En esta página, se describe cómo encontrar y resolver errores de memoria insuficiente (OOM) en Dataflow.
Encontrar errores de memoria insuficiente
Para determinar si tu canalización se está quedando sin memoria, usa uno de los siguientes métodos.
- En la página Detalles del trabajo, en el panel Registros, consulta la pestaña Diagnóstico. Esta pestaña muestra errores relacionados con los problemas de memoria y la frecuencia con la que se producen.
- En la interfaz de supervisión de Dataflow, usa el gráfico de uso de memoria para supervisar la capacidad y el uso de memoria del trabajador.
- En la página Detalles del trabajo, en el panel Registros, selecciona Registros de trabajador para encontrar errores de memoria insuficiente en los registros de trabajador.
Los errores de memoria insuficiente también pueden aparecer en los registros del sistema. Para verlos, navega al Explorador de registros y usa la siguiente consulta:
resource.type="dataflow_step" resource.labels.job_id="JOB_ID" "out of memory" OR "OutOfMemory" OR "Shutting down JVM"Reemplaza JOB_ID por el ID de tu trabajo.
Para los trabajos de Java, el supervisor de Java Memory informa de forma periódica las métricas de recolección de elementos no utilizados. Si la fracción de tiempo de CPU usada para la recolección de elementos no utilizados excede un umbral del 50% durante un período prolongado, el agente de SDK falla. Es posible que veas un error similar al siguiente ejemplo:
Shutting down JVM after 8 consecutive periods of measured GC thrashing. Memory is used/total/max = ...Este error puede ocurrir cuando la memoria física aún está disponible y, por lo general, indica que el uso de memoria de la canalización es ineficiente. Para resolver este problema, optimiza tu canalización.
El supervisor de Java Memory se configura a través de la interfaz
MemoryMonitorOptions.
Si tu trabajo tiene errores de memoria elevados o no hay memoria suficiente, sigue las recomendaciones de esta página para optimizar el uso de memoria o aumentar la cantidad de memoria disponible.
Resuelve errores de memoria insuficiente
Los cambios en tu canalización de Dataflow pueden resolver los errores de memoria o reducir el uso de memoria. Entre los cambios posibles, se incluyen las siguientes acciones:
- Optimiza tu canalización
- Reduce la cantidad de subprocesos
- Usa un tipo de máquina con más memoria por CPU virtual
En el diagrama siguiente, se muestra el flujo de trabajo de solución de problemas de Dataflow que se describe en esta página.
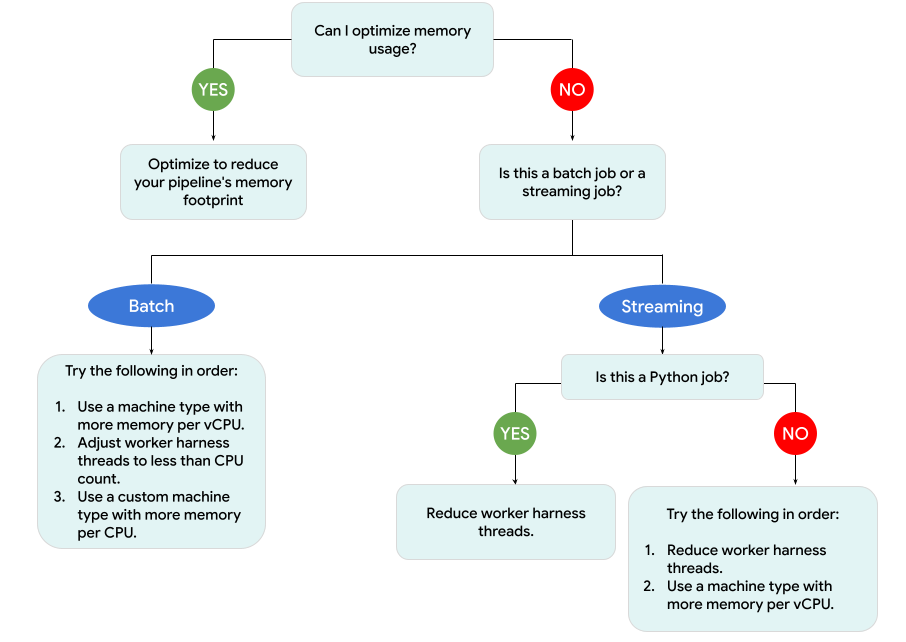
Prueba las siguientes medidas de mitigación:
- Si es posible, optimiza tu canalización para reducir el uso de memoria.
- Si el trabajo es un trabajo por lotes, prueba los siguientes pasos en el orden indicado:
- Usa un tipo de máquina con más memoria por CPU virtual.
