Ringkasan
Anda dapat menggunakan pipeline data Dataflow untuk tugas berikut:
- Buat jadwal tugas berulang.
- Pahami tempat sumber daya dibelanjakan selama beberapa eksekusi tugas.
- Menentukan dan mengelola tujuan keaktualan data.
- Lihat perincian setiap tahap pipeline untuk memperbaiki dan mengoptimalkan pipeline Anda.
Untuk dokumentasi API, lihat referensi Data Pipelines.
Fitur
- Buat pipeline batch berulang untuk menjalankan tugas batch sesuai jadwal.
- Buat pipeline batch inkremental berulang untuk menjalankan tugas batch terhadap versi terbaru data input.
- Gunakan kartu skor ringkasan pipeline untuk melihat penggunaan kapasitas gabungan dan konsumsi resource pipeline.
- Melihat keaktualan data pipeline streaming. Metrik ini, yang berkembang seiring waktu, dapat dikaitkan dengan pemberitahuan yang memberi tahu Anda saat keaktualan turun di bawah tujuan yang ditentukan.
- Gunakan grafik metrik pipeline untuk membandingkan tugas pipeline batch dan menemukan anomali.
Batasan
Ketersediaan regional: Anda dapat membuat pipeline data di region Cloud Scheduler yang tersedia.
Kuota:
- Jumlah pipeline default per project: 500
Jumlah pipeline default per organisasi: 2.500
Kuota tingkat organisasi dinonaktifkan secara default. Anda dapat memilih untuk menggunakan kuota tingkat organisasi, dan jika Anda melakukannya, setiap organisasi dapat memiliki maksimal 2.500 pipeline secara default.
Label: Anda tidak dapat menggunakan label yang ditentukan pengguna untuk memberi label pada pipeline data Dataflow. Namun, saat Anda menggunakan kolom
additionalUserLabels, nilai tersebut diteruskan ke tugas Dataflow Anda. Untuk mengetahui informasi selengkapnya tentang cara penerapan label ke setiap tugas Dataflow, lihat Opsi pipeline.
Jenis pipeline data
Dataflow memiliki dua jenis pipeline data, streaming dan batch. Kedua jenis pipeline menjalankan tugas yang ditentukan dalam template Dataflow.
- Streaming data pipeline
- Pipeline data streaming menjalankan tugas streaming Dataflow segera setelah dibuat.
- Pipeline data batch
Pipeline data batch menjalankan tugas batch Dataflow sesuai jadwal yang ditentukan pengguna. Nama file input pipeline batch dapat diberi parameter untuk memungkinkan pemrosesan pipeline batch inkremental.
Pipeline batch inkremental
Anda dapat menggunakan placeholder tanggal dan waktu untuk menentukan format file input inkremental untuk pipeline batch.
- Placeholder untuk tahun, bulan, tanggal, jam, menit, dan detik dapat digunakan, dan
harus mengikuti
format
strftime(). Placeholder diawali dengan simbol persentase (%). - Pemformatan parameter tidak diverifikasi selama pembuatan pipeline.
- Contoh: Jika Anda menentukan "gs://bucket/Y" sebagai jalur input berparameter,
jalur tersebut dievaluasi sebagai "gs://bucket/Y", karena "Y" tanpa "%" di depannya
tidak dipetakan ke format
strftime().
- Contoh: Jika Anda menentukan "gs://bucket/Y" sebagai jalur input berparameter,
jalur tersebut dievaluasi sebagai "gs://bucket/Y", karena "Y" tanpa "%" di depannya
tidak dipetakan ke format
Pada setiap waktu eksekusi pipeline batch terjadwal, bagian placeholder dari jalur input dievaluasi ke tanggal dan waktu saat ini (atau bergeser waktu). Nilai tanggal dievaluasi menggunakan tanggal saat ini di zona waktu tugas terjadwal. Jika jalur yang dievaluasi cocok dengan jalur file input, file akan diambil untuk diproses oleh pipeline batch pada waktu yang dijadwalkan.
