Dataflow 會收集作業的指標,協助您偵錯、排解效能問題,或最佳化管道。Dataflow 監控介面會顯示這些指標的視覺化資料。您也可以使用 Cloud Monitoring 建立快訊或建構指標探索工具查詢。
存取工作指標
如要查看工作的指標,請執行下列步驟:
在 Google Cloud 控制台中,依序前往「Dataflow」>「Jobs」(工作) 頁面。
選取職務。
按一下「工作指標」分頁標籤。
選取要查看的指標。
如要存取工作指標圖表中的其他資訊,請按一下「探索資料」。
每項指標都會整理到下列資訊主頁:
支援與限制
使用 Dataflow 指標時,請注意下列詳細資料。
有時工作資料會暫時無法使用。如果缺少資料,工作監控圖表就會出現間隙。
部分圖表專門用於串流管道。
如要寫入指標資料,使用者管理的服務帳戶必須具備 IAM API 權限
monitoring.timeSeries.create。此權限包含在 Dataflow 工作者角色中。Dataflow 服務會在工作完成後回報保留的 CPU 作業時間。對於無限制 (串流) 工作,只有在工作取消或失敗後,才會回報保留的 CPU 作業時間。因此,工作指標不會納入串流工作的保留 CPU 作業時間。
自動調度資源指標
自動水平調度資源功能可讓 Dataflow 為工作選擇適當的工作站執行個體數量,並視需要新增或移除工作站。
「工作指標」分頁的「自動調度資源」部分會顯示工作站數量和目標工作站數量隨時間的變化。如果工作使用 Streaming Engine,也會顯示工作站數量下限和上限。
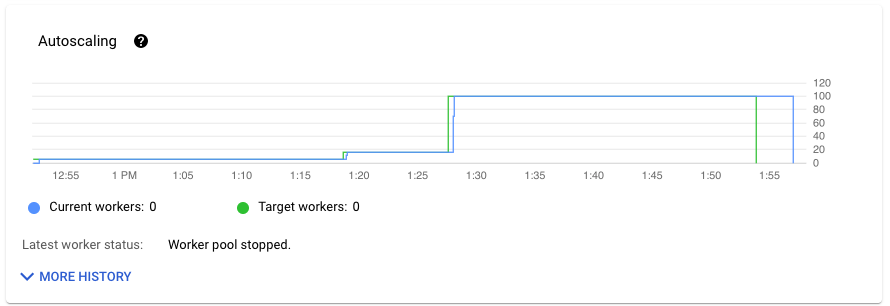
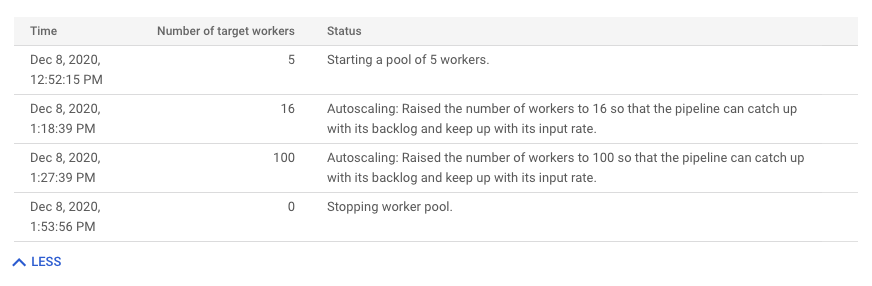
如要查看自動調度資源變更的記錄,請按一下「顯示詳細記錄」。系統會顯示表格,其中包含工作的工作站記錄資訊。
如要查看串流作業的自動調度資源資訊,請按一下「Autoscaling」(自動調度資源) 分頁標籤。詳情請參閱「監控 Dataflow 自動調度資源功能」。
總覽指標
下列指標會顯示在「總覽指標」下方。