- Reduce la cantidad de subprocesos a menos del recuento de CPU virtuales por trabajador.
- Usa un tipo de máquina personalizado con más memoria por CPU virtual.
- Si el trabajo es de transmisión y usa Python, reduce la cantidad de subprocesos a menos de 12.
- Si el trabajo es de transmisión y usa Java o Go, prueba lo siguiente:
- Reduce la cantidad de subprocesos a menos de 500 para los trabajos de Runner v2 o a menos de 300 para los trabajos que no usan Runner v2.
- Usa un tipo de máquina con más memoria.
Optimiza tu canalización
Varias operaciones de canalización pueden provocar errores de falta de memoria. En esta sección, se proporcionan opciones para reducir el uso de memoria de tu canalización. Para identificar las etapas de la canalización que consumen más memoria, usa Cloud Profiler para supervisar el rendimiento de las canalizaciones.
Puedes usar las siguientes prácticas recomendadas para optimizar tu canalización:
- Usa conectores de E/S integrados de Apache Beam para leer archivos
- Rediseñar las operaciones cuando se usan PTransforms
GroupByKey - Reduce los datos de entrada de fuentes externas
- Comparte objetos en subprocesos
- Usa representaciones de elementos con eficiencia de memoria
- Reduce el tamaño de las entradas complementarias
- Usa DoFns divisibles de Apache Beam
Usa los conectores de E/S integrados de Apache Beam para leer archivos
No abras archivos grandes dentro de un DoFn. Para leer archivos, usa los conectores de E/S integrados de Apache Beam.
Los archivos que se abren en una DoFn deben caber en la memoria. Debido a que varias instancias DoFn se ejecutan en simultáneo, los archivos grandes abiertos en DoFn pueden causar errores de memoria insuficiente.
Rediseñar operaciones cuando se usan PTransforms GroupByKey
Cuando usas una PTransform GroupByKey en Dataflow, los valores resultantes por clave y por ventana se procesan en un solo subproceso. Debido a que estos datos se pasan como una transmisión desde el servicio de backend de Dataflow a los trabajadores, no es necesario que se ajuste a la memoria del trabajador. Sin embargo, si los valores se recopilan en la memoria, la lógica de procesamiento puede causar errores de falta de memoria.
Por ejemplo, si tienes una clave que contiene datos para una ventana y agregas los valores clave a un objeto en la memoria, como una lista, puede haber errores de memoria insuficiente. En esta situación, es posible que el trabajador no tenga suficiente capacidad de memoria para contener todos los objetos.
Para obtener más información sobre las GroupByKey transformaciones, consulta la documentación de
Python GroupByKey
y Java GroupByKey
de Apache Beam.
La siguiente lista contiene sugerencias para diseñar tu canalización a fin de minimizar el consumo de memoria cuando se usan PTransforms GroupByKey.
- Para reducir la cantidad de datos por clave y por ventana, evita las claves con muchos valores, también conocidos como claves de acceso rápido.
- Para reducir la cantidad de datos recopilados por ventana, usa un tamaño de ventana más pequeño.
- Si usas valores de clave en una ventana para calcular un número, usa una transformación
Combine. No realices el cálculo en una sola instanciaDoFndespués de recopilar los valores. - Filtra los valores o duplicados antes de procesarlos. Para obtener más información, consulta la documentación de transformación de Python
Filtery JavaFilter.
Reduce los datos de entrada de fuentes externas
Si realizas llamadas a una API externa o a una base de datos para enriquecimiento de datos, los datos que se muestran deben ajustarse a la memoria del trabajador.
Si agrupas en lotes las llamadas, se recomienda usar una transformación GroupIntoBatches.
Si te quedas con errores de memoria insuficiente, reduce el tamaño del lote. Para obtener más información sobre la agrupación en lotes, consulta la documentación de transformación de Python GroupIntoBatches y Java GroupIntoBatches.
Comparte objetos en subprocesos
Compartir un objeto de datos en la memoria a través de instancias de DoFn puede mejorar la eficiencia del espacio y el acceso. Los objetos de datos creados en cualquier método de DoFn, incluidos Setup, StartBundle, Process, FinishBundle y Teardown, se invocan para cada uno DoFn. En Dataflow, cada trabajador puede tener varias instancias de DoFn. Para obtener un uso de memoria más eficiente, pasa un objeto de datos como un singleton a fin de compartirlo entre varios DoFn. Para obtener más información, consulta la entrada de blog Reutilización de caché en DoFn.
