu trabajo de Google Cloud , configura el control de acceso para la cuenta de servicio Google Cloud predeterminada.
- Si usas una nube privada virtual (VPC) compartida, asegúrate de que los trabajadores puedan acceder al host del repositorio de contenedores personalizado.
- Usa
sshpara conectarte con una VM de trabajador de un trabajo en ejecución y ejecutadocker pull $imagea fin de confirmar directamente que el trabajador está configurado de forma correcta.
Si los trabajadores fallan varias veces seguidas debido a este error y no se han iniciado trabajos en el trabajo, este puede fallar con un error como el siguiente:
Job appears to be stuck.
Si quitas el acceso a la imagen mientras se ejecuta el trabajo, ya sea quitando la imagen en sí o revocando las credenciales de la cuenta de servicio del trabajador de Dataflow o el acceso a Internet para acceder a las imágenes, Dataflow solo registra errores. Dataflow no hace fallar el trabajo. Dataflow también evita las fallas de las canalizaciones de transmisión de larga duración para evitar la pérdida del estado de la canalización.
Pueden surgir otros errores posibles debido a problemas o interrupciones de la cuota del repositorio. Si tienes problemas por superar la cuota de Docker Hub para extraer imágenes públicas o interrupciones generales del repositorio de terceros, considera usar Artifact Registry como el repositorio de imágenes.
SystemError: código de operación desconocido
Tu canalización de contenedor personalizada de Python puede fallar con el siguiente error inmediatamente después del envío de trabajos:
SystemError: unknown opcode
Además, el seguimiento de pila puede incluir lo siguiente:
apache_beam/internal/pickler.py
Para resolver este problema, verifica que la versión de Python que usas de manera local coincida con la versión de la imagen de contenedor hasta las versiones principales y secundarias. La diferencia en la versión del parche, como 3.6.7 en comparación con 3.6.8, no crea problemas de compatibilidad. La diferencia en la versión secundaria, como 3.6.8 en comparación con 3.8.2, puede causar fallas en la canalización.
Errores de actualización de la canalización de transmisión
Para obtener información sobre cómo resolver errores cuando actualizas una canalización de transmisión con funciones como la ejecución de un trabajo de reemplazo paralelo, consulta Soluciona problemas de actualizaciones de canalizaciones de transmisión.
Actualización del arnés de Runner v2
El siguiente mensaje informativo aparece en los registros de trabajos de un trabajo de Runner v2
The Dataflow RunnerV2 container image of this job's workers will be ready for update in 7 days.
Esto significa que la versión del proceso de arnés del ejecutor se actualizará automáticamente en algún momento 7 días después de la entrega inicial del mensaje, lo que provocará una breve pausa en el procesamiento. Si quieres controlar cuándo se produce esta pausa, consulta Cómo actualizar una canalización existente para iniciar un trabajo de reemplazo que tendrá la versión más reciente del arnés del ejecutor.
Errores de trabajador
Las siguientes secciones contienen errores de trabajador comunes que puedes encontrar y pasos para resolver o solucionar los errores.
La llamada desde el agente de trabajo de Java a un DoFn de Python falla con un error
Si falla una llamada del agente de trabajo de Java a un DoFn de Python, se muestra un mensaje de error relevante.
Para investigar el error, expande la entrada de registro de error de Cloud Monitoring y observa el mensaje de error y el traceback. Muestra qué código falló para que puedas corregirlo si es necesario. Si crees que el error es un error en Apache Beam o Dataflow, infórmalo.
EOFError: datos marshal demasiado cortos
En los registros del trabajador, aparece el siguiente error:
EOFError: marshal data too short
Este error a veces ocurre cuando los trabajadores de la canalización de Python se quedan sin espacio en el disco.
Para resolver este problema, consulta No queda espacio en el dispositivo.
No se pudo conectar el disco
Cuando intentas iniciar un trabajo de Dataflow que usa VMs de C3 con Persistent Disk, el trabajo falla con uno o ambos de los siguientes errores:
Failed to attach disk(s), status: generic::invalid_argument: One or more operations had an error
Can not allocate sha384 (reason: -2), Spectre V2 : WARNING: Unprivileged eBPF is enabled with eIBRS on...
