このページでは、パイプライン コードから Dataflow ジョブまでのパイプラインのライフサイクルの概要について説明します。
このページでは、次のコンセプトについて説明します。
- 実行グラフの概要と、Apache Beam パイプラインが Dataflow ジョブになる仕組み
- Dataflow によるエラーの処理方法
- Dataflow がパイプラインの処理ロジックを自動的に並列化し、ジョブを実行するワーカーに分散する方法
- Dataflow によるジョブの最適化
実行グラフ
Dataflow パイプラインを実行すると、Dataflow はすべての変換とそれらの関連する処理関数(DoFn オブジェクトなど)を含む Pipeline オブジェクトを作成するコードから実行グラフを作成します。パイプラインの実行グラフで、フェーズはグラフの作成時間と呼ばれます。
グラフの作成中、Apache Beam はパイプライン コードのメインエントリ ポイントからコードをローカルで実行して、ソース、シンク、変換ステップの呼び出しで停止し、これらの呼び出しをグラフのノードに変換します。したがって、パイプラインのエントリ ポイント(Java と Go の main メソッド、または Python スクリプトのトップレベル)のコードの一部は、パイプラインを実行するマシンのローカルで実行されます。DoFn オブジェクトのメソッドで宣言された同じコードは Dataflow ワーカーで実行されます。
たとえば、Apache Beam SDK に含まれる WordCount サンプルには、テキストのコレクション内の個々の単語と各単語のオカレンスの読み取り、抽出、カウント、書式設定、書き込みを行う一連の変換が含まれます。次の図は、WordCount パイプライン内の変換が実行グラフにどのように展開されるかを示しています。
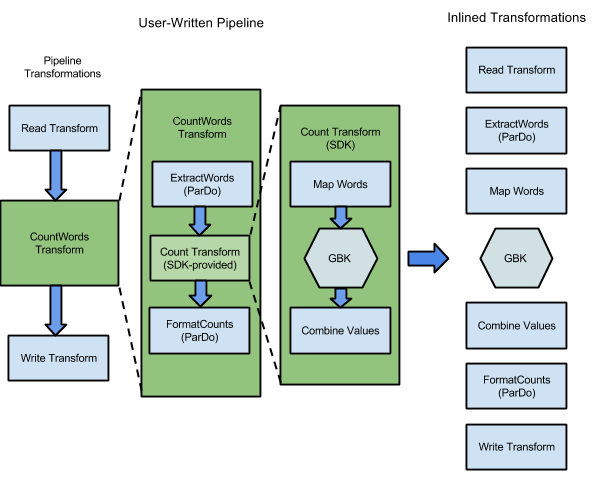
図 1: WordCount サンプルの実行グラフ
多くの場合、実行グラフは、パイプラインの作成時に変換を指定した順序とは異なります。この相違は、Dataflow サービスが管理対象のクラウド リソースに対して実行される前に実行グラフに対してさまざまな最適化と融合を実行することが要因です。Dataflow サービスは、パイプラインの実行時にデータの依存関係を尊重します。ただし、相互にデータの依存関係がないステップは、任意の順序で実行できます。
Dataflow がパイプラインに対して生成した最適化されていない実行グラフを表示するには、Dataflow モニタリング インターフェースでジョブを選択します。ジョブの表示の詳細については、Dataflow モニタリング インターフェースを使用するをご覧ください。
グラフ作成中に、Apache Beam は、パイプラインによって参照されるリソース(Cloud Storage バケット、BigQuery テーブル、Pub/Sub トピック、サブスクリプションなど)が実際に存在し、アクセス可能であることを検証します。検証は、各サービスに対する標準 API 呼び出しを通じて行われるため、パイプラインの実行に使用されるユーザー アカウントに必要なサービスへの適切な接続が確立され、サービスの API を呼び出す権限があることが不可欠です。パイプラインを Dataflow サービスに送信する前に、Apache Beam は他のエラーもチェックし、パイプライン グラフに不正なオペレーションが含まれていないことを確認します。
実行グラフは JSON 形式に変換され、JSON 実行グラフは Dataflow サービス エンドポイントに転送されます。
Dataflow サービスは、JSON 実行グラフを検証します。グラフが検証されると、Dataflow サービスでジョブになります。Dataflow モニタリング インターフェースを使用して、ジョブ、その実行グラフ、ステータス、ログ情報を参照できます。
Java
Dataflow サービスは、Dataflow プログラムが実行されたマシンにレスポンスを送信します。このレスポンスは、Dataflow ジョブの jobId を含むオブジェクト DataflowPipelineJob にカプセル化されます。jobId を使用して、Dataflow モニタリング インターフェースと Dataflow コマンドライン インターフェースを使用して、ジョブのモニタリング、追跡、トラブルシューティングを行います。詳細については、DataflowPipelineJob の API リファレンスをご覧ください。