Usa representaciones de elementos con eficiencia de memoria
Evalúa si puedes usar representaciones para elementos PCollection que usan menos memoria. Cuando uses codificadores en tu canalización, considera no solo codificar representaciones, sino también decodificar los elementos PCollection. Las matrices dispersas a menudo pueden beneficiarse de este tipo de optimización.
Reduce el tamaño de las entradas complementarias
Si tus DoFn usan entradas complementarias, reduce el tamaño de la entrada complementaria. Para las entradas complementarias que son colecciones de elementos, considera usar vistas iterables, como AsIterable o AsMultimap, en lugar de vistas que materializan toda la entrada complementaria al mismo tiempo, como AsList.
Reduce la cantidad de subprocesos
Puedes aumentar la memoria disponible por subproceso reduciendo la cantidad máxima de subprocesos que ejecutan instancias DoFn. Este cambio reduce el paralelismo, pero hace que haya más memoria disponible para cada DoFn.
En la siguiente tabla, se muestra la cantidad predeterminada de subprocesos que crea Dataflow:
| Tipo de trabajo | Python SDK | SDKs de Java/Go |
|---|---|---|
| Lote | 1 subproceso por CPU virtual | 1 subproceso por CPU virtual |
| Transmisión con Runner v2 | 12 subprocesos por CPU virtual | 500 subprocesos por VM de trabajador |
| Transmisión sin Runner v2 | 12 subprocesos por CPU virtual | 300 subprocesos por VM de trabajador |
Para reducir la cantidad de subprocesos del SDK de Apache Beam, establece la siguiente opción de canalización:
Java
Usa la opción de canalización --numberOfWorkerHarnessThreads.
Python
Usa la opción de canalización --number_of_worker_harness_threads.
Go
Usa la opción de canalización --number_of_worker_harness_threads.
Para los trabajos por lotes, establece el valor en un número que sea menor que la cantidad de CPU virtuales.
En el caso de los trabajos de transmisión, comienza por reducir el valor a la mitad del valor predeterminado. Si este paso no mitiga el problema, sigue reduciendo el valor a la mitad y observa los resultados en cada paso. Por ejemplo, cuando uses Python, prueba con los valores 6, 3 y 1.
Usa un tipo de máquina con más memoria por CPU virtual
Para seleccionar un trabajador con más memoria por CPU virtual, usa uno de los siguientes métodos.
- Usa un tipo de máquina con alta capacidad de memoria en la familia de máquinas de uso general. Los tipos de máquinas con alta capacidad de memoria tienen más memoria por CPU virtual que los tipos de máquinas estándar. El uso de un tipo de máquina con alta capacidad de memoria aumenta la memoria disponible para cada trabajador y la memoria disponible por subproceso, ya que la cantidad de CPU virtuales sigue siendo la misma. Como resultado, usar un tipo de máquina con alta capacidad de memoria puede ser una forma rentable de seleccionar un trabajador con más memoria por CPU virtual.
- Para obtener más flexibilidad cuando se especifica la cantidad de CPU virtuales y de memoria, puedes usar un tipo personalizado de máquina. Con los tipos personalizados de máquinas, puedes aumentar la memoria en incrementos de 256 MB. El precio de estos tipos de máquinas es diferente al de los tipos estándar.
- Algunas familias de máquinas te permiten usar tipos personalizados de máquinas con memoria extendida. La memoria extendida habilita una proporción más alta de memoria por CPU virtual. El costo es más alto.
Para establecer tipos de trabajadores, usa la siguiente opción de canalización. Si deseas obtener más información, consulta Configura las opciones de canalización y Opciones de canalización.
Java
Usa la opción de canalización --workerMachineType.
Python
Usa la opción de canalización --machine_type.
Go
Usa la opción de canalización --worker_machine_type.
Usa solo un proceso del SDK de Apache Beam
Para las canalizaciones de transmisión de Python y las canalizaciones de Python que usan Runner v2, puedes forzar a Dataflow a que inicie solo un proceso del SDK de Apache Beam por trabajador. Antes de probar esta opción, intenta resolver el problema con los otros métodos. Si deseas configurar las VMs de trabajador de Dataflow para que inicien solo un proceso en Python en contenedor, usa la siguiente opción de canalización:
--experiments=no_use_multiple_sdk_containers
Con esta configuración, las canalizaciones de Python crean un proceso del SDK de Apache Beam por trabajador. Esta configuración evita que los objetos y datos compartidos se repliquen varias veces para cada proceso del SDK de Apache Beam. Sin embargo, limita el uso eficiente de los recursos de procesamiento disponibles en el trabajador.
