資料科學解決方案
適用於 AI 工作流程的整合式資料、分析與機器學習平台
將複雜作業交給統合資料與 AI 平台,減輕資料團隊的負擔。Google Cloud 的全方位代管服務套件和整合式工作流程,可助您輕鬆建構、管理及擴充資料科學解決方案。
總覽
什麼是資料科學解決方案?
資料科學解決方案是全方位的技術導向做法,運用機器學習、AI 和統計模型來解決複雜的業務難題,並提升營運效率。這項做法可將重心從基本資料分析轉移至企業執行作業的完整生命週期,著重於資料工程、預測模型和 MLOps 的核心程序,將原始資料轉化為自動化且具策略價值的成果。
選用 Google Cloud 資料科學解決方案的優點
提升業務的速度和靈活性,創造短期和長期價值。傳統做法往往需要整合 5 到 7 種不同工具,而 Google Cloud 的資料科學平台以單一多模態資料為基礎,涵蓋從資料擷取到模型部署的完整生命週期,確保統一管理。
適用於各種業務難題的資料科學解決方案
無論您的目標是提高收益、降低成本或管理風險,Google Cloud 都能提供工具,協助您將資料模型產業化,並將重心從個別實驗轉移至實際的 MLOps 管道。

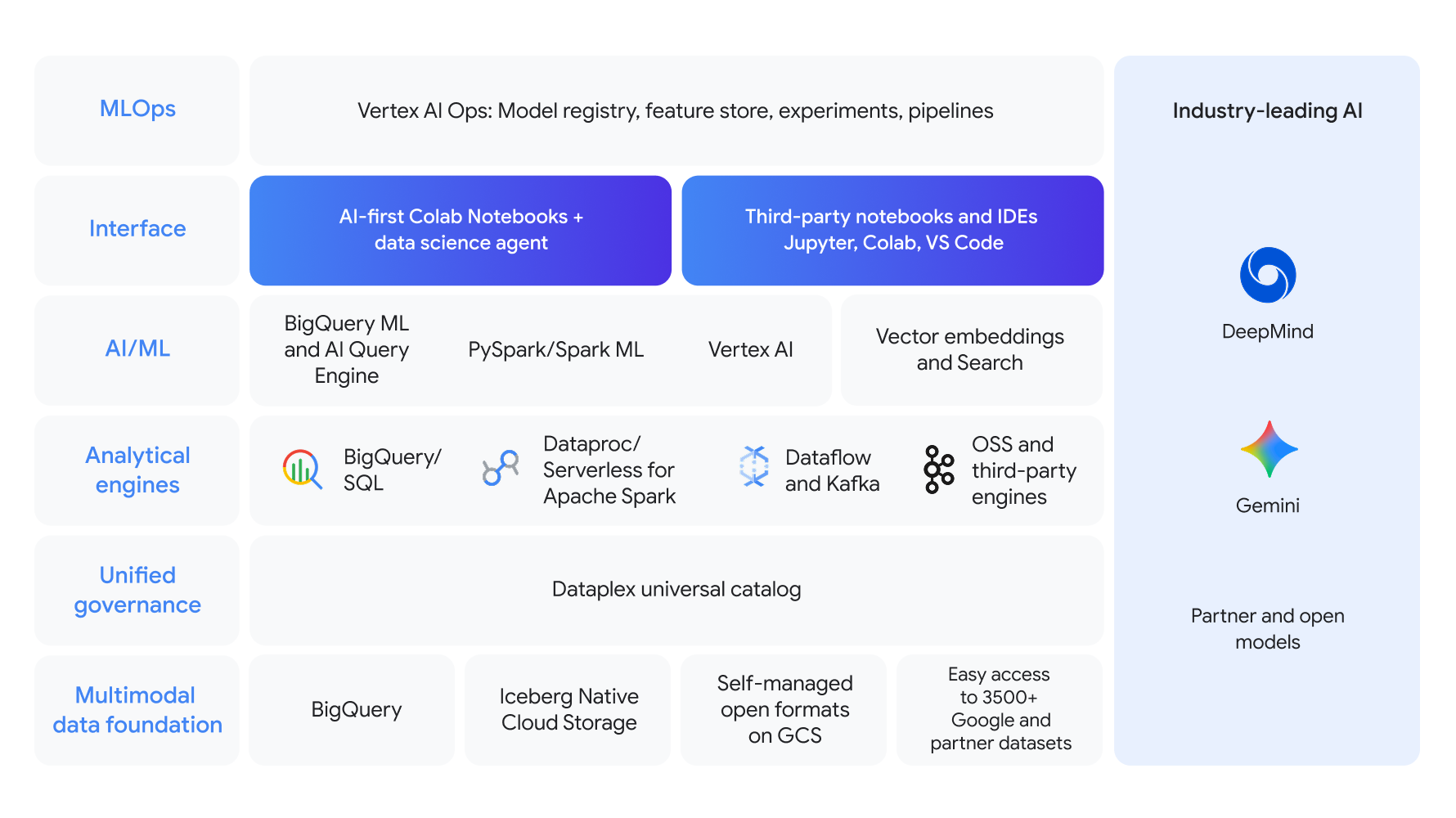
統合式平台,採用端對端資料科學工作流程
以多模態資料為基礎,打造整合式解決方案,涵蓋整個資料科學與機器學習生命週期,確保統一管理
您可以先運用 BigQuery SQL 和 Apache Spark 等強大的分析引擎,再用 BigQuery ML 或 Gemini Enterprise Agent Platform 建立模型。結合由業界頂尖 AI 驅動的 AI 優先 Colab Enterprise 筆記本和穩健的 MLOps,簡化開發流程。
操作說明
以多模態資料為基礎,打造整合式解決方案,涵蓋整個資料科學與機器學習生命週期,確保統一管理
您可以先運用 BigQuery SQL 和 Apache Spark 等強大的分析引擎,再用 BigQuery ML 或 Gemini Enterprise Agent Platform 建立模型。結合由業界頂尖 AI 驅動的 AI 優先 Colab Enterprise 筆記本和穩健的 MLOps,簡化開發流程。
採用集中工作區並提供 AI 優先筆記本
從一系列筆記本解決方案中,選擇適合企業資料科學的產品
Colab Enterprise 提供安全的代管環境,並整合 Gemini Enterprise Agent Platform 和 BigQuery。Workbenches 提供可自訂的 JupyterLab 執行個體,而 Cloud Workstations 則支援完整的 IDE。擴充功能還能將自行託管的工具直接連至 Google Cloud 服務。

