이 페이지에서는 Cloud Storage에서 BigQuery로 데이터를 마이그레이션할 때 네임스페이스 수준에서 Google Cloud 리소스에 대한 액세스를 제어하는 사용 사례에 대해 설명합니다.
Google Cloud 리소스에 대한 액세스를 제어하기 위해 Cloud Data Fusion의 네임스페이스는 기본적으로 Cloud Data Fusion API 서비스 에이전트를 사용합니다.
더 나은 데이터 격리를 위해 맞춤설정된 IAM 서비스 계정(네임스페이스 서비스 계정별이라고 함)을 각 네임스페이스와 연결할 수 있습니다. 네임스페이스마다 다를 수 있는 맞춤설정된 IAM 서비스 계정을 사용하면 Cloud Data Fusion에서 파이프라인 설계 시간 파이프라인 작업(예: 파이프라인 미리보기, Wrangler, 파이프라인 유효성 검사)의 네임스페이스 간Google Cloud 리소스에 대한 액세스를 제어할 수 있습니다.
자세한 내용은 네임스페이스 서비스 계정으로 액세스 제어를 참조하세요.
시나리오
이 사용 사례에서는 마케팅 부서가 Cloud Data Fusion을 사용하여 Cloud Storage에서 BigQuery로 데이터를 마이그레이션하게 됩니다.