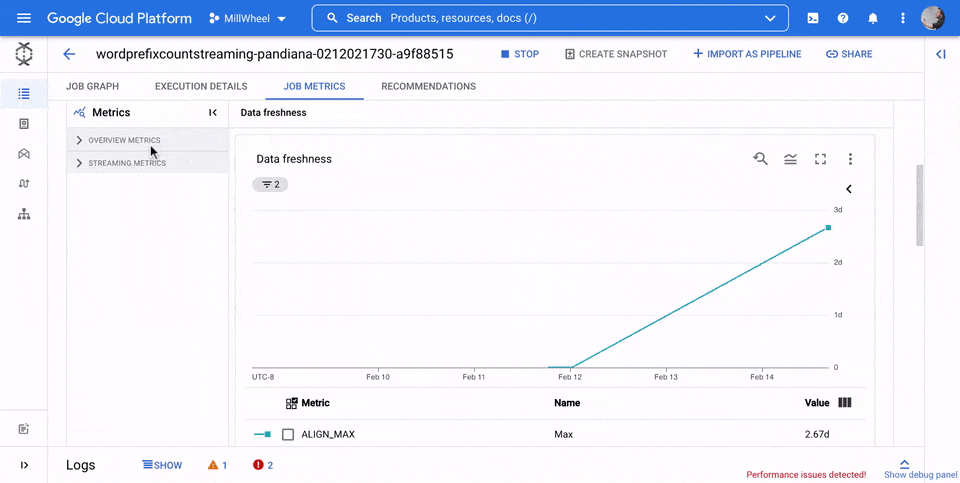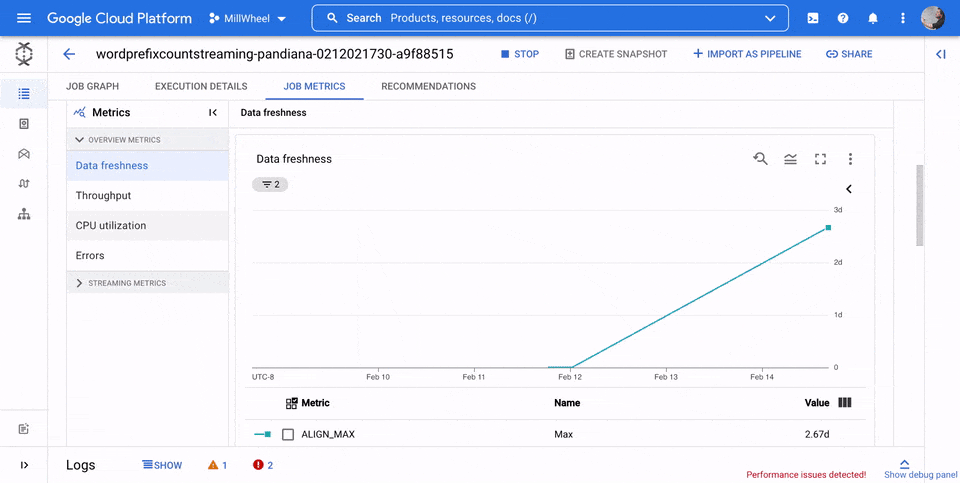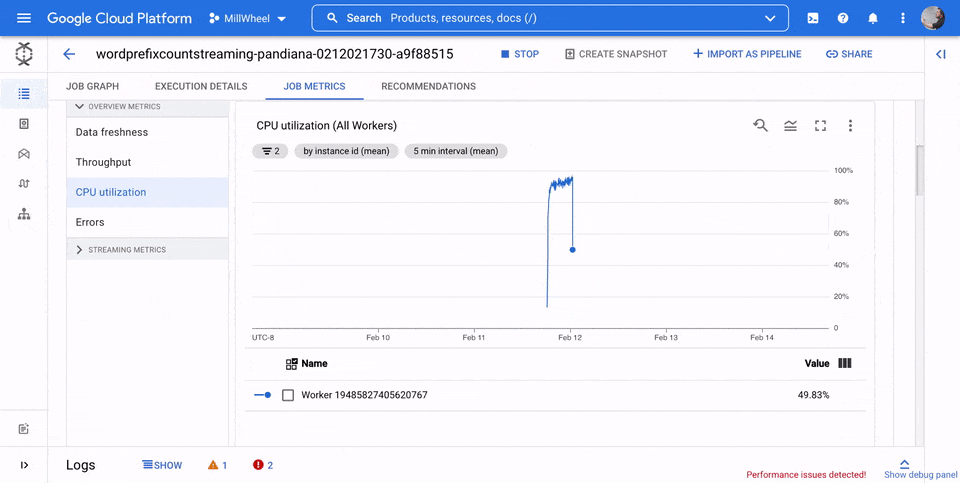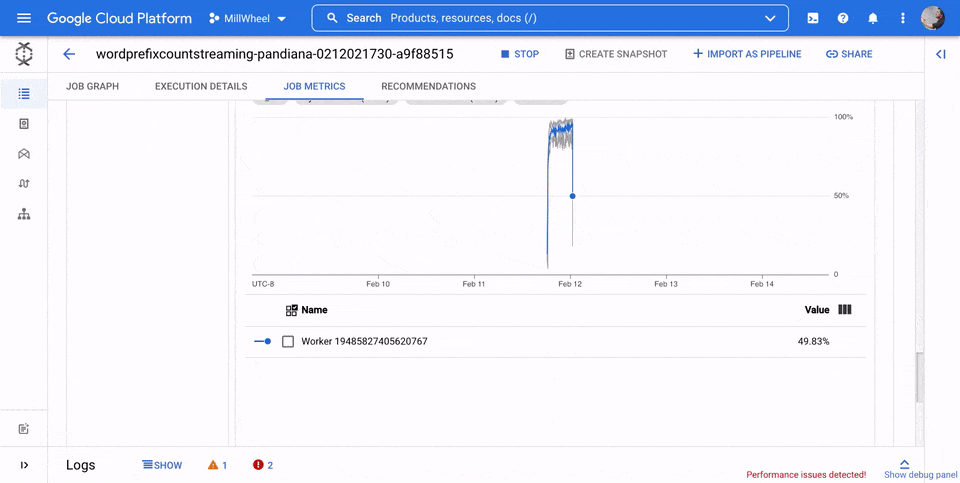
資料更新間隔
這項指標僅適用於串流工作。
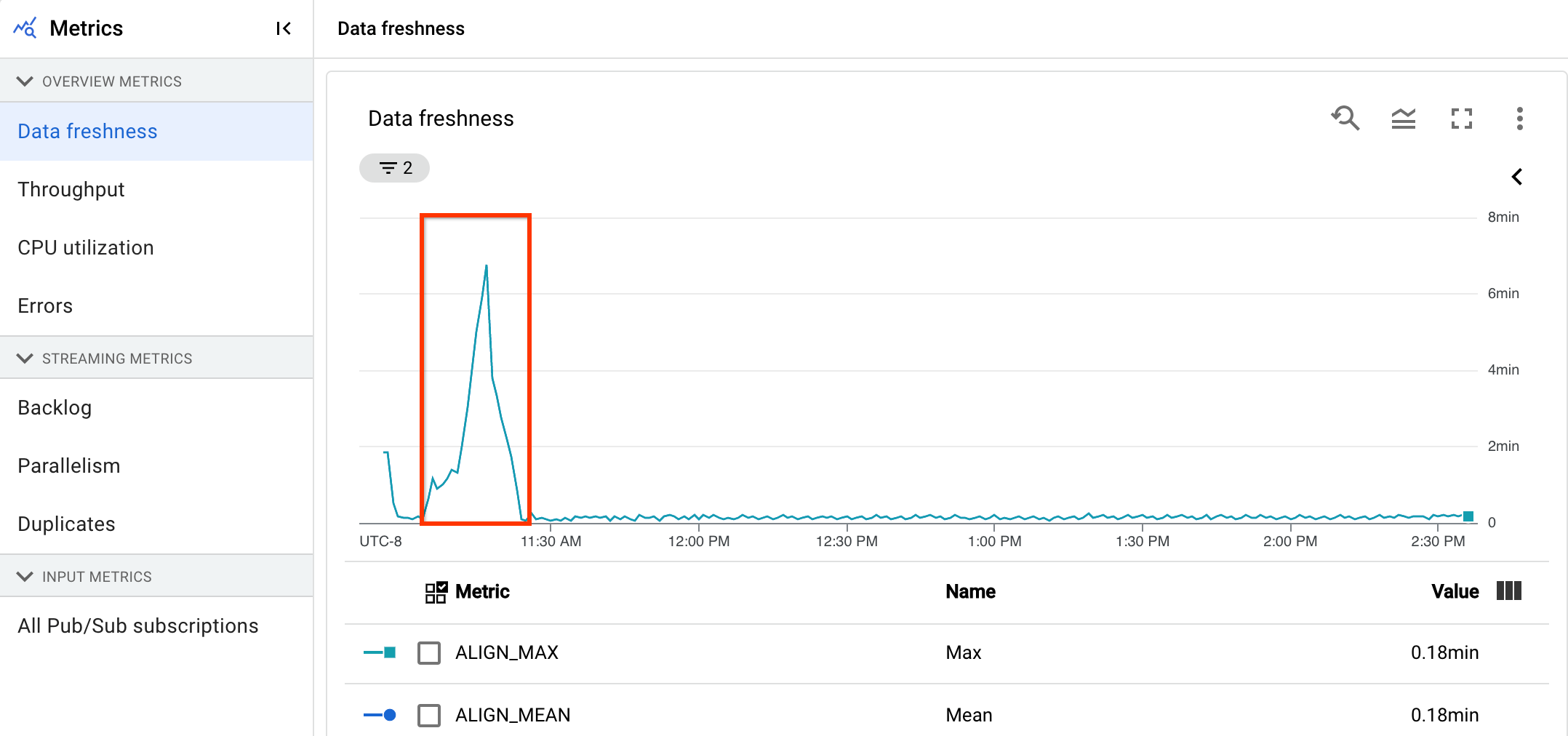
資料更新間隔是指資料元素處理時間與資料元素時間戳記 (事件時間) 之間的差異。值越高,表示事件時間與處理時間之間的延遲越長。
資料更新間隔圖表會顯示任何時間點的最大資料更新間隔值。Dataflow 會平行處理多個元素,因此圖表會反映相對於事件時間延遲最久的元素。
如果尚未處理某些輸入資料,則可能會延遲輸出浮水印,這會影響資料更新間隔。如果浮水印時間和事件時間差異很大,可能表示作業緩慢或停滯。詳情請參閱 Apache Beam 說明文件中的「Watermarks and late data」(浮水印和延遲資料)。
這個資訊主頁包含下列兩張圖表:
- 各個階段的資料更新間隔
- 資料更新間隔
在下圖中,醒目顯示的區域顯示事件時間與輸出浮水印時間之間有很大的差異,表示作業速度緩慢。
下列問題可能會導致這項指標的值偏高:
- 效能瓶頸:如果管道的階段具有高系統延遲或記錄指出轉換停滯,管道可能會有效能問題,進而導致資料新鮮度降低。如要進一步調查,請參閱「排解工作緩慢或停滯的問題」。
- 資料來源瓶頸:如果資料來源的待處理項目不斷增加,元素事件時間戳記可能會與浮水印不同步,因為這些項目需要等待處理。造成大量待處理工作的通常是效能瓶頸或資料來源問題,最好監控管道使用的來源來偵測這些問題。
- 無序來源 (例如 Pub/Sub) 即使以高速率輸出,仍可能產生停滯的水印。發生這種情況的原因是元素並非依時間戳記順序輸出,且浮水印是以未處理的最低時間戳記為準。
- 頻繁重試:如果看到任何錯誤,指出元素處理失敗並重試,則重試元素中的舊時間戳記可能會提高資料即時性。您可以參閱常見 Dataflow 錯誤清單,排解問題。
最近更新的串流工作可能無法提供工作狀態和浮水印資訊。更新作業所做的變更需要幾分鐘才會反映在 Dataflow 監控介面中。請嘗試在更新工作完成 5 分鐘後重新整理監控介面。
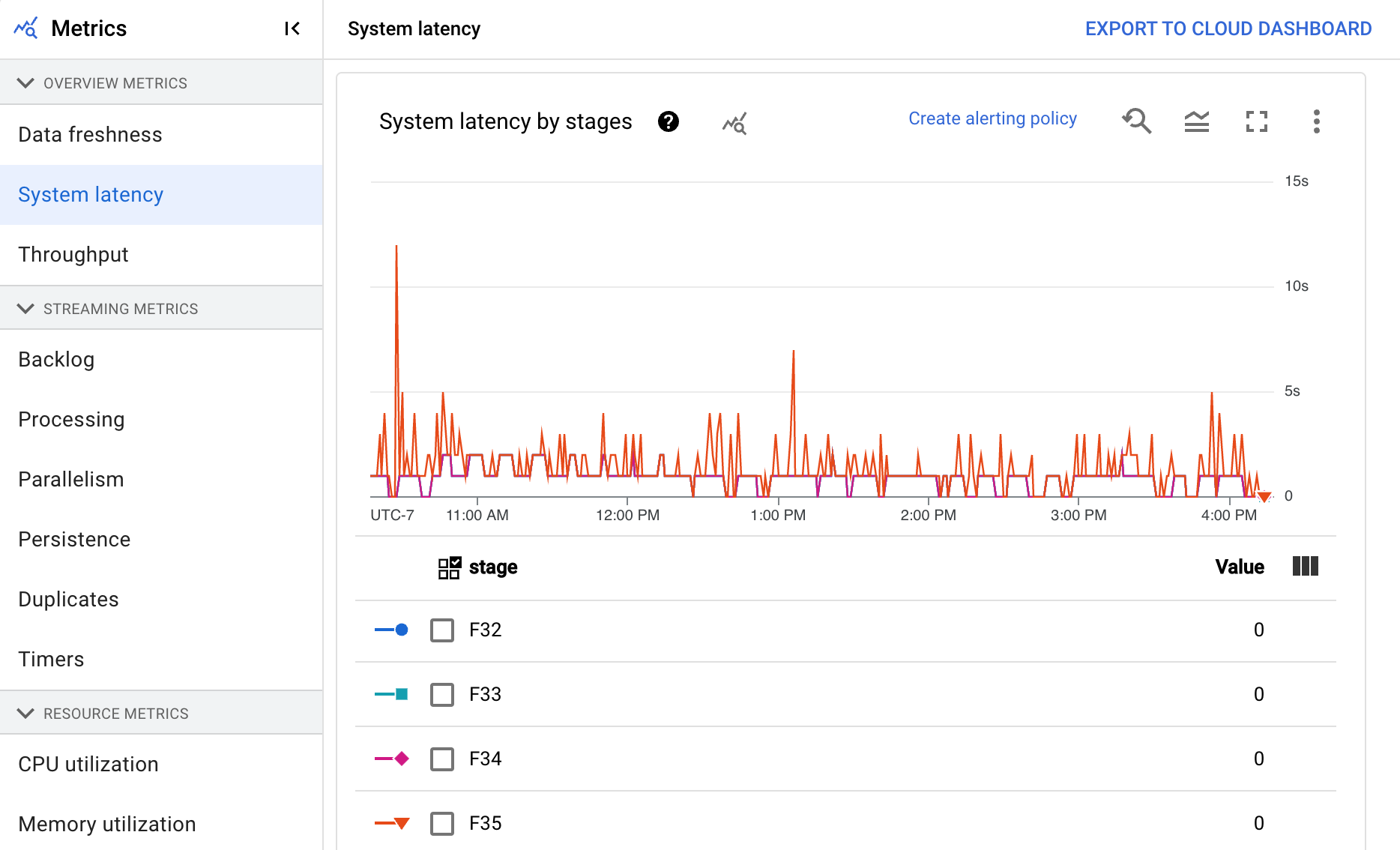
