ユースケース: 別のプロジェクトの Dataproc クラスタのアクセス制御
このページでは、別のプロジェクトで Dataproc クラスタを使用するパイプラインをデプロイして実行する際のアクセス制御の管理について説明します。 Google Cloud
シナリオ
デフォルトでは、Cloud Data Fusion インスタンスがGoogle Cloud プロジェクトで起動されると、同じプロジェクト内の Dataproc クラスタを使用してパイプラインをデプロイして実行します。ただし、組織によっては、別のプロジェクトでクラスタを使用することが必要な場合があります。このユースケースでは、プロジェクト間のアクセスを管理する必要があります。次のページでは、ベースライン(デフォルト)構成を変更して、適切なアクセス制御を適用する方法について説明します。
準備
このユースケースのソリューションを理解するには、次のコンテキストが必要です。
前提条件と対象範囲
このユースケースには、次の要件があります。
ソリューション
このソリューションでは、ベースラインとユースケース固有のアーキテクチャおよび構成を比較します。
アーキテクチャ
次の図は、同じプロジェクト(ベースライン)とテナント プロジェクトの VPC を介して別のプロジェクトでクラスタを使用する場合の、Cloud Data Fusion インスタンスの作成とパイプラインの実行に関するプロジェクト アーキテクチャを比較しています。
ベースライン アーキテクチャ
次の図は、プロジェクトのベースライン アーキテクチャを示しています。
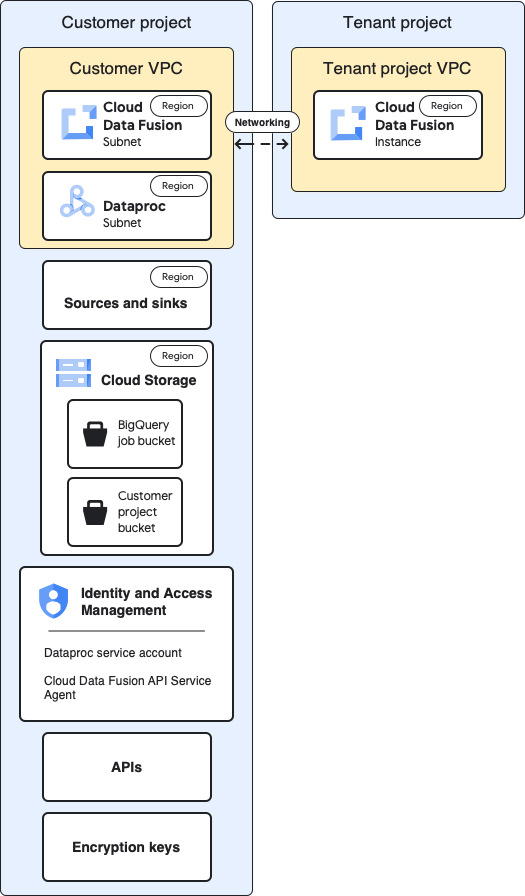
ベースライン構成では、プライベート Cloud Data Fusion インスタンスを作成し、追加のカスタマイズを行うことなくパイプラインを実行します。
- 組み込みのコンピューティング プロファイルのいずれかを使用している
- ソースとシンクがインスタンスと同じプロジェクトにある
- どのサービス アカウントにも追加のロールが付与されてない
テナント プロジェクトとお客様のプロジェクトの詳細については、ネットワーキングをご覧ください。
ユースケースのアーキテクチャ
次の図は、別のプロジェクトでクラスタを使用する場合のプロジェクト アーキテクチャを示しています。
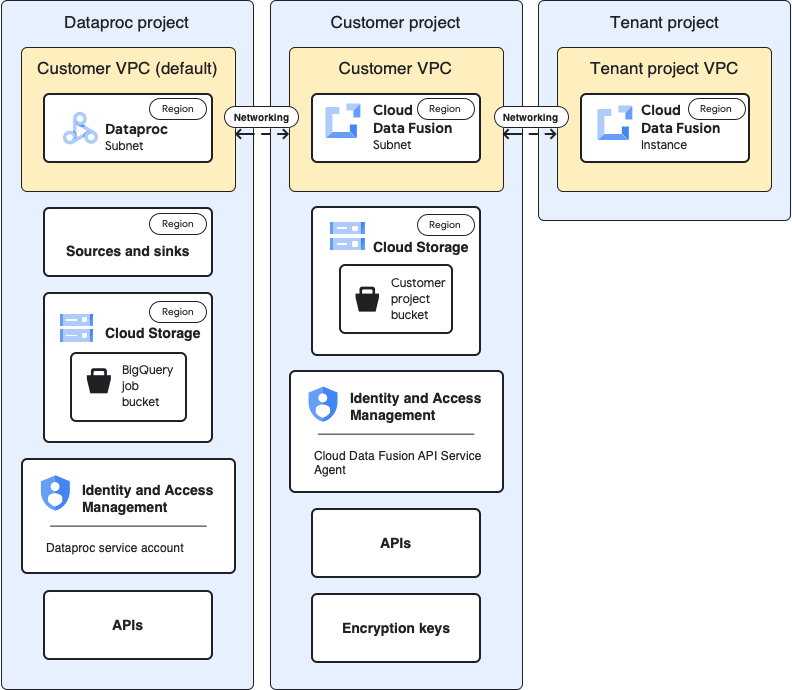
構成
以下の各セクションでは、ベースライン構成と、デフォルトのテナント プロジェクト VPC を介して別のプロジェクトで Dataproc クラスタを使用するユースケース固有の構成を比較します。
以下のユースケースの説明では、お客様のプロジェクトは Cloud Data Fusion インスタンスが実行される場所、Dataproc プロジェクトは Dataproc クラスタが起動される場所です。
テナント プロジェクトの VPC とインスタンス
| ベースライン |
ユースケース |
前述のベースライン アーキテクチャの図では、テナント プロジェクトには次のコンポーネントが含まれています。
- 自動的に作成されるデフォルトの VPC。
- Cloud Data Fusion インスタンスの物理的なデプロイ。
|
このユースケースでは、追加の構成は必要ありません。 |
お客様のプロジェクト
| ベースライン |
ユースケース |
| Google Cloud プロジェクトは、パイプラインをデプロイして実行する場所です。
デフォルトでは、パイプラインの実行時にこのプロジェクトで Dataproc クラスタが起動されます。 |
このユースケースでは、2 つのプロジェクトを管理します。このページでは、お客様のプロジェクトは、Cloud Data Fusion インスタンスが実行される場所を意味します。
Dataproc プロジェクトは、Dataproc クラスタを起動する場所を意味します。 |
お客様の VPC
| ベースライン |
ユースケース |
自分の(お客様の)観点からは、お客様の VPC は Cloud Data Fusion が論理的に配置されている場所です。
重要ポイント:
お客様の VPC の詳細は、プロジェクトの VPC ネットワーク ページで確認できます。
[VPC ネットワーク] に移動 |
このユースケースでは、追加の構成は必要ありません。 |
Cloud Data Fusion サブネット
| ベースライン |
ユースケース |
自分の(お客様の)観点からは、このサブネットは Cloud Data Fusion が論理的に配置されている場所です。