마케팅 부서에는 A, B, C 세 팀이 있습니다. 목표는 각 팀(A, B, C)에 해당하는 Cloud Data Fusion 네임스페이스를 통해 Cloud Storage에서 데이터 액세스를 제어하는 구조화된 접근 방식을 설정하는 것입니다.
솔루션
다음 단계에서는 네임스페이스 서비스 계정으로 Google Cloud 리소스에 대한 액세스를 제어하여 서로 다른 팀의 데이터 스토어 간 무단 액세스를 방지하는 방법을 보여줍니다.
각 네임스페이스에 Identity and Access Management 서비스 계정 연결
각 팀의 네임스페이스에서 IAM 서비스 계정을 구성합니다(네임스페이스 서비스 계정 구성 참고).
팀 A에 대한 맞춤설정된 서비스 계정(예:
team-a@pipeline-design-time-project.iam.gserviceaccount.com)을 추가하여 액세스 제어를 설정합니다.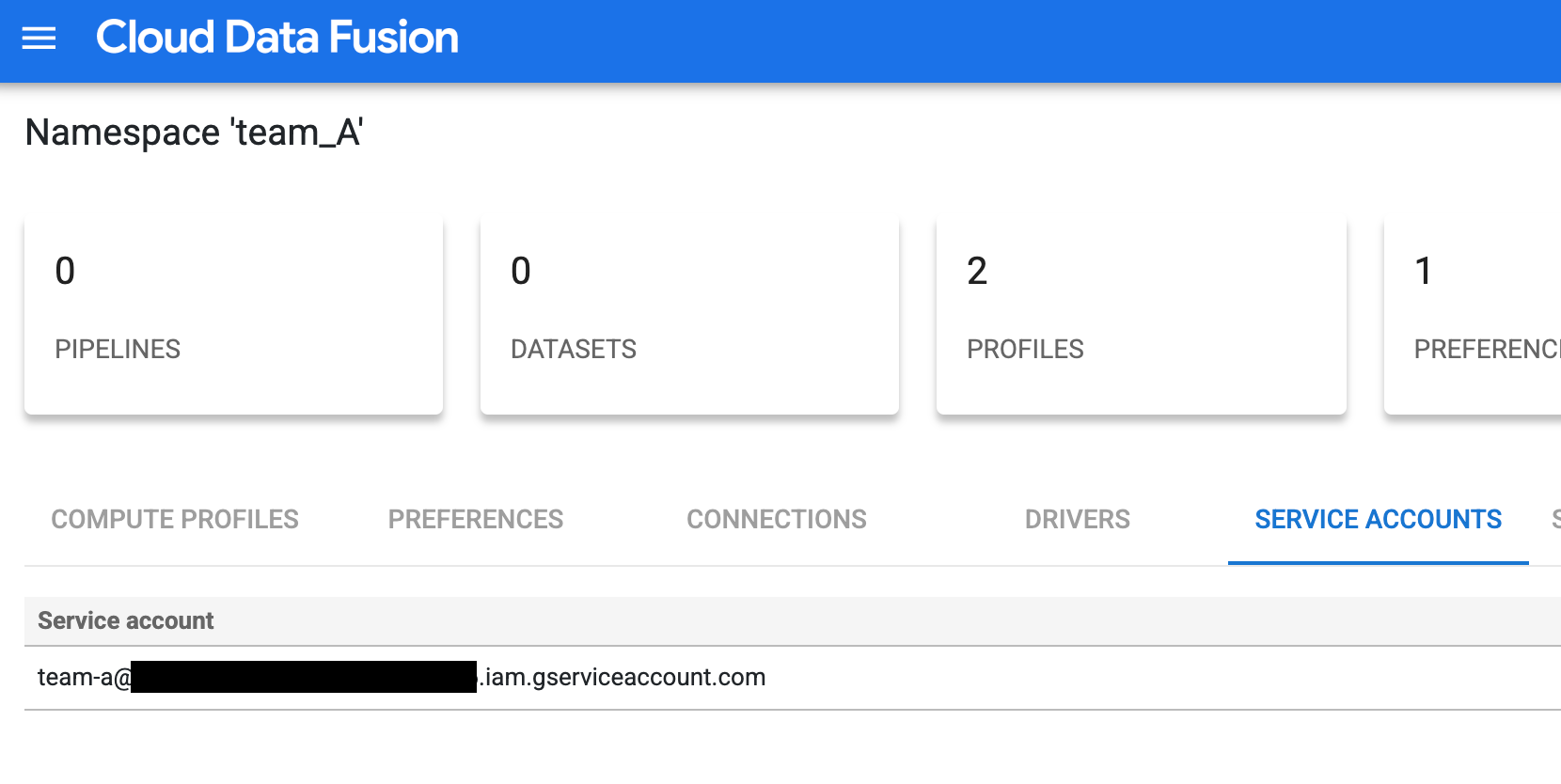
그림 1: 팀 A에 대한 맞춤설정된 서비스 계정 추가 팀 B와 C의 구성 단계를 반복하여 맞춤설정된 서비스 계정으로 액세스 제어를 설정합니다.
Cloud Storage 버킷에 대한 액세스 제한
적절한 권한을 부여하여 Cloud Storage 버킷에 대한 액세스를 제한합니다.
- 프로젝트에서 Cloud Storage 버킷을 나열하는 데 필요한