- Contoh: Pipeline batch dijadwalkan untuk berulang di awal setiap jam PST. Jika Anda memparameterisasi jalur input sebagai
gs://bucket-name/%Y-%m-%d/prefix-%H_%M.csv, pada 15 April 2021, pukul 18.00 PST, jalur input akan dievaluasi menjadigs://bucket-name/2021-04-15/prefix-18_00.csv.
Menggunakan parameter pergeseran waktu
Anda dapat menggunakan parameter pergeseran waktu + atau - menit atau jam.
Untuk mendukung pencocokan jalur input dengan tanggal & waktu yang dievaluasi yang
diubah sebelum atau setelah tanggal & waktu saat ini dari jadwal pipeline,
sertakan parameter ini dalam tanda kurung kurawal.
Gunakan format {[+|-][0-9]+[m|h]}. Pipeline batch terus berulang pada
waktu yang dijadwalkan, tetapi jalur input dievaluasi dengan
selisih waktu yang ditentukan.
- Contoh: Pipeline batch dijadwalkan untuk berulang di awal setiap jam PST. Jika Anda memparameterisasi jalur input sebagai
gs://bucket-name/%Y-%m-%d/prefix-%H_%M.csv{-2h}, pada 15 April 2021, pukul 18.00 PST, jalur input akan dievaluasi menjadigs://bucket-name/2021-04-15/prefix-16_00.csv.
Peran pipeline data
Agar operasi pipeline data Dataflow berhasil, Anda memerlukan peran IAM yang diperlukan, sebagai berikut:
Anda memerlukan peran yang sesuai untuk melakukan operasi:
Datapipelines.admin: Dapat melakukan semua operasi pipeline dataDatapipelines.viewer: Dapat melihat pipeline dan tugas dataDatapipelines.invoker: Dapat memanggil eksekusi tugas pipeline data (peran ini dapat diaktifkan menggunakan API)
Akun layanan yang digunakan oleh Cloud Scheduler harus memiliki peran
roles/iam.serviceAccountUser, baik akun layanan ditentukan pengguna maupun akun layanan default Compute Engine. Untuk mengetahui informasi selengkapnya, lihat Peran pipeline data.Anda harus dapat bertindak sebagai akun layanan yang digunakan oleh Cloud Scheduler dan Dataflow dengan diberi peran
roles/iam.serviceAccountUserdi akun tersebut. Jika Anda tidak memilih akun layanan untuk Cloud Scheduler dan Dataflow, akun layanan Compute Engine default akan digunakan.
Membuat pipeline data
Anda dapat membuat pipeline data Dataflow dengan dua cara:
Halaman penyiapan pipeline data: Saat Anda pertama kali mengakses fitur pipeline Dataflow di konsol Google Cloud , halaman penyiapan akan terbuka. Aktifkan API yang tercantum untuk membuat pipeline data.
Mengimpor tugas
Anda dapat mengimpor tugas batch atau streaming Dataflow yang didasarkan pada template klasik atau fleksibel dan menjadikannya pipeline data.
Di konsol Google Cloud , buka halaman Jobs Dataflow.
Pilih tugas yang telah selesai, lalu di halaman Detail Tugas, pilih +Impor sebagai pipeline.
Di halaman Buat pipeline dari template, parameter diisi dengan opsi tugas yang diimpor.
Untuk tugas batch, di bagian Jadwalkan pipeline Anda, berikan jadwal berulang. Memberikan alamat akun email untuk Cloud Scheduler, yang digunakan untuk menjadwalkan batch run, bersifat opsional. Jika tidak ditentukan, akun layanan Compute Engine default akan digunakan.
Membuat pipeline data
Di konsol Google Cloud , buka halaman Dataflow Data pipelines.
Pilih +Buat pipeline data.
Di halaman Buat pipeline dari template, berikan nama pipeline, lalu isi template lainnya pemilihan dan kolom parameter.