Python
Dataflow サービスは、Dataflow プログラムが実行されたマシンにレスポンスを送信します。このレスポンスは、Dataflow ジョブの job_id を含むオブジェクト DataflowPipelineResult にカプセル化されます。job_id を使用して、Dataflow モニタリング インターフェースと Dataflow コマンドライン インターフェースを使用して、ジョブのモニタリング、追跡、トラブルシューティングを行います。
Go
Dataflow サービスは、Dataflow プログラムが実行されたマシンにレスポンスを送信します。このレスポンスは、Dataflow ジョブの jobID を含むオブジェクト dataflowPipelineResult にカプセル化されます。jobID を使用して、Dataflow モニタリング インターフェースと Dataflow コマンドライン インターフェースを使用して、ジョブのモニタリング、追跡、トラブルシューティングを行います。
グラフ作成は、パイプラインをローカルで実行したときにも行われますが、グラフが JSON に変換される、またはサービスに転送されることはありません。代わりに、グラフは Dataflow プログラムを起動したのと同じマシンでローカルに実行されます。詳細については、ローカル実行用に PipelineOption を構成するをご覧ください。
エラーと例外の処理
データの処理中にパイプラインによって例外がスローされることがあります。これらのエラーのいくつかは、外部サービスにアクセスすることが一時的に困難であるなど、一過性のものです。その他のエラーは、破損した、または解析不能な入力データや計算中の null ポインタを原因とするエラーなど、永続的なものです。
バンドル内のいずれかの要素についてエラーがスローされた場合、Dataflow はそのバンドル内の要素を処理し、バンドル全体を再試行します。バッチモードで実行している場合、失敗した項目を含むバンドルは 4 回再試行されます。1 つのバンドルが 4 回失敗すると、パイプラインが完全に失敗します。ストリーミング モードで実行している場合、失敗した項目を含むバンドルは無期限に再試行され、パイプラインが恒久的に滞るおそれがあります。
バッチモードで処理している場合は、パイプライン ジョブが完全に失敗する(これは指定されたバンドルが 4 回の再試行後に失敗した場合に発生します)前に、個別の失敗が大量に発生する可能性があります。たとえば、パイプラインが 100 バンドルを処理しようとした場合、単一のバンドルが 4 回の失敗条件に達して終了するまで、Dataflow は個別の失敗を数百件生成する可能性があります。
起動ワーカーのエラー(ワーカーへのパッケージのインストールの失敗など)は一時的なものです。この場合、再試行が無期限に行われ、パイプラインが恒久的に滞るおそれがあります。
並列化と分散
Dataflow サービスは、パイプラインの処理ロジックを自動的に並列化し、ジョブを実行するために割り当てられたワーカーに分散します。Dataflow は、プログラミング モデルでの抽象化を使用して、並列処理機能を表します。たとえば、パイプラインの ParDo 変換により、Dataflow は並列で実行される複数のワーカーに処理コード(DoFn オブジェクトで表現)を自動的に分散します。
ジョブの並列処理には次の 2 つのタイプがあります。
水平並列処理は、パイプライン データが分割され、複数のワーカーで同時に処理される場合に実施されます。Dataflow ランタイム環境は、分散ワーカーのプールによって強化されています。プールに含まれるワーカーが多いほど、パイプラインの並列処理の実施可能性が高くなりますが、その構成ではコストも増大します。理論上、水平並列処理には上限がありません。ただし、Dataflow では、フリート全体のリソース使用量を最適化するために、ワーカープールを 4,000 個のワーカーに制限しています。