storage.buckets.list권한을 IAM 서비스 계정에 부여합니다. 자세한 내용은 버킷 나열을 참고하세요. IAM 서비스 계정에 특정 버킷의 객체에 액세스할 수 있는 권한을 부여합니다.
예를 들어 버킷
team_a1의 네임스페이스team_A와 연결된 IAM 서비스 계정에 스토리지 객체 뷰어 역할을 부여합니다. 이 권한을 사용하면 팀 A는 격리된 디자인 시간 환경에서 해당 버킷의 객체와 관리형 폴더를 메타데이터와 함께 보고 나열할 수 있습니다.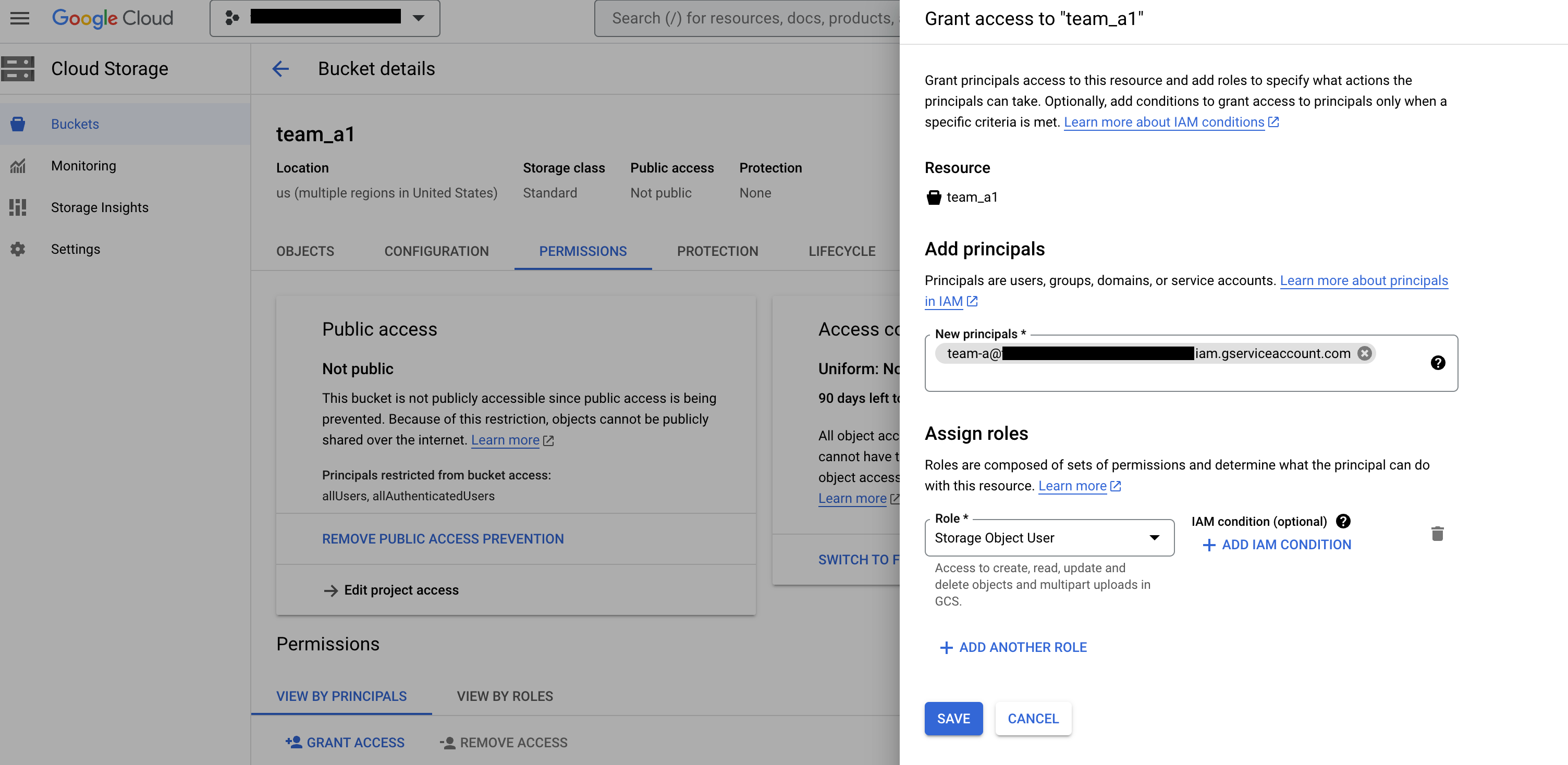
그림 2: Cloud Storage 버킷 페이지에서 팀을 주 구성원으로 추가하고 스토리지 객체 사용자 역할을 할당합니다.
해당 네임스페이스에서 Cloud Storage 연결 만들기
각 팀의 네임스페이스에서 Cloud Storage 연결을 만듭니다.
Google Cloud 콘솔에서 Cloud Data Fusion 인스턴스 페이지로 이동하고 Cloud Data Fusion 웹 인터페이스에서 인스턴스를 엽니다.
시스템 관리자 > 구성 > 네임스페이스를 클릭합니다.
사용할 네임스페이스(예: 팀 A의 네임스페이스)를 클릭합니다.
연결 탭을 클릭한 다음 연결 추가를 클릭합니다.
GCS를 선택하고 연결을 구성합니다.