操作說明
從一系列筆記本解決方案中,選擇適合企業資料科學的產品
Colab Enterprise 提供安全的代管環境,並整合 Gemini Enterprise Agent Platform 和 BigQuery。Workbenches 提供可自訂的 JupyterLab 執行個體,而 Cloud Workstations 則支援完整的 IDE。擴充功能還能將自行託管的工具直接連至 Google Cloud 服務。


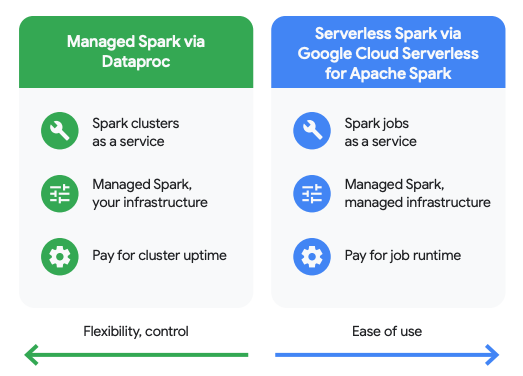
使用多個引擎,靈活處理資料
操作說明
使用支援 Python 的 BigQuery DataFrames 擴充資料科學作業規模
偏好使用 Python 原生資料庫嗎?
BigQuery DataFrames 提供類似 pandas 的 API,可將 Python 程式碼轉譯為適合在 BigQuery 引擎上執行的 SQL。無論是 SQL、PySpark 或適用於 pandas 的 DataFrame,您都能使用相同的基礎資料,並靈活運用合適的工具完成所需工作