Estos errores se producen cuando usas VMs C3 con un tipo de Persistent Disk no compatible. Si deseas obtener más información, consultaTipos de discos compatibles para C3.
Para usar VMa de C3 con tu trabajo de Dataflow, elige
el tipo de disco de trabajador pd-ssd. Para obtener más información, consulta
Opciones a nivel de trabajador.
Java
--workerDiskType=pd-ssd
Python
--worker_disk_type=pd-ssd
Go
disk_type=pd-ssd
No queda espacio en el dispositivo
Cuando un trabajo se queda sin espacio en el disco, puede aparecer el siguiente error en los registros del trabajador:
No space left on device
Este error puede ocurrir por uno de los siguientes motivos:
- El almacenamiento persistente de trabajadores se queda sin espacio libre, lo que puede ocurrir por uno de los siguientes motivos:
- Un trabajo descarga dependencias grandes en el entorno de ejecución
- Un trabajo usa contenedores personalizados grandes
- Un trabajo escribe muchos datos temporales en el disco local
- Cuando se usa Dataflow Shuffle, Dataflow configura el tamaño de disco predeterminado más bajo. Como resultado, este error puede ocurrir con trabajos que se mueven desde una operación Shuffle basada en trabajadores.
- El disco de arranque del trabajador se llena porque registra más de 50 entradas por segundo.
Para resolver este problema, sigue estos pasos:
Para ver los recursos del disco asociados con un solo trabajador, busca los detalles de las VM de trabajador asociados con tu trabajo. El sistema operativo, los objetos binarios, los registros y los contenedores consumen parte del espacio en disco.
Para aumentar el espacio del disco persistente o del disco de arranque, ajusta la opción de canalización del tamaño del disco.
Realiza un seguimiento del uso del espacio en el disco en las instancias de VM de trabajador mediante Cloud Monitoring. Consulta Recibe métricas de VM de trabajador del agente de Monitoring para obtener instrucciones que expliquen cómo configurar esto.
Para buscar problemas de espacio en el disco de arranque, visualiza la salida del puerto en serie en las instancias de VM de trabajador y busca mensajes como el siguiente:
Failed to open system journal: No space left on device
Si tienes muchas instancias de VM de trabajador, puedes crear una secuencia de comandos para ejecutar gcloud compute instances get-serial-port-output en todas ellas de una vez.
En su lugar, puedes revisar ese resultado.
La canalización de Python falla después de una hora de inactividad del trabajador
Cuando uses el SDK de Apache Beam para Python con Dataflow Runner V2 en máquinas de trabajador con muchos núcleos de CPU, usa el SDK de Apache Beam 2.35.0 o una versión posterior. Si tu trabajo usa un contenedor personalizado, usa el SDK de Apache Beam 2.46.0 o una versión posterior.
Considera compilar tu contenedor de Python de forma previa. Este paso puede mejorar los tiempos de inicio de la VM y el rendimiento del ajuste de escala automático horizontal. Para usar esta función, habilita la API de Cloud Build en tu proyecto y envía tu canalización con el siguiente parámetro:
‑‑prebuild_sdk_container_engine=cloud_build.
Para obtener más información, consulta Dataflow Runner V2.
También puedes usar una imagen de contenedor personalizada con todas las dependencias preinstaladas.
RESOURCE_POOL_EXHAUSTED
Cuando creas un recurso Google Cloud , se produce el siguiente error:
Startup of the worker pool in zone ZONE_NAME failed to bring up any of the desired NUMBER workers.
ZONE_RESOURCE_POOL_EXHAUSTED_WITH_DETAILS: Instance 'INSTANCE_NAME' creation failed: The zone 'projects/PROJECT_ID/zones/ZONE_NAME' does not have enough resources available to fulfill the request. '(resource type:RESOURCE_TYPE)'.
Este error se produce para las condiciones de agotamiento temporal de un recurso específico en una zona específica.
Para resolver el problema, puedes esperar o crear el mismo recurso en otra zona.