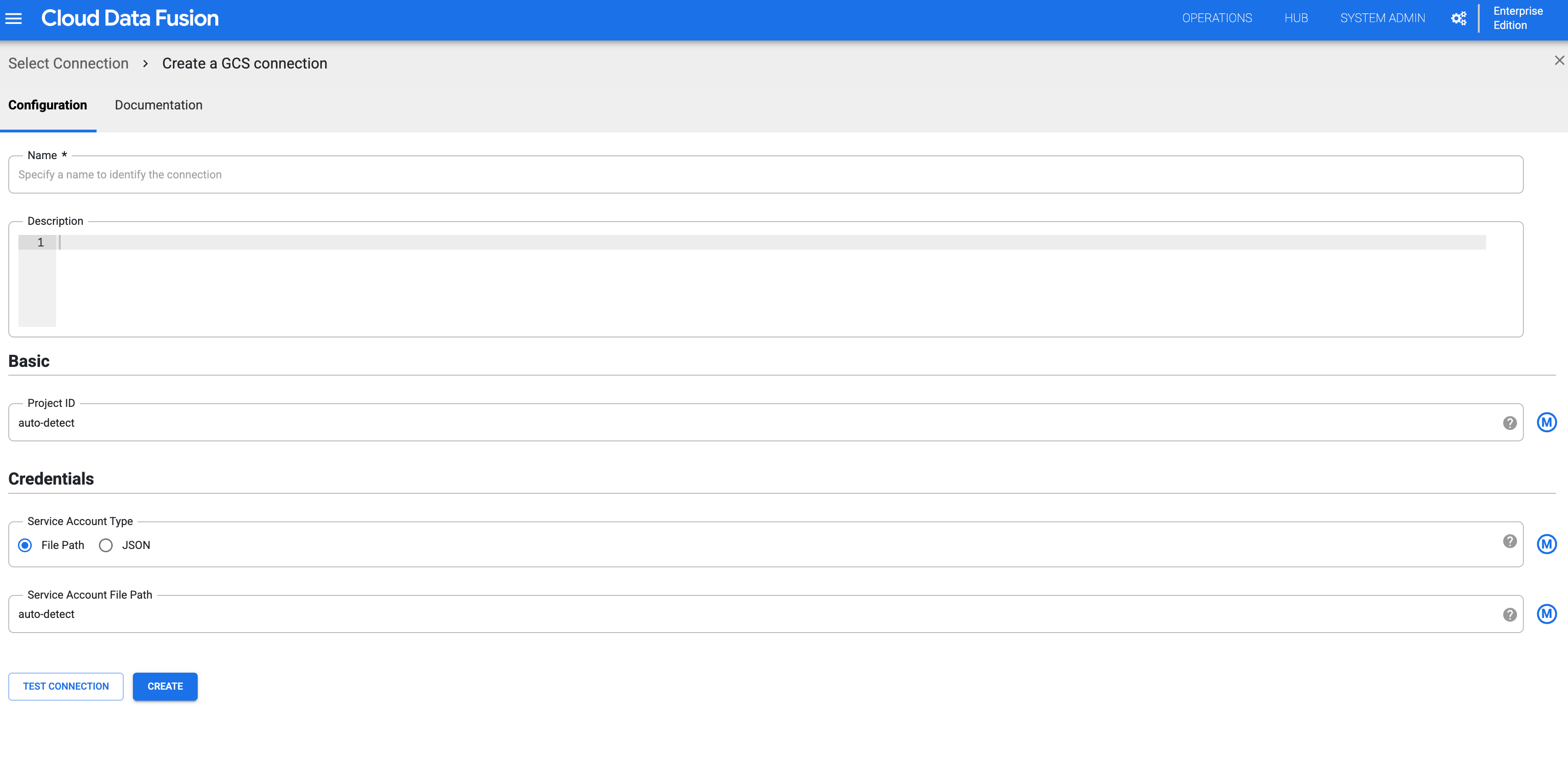
그림 3: 네임스페이스에 대한 Cloud Storage 연결을 구성합니다. 위 단계를 반복하여 모든 네임스페이스에 대한 Cloud Storage 연결을 만듭니다. 그러면 각 팀은 설계 시간 작업을 위해 리소스의 격리된 사본과 상호작용할 수 있습니다.
각 네임스페이스의 설계 시간 격리 검증
팀 A는 각 네임스페이스의 Cloud Storage 버킷에 액세스하여 설계 시 격리를 검증할 수 있습니다.
Google Cloud 콘솔에서 Cloud Data Fusion 인스턴스 페이지로 이동하고 Cloud Data Fusion 웹 인터페이스에서 인스턴스를 엽니다.
시스템 관리자 > 구성 > 네임스페이스를 클릭합니다.
네임스페이스(예: 팀 A 네임스페이스
team_A)를 선택합니다.메뉴 > Wrangler를 클릭합니다.
GCS를 클릭합니다.
버킷 목록에서
team_a1버킷을 클릭합니다.팀 A 네임스페이스에
storage.buckets.list권한이 있으므로 버킷 목록을 볼 수 있습니다.버킷을 클릭하면 팀 A 네임스페이스에 스토리지 객체 뷰어 역할이 있으므로 콘텐츠를 볼 수 있습니다.