Untuk tugas batch, di bagian Jadwalkan pipeline Anda, berikan jadwal berulang. Memberikan alamat akun email untuk Cloud Scheduler, yang digunakan untuk menjadwalkan batch run, bersifat opsional. Jika nilai tidak ditentukan, akun layanan Compute Engine default akan digunakan.
Membuat pipeline data batch
Untuk membuat pipeline data batch contoh ini, Anda harus memiliki akses ke resource berikut di project Anda:
- Bucket Cloud Storage untuk menyimpan file input dan output
- Set data BigQuery untuk membuat tabel.
Contoh pipeline ini menggunakan template pipeline batch Cloud Storage Text to BigQuery. Template ini membaca file dalam format CSV dari Cloud Storage, menjalankan transformasi, lalu menyisipkan nilai ke dalam tabel BigQuery dengan tiga kolom.
Buat file berikut di drive lokal Anda:
File
bq_three_column_table.jsonyang berisi skema tabel BigQuery tujuan berikut.{ "BigQuery Schema": [ { "name": "col1", "type": "STRING" }, { "name": "col2", "type": "STRING" }, { "name": "col3", "type": "INT64" } ] }File JavaScript
split_csv_3cols.js, yang menerapkan transformasi sederhana pada data input sebelum dimasukkan ke BigQuery.function transform(line) { var values = line.split(','); var obj = new Object(); obj.col1 = values[0]; obj.col2 = values[1]; obj.col3 = values[2]; var jsonString = JSON.stringify(obj); return jsonString; }File CSV
file01.csvdengan beberapa catatan yang dimasukkan ke dalam tabel BigQuery.b8e5087a,74,27531 7a52c051,4a,25846 672de80f,cd,76981 111b92bf,2e,104653 ff658424,f0,149364 e6c17c75,84,38840 833f5a69,8f,76892 d8c833ff,7d,201386 7d3da7fb,d5,81919 3836d29b,70,181524 ca66e6e5,d7,172076 c8475eb6,03,247282 558294df,f3,155392 737b82a8,c7,235523 82c8f5dc,35,468039 57ab17f9,5e,480350 cbcdaf84,bd,354127 52b55391,eb,423078 825b8863,62,88160 26f16d4f,fd,397783
Gunakan perintah
gcloud storage cpuntuk menyalin file ke folder di bucket Cloud Storage dalam project Anda, sebagai berikut:Salin
bq_three_column_table.jsondansplit_csv_3cols.jskegs://BUCKET_ID/text_to_bigquery/gcloud storage cp bq_three_column_table.json gs://BUCKET_ID/text_to_bigquery/gcloud storage cp split_csv_3cols.js gs://BUCKET_ID/text_to_bigquery/Menyalin
file01.csvkegs://BUCKET_ID/inputs/gcloud storage cp file01.csv gs://BUCKET_ID/inputs/
Di Google Cloud konsol, buka halaman Bucket Cloud Storage.