垂直並列処理は、パイプライン データが分割され、同じワーカーの複数の CPU コアで処理される場合に実施されます。各ワーカーは Compute Engine VM を使用しています。VM は複数のプロセスを実行して、すべての CPU コアを飽和させることができます。コア数が多い VM では垂直並列処理の実施可能性が高くなりますが、この構成ではコストが増大します。多くの場合にコア数が多いとメモリ使用量が増加するため、通常はコア数をメモリサイズに合わせてスケーリングします。コンピュータ アーキテクチャの物理的な制限により、垂直並列処理の上限は水平並列処理の上限よりもはるかに低くなります。
マネージド並列処理
デフォルトでは、Dataflow はジョブの並列処理を自動的に管理します。Dataflow は、CPU やメモリ使用量など、ジョブの実行時の統計情報をモニタリングして、ジョブのスケーリング方法を決定します。ジョブの設定に応じて、Dataflow はジョブを水平方向(水平自動スケーリング)または垂直方向(垂直スケーリング)にスケーリングできます。並列処理のために自動的にスケーリングすることで、ジョブの費用とパフォーマンスが最適化されます。
ジョブのパフォーマンスを向上させるため、Dataflow は内部でパイプラインも最適化します。一般的な最適化には、融合の最適化と結合の最適化があります。パイプライン ステップを融合することで、Dataflow は分散システムでステップを調整し、個別のステップを独立して実行する際に発生する不要なコストの発生を回避できます。
並列処理に影響する要因
次の要因は、Dataflow ジョブでの並列処理の効率に影響します。
入力ソース
入力ソースが並列処理を許可しない場合は、入力ソースの取り込みステップが Dataflow ジョブのボトルネックになる可能性があります。たとえば、単一の圧縮テキスト ファイルからデータを取り込む場合、Dataflow は入力データを並列化できません。ほとんどの圧縮形式は、取り込み時に任意のシャードに分割できないため、Dataflow はファイルの先頭から順次データを読み取る必要があります。パイプラインの並列化されていない部分によって、パイプラインの全体的なスループットが低下します。この問題を解決するには、よりスケーラブルな入力ソースを使用します。
場合によっては、ステップの融合によって並列処理も減少します。入力ソースが並列処理を許可していない場合は、Dataflow がデータ取り込みステップを後続のステップと融合し、この融合されたステップを単一のスレッドに割り当てると、パイプライン全体の実行速度が低下する可能性があります。
このシナリオを回避するには、入力ソースの取り込みステップの後に Redistribute ステップを挿入します。詳細については、このドキュメントの融合を防ぐセクションをご覧ください。
デフォルトのファンアウトとデータ形態
単一変換ステップのデフォルトのファンアウトは、ボトルネックになり、並列処理を制限する可能性があります。たとえば、「高ファンアウト」の ParDo 変換では、Dataflow がワーカー使用状況を最適化する能力が融合によって制限される可能性があります。このようなオペレーションでは、入力コレクションの要素が比較的少数でも、ParDo は数百または数千倍の要素数の出力を生成し、その後に別の ParDo が続くことがあります。Dataflow サービスでこれらの ParDo オペレーションが融合されると、中間 PCollection にさらに多くの要素が含まれている場合でも、このステップでの並列処理は入力コレクション内のアイテム数以下に制限されます。
考えられる解決策については、このドキュメントの融合を防ぐセクションをご覧ください。
データの形
データの形状(入力データまたは中間データ)によって、並列処理が制限される場合があります。たとえば、都市などの自然キーに対する GroupByKey ステップの後に map ステップまたは Combine ステップが続く場合、Dataflow は 2 つのステップを融合します。キースペースが小さい(例: 5 つの都市)場合や、1 つのキーが非常にホットである(例: 大都市)場合は、GroupByKey ステップの出力内のほとんどの項目が 1 つのプロセスに分散されます。このプロセスがボトルネックとなり、ジョブの実行速度が低下します。