系統延遲時間
這項指標僅適用於串流工作。
系統延遲時間是資料項目目前處理或等待處理的最長時間 (以秒為單位)。這項指標包括元素在來源內等待的時間。舉例來說,如果輸出目的地暫時停止接受寫入要求,資料可能會累積在來源端,導致系統延遲時間增加。如果寫入作業恢復,且管道能夠趕上進度,系統延遲時間就會恢復到基準層級。
以下狀況是其他需要考量的地方:
- 如果有多個來源和接收器,系統延遲時間就是元素在寫入所有接收器之前,在來源中等待的最長時間。
- 有時,來源不會提供元素在來源中等待的時間值。此外,元素可能沒有中繼資料來定義其事件時間。在此情境下,系統延遲時間是從管道一開始收到該元素的時間開始計算。
這個資訊主頁包含下列兩張圖表:
- 各個階段的系統延遲時間
- 系統延遲時間
處理量
處理量是指在任何時間點處理的資料量。這個資訊主頁包含下列圖表:
- 每個步驟的處理量 (元素/秒)
- 每個步驟的處理量 (每秒位元組數)
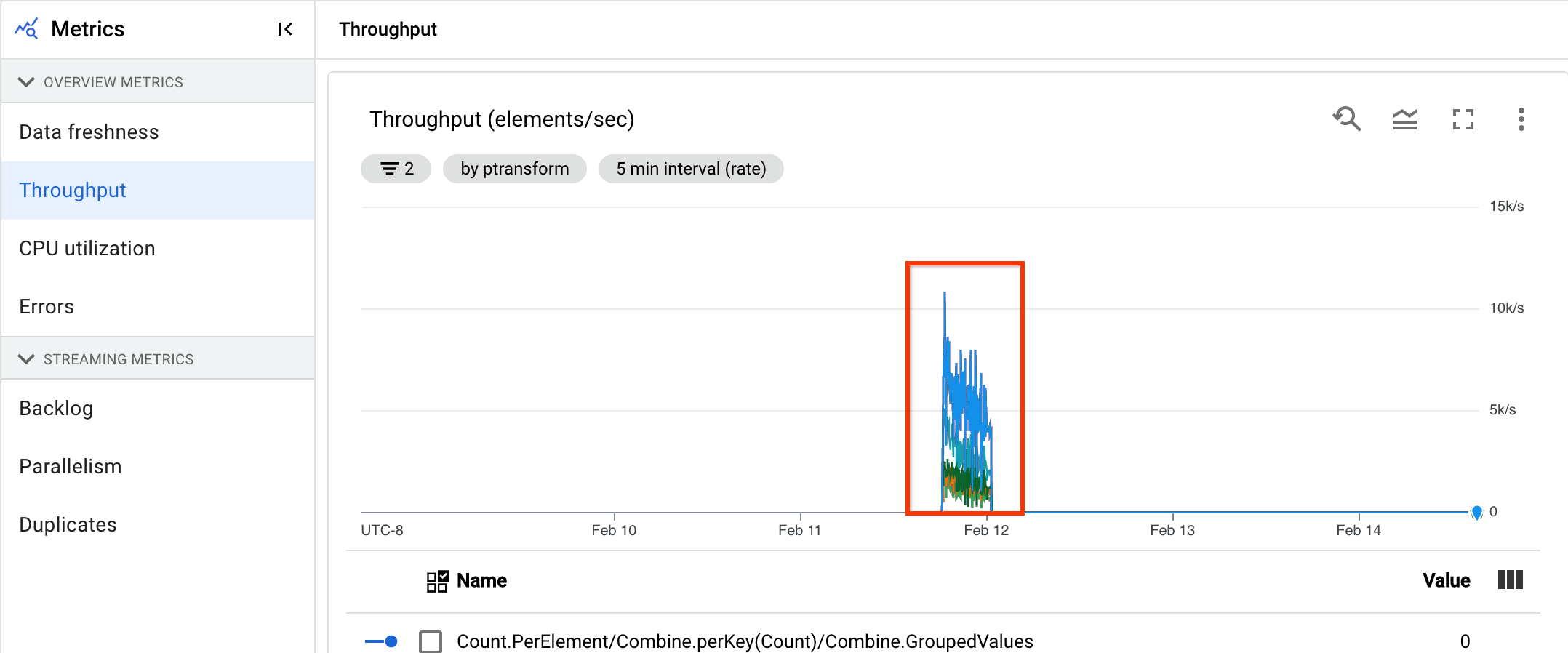
工作站的「錯誤」記錄項目數量
「工作站的『錯誤』記錄項目數量」會顯示任何時間點所有工作站的錯誤率。

串流指標
下列指標會顯示在「串流指標」下方。
待處理工作量
這項指標僅適用於串流工作。
「待處理事項」資訊主頁會提供待處理元素的相關資訊。這個資訊主頁包含下列兩張圖表:
- 待處理工作秒數 (僅限 Streaming Engine)
- 待處理位元組數 (使用和未使用 Streaming Engine)
「待處理工作秒數」圖表會預估在沒有新資料傳入,且處理量不變的情況下,完成目前待處理工作所需的秒數。預估待處理時間是根據輸入來源的處理量和待處理位元組計算得出,串流自動調度功能會使用這項指標,判斷擴充或縮減資源的時機。
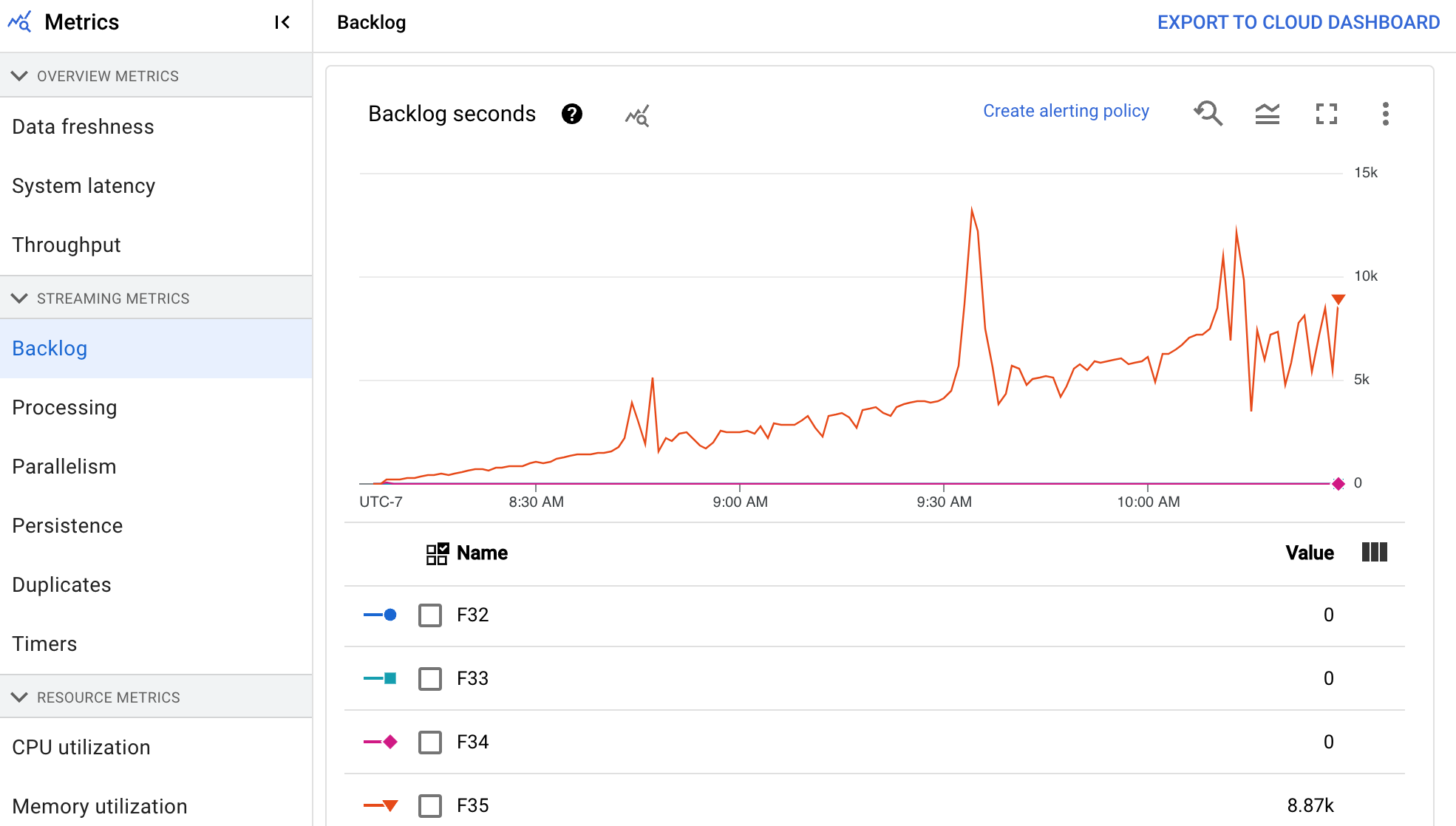
「待處理作業位元組」圖表會以位元組為單位,顯示階段中已知未處理的輸入量。這項指標會比較每個階段與上游階段的剩餘位元組數。如要讓這項指標準確回報資料,管道擷取的每個來源都必須正確設定。 系統已支援 Pub/Sub 和 BigQuery 等內建來源,但自訂來源需要額外實作。 詳情請參閱自訂無界來源的自動調度資源。