Como solución alternativa, implementa un bucle de reintentos para tus trabajos, de modo que, cuando se produzca un error de falta de stock, el trabajo se reintente automáticamente hasta que haya recursos disponibles. Para crear un bucle de reintento, implementa el siguiente flujo de trabajo:
- Crea un trabajo de Dataflow y obtén su ID.
- Sondea el estado del trabajo hasta que sea
RUNNINGoFAILED.- Si el estado del trabajo es
RUNNING, sal del bucle de reintentos. - Si el estado del trabajo es
FAILED, usa la API de Cloud Logging para consultar los registros del trabajo en busca de la cadenaZONE_RESOURCE_POOL_EXHAUSTED_WITH_DETAILS. Para obtener más información, consulta Trabaja con registros de canalización.- Si los registros no contienen la cadena, sal del bucle de reintentos.
- Si los registros contienen la cadena, crea un trabajo de Dataflow, obtén el ID del trabajo y reinicia el bucle de reintentos.
- Si el estado del trabajo es
Como práctica recomendada, distribuye tus recursos en varias zonas y regiones para tolerar interrupciones.
Las instancias con aceleradores invitados no admiten la migración en vivo
Una canalización de Dataflow falla en el envío del trabajo con el siguiente error:
UNSUPPORTED_OPERATION: Instance <worker_instance_name> creation failed:
Instances with guest accelerators do not support live migration
Este error puede ocurrir cuando solicitaste un tipo de máquina de trabajador que tiene aceleradores de hardware, pero no configuraste Dataflow para que use aceleradores.
Usa la opción de servicio --worker_accelerator de Dataflow o la sugerencia de recursos accelerator para solicitar aceleradores de hardware.
Si usas plantillas de Flex, puedes usar la opción --additionalExperiments para proporcionar opciones del servicio de Dataflow. Si se realiza correctamente, la opción worker_accelerator se puede encontrar en el panel de información del trabajo en la consola deGoogle Cloud .
Cuota del proyecto… o políticas de control de acceso que impiden la operación
Se produce el siguiente error:
Startup of the worker pool in zone ZONE_NAME failed to bring up any of the desired NUMBER workers. The project quota may have been exceeded or access control policies may be preventing the operation; review the Cloud Logging 'VM Instance' log for diagnostics.
Este error ocurre por uno de los siguientes motivos:
- Excediste una de las cuotas de Compute Engine en las que se basa la creación de trabajadores de Dataflow.
- Tu organización tiene restricciones que prohíben algún aspecto del proceso de creación de instancias de VM, como la cuenta que se usa o la zona a la que se orienta.
Para resolver este problema, sigue estos pasos:
Revisa el registro de instancias de VM
- Ve al visor de Cloud Logging
- En la lista desplegable Recurso auditado, selecciona Instancia de VM.
- En la lista desplegable Todos los registros, selecciona compute.googleapis.com/activity_log
- Analiza el registro en busca de entradas relacionadas con la falla de creación de la instancia de VM.
Verifica el uso de las cuotas de Compute Engine
Para ver el uso de recursos de Compute Engine en comparación con las cuotas de Dataflow de la zona a la que orientas, ejecuta el siguiente comando:
gcloud compute regions describe [REGION]Revisa los resultados de los siguientes recursos para ver si alguno supera la cuota:
- CPU
- DISKS_TOTAL_GB
- IN_USE_ADDRESSES
- INSTANCE_GROUPS
- INSTANCES
- REGIONAL_INSTANCE_GROUP_MANAGERS
Si es necesario, solicita un cambio de cuota.
Revisa las restricciones de la política de la organización
- Ve a la página Políticas de la organización.
- Revisa las restricciones de cualquiera que pueda limitar la creación de instancias de VM para la cuenta que usas (de forma predeterminada, la cuenta de servicio de Dataflow) o en la zona a la que se orienta.
- Si tienes una política que restringe el uso de direcciones IP externas, desactiva las direcciones IP externas para este trabajo. Para obtener más información sobre cómo desactivar las direcciones IP externas, consulta Configura el acceso a Internet y las reglas de firewall.