Untuk membuat folder
tmpdi bucket Cloud Storage Anda, pilih nama folder Anda untuk membuka halaman Detail bucket, lalu klik Buat folder.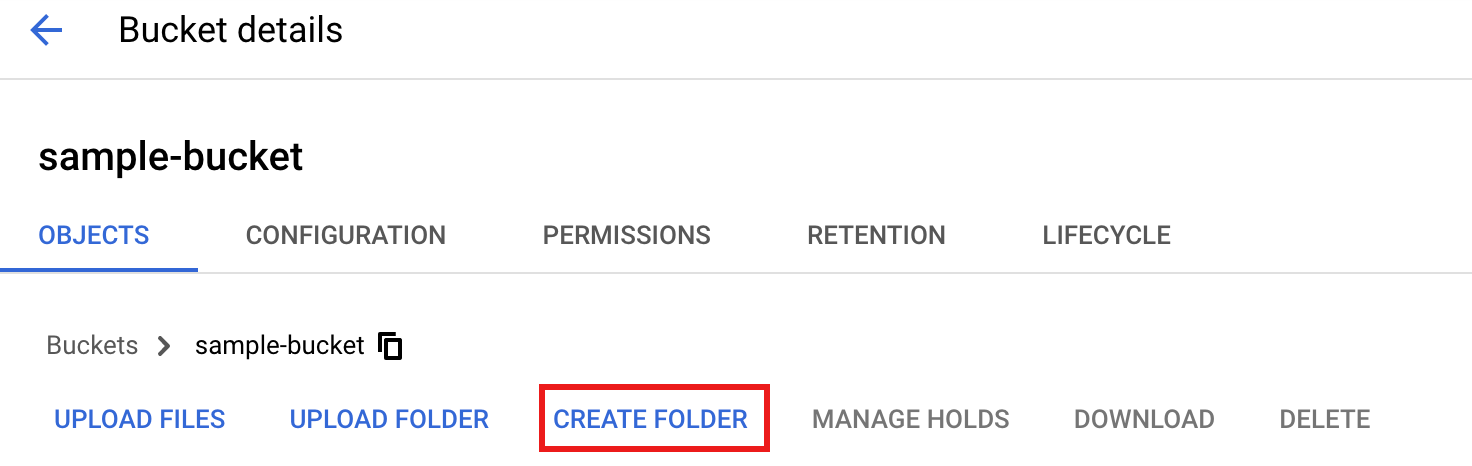
Di konsol Google Cloud , buka halaman Dataflow Data pipelines.
Pilih Buat pipeline data. Masukkan atau pilih item berikut di halaman Create pipeline from template:
- Untuk Pipeline name, masukkan
text_to_bq_batch_data_pipeline. - Untuk Regional endpoint, pilih region Compute Engine. Region sumber dan tujuan harus cocok. Oleh karena itu, bucket Cloud Storage dan tabel BigQuery Anda harus berada di region yang sama.
Untuk Dataflow template, di Process Data in Bulk (batch), pilih Text Files on Cloud Storage to BigQuery.
Untuk Jadwalkan pipeline Anda, pilih jadwal, seperti Per jam pada menit 25, di zona waktu Anda. Anda dapat mengedit jadwal setelah mengirimkan pipeline. Memberikan alamat akun email untuk Cloud Scheduler, yang digunakan untuk menjadwalkan batch run, bersifat opsional. Jika tidak ditentukan, akun layanan Compute Engine default akan digunakan.
Di Parameter wajib, masukkan berikut ini:
- Untuk JavaScript UDF path in Cloud Storage:
gs://BUCKET_ID/text_to_bigquery/split_csv_3cols.js
- Untuk Jalur JSON:
BUCKET_ID/text_to_bigquery/bq_three_column_table.json
- Untuk JavaScript UDF name:
transform - Untuk BigQuery output table:
PROJECT_ID:DATASET_ID.three_column_table
- Untuk Jalur input Cloud Storage:
BUCKET_ID/inputs/file01.csv
- Untuk Temporary BigQuery directory:
BUCKET_ID/tmp
- Untuk Lokasi sementara:
BUCKET_ID/tmp
- Untuk JavaScript UDF path in Cloud Storage:
Klik Create pipeline.
- Untuk Pipeline name, masukkan
Konfirmasi informasi pipeline dan template serta lihat histori saat ini dan sebelumnya dari halaman Detail pipeline.