Reducir la cantidad de procesos del SDK de Apache Beam a uno no siempre reduce la cantidad total de subprocesos iniciados en el trabajador. Además, tener todos los subprocesos en un solo proceso del SDK de Apache Beam puede hacer que el procesamiento lento o la canalización se detenga. Por lo tanto, es posible que también debas reducir la cantidad de subprocesos, como se describe en la sección Reduce la cantidad de subprocesos en esta página.
También puedes forzar a los trabajadores a usar solo un proceso del SDK de Apache Beam mediante el uso de un tipo de máquina con solo una CPU virtual.
Información sobre el uso de memoria de Dataflow
Para solucionar problemas de memoria insuficiente, es útil comprender cómo las canalizaciones de Dataflow usan la memoria.
Cuando Dataflow ejecuta una canalización, el procesamiento se distribuye entre varias máquinas virtuales (VMs) de Compute Engine, que a menudo se denominan trabajadores.
Los trabajadores procesan los elementos de trabajo del servicio de Dataflow y delega los elementos de trabajo a los procesos del SDK de Apache Beam. Un proceso del SDK de Apache Beam crea instancias de DoFn. DoFn es una clase del SDK de Apache Beam que define una función de procesamiento distribuido.
Dataflow inicia varios subprocesos en cada trabajador, y la memoria de cada trabajador se comparte en todos los subprocesos. Un subproceso es una única tarea ejecutable que se ejecuta dentro de un proceso más grande. La cantidad predeterminada de subprocesos depende de varios factores y varía entre los trabajos por lotes y de transmisión.
Si tu canalización necesita más memoria que la cantidad predeterminada de memoria disponible en los trabajadores, es posible que encuentres errores de memoria.
Las canalizaciones de Dataflow usan la memoria de un trabajador de tres maneras:
Memoria operativa del trabajador
Los trabajadores de Dataflow necesitan memoria para sus sistemas operativos y procesos del sistema. El uso de memoria del trabajador no suele superar 1 GB. El uso suele ser inferior a 1 GB.
- Varios procesos en el trabajador usan la memoria para garantizar que tu canalización esté en orden. Cada uno de estos procesos puede reservar una pequeña cantidad de memoria para su operación.
- Cuando tu canalización no usa Streaming Engine, los procesos de trabajadores adicionales usan la memoria.
Memoria del proceso del SDK
Los procesos del SDK de Apache Beam pueden crear objetos y datos que se comparten entre subprocesos dentro del proceso, denominados en esta página como objetos y datos compartidos del SDK. El uso de memoria de estos objetos y datos compartidos del SDK se conoce como memoria de proceso del SDK. En la siguiente lista, se incluyen ejemplos de objetos y datos compartidos del SDK:
- Datos de entrada adicionales
- Modelos de aprendizaje automático
- Objetos singleton en la memoria
- Objetos de Python creados con el
módulo
apache_beam.utils.shared - Datos cargados desde fuentes externas, como Cloud Storage o BigQuery
Los trabajos de transmisión que no usan Streaming Engine almacenan entradas complementarias en la memoria. Para las canalizaciones de Java y Go, cada trabajador tiene una copia de la entrada complementaria. Para las canalizaciones de Python, cada proceso del SDK de Apache Beam tiene una copia de la entrada complementaria.
Los trabajos de transmisión que usan Streaming Engine tienen un límite de tamaño de entrada lateral de 80 MB. Las entradas complementarias se almacenan fuera de la memoria del trabajador.
El uso de memoria de los objetos y datos compartidos del SDK crece de forma lineal con la cantidad de procesos del SDK de Apache Beam. En las canalizaciones de Java y Go, se inicia un proceso del SDK de Apache Beam por trabajador. En las canalizaciones de Python, se inicia un proceso del SDK de Apache Beam por CPU virtual. Los objetos y datos compartidos del SDK se vuelven a usar en subprocesos dentro del mismo proceso del SDK de Apache Beam.
DoFn uso de memoria
DoFn es una clase del SDK de Apache Beam que define una función de procesamiento distribuido.
Cada trabajador puede ejecutar instancias de DoFn en simultáneo. Cada subproceso ejecuta una instancia DoFn. Cuando evalúas el uso total de la memoria, calcular el tamaño del conjunto de trabajo o la cantidad de memoria necesaria para que una aplicación continúe funcionando, puede ser útil. Por ejemplo, si una DoFn individual usa un máximo de 5 MB de memoria y un trabajador tiene 300 subprocesos, el uso de memoria DoFn puede alcanzar un máximo de 1.5 GB o la cantidad de bytes de memoria multiplicada por la cantidad de subprocesos. Según cómo los trabajadores usen la memoria, un aumento repentino en el uso podría provocar que los trabajadores se queden sin memoria.