Se agotó el tiempo de espera para una actualización del trabajador
Cuando falla un trabajo de Dataflow, se produce el siguiente error:
Root cause: Timed out waiting for an update from the worker. For more information, see https://cloud.google.com/dataflow/docs/guides/common-errors#worker-lost-contact.
Este error puede deberse a varios motivos, incluidos los siguientes:
- Sobrecarga del trabajador
- Cómo mantener el bloqueo del intérprete global
- Configuración de DoFn de larga duración
Sobrecarga de trabajadores
En ocasiones, se produce un error de tiempo de espera cuando el trabajador se queda sin memoria o espacio de intercambio. Para resolver este problema, como primer paso, intenta ejecutar el trabajo de nuevo. Si el trabajo aún falla y se produce el mismo error, intenta usar un trabajador con más memoria y espacio en el disco. Por ejemplo, agrega la siguiente opción de inicio de canalización:
--worker_machine_type=m1-ultramem-40 --disk_size_gb=500
Cambiar el tipo de trabajador podría afectar el costo facturado. Para obtener más información, consulta Cómo solucionar problemas de errores de memoria en Dataflow.
Este error también puede ocurrir cuando tus datos contienen una clave de acceso rápido. En esta situación, el uso de CPU es alto en algunos trabajadores durante la mayor parte del trabajo. Sin embargo, la cantidad de trabajadores no alcanza el máximo permitido. Para obtener más información sobre las claves de acceso rápido y sus posibles soluciones, consulta Escribe canalizaciones de Dataflow teniendo en cuenta la escalabilidad.
Para obtener soluciones adicionales a este problema, consulta Se detectó una clave de acceso rápido.
Python: bloqueo global del intérprete (GIL)
Si tu código de Python llama al código de C/C++ con el mecanismo de extensión de Python, verifica si el código de la extensión libera el bloqueo de intérprete global de Python (GIL) en partes de código de procesamiento intensivo que no acceden al estado de Python. Si el GIL no se libera durante un período prolongado, es posible que veas mensajes de error como los siguientes:
Unable to retrieve status info from SDK harness <...> within allowed time y SDK worker appears to be permanently unresponsive. Aborting the SDK.
Las bibliotecas que facilitan las interacciones con las extensiones, como Cython y PyBind, tienen primitivas para controlar el estado de GIL. También puedes liberar el GIL de forma manual y volver a adquirirlo antes de mostrar el control al intérprete de Python mediante las macro Py_BEGIN_ALLOW_THREADS y Py_END_ALLOW_THREADS.
Para obtener más información, consulta Estado del subproceso y el bloqueo del intérprete global en la documentación de Python.
Es posible recuperar los seguimientos de pila de un subproceso que contiene el GIL en un trabajador de Dataflow en ejecución de la siguiente manera:
# SSH into a running Dataflow worker VM that is currently a straggler, for example:
gcloud compute ssh --zone "us-central1-a" "worker-that-emits-unable-to-retrieve-status-messages" --project "project-id"
# Install nerdctl to inspect a running container with ptrace privileges.
wget https://github.com/containerd/nerdctl/releases/download/v2.0.2/nerdctl-2.0.2-linux-amd64.tar.gz
sudo tar Cxzvvf /var/lib/toolbox nerdctl-2.0.2-linux-amd64.tar.gz
alias nerdctl="sudo /var/lib/toolbox/nerdctl -n k8s.io"
# Find a container running the Python SDK harness.
CONTAINER_ID=`nerdctl ps | grep sdk-0-0 | awk '{print $1}'`
# Start a shell in the running container.
nerdctl exec --privileged -it $CONTAINER_ID /bin/bash
# Inspect python processes in the running container.
ps -A | grep python
PYTHON_PID=$(ps -A | grep python | head -1 | awk '{print $1}')