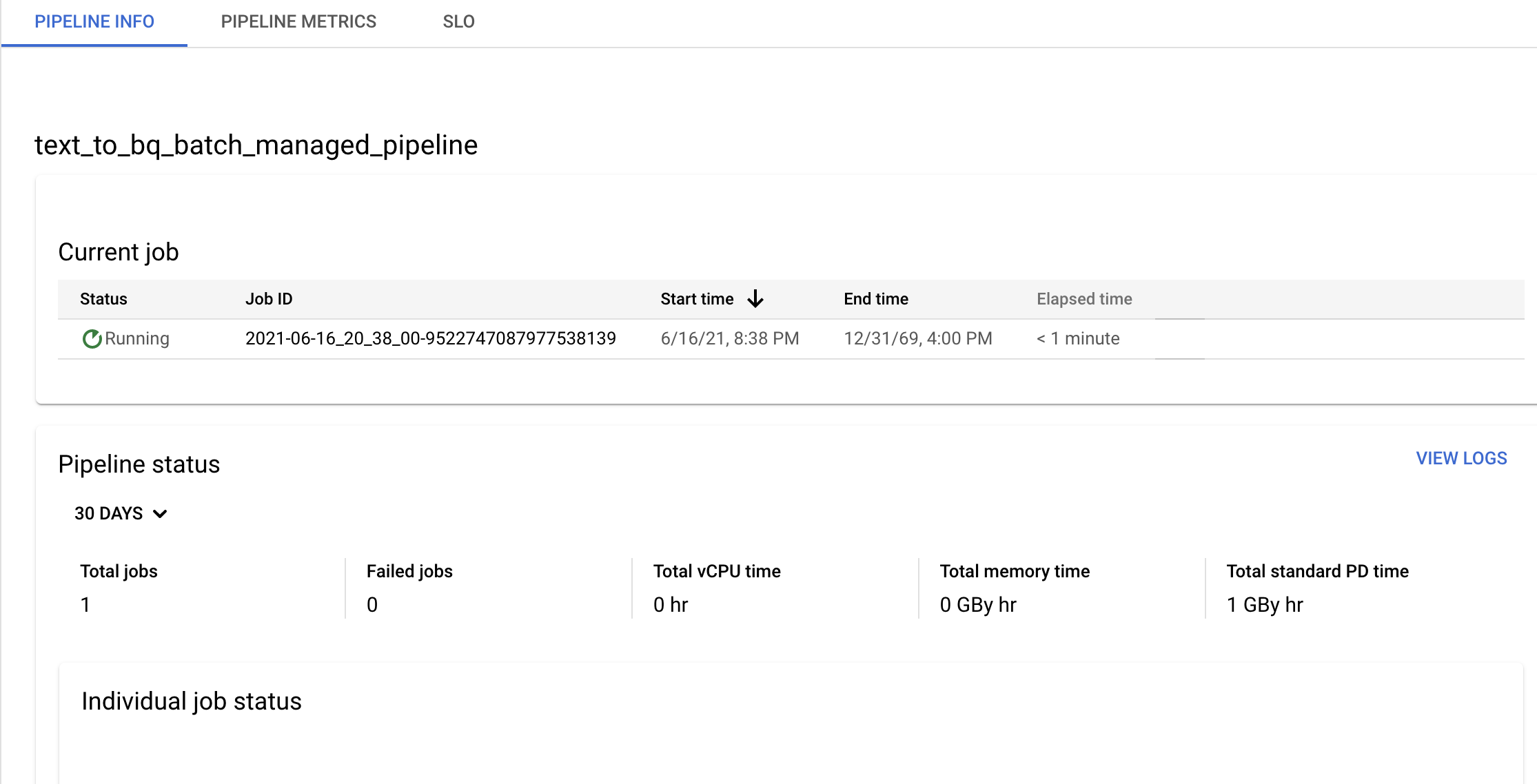
Anda dapat mengedit jadwal pipeline data dari panel Info pipeline di halaman Detail pipeline.
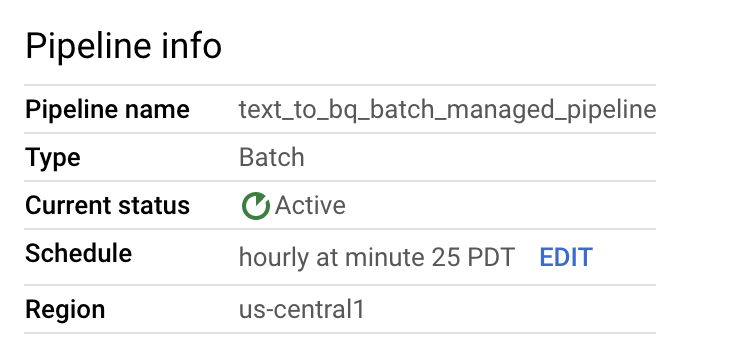
Anda juga dapat menjalankan pipeline batch sesuai permintaan menggunakan tombol Run di konsol Dataflow Pipelines.