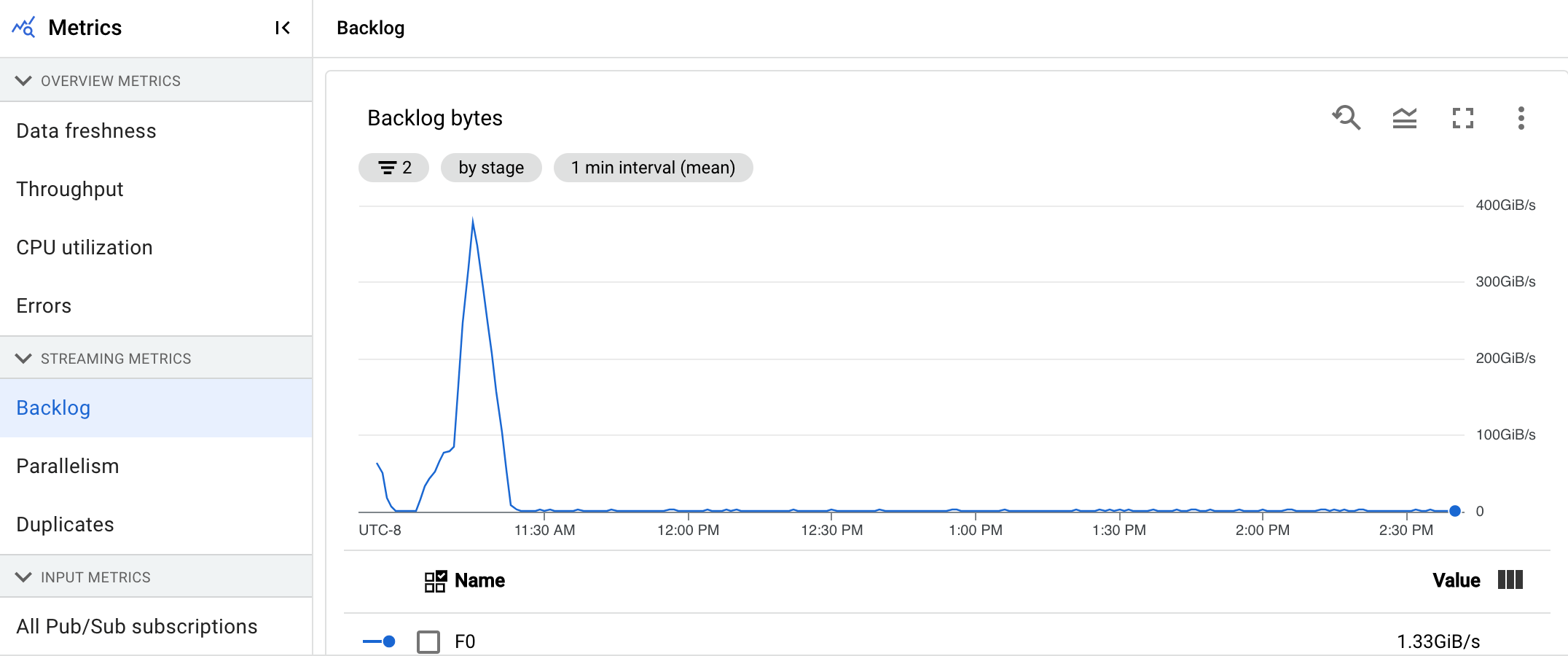
處理中
這項指標僅適用於串流工作。
在 Dataflow 服務上執行 Apache Beam 管道時,管道工作會在工作站 VM 上執行。「處理」資訊主頁會提供工作站 VM 處理工作所花費的時間資訊。這個資訊主頁包含下列兩張圖表:
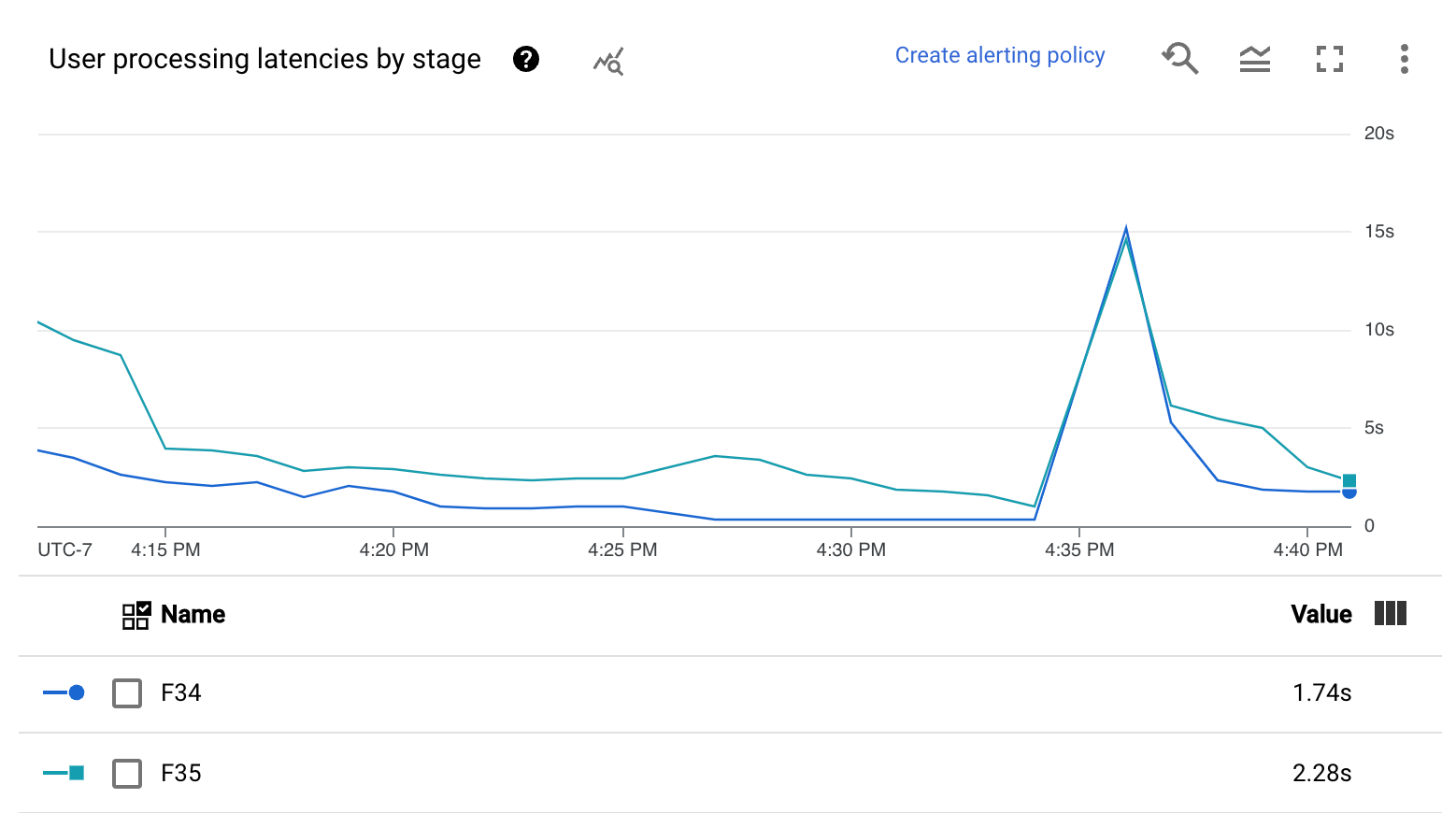
- 使用者處理延遲時間熱視圖
- 各個階段的使用者處理延遲時間
使用者處理延遲時間熱視圖顯示了分布情形為第 50、第 95 和第 99 個百分位數的最大作業延遲時間。使用熱視圖,查看是否有任何長尾作業導致整體系統延遲時間過長,或對整體資料更新間隔造成負面影響。
如要修正上游問題,避免問題蔓延至下游,請為第 50 個百分位數的高延遲設定警告政策。
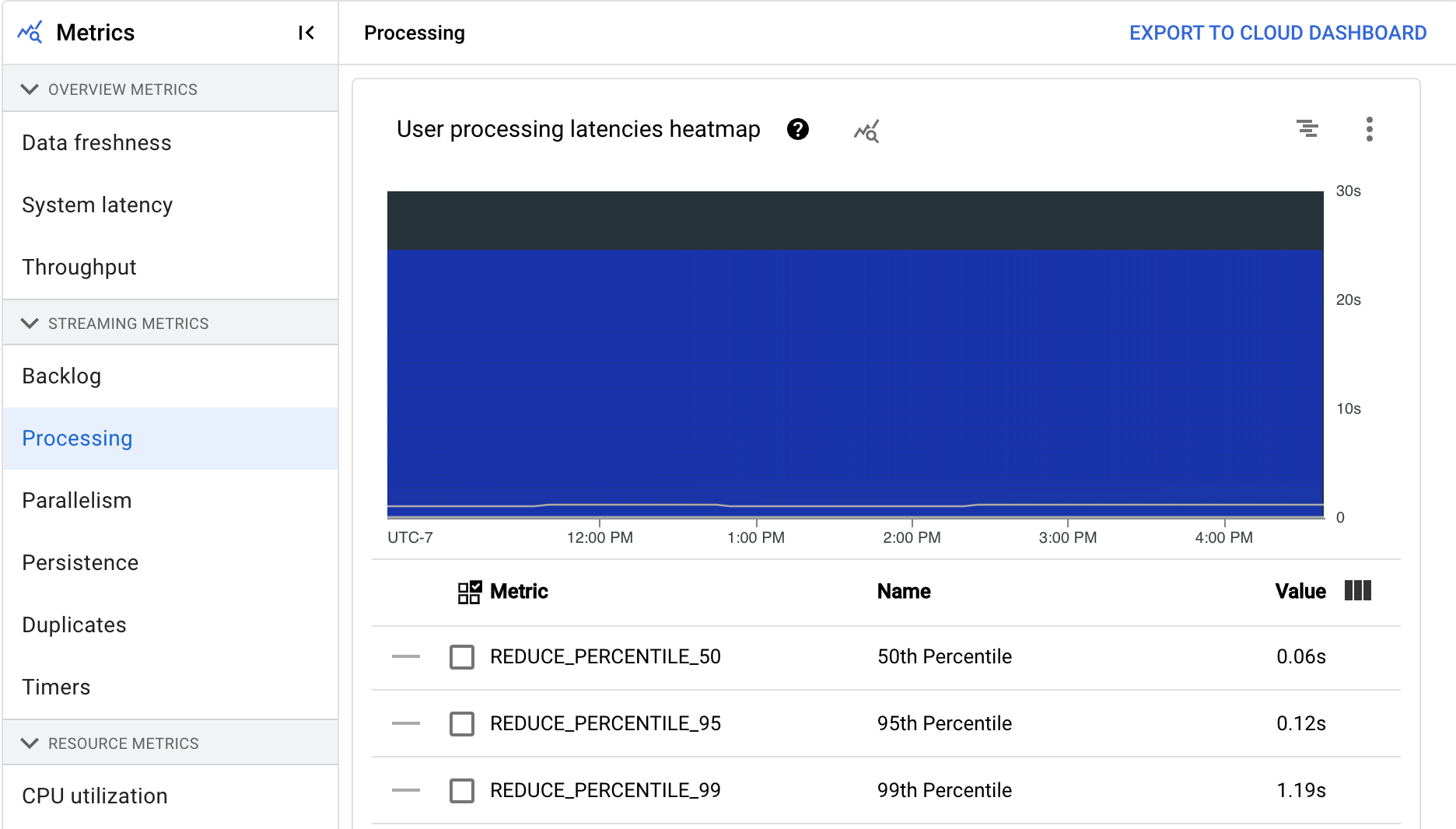
「各個階段的使用者處理延遲時間」圖表會顯示工作者處理的所有工作,以階段劃分的第 99 個百分位數。如果使用者程式碼造成瓶頸,這張圖表會顯示瓶頸所在的階段。您可以按照下列步驟對管道進行偵錯:
使用圖表找出延遲時間異常高的階段。
在工作詳細資料頁面的「執行詳細資料」分頁中,選取「圖表檢視」的「階段工作流程」。在「Stage workflow」(階段工作流程) 圖表中,找出延遲時間異常高的階段。
如要找出相關聯的使用者作業,請在圖表中按一下該階段的節點。
如要查看其他詳細資料,請前往 Cloud Profiler,並使用 Cloud Profiler 在正確的時間範圍內偵錯堆疊追蹤。找出您在上一個步驟中識別的使用者作業。
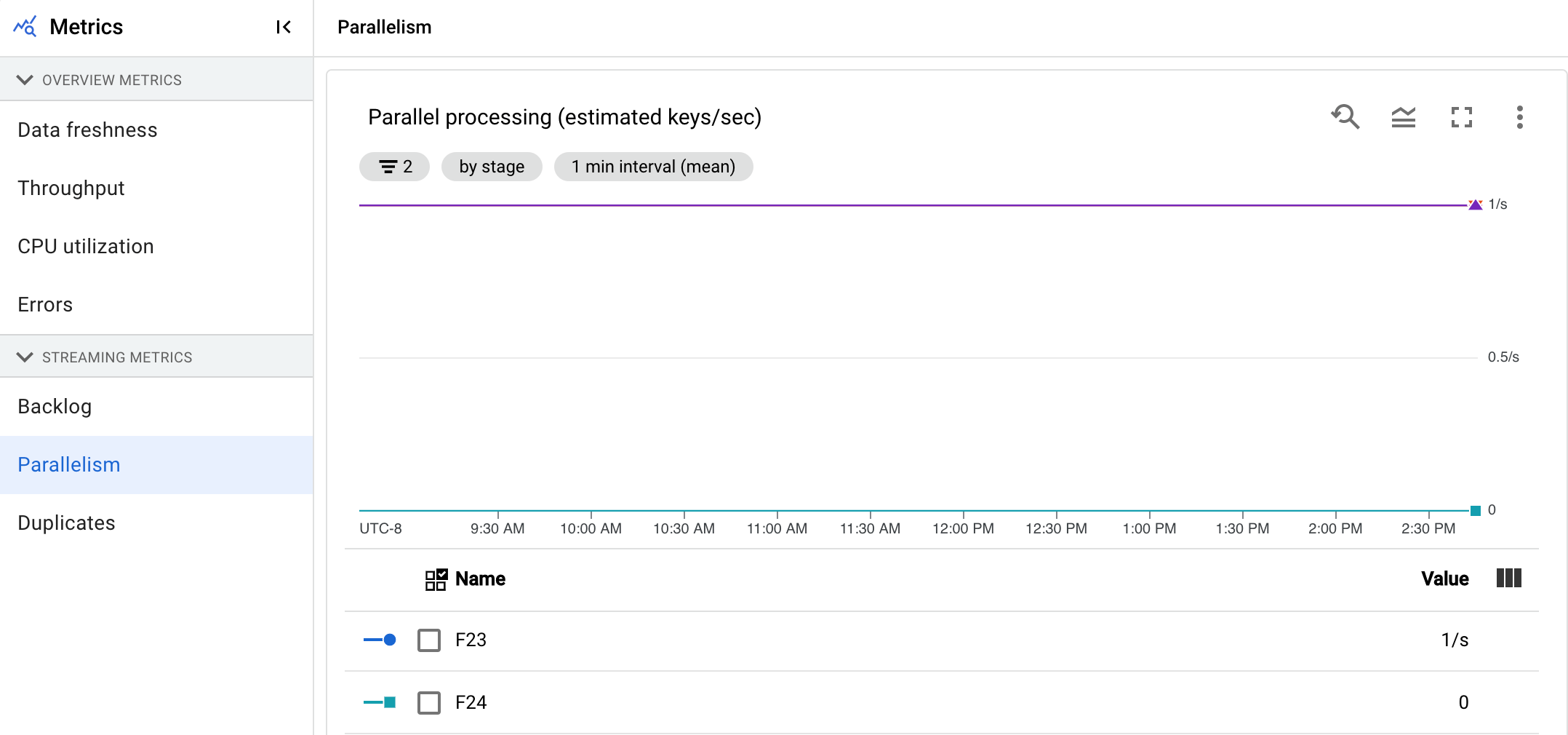
平行處理工作數量
這項指標僅適用於 Streaming Engine 工作。
「平行處理」圖表會顯示每個階段用於資料處理的索引鍵概略數量。Dataflow 會根據管道的平行處理程度調整規模。
Dataflow 執行管道時,處理作業會分配到多個 Compute Engine 虛擬機器 (VM),也就是工作站。Dataflow 服務會自動平行處理管道中的處理邏輯,並將處理邏輯分布到工作站。任何指定索引鍵的處理作業都會序列化,因此階段的索引鍵總數代表該階段可用的平行處理量上限。