この例では、自然なキーを使用する代わりに、GroupByKey ステップの結果をより大きな人工キースペースに再分配できます。GroupByKey ステップと map ステップまたは Combine ステップの間に Redistribute ステップを挿入します。Redistribute ステップで、hash 関数を使用するなどして人工的なキースペースを作成し、データ形態による並列処理の制限を克服します。
詳細については、このドキュメントの融合を防ぐセクションをご覧ください。
出力シンク
シンクは、ファイルやデータベースなどの外部データ ストレージ システムに書き込む変換です。実際には、シンクは標準の DoFn オブジェクトとしてモデル化および実装され、外部システムに PCollection を実体化するために使用されます。この場合、PCollection には最終的なパイプライン結果が含まれます。シンク API を呼び出すスレッドは、外部システムにデータを書き込むために並行して実行できます。デフォルトでは、スレッド間の調整は行われません。書き込みリクエストと制御フローをバッファリングする中間レイヤがないと、外部システムが過負荷になり、書き込みスループットが低下する可能性があります。並列処理を追加してリソースをスケールアップすると、パイプラインの実行速度がさらに低下する可能性があります。
この問題の解決策は、書き込みステップの並列処理を削減することです。書き込みステップの直前に GroupByKey ステップを追加できます。GroupByKey ステップは、出力データをより小さなバッチセットにグループ化して、外部システムへの合計 RPC 呼び出しと接続を低減します。たとえば、GroupByKey を使用して、100 万個のデータポイントのうち 50 個のハッシュ スペースを作成します。
この方法の欠点は、並列処理にハードコードされた制限が導入されることです。別の方法として、データを書き込むときにシンクに指数バックオフを実装することもできます。このオプションを使用すると、必要最小限のクライアント スロットリングを実現できます。
並列処理をモニタリングする
並列処理をモニタリングするには、 Google Cloud コンソールを使用して、検出されたストラガーを表示します。詳細については、バッチジョブのストラグラーのトラブルシューティングとストリーミング ジョブのストラグラーのトラブルシューティングをご覧ください。
融合の最適化
パイプライン実行グラフの JSON 形式が検証されると、Dataflow サービスは最適化を実行するためにグラフを修正する場合があります。最適化には、パイプラインの実行グラフ内の複数のステップまたは変換を単一のステップに融合することが含まれます。ステップを融合すると、Dataflow サービスはパイプラインの中間 PCollection をすべて実体化する必要がなくなります。実体化はメモリと処理のオーバーヘッドの点でコストが高くなることがあります。
パイプラインの作成で指定したすべての変換がサービスで実行されますが、パイプラインを最も効率よく実行するために、それらは異なる順序で実行される、または融合された、より大規模な変換の一部として実行される場合があります。Dataflow サービスは、実行グラフのステップ間のデータ依存関係を尊重しますが、それ以外ではステップが任意の順序で実行される可能性があります。
融合の例
次の図は、Apache Beam SDK for Java に含まれる WordCount サンプルの実行グラフを、効率的な実行のために Dataflow サービスによって最適化および融合する方法を示しています。
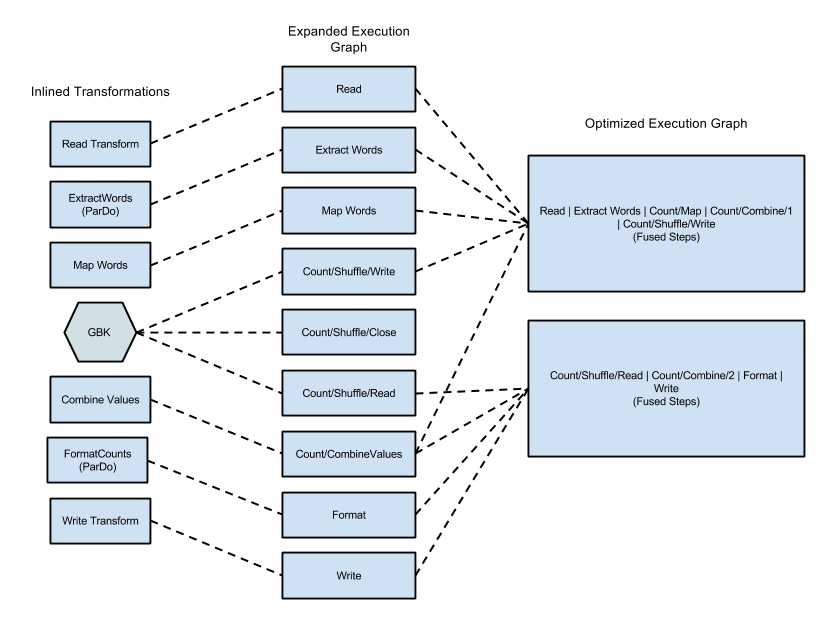
図 2: WordCount サンプルの最適化された実行グラフ
融合を防ぐ
場合によっては、Dataflow がパイプライン内のオペレーションを融合する最適な方法を誤って推測し、Dataflow が使用可能ワーカーを十分に利用できなくなる可能性があります。このような場合は、Redistribute 変換を使用して、データを再分散するように Dataflow にヒントを提供できます。
Redistribute 変換を追加するには、次のいずれかの方法を呼び出します。