操作說明
偏好使用 Python 原生資料庫嗎?
BigQuery DataFrames 提供類似 pandas 的 API,可將 Python 程式碼轉譯為適合在 BigQuery 引擎上執行的 SQL。無論是 SQL、PySpark 或適用於 pandas 的 DataFrame,您都能使用相同的基礎資料,並靈活運用合適的工具完成所需工作
建構、訓練、調整及執行機器學習模型
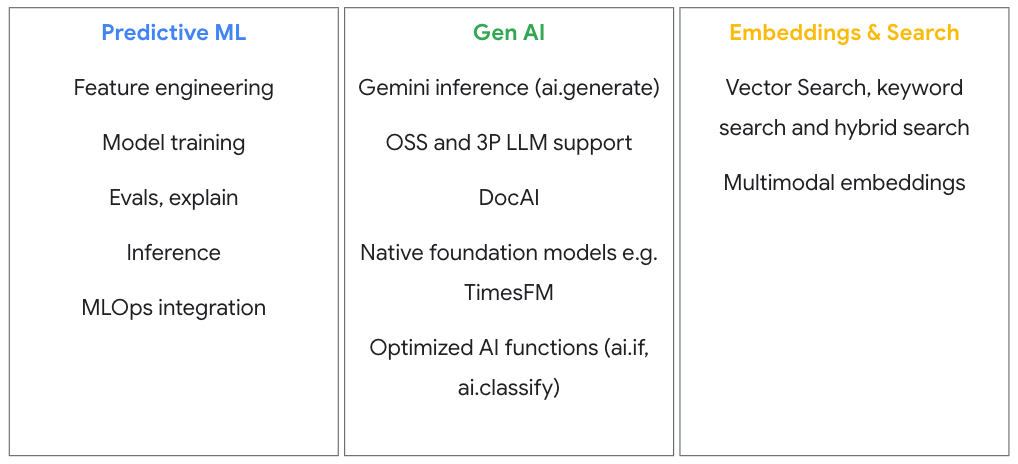
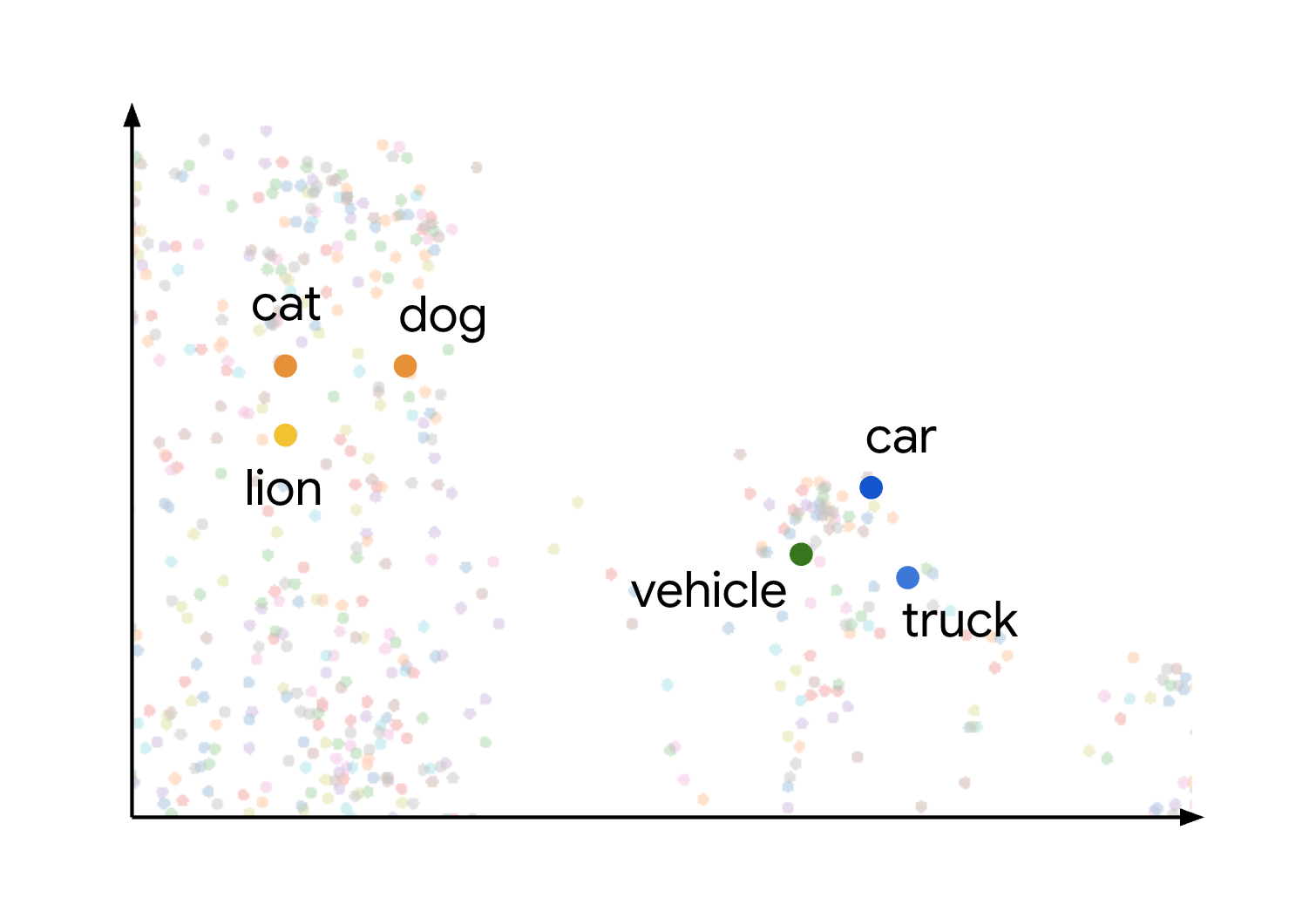
透過整合式 MLOps,完成模型開發到正式環境部署的所有流程
BigQuery 和 Gemini Enterprise Agent Platform 整合後,可簡化 MLOps 流程
在 Gemini Enterprise Agent Platform 特徵儲存庫中集中管理特徵,避免訓練/應用偏差和重複作業。AutoML 可自動建構表格型資料的模型。無論模型來自 BigQuery ML 或 Gemini Enterprise Agent Platform,都會自動在平台 Model Registry 註冊,方便您在單一平台上輕鬆管理版本、評估及部署模型,打造流暢的端對端生命週期。