平行處理指標有助於找出熱鍵或瓶頸,以解決管道速度緩慢或停滯的問題。
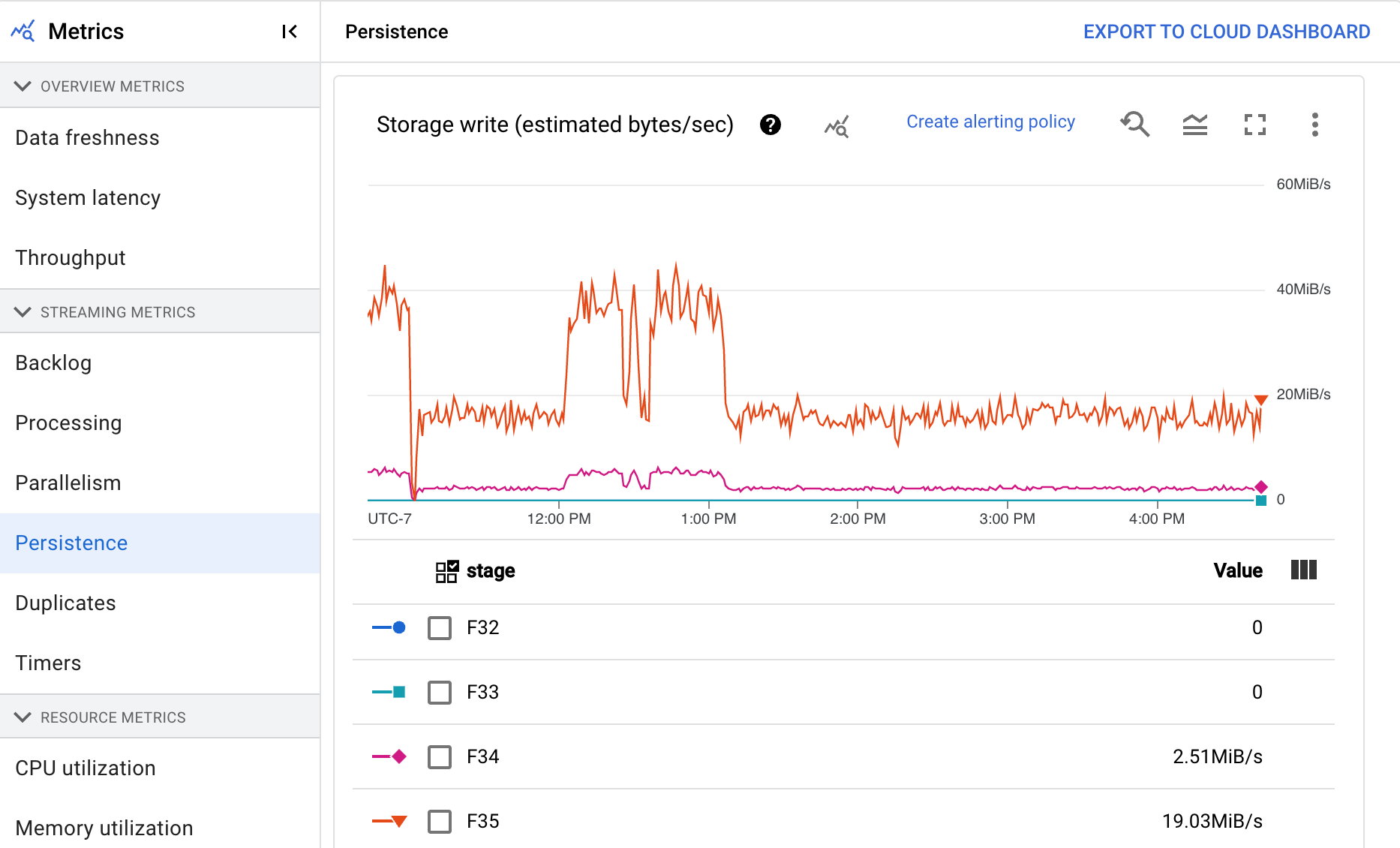
持續性
這項指標僅適用於串流工作。
「持續性」資訊主頁會提供特定管道階段寫入和讀取持續性儲存空間的速率資訊,單位為每秒位元組數。讀取和寫入的位元組包括使用者狀態作業,以及持續性隨機排序、移除重複項目、側邊輸入和水位線追蹤的狀態。管道編碼器和快取會影響讀取和寫入的位元組。由於內部儲存空間用量和快取,儲存空間位元組數可能與處理的位元組數不同。
這個資訊主頁包含下列兩張圖表:
- 儲存空間寫入
- 儲存空間讀取
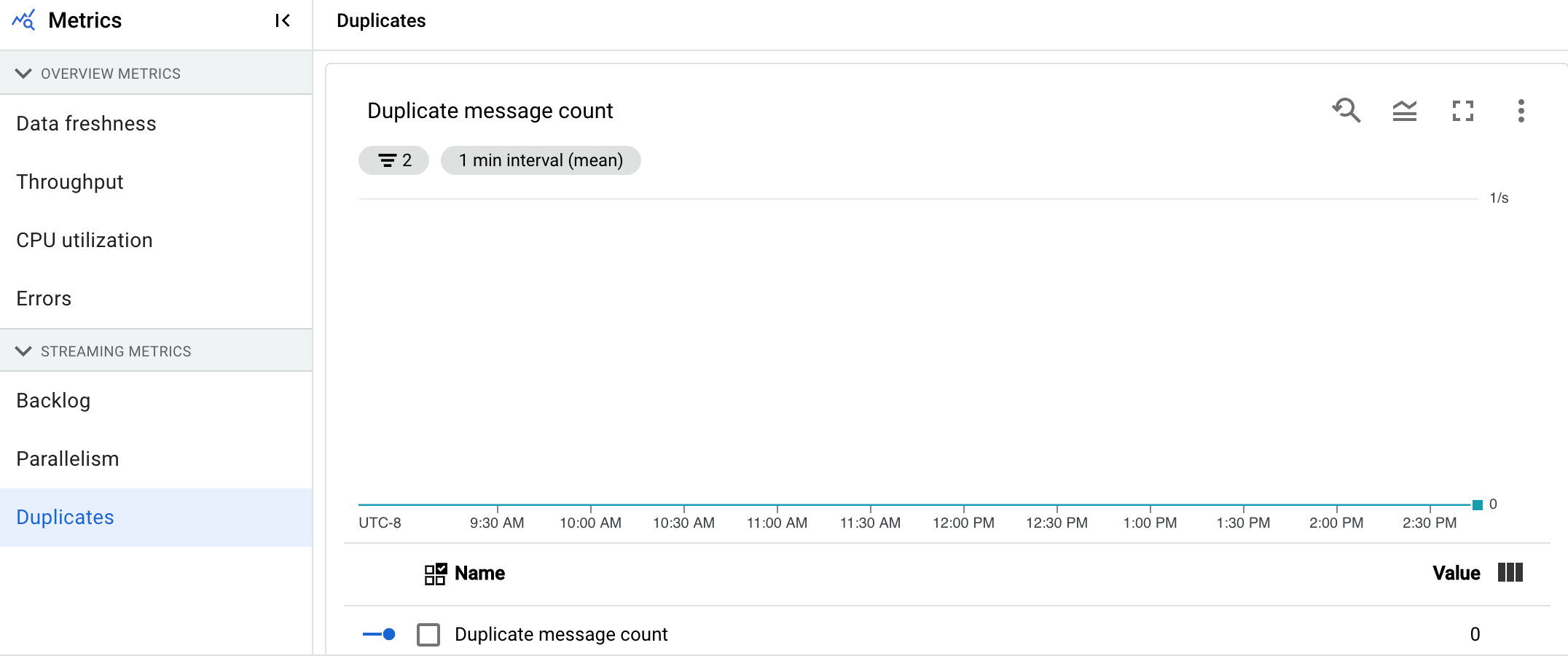
重複項目
這項指標僅適用於串流工作。
「重複」圖表會顯示特定階段處理的訊息數量,這些訊息已篩除為重複訊息。
Dataflow 支援許多來源和接收器,可確保 at least once 傳送資料。at least once 傳送的缺點是可能會導致重複。
Dataflow 可確保 exactly once 傳送,因此系統會自動篩除重複項目。下游階段會避免重新處理相同元素,確保狀態和輸出內容不受影響。
減少每個階段產生的重複項目數量,即可最佳化管道的資源和效能。
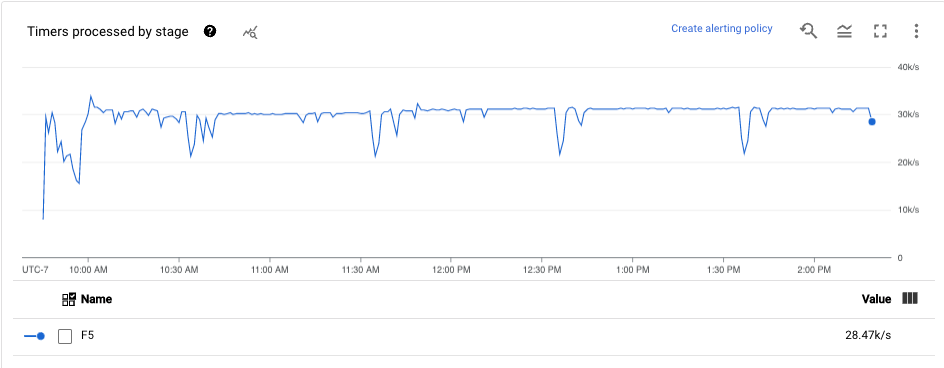
計時器
這項指標僅適用於串流工作。
「計時器」資訊主頁會顯示特定管道階段中待處理的計時器數量,以及已處理的計時器數量。由於視窗依賴計時器,因此這個指標可讓您追蹤視窗的進度。
這個資訊主頁包含下列兩張圖表:
- 依階段顯示的待處理計時器
- 依階段顯示的處理中計時器
這些圖表會顯示特定時間點的待處理或處理中視窗比率。「依階段顯示的待處理計時器」圖表會指出有多少個時間視窗因瓶頸而延遲。「依階段顯示的已處理計時器」圖表會指出有多少個時間區間正在收集元素。
這些圖表會顯示所有作業計時器,因此如果程式碼的其他位置也使用計時器,這些計時器也會顯示在圖表中。

資源指標
下列指標會顯示在「資源指標」下方。
CPU 使用率
CPU 使用率是指使用的 CPU 數量除以可供處理的 CPU 數量。這項指標會以百分比顯示。 這個資訊主頁包含下列四張圖表:
- CPU 使用率 (所有工作站)