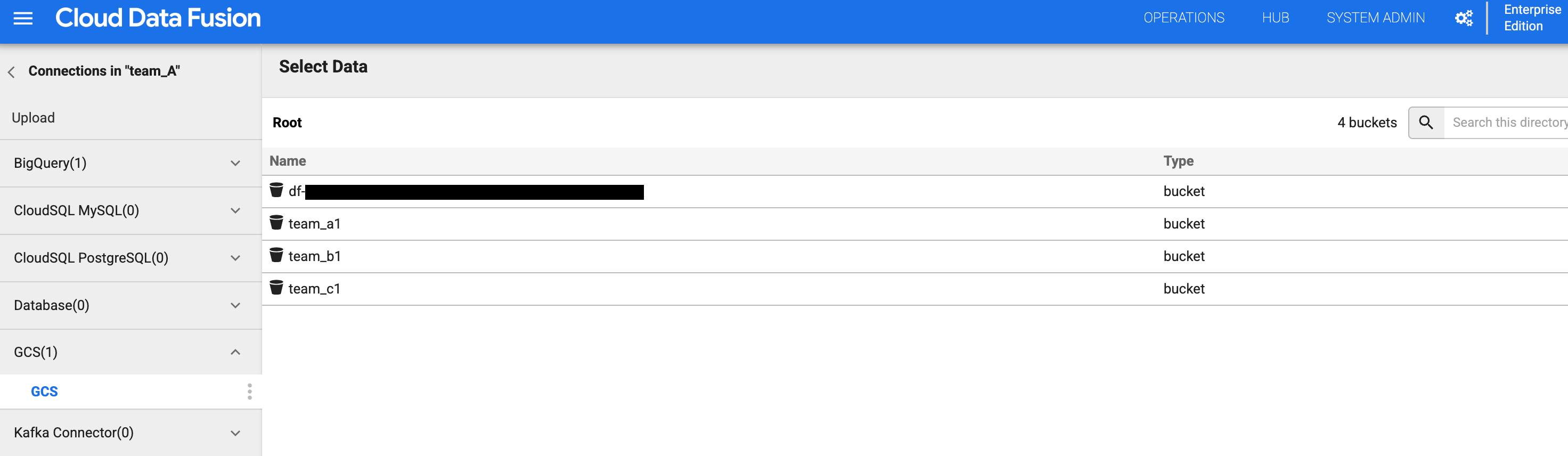
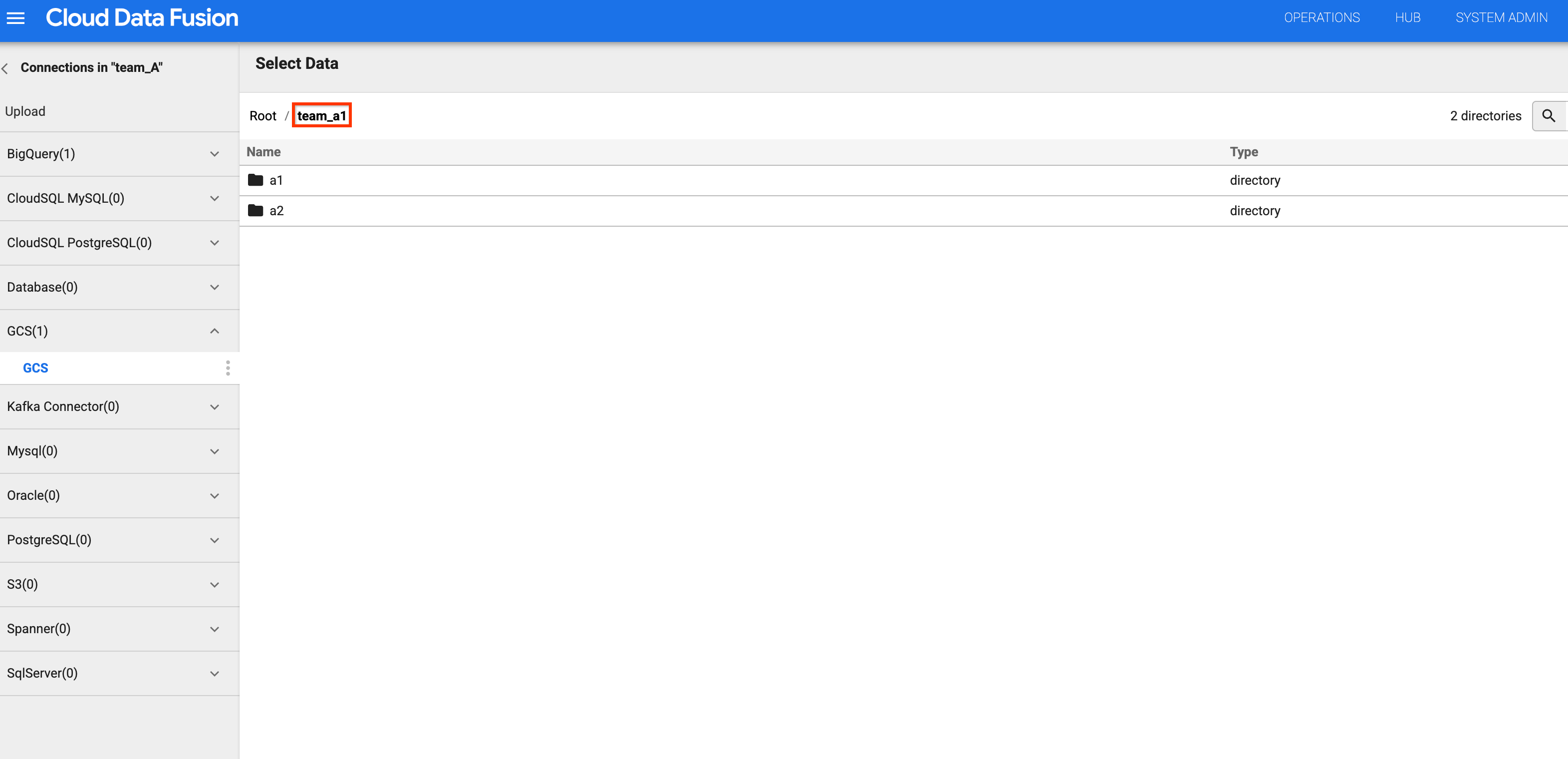
그림 4 및 5: 팀 A가 적절한 스토리지 버킷에 액세스할 수 있는지 확인합니다. 버킷 목록으로 돌아가서
team_b1또는team_c1버킷을 클릭합니다. 