# Use pystack to retrieve stacktraces from the python process.
pip install pystack
pystack remote --native $PYTHON_PID
# Find which thread holds the GIL and inspect the stacktrace.
pystack remote --native $PYTHON_PID | grep -iF "Has the GIL" -A 100
# Alternately, use inspect with gdb.
apt update && apt install -y gdb
gdb --quiet \
--eval-command="set pagination off" \
--eval-command="thread apply all bt" \
--eval-command "set confirm off" \
--eval-command="quit" -p $PYTHON_PID
En las canalizaciones de Python, en la configuración predeterminada, Dataflow supone que cada proceso de Python que se ejecuta en los trabajadores usa un núcleo de CPU virtual de manera eficiente. Si el código de la canalización omite las limitaciones, por ejemplo, mediante bibliotecas implementadas en C++, los elementos de procesamiento pueden usar recursos de más de un núcleo de CPU virtual y es posible que los trabajadores no tengan suficientes recursos de CPU. Para solucionar este problema, reduce la cantidad de subprocesos en los trabajadores.
Configuración de DoFn de larga duración
Si no usas Runner v2, una llamada de larga duración a DoFn.Setup puede generar el siguiente error:
Timed out waiting for an update from the worker
En general, evita las operaciones que consumen mucho tiempo dentro de DoFn.Setup.
Errores transitorios de publicación en el tema
Cuando tu trabajo de transmisión usa el modo de transmisión al menos una vez y publica en un receptor de Pub/Sub, aparece el siguiente error en los registros del trabajo:
There were transient errors publishing to topic
Si tu trabajo se ejecuta de forma correcta, este error es benigno y puedes ignorarlo. Dataflow vuelve a intentar enviar los mensajes de Pub/Sub de forma automática con una demora de retirada.
No se pudieron recuperar los datos debido a una discrepancia de token para la clave
El siguiente error significa que el elemento de trabajo que se está procesando se reasignó a otro trabajador:
Unable to fetch data due to token mismatch for key
Esto suele ocurrir durante el ajuste de escala automático, pero puede suceder en cualquier momento. Se volverá a intentar cualquier trabajo afectado. Puedes ignorar este error.
Problemas de dependencia de Java
Las clases y bibliotecas incompatibles pueden causar problemas de dependencia de Java. Cuando tu canalización tiene problemas de dependencia de Java, puede producirse uno de los siguientes errores:
NoClassDefFoundError: Este error se produce cuando una clase completa no está disponible durante el entorno de ejecución. Puede deberse a problemas generales de configuración o a incompatibilidades entre la versión de protobuf de Beam y los protos generados de un cliente (por ejemplo, este problema).NoSuchMethodError: Este error se produce cuando la clase en la ruta de clase usa una versión que no contiene el método correcto o cuando cambió la firma del método.NoSuchFieldError: Este error se produce cuando la clase en la ruta de clase usa una versión que no tiene un campo obligatorio durante el entorno de ejecución.FATAL ERROR in native method: Este error ocurre cuando una dependencia integrada no se puede cargar de forma correcta. Cuando uses JAR uber (sombreado), no incluyas bibliotecas que usen firmas (como Conscrypt) en el mismo JAR.
If your pipeline contains user-specific code and settings, the code can't contain mixed versions of libraries. Si usas una biblioteca de administración de dependencias, te recomendamos que uses la BoM de las bibliotecas deGoogle Cloud .
Si usas el SDK de Apache Beam, para importar las bibliotecas BOM de bibliotecas correctas, usa beam-sdks-java-io-google-cloud-platform-bom:
Maven
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.apache.beam</groupId>
<artifactId>beam-sdks-java-google-cloud-platform-bom</artifactId>
<version>BEAM_VERSION</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
Gradle
dependencies {
implementation(platform("org.apache.beam:beam-sdks-java-google-cloud-platform-bom:BEAM_VERSION"))
}
Para obtener más información, consulta Administra dependencias de canalizaciones en Dataflow.
InaccessibleObjectException en JDK 17 y versiones posteriores
Cuando ejecutas canalizaciones con las versiones 17 y posteriores del kit de desarrollo de Java Platform, Standard Edition (JDK), es posible que aparezca el siguiente error en los archivos de registro del trabajador:
Unable to make protected METHOD accessible:
module java.MODULE does not "opens java.MODULE" to ...