- CPU 使用率 (統計資料)
- CPU 使用率 (最高的 4 項)
- CPU 使用率 (最低的 4 項)
記憶體使用率
記憶體使用率是指工作站每秒使用的預估記憶體量 (以位元組為單位)。這個資訊主頁包含下列兩張圖表:
- 工作站記憶體最高使用率 (每秒位元組數預估值)
- 記憶體使用率 (預估每秒位元組數)
「工作站記憶體最大用量」圖表會顯示 Dataflow 工作中,每個時間點使用最多記憶體的工作站。如果工作期間使用最多記憶體的工作站有所變更,圖表中的同一條線會顯示多個工作站的資料。折線圖中的每個資料點,都會顯示當時使用最多記憶體的工作站資料。這張圖表會比較工作站的預估記憶體用量與記憶體限制 (以位元組為單位)。
您可以運用這張圖表來找出記憶體不足 (OOM) 錯誤。這個圖表不會顯示工作站記憶體不足導致當機的事件。
「記憶體使用率」圖表會顯示 Dataflow 工作中所有工作站的預估記憶體用量,並與記憶體限制 (以位元組為單位) 比較。
輸入和輸出指標
如果串流 Dataflow 工作使用 Pub/Sub 讀取或寫入記錄,則「工作指標」分頁會顯示 Pub/Sub 讀取或寫入的指標。
系統會合併相同類型的所有輸入指標,以及所有輸出指標。 舉例來說,所有 Pub/Sub 指標都會歸類在同一節中。 每個指標類型都會整理到不同的區段。如要變更顯示的指標,請在左側選取最能代表所需指標的區段。 下圖顯示所有可用的區段。
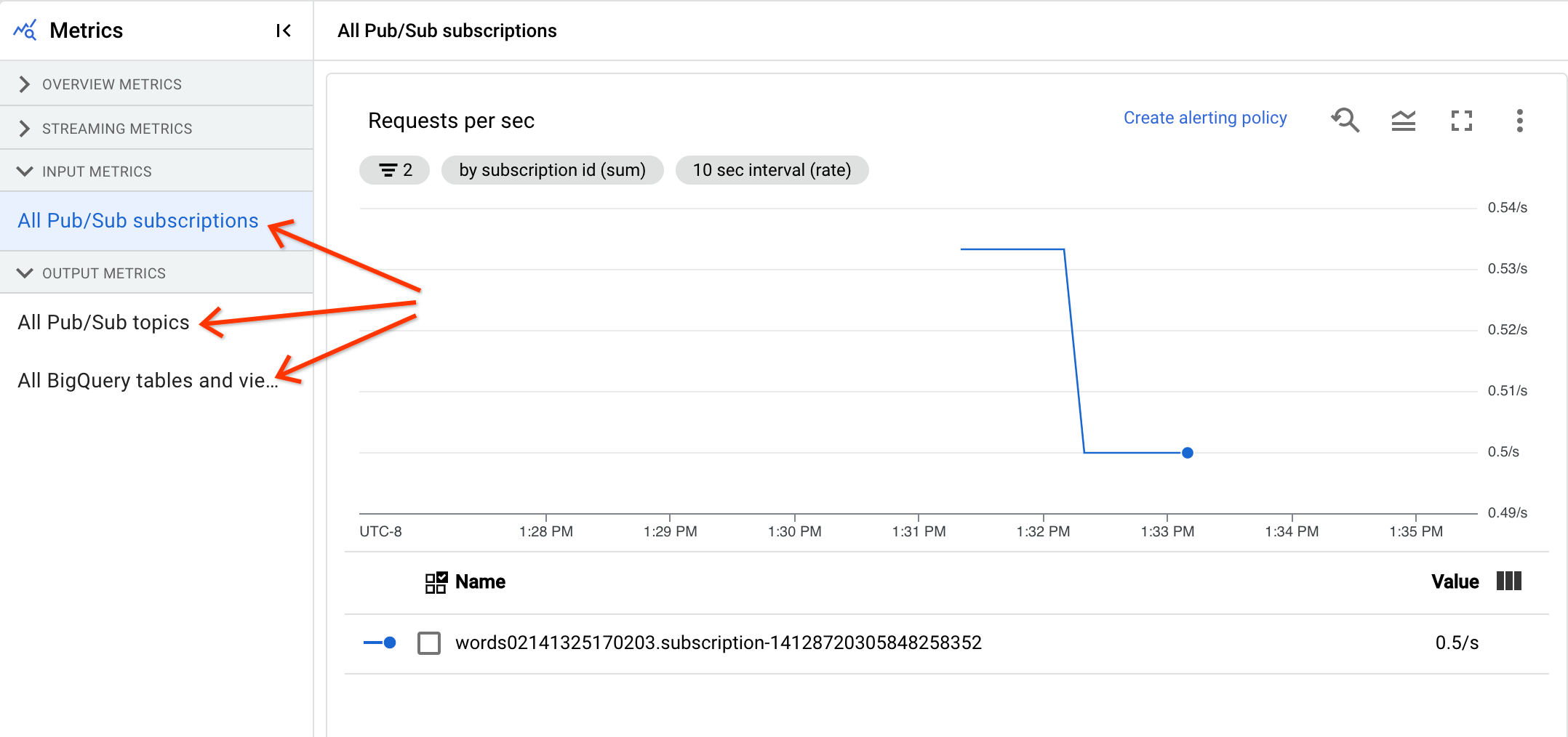
「輸入指標」和「輸出指標」部分都會顯示下列兩張圖表。
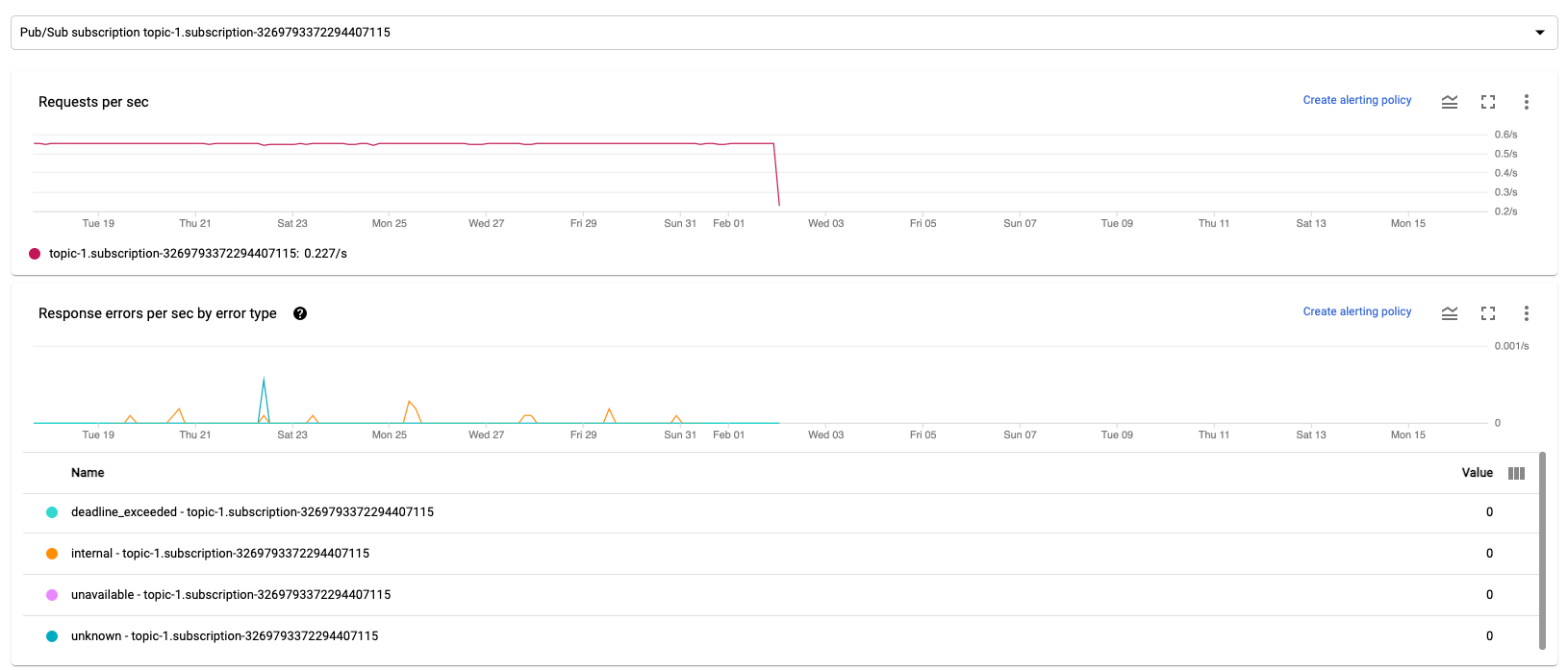
每秒要求數
每秒要求數是指來源或接收器在一段時間內讀取或寫入資料的 API 要求頻率。如果這個比率降至零,或相較於預期行為,在一段時間內大幅降低,則管道可能無法執行特定作業。此外,也可能沒有可讀取的資料。在這種情況下,請檢查系統浮水印較高的工作步驟。此外,請檢查工作站記錄檔是否有錯誤,或處理速度緩慢的跡象。

各錯誤類型的每秒回應錯誤
「各錯誤類型的每秒回應錯誤」是指一段時間內,來源或接收器讀取或寫入資料時,API 要求失敗的比率。如果這類錯誤頻繁發生,API 要求可能會減緩處理速度。您必須調查這類失敗的 API 要求。 如要排解這類問題,請參閱一般輸入和輸出錯誤代碼。此外,請一併查看來源或接收器使用的任何特定錯誤代碼文件,例如 Pub/Sub 錯誤代碼。