팀 A의 네임스페이스 서비스 계정을 사용하여 이 설계 시간 리소스를 격리했기 때문에 액세스가 제한됩니다.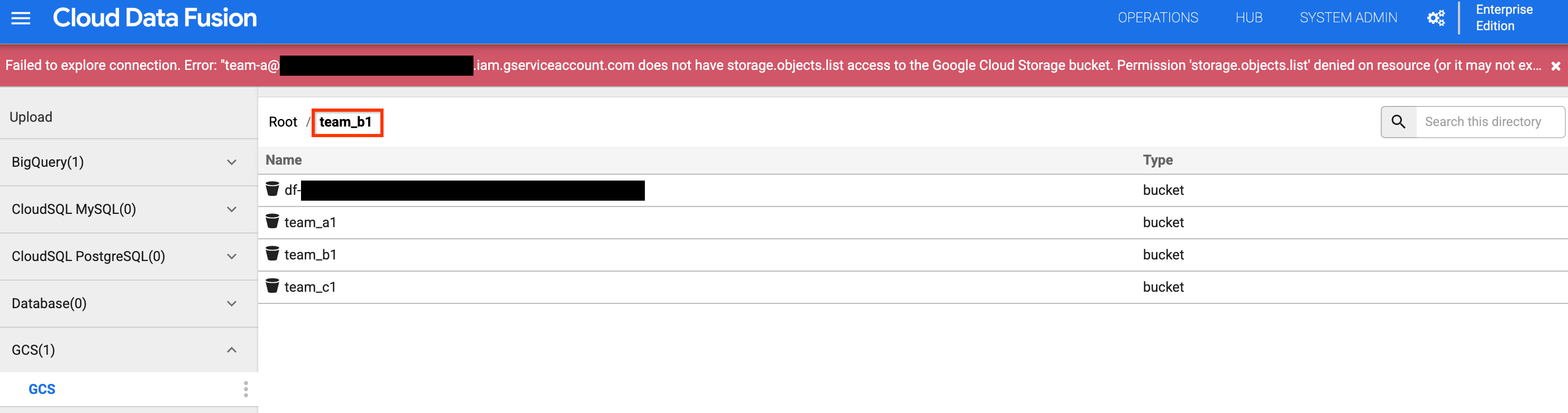
그림 6: 팀 A가 팀 B 및 C 스토리지 버킷에 액세스할 수 없는지 확인합니다.
다음 단계
- Cloud Data Fusion의 보안 기능에 대해 자세히 알아보기