重要ポイント:
このサブネットのリージョンは、テナント プロジェクトの Cloud Data Fusion インスタンスのロケーションと同じです。
|
このユースケースでは、追加の構成は必要ありません。 |
Dataproc サブネット
| ベースライン |
ユースケース |
パイプラインの実行時に Dataproc クラスタが起動されるサブネット。
重要ポイント:
- このベースライン構成では、Dataproc は Cloud Data Fusion インスタンスと同じサブネットで実行されます。
- Cloud Data Fusion は、Cloud Data Fusion のインスタンスとサブネットの両方と同じリージョンにサブネットを配置します。このリージョンにサブネットが 1 つのみ存在する場合、サブネットは同じです。
- Dataproc サブネットに限定公開の Google アクセスが必要です。
|
これは、パイプラインの実行時に Dataproc クラスタが起動される新しいサブネットです。
重要ポイント:
- この新しいサブネットでは、限定公開の Google アクセスを [オン] に設定します。
- Dataproc サブネットは、Cloud Data Fusion インスタンスと同じロケーションに存在する必要はありません。
|
ソースとシンク
| ベースライン |
ユースケース |
データが抽出されるソースと、データが読み込まれるシンク(BigQuery のソースやシンクなど)。
重要ポイント:
- データをフェッチして読み込むジョブは、データセットと同じロケーションで処理する必要があります。そのように処理しないとエラーが発生します。
|
このページのユースケース固有のアクセス制御構成は、BigQuery のソースとシンク用です。 |
Cloud Storage
| ベースライン |
ユースケース |
Cloud Data Fusion と Dataproc の間でファイルを転送するために使用する、お客様のプロジェクト内のストレージ バケット。
重要ポイント:
- このバケットは、Cloud Data Fusion ウェブ インターフェースで、エフェメラル クラスタの [コンピューティング プロファイル] 設定で指定できます。
- バッチ パイプラインとリアルタイム パイプライン、またはレプリケーション ジョブの場合:
Compute プロファイルでバケットを指定しない場合、Cloud Data Fusion はインスタンスと同じプロジェクトにバケットを作成します。
- 静的 Dataproc クラスタであっても、このベースライン構成では、バケットが Cloud Data Fusion によって作成され、Dataproc のステージング バケットと一時バケットとは異なります。
- Cloud Data Fusion API サービス エージェントには、Cloud Data Fusion インスタンスを含むプロジェクトにこのバケットを作成するための権限が組み込まれています。
|
このユースケースでは、追加の構成は必要ありません。 |
ソースとシンクで使用される一時バケット
| ベースライン |
ユースケース |
ソースとシンクのプラグインによって作成された一時バケット(BigQuery Sink プラグインによって開始された読み込みジョブなど)。
重要ポイント:
- これらのバケットは、ソース プラグイン プロパティとシンク プラグイン プロパティを構成するときに定義できます。
- バケットを定義しない場合、Dataproc が実行されているのと同じプロジェクトにバケットが作成されます。
- データセットがマルチリージョンの場合、バケットは同じスコープに作成されます。
- プラグイン構成でバケットを定義する場合、バケットのリージョンはデータセットのリージョンと一致する必要があります。
- プラグイン構成でバケットを定義しない場合、パイプラインが終了するときに、作成されたバケットが削除されます。
|
このユースケースでは、バケットは任意のプロジェクトに作成できます。 |
プラグインのデータのソースまたはシンクであるバケット
| ベースライン |
ユースケース |
| Cloud Storage プラグインや FTP to Cloud Storage プラグインなどのプラグインの構成で指定したお客様のバケット。 |
このユースケースでは、追加の構成は必要ありません。 |
IAM: Cloud Data Fusion API サービス エージェント