如要進一步瞭解可使用這些指標進行偵錯的情境,請參閱「排解工作緩慢或停滯的問題」一文中的「偵錯工具」。
使用 Cloud Monitoring
Dataflow 與 Cloud Monitoring 完全整合。您可以使用 Cloud Monitoring 執行下列工作:
- 在工作超過使用者定義的門檻時建立快訊。
- 使用 Metrics Explorer 建立查詢,並調整指標的時間範圍。
- 查看未顯示在 Dataflow 監控介面中的指標。
如需建立快訊和使用 Metrics Explorer 的操作說明,請參閱「使用 Cloud Monitoring 監控 Dataflow 管道」一文。
如需完整的 Dataflow 指標清單,請參閱Google Cloud 指標說明文件。
建立 Cloud Monitoring 快訊
如果 Dataflow 工作超過使用者定義的門檻,Cloud Monitoring 可讓您建立快訊。如要從指標圖表建立 Cloud Monitoring 快訊,請按一下「建立快訊政策」。
如果無法查看監控圖表或建立快訊,可能需要額外的監控權限。
在 Metrics Explorer 中查看
您可以在 Metrics Explorer 中查看 Dataflow 指標圖表,並建構查詢及調整指標的時間範圍。
如要在 Metrics Explorer 中查看 Dataflow 圖表,請在「Job metrics」檢視畫面中開啟「More chart options」,然後按一下「View in Metrics Explorer」。
調整指標的時間範圍時,您可以選取預先定義的持續時間,或選取自訂時間間隔來分析工作。
根據預設,對於串流工作和進行中的批次工作,顯示畫面會顯示該工作過去六小時的指標。對於已停止或完成的串流工作,預設顯示畫面會顯示工作持續時間的整個執行時間。
Dataflow I/O 指標
您可以在 Metrics Explorer 中查看下列 Dataflow I/O 指標:
job/pubsub/write_count:Dataflow 工作中 PubsubIO.Write 的 Pub/Sub 發布要求。job/pubsub/read_count:Dataflow 工作中 PubsubIO.Read 的 Pub/Sub 提取要求。job/bigquery/write_count:Dataflow 作業中 BigQueryIO.Write 的 BigQuery 發布要求。 在 Apache Beam 2.28.0 以上版本中,如果啟用method='STREAMING_INSERTS',Python 管道就能使用 WriteToBigQuery 轉換的job/bigquery/write_count指標。這項指標適用於批次和串流管道。- 如果管道使用 BigQuery 來源或接收器,請使用 BigQuery Storage API 指標排解配額問題。
DoFn 指標
針對使用 Streaming Engine 且不使用 Runner v2 的串流工作,您可以查看個別使用者定義 DoFns 的下列指標:
job/dofn_latency_average:過去 3 分鐘內,單一DoFn的平均訊息處理時間 (以毫秒為單位)。job/dofn_latency_max:過去 3 分鐘內,單一DoFn的訊息處理時間上限 (以毫秒為單位)。job/dofn_latency_min:過去 3 分鐘內,單一DoFn的最短訊息處理時間 (以毫秒為單位)。job/dofn_latency_num_messages: 單一DoFn在過去 3 分鐘內處理的訊息數量。job/dofn_latency_total:過去 3 分鐘內,單一DoFn中所有訊息的訊息處理總時間 (以毫秒為單位)。job/oldest_active_message_age:最舊的現有訊息在DoFn中處理的時間長度 (以毫秒為單位)。
如要使用這些指標,請使用 Apache Beam SDK 2.53.0 以上版本。如要查看這些指標,請使用 Metrics Explorer。
您可以根據這些指標,找出哪些 DoFns 最容易導致工作處理延遲。舉例來說,如果工作停滯,請使用 job/oldest_active_message_age 指標找出具有最舊有效訊息的 DoFn。下圖顯示 DoFn,這項指標出現大幅尖峰:

如要查看 DoFn 的名稱,請將指標懸停在圖表線上。