Redistribute.arbitrarily: データのバランスが崩れている可能性が高いことを示します。Dataflow は、データを再分散するための最適なアルゴリズムを選択します。Redistribute.byKey: Key-Value ペアのPCollectionのバランスが崩れている可能性があり、キーに基づいて再分散する必要があることを示します。通常、Dataflow は単一キーのすべての要素を同じワーカー スレッドに配置します。ただし、キーのコロケーションは保証されず、要素は個別に処理されます。
パイプラインに Redistribute 変換が含まれている場合、通常、Dataflow は Redistribute 変換の前後のステップの融合を防ぎ、Redistribute 変換のダウンストリームのステップでより最適な並列処理が得られるようにデータをシャッフルします。
融合をモニタリングする
Google Cloud コンソール、gcloud CLI、または API を使用して、最適化されたグラフと融合ステージにアクセスできます。
コンソール
コンソールでグラフの融合ステージとステップを確認するには、Dataflow ジョブの [実行の詳細] タブで [ステージのワークフロー] グラフビューを開きます。
ステージに融合されたコンポーネント ステップを表示するには、グラフで融合ステージをクリックします。[ステージ情報] ペインの [コンポーネントのステップ] 行に融合ステージが表示されます。1 つの複合変換の一部分が複数のステージに融合される場合があります。
gcloud
gcloud CLI を使用して、最適化されたグラフと融合ステージにアクセスするには、次の gcloud コマンドを実行します。
gcloud dataflow jobs describe --full JOB_ID --format json
JOB_ID は、Dataflow ジョブの ID に置き換えます。
関連するビットを抽出するには、gcloud コマンドの出力を jq にパイプします。
gcloud dataflow jobs describe --full JOB_ID --format json | jq '.pipelineDescription.executionPipelineStage\[\] | {"stage_id": .id, "stage_name": .name, "fused_steps": .componentTransform }'
出力レスポンス ファイルの融合ステージの説明を表示するには、ComponentTransform 配列内の ExecutionStageSummary オブジェクトを確認します。
API
API を使用して、最適化されたグラフと融合ステージにアクセスするには、project.locations.jobs.get を呼び出します。
出力レスポンス ファイルの融合ステージの説明を表示するには、ComponentTransform 配列内の ExecutionStageSummary オブジェクトを確認します。
結合の最適化
集約オペレーションは、大規模なデータ処理における重要なコンセプトです。集約は、概念的に非常に異なるデータをまとめて、関連付けに極めて有用にします。Dataflow プログラミング モデルでは、集約オペレーションを GroupByKey、CoGroupByKey、Combine 変換として表します。
Dataflow の集約オペレーションは、データセット全体でデータを結合します。これには、複数のワーカーにわたって存在する可能性のあるデータも含まれます。多くの場合、このような集約オペレーション中に、インスタンスをまたがるデータを結合する前にデータをできるだけローカルに結合するのが最も効率的です。GroupByKey または他の集約変換を適用する場合、Dataflow サービスは、メインのグループ化オペレーションの前に部分的なローカル結合を自動的に実行します。
部分結合または複数レベル結合を実行する場合、Dataflow サービスはパイプラインがバッチデータとストリーミング データのどちらを操作するかに基づいて異なる決定を行います。制限付きデータの場合、サービスは効率性を重視し、できるだけローカルの結合を実行します。制限なしデータの場合、サービスは低レイテンシを重視し、部分結合は実行しない可能性があります(レイテンシが増加する可能性があるため)。