| ベースライン |
ユースケース |
Cloud Data Fusion API を有効にすると、Cloud Data Fusion API サービス エージェントのロール(roles/datafusion.serviceAgent)が Cloud Data Fusion サービス アカウント、プライマリ サービス エージェントに自動的に付与されます。
重要ポイント:
- このロールには、BigQuery や Dataproc など、インスタンスと同じプロジェクト内のサービスに対する権限が含まれています。サポートされているすべてのサービスについては、ロールの詳細をご覧ください。
- Cloud Data Fusion サービス アカウントは、次の処理を行います。
- 他のサービスとのデータ プレーン(パイプライン設計と実行)通信(例: 設計時の Cloud Storage、BigQuery、Datastream との通信)。
- Dataproc クラスタをプロビジョニングします。
- Oracle ソースから複製する場合は、このサービス アカウントに、ジョブが発生するプロジェクトで Datastream 管理者とストレージ管理者のロールも付与する必要があります。このページでは、レプリケーションのユースケースについては説明しません。
|
このユースケースでは、Dataproc プロジェクトのサービス アカウントに Cloud Data Fusion API サービス エージェントのロールを付与します。次に、そのプロジェクトで次のロールを付与します。
- Compute ネットワーク ユーザーのロール
- Dataproc 編集者のロール
|
IAM: Dataproc サービス アカウント
| ベースライン |
ユースケース |
Dataproc クラスタ内のジョブとしてパイプラインを実行するために使用されるサービス アカウント。デフォルトでは、Compute Engine サービス アカウントです。
省略可: ベースライン構成で、デフォルトのサービス アカウントを同じプロジェクトの別のサービス アカウントに変更できます。新しいサービス アカウントに次の IAM ロールを付与します。
- Cloud Data Fusion ランナーのロール。このロールにより、Dataproc は Cloud Data Fusion API と通信できます。
- Dataproc ワーカーのロール。このロールを使用すると、ジョブを Dataproc クラスタで実行できます。
重要ポイント:
- Service API エージェントが Dataproc クラスタを起動できるように、新しいサービスの API エージェント サービス アカウントに Dataproc サービス アカウントのサービス アカウント ユーザーロールを付与する必要があります。
|
このユースケースの例では、Dataproc プロジェクトのデフォルトの Compute Engine サービス アカウント(PROJECT_NUMBER-compute@developer.gserviceaccount.com)を使用していることを前提としています。
Dataproc プロジェクトのデフォルトの Compute Engine サービス アカウントに次のロールを付与します。
- Dataproc ワーカーのロール。
- Dataproc が BigQuery の一時バケットを作成できるようにするストレージ管理者のロール(または、少なくとも「storage.buckets.create」権限)。
- BigQuery ジョブユーザーのロール。このロールにより、Dataproc は読み込みジョブを作成できます。ジョブはデフォルトで Dataproc プロジェクトに作成されます。
- BigQuery データセット編集者のロール。このロールにより、Dataproc はデータを読み込むときにデータセットを作成できます。
Dataproc プロジェクトのデフォルトの Compute Engine サービス アカウントの Cloud Data Fusion サービス アカウントに、サービス アカウントのユーザーロールを付与します。この操作は Dataproc プロジェクトで行う必要があります。
Dataproc プロジェクトのデフォルトの Compute Engine サービス アカウントを Cloud Data Fusion プロジェクトに追加します。また、次のロールも付与します。
- Cloud Data Fusion コンシューマ バケットからパイプライン ジョブ関