Es difícil estimar cuántas instancias de un DoFn que Dataflow crea. La cantidad depende de varios factores, como el SDK, el tipo de máquina, etcétera. Además, varios subprocesos seguidos pueden usar DoFn.
El servicio de Dataflow no garantiza cuántas veces se invoca un DoFn ni garantiza la cantidad exacta de instancias de DoFn creadas en el transcurso de una canalización.
Sin embargo, la siguiente tabla proporciona estadísticas sobre el nivel de paralelismo que puedes esperar y estima un límite superior en la cantidad de instancias DoFn.
SDK de Beam para Python
| Lote | Transmisión sin Streaming Engine | Streaming Engine | |
|---|---|---|---|
| Paralelismo |
1 proceso por CPU virtual 1 subproceso por proceso 1 subproceso por CPU virtual
|
1 proceso por CPU virtual 12 subprocesos por proceso 12 subprocesos por CPU virtual |
1 proceso por CPU virtual 12 subprocesos por proceso 12 subprocesos por CPU virtual
|
Cantidad máxima de instancias DoFn simultáneas (todas estas cantidades están sujetas a cambios en cualquier momento). |
1 DoFn por subproceso
1
|
1 DoFn por subproceso
12
|
1 DoFn por subproceso
12
|
SDK de Beam para Java/Go
| Lote | Streaming Appliance y Streaming Engine sin el ejecutor v2 | Streaming Engine con Runner v2 | |
|---|---|---|---|
| Paralelismo |
1 proceso por VM de trabajador 1 subproceso por CPU virtual
|
1 proceso por VM de trabajador 300 subprocesos por proceso 300 subprocesos por VM de trabajador
|
1 proceso por VM de trabajador 500 subprocesos por proceso 500 subprocesos por VM de trabajador
|
Cantidad máxima de instancias DoFn simultáneas (todas estas cantidades están sujetas a cambios en cualquier momento). |
1 DoFn por subproceso
1
|
1 DoFn por subproceso
300
|
1 DoFn por subproceso
500
|
Por ejemplo, cuando se usa el SDK de Python con un trabajador de Dataflow n1-standard-2, se aplica lo siguiente:
- Trabajos por lotes: Dataflow inicia un proceso por CPU virtual (dos en este caso). Cada proceso usa un subproceso, y cada subproceso crea una instancia
DoFn. - Trabajos de transmisión con Streaming Engine: Dataflow inicia un proceso por CPU virtual (dos en total). Sin embargo, cada proceso puede generar hasta 12 subprocesos, cada uno con su propia instancia de DoFn.
Cuando diseñas canalizaciones complejas, es importante comprender el ciclo de vida de DoFn.
Asegúrate de que tus funciones DoFn sean serializables y evita modificar el argumento del elemento directamente dentro de ellas.
Cuando tienes una canalización de varios lenguajes y más de un SDK de Apache Beam se ejecuta en el trabajador, este usa el menor grado de paralelismo por proceso de cada posible.
Diferencias entre Java, Go y Python
Java, Go y Python administran los procesos y la memoria de manera diferente. Como resultado, el enfoque que debes adoptar cuando solucionas los problemas de errores de memoria varía según si tu canalización usa Java, Go o Python.
Canalizaciones de Java y Go
En canalizaciones de Java y Go:
- Cada trabajador inicia un proceso del SDK de Apache Beam.
- Los objetos y datos compartidos del SDK, como entradas complementarias y cachés, se comparten entre todos los subprocesos del trabajador.
- Por lo general, la memoria que usan los datos y los objetos compartidos del SDK no se escala en función de la cantidad de CPU virtuales en el trabajador.
Canalizaciones de Python
En las canalizaciones de Python:
- Cada trabajador inicia un proceso del SDK de Apache Beam por CPU virtual.
- Los objetos y datos compartidos del SDK, como las entradas y las memorias caché, se comparten entre todos los subprocesos de cada proceso del SDK de Apache Beam.
- La cantidad total de subprocesos en el trabajador escala de manera lineal en función de la cantidad de CPU virtuales. Como resultado, la memoria que usan los objetos compartidos y los datos del SDK crece de manera lineal con la cantidad de CPU virtuales.
- Los subprocesos que realizan el trabajo se distribuyen entre los procesos. Las unidades de trabajo nuevas se asignan a un proceso sin elementos de trabajo o al proceso con la menor cantidad de elementos de trabajo asignados actualmente.