Membuat contoh pipeline data streaming
Anda dapat membuat pipeline data streaming contoh dengan mengikuti petunjuk pipeline batch contoh, dengan perbedaan berikut:
- Untuk Jadwal pipeline, jangan tentukan jadwal untuk pipeline data streaming. Tugas streaming Dataflow akan segera dimulai.
- Untuk Dataflow template, di Process Data Continuously (stream), pilih Text Files on Cloud Storage to BigQuery.
- Untuk Jenis mesin pekerja, pipeline memproses kumpulan awal file yang cocok dengan pola
gs://BUCKET_ID/inputs/file01.csvdan file tambahan yang cocok dengan pola ini yang Anda upload ke folderinputs/. Jika ukuran file CSV melebihi beberapa GB, untuk menghindari kemungkinan error kehabisan memori, pilih jenis mesin dengan memori yang lebih tinggi daripada jenis mesinn1-standard-4default, sepertin1-highmem-8.
Pemecahan masalah
Bagian ini menunjukkan cara menyelesaikan masalah pada pipeline data Dataflow.
Tugas pipeline data gagal diluncurkan
Saat Anda menggunakan pipeline data untuk membuat jadwal tugas berulang, tugas Dataflow Anda mungkin tidak diluncurkan, dan error status 503 akan muncul di file log Cloud Scheduler.
Masalah ini terjadi saat Dataflow tidak dapat menjalankan tugas untuk sementara.
Untuk mengatasi masalah ini, konfigurasi Cloud Scheduler agar mencoba kembali tugas. Karena masalahnya bersifat sementara, saat tugas dicoba lagi, tugas mungkin berhasil. Untuk informasi selengkapnya tentang cara menetapkan nilai percobaan ulang di Cloud Scheduler, lihat Membuat tugas.
Menyelidiki pelanggaran tujuan pipeline
Bagian berikut menjelaskan cara menyelidiki pipeline yang tidak memenuhi tujuan performa.
Pipeline batch berulang
Untuk analisis awal kondisi pipeline Anda, di halaman Info pipeline di konsol Google Cloud , gunakan grafik Status tugas individual dan Waktu thread per langkah. Grafik ini berada di panel status pipeline.
Contoh penyelidikan:
Anda memiliki pipeline batch berulang yang berjalan setiap jam pada 3 menit setelah setiap jam. Setiap tugas biasanya berjalan selama sekitar 9 menit. Anda memiliki tujuan agar semua tugas selesai dalam waktu kurang dari 10 menit.
Grafik status tugas menunjukkan bahwa tugas berjalan selama lebih dari 10 menit.
Di tabel histori Update/Eksekusi, temukan tugas yang berjalan selama jam yang diinginkan. Klik untuk membuka halaman detail tugas Dataflow. Di halaman tersebut, temukan tahap yang berjalan lebih lama, lalu periksa kemungkinan error dalam log untuk menentukan penyebab keterlambatan.
Pipeline streaming
Untuk analisis awal kondisi pipeline Anda, di halaman Detail Pipeline, di tab Info pipeline, gunakan grafik keaktualan data. Grafik ini berada di panel status pipeline.
Contoh penyelidikan:
Anda memiliki pipeline streaming yang biasanya menghasilkan output dengan keaktualan data 20 detik.
Anda menetapkan tujuan untuk memiliki jaminan keaktualan data 30 detik. Saat meninjau grafik keaktualan data, Anda melihat bahwa antara pukul 09.00 dan 10.00, keaktualan data melonjak hingga hampir 40 detik.