Este problema se produce porque, a partir de la versión 9 de Java, se necesitan opciones de máquina virtual (JVM) de Java de módulo abierto para acceder a los elementos internos del JDK. En Java 16 y versiones posteriores, siempre se requieren opciones de JVM de módulos abiertos para acceder a los elementos internos del JDK.
A fin de resolver este problema, cuando pases módulos a tu canalización de Dataflow para abrirlos, usa el formato MODULE/PACKAGE=TARGET_MODULE(,TARGET_MODULE)* con la opción de canalización jdkAddOpenModules. Este formato permite el acceso a la biblioteca necesaria.
Por ejemplo, si el error es module java.base does not "opens java.lang" to unnamed module @..., incluye la siguiente opción de canalización cuando ejecutes tu canalización:
--jdkAddOpenModules=java.base/java.lang=ALL-UNNAMED
For more information, see the
DataflowPipelineOptions
class documentation.
Progreso del elemento de trabajo de informes de errores
En el caso de las canalizaciones de Java, si no usas Runner v2, es posible que veas el siguiente error:
Error reporting workitem progress update to Dataflow service: ...
Este error se debe a una excepción no controlada durante una actualización del progreso de un elemento de trabajo, por ejemplo, durante la división de una fuente. En la mayoría de los casos, si el código del usuario de Apache Beam arroja una excepción no controlada, el elemento de trabajo falla, lo que provoca que la canalización falle.Sin embargo, las excepciones en Source.split se suprimen, ya que esa parte del código está fuera de un elemento de trabajo. Como resultado, solo se registra un registro de errores.
Por lo general, este error es inofensivo si ocurre solo de forma intermitente. Sin embargo, considera controlar las excepciones de forma fluida dentro de tu código de Source.split.
Errores del conector de BigQuery
Las siguientes secciones contienen errores comunes del conector de BigQuery que puedes encontrar y pasos para resolverlos o solucionarlos.
quotaExceeded
Cuando usas el conector de BigQuery para escribir en BigQuery mediante inserciones de transmisión, la capacidad de procesamiento de escritura es menor que la esperada y puede ocurrir el siguiente error:
quotaExceeded
Una capacidad de procesamiento lenta puede deberse a que la canalización excede la cuota de inserción de transmisión de BigQuery disponible. Si este es el caso, los mensajes de error relacionados con las cuotas de BigQuery aparecen en los registros del trabajador de Dataflow (busca errores quotaExceeded).
Si ves errores quotaExceeded, para resolver este problema, haz lo siguiente:
- Cuando uses el SDK de Apache Beam para Java, configura la opción de receptor de BigQuery
ignoreInsertIds(). - Cuando uses el SDK de Apache Beam para Python, usa la opción
ignore_insert_ids.
Esta configuración hace que seas apto para una capacidad de procesamiento de inserción de transmisión de BigQuery de un GB/s por proyecto. Para obtener más información sobre las advertencias relacionadas con la anulación de duplicación automática de mensajes, consulta la documentación de BigQuery. Si quieres aumentar la cuota de inserción de transmisión de BigQuery por encima de un GBps, envía una solicitud a través de la Google Cloud consola.
Si no ves errores relacionados con la cuota en los registros de trabajadores, el problema podría ser que los parámetros predeterminados relacionados con la agrupación en paquetes o en lotes no proporcionen un paralelismo adecuado para que la canalización realice un escalamiento. Puedes ajustar varias opciones de configuración relacionadas con el conector de BigQuery de Dataflow para lograr el rendimiento esperado cuando escribes en BigQuery mediante inserciones de transmisión. Por ejemplo, en el SDK de Apache Beam para Java, ajusta numStreamingKeys a fin de que coincida con la cantidad máxima de trabajadores y considera aumentar insertBundleParallelism para configurar el conector de BigQuery con el objetivo de escribir en BigQuery mediante más subprocesos paralelos.