操作說明
BigQuery 和 Gemini Enterprise Agent Platform 整合後,可簡化 MLOps 流程
在 Gemini Enterprise Agent Platform 特徵儲存庫中集中管理特徵,避免訓練/應用偏差和重複作業。AutoML 可自動建構表格型資料的模型。無論模型來自 BigQuery ML 或 Gemini Enterprise Agent Platform,都會自動在平台 Model Registry 註冊,方便您在單一平台上輕鬆管理版本、評估及部署模型,打造流暢的端對端生命週期。
企業案例
以成果為導向的成功案例




瞭解詳情





專為資料科學團隊的各類角色打造
專為資料科學團隊的各類角色打造
常見問題
資料科學家和機器學習工程師
著重於開發人員體驗,並支援 Colab Enterprise 筆記本、PyTorch 和 TensorFlow 等架構,以及 BigQuery DataFrames。團隊可以跨專案共用筆記本、資料連線和運算資源,讓 Google Cloud 成為名符其實的資料科學協作平台。
資料與分析部門主管
盡可能提高投資報酬率並強化管理成效。整合式平台可降低供應商成本並簡化所需工具數量,還有內建控管機制。模型可從筆記本環境直接部署至正式環境,無需另外成立 MLOps 團隊,直接支援 3 倍/4 倍/10 倍的效能統計資料。
資料工程師和架構師
享受整合與彈性帶來的優勢。支援開放原始碼相容性 (Apache Spark、Airflow 和 Kafka),並在單一資料副本上進行多引擎處理,確保框架不會受制於單一供應商。


