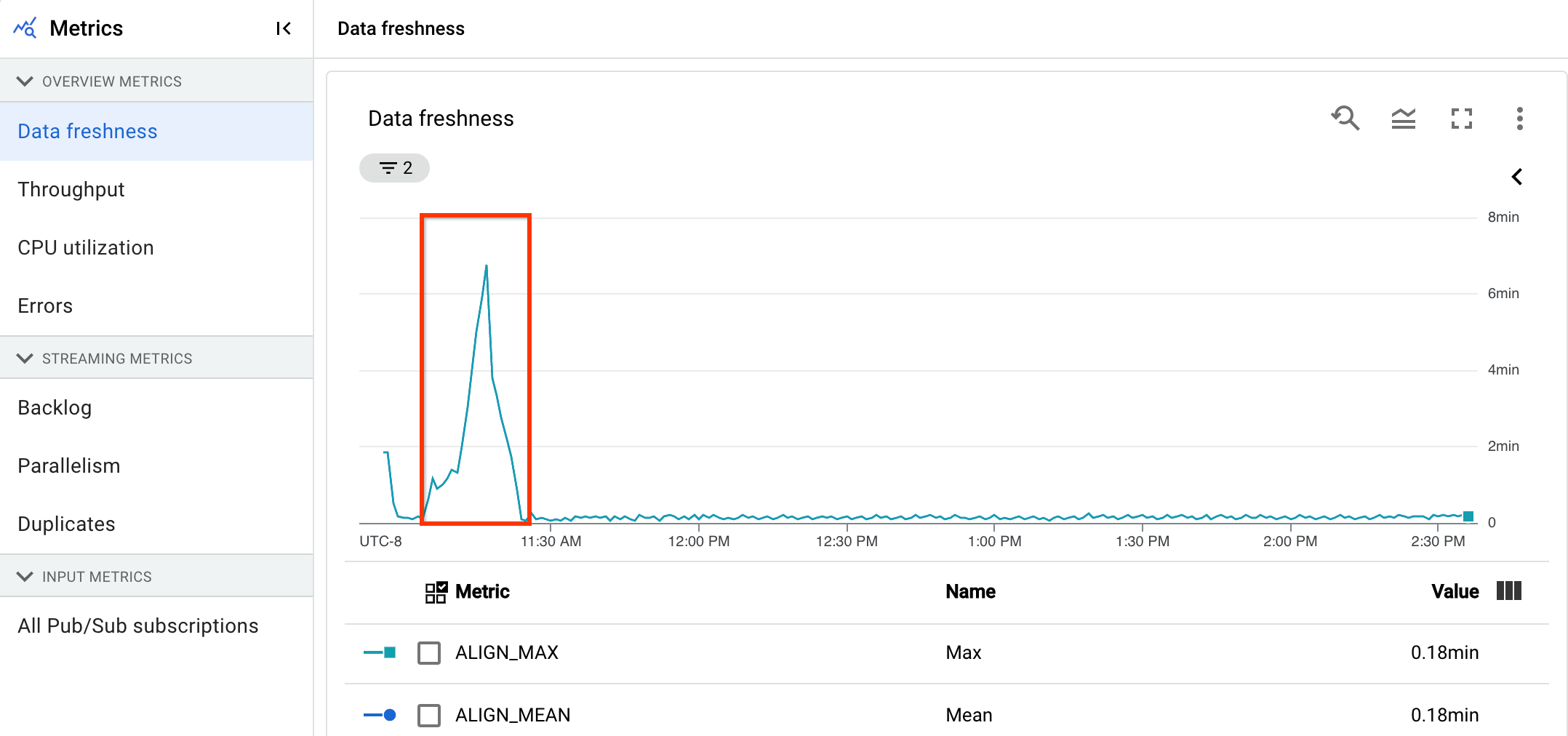
Beralih ke tab Pipeline metrics, lalu lihat grafik CPU Utilization dan Memory Utilization untuk analisis lebih lanjut.
Error: ID pipeline sudah ada dalam project
Jika Anda mencoba membuat pipeline baru dengan nama yang sudah ada di project Anda, Anda akan menerima pesan error ini: Pipeline Id already exist within the
project. Untuk menghindari masalah ini, selalu pilih nama unik untuk pipeline Anda.