Si deseas conocer las opciones de configuración disponibles en el SDK de Apache Beam para Java, consulta BigQueryPipelineOptions. Obtén información sobre las opciones de configuración disponibles en el SDK de Apache Beam para Python en la página sobre transformaciones WriteToBigQuery.
rateLimitExceeded
Cuando usas el conector de BigQuery, se produce el siguiente error:
rateLimitExceeded
Este error ocurre si se envían demasiadas solicitudes a la API durante un período breve. BigQuery tiene límites de cuota a corto plazo.
Es posible que la canalización de Dataflow exceda de forma temporal esa cuota. Cuando esto sucede, las solicitudes a la API de tu canalización de Dataflow a BigQuery pueden fallar, lo que puede generar errores rateLimitExceeded en los registros de trabajador.
Dataflow reintenta estas fallas, por lo que puedes ignorar estos errores de forma segura. Si crees que la canalización se ve afectada por errores rateLimitExceeded, comunícate con Atención al cliente de Cloud.
Otros errores
Las siguientes secciones contienen varios errores que puedes encontrar y pasos para resolverlos o solucionarlos.
No se puede asignar sha384
Tu trabajo se ejecuta de forma correcta, pero ves el siguiente error en los registros de trabajos:
ima: Can not allocate sha384 (reason: -2)
Si tu trabajo se ejecuta de forma correcta, este error es benigno y puedes ignorarlo. Las imágenes base de la VM de trabajador a veces producen este mensaje. Dataflow responde y aborda de forma automática el problema subyacente.
Existe una solicitud de función para cambiar el nivel de este mensaje de WARN a INFO. Para obtener más información, consulta Baja el nivel de registro de error de inicio del sistema de Dataflow a WARN o INFO.
Se produjo un error cuando se inicializaba el sistema de sondeo del complemento dinámico
Tu trabajo se ejecuta de forma correcta, pero ves el siguiente error en los registros de trabajos:
Error initializing dynamic plugin prober" err="error (re-)creating driver directory: mkdir /usr/libexec/kubernetes: read-only file system
Si tu trabajo se ejecuta de forma correcta, este error es benigno y puedes ignorarlo. Este error se produce cuando el trabajo de Dataflow intenta crear un directorio sin los permisos de escritura necesarios y la tarea falla. Si el trabajo se realizó de forma correcta, el directorio no era necesario, o Dataflow abordó el problema subyacente.
Existe una solicitud de función para cambiar el nivel de este mensaje de WARN a INFO. Para obtener más información, consulta Baja el nivel de registro de error de inicio del sistema de Dataflow a WARN o INFO.
No existe el objeto pipeline.pb
Cuando se enumeran trabajos con la opción JOB_VIEW_ALL, se produce el siguiente error:
No such object: BUCKET_NAME/PATH/pipeline.pb
Este error puede ocurrir si borras el archivo pipeline.pb de los archivos de etapa de pruebas del trabajo.
Omite la sincronización de Pods
Tu trabajo se ejecuta de forma correcta, pero ves uno de los siguientes errores en los registros del trabajo:
Skipping pod synchronization" err="container runtime status check may not have completed yet"
O:
Skipping pod synchronization" err="[container runtime status check may not have completed yet, PLEG is not healthy: pleg has yet to be successful]"
Si tu trabajo se ejecuta de forma correcta, estos errores son benignos y puedes ignorarlos.
El mensaje container runtime status check may not have completed yet ocurre cuando el kubelet de Kubernetes omite la sincronización de Pods porque espera a que se inicialice el entorno de ejecución del contenedor. Esta situación ocurre por varias razones, como cuando el entorno de ejecución del contenedor se inició o se está reiniciando recientemente.
Cuando el mensaje incluye PLEG is not healthy: pleg has yet to be successful, Kubelet espera a que el generador de eventos de ciclo de vida del Pod (PLEG) esté en buen estado antes de sincronizar los Pods. El PLEG es responsable de generar eventos que kubelet usa para realizar un seguimiento del estado de los Pods.
Existe una solicitud de función para cambiar el nivel de este mensaje de WARN a INFO. Para obtener más información, consulta Baja el nivel de registro de error de inicio del sistema de Dataflow a WARN o INFO.
Recomendaciones
Para obtener orientación sobre las recomendaciones que generan las estadísticas de Dataflow, consulta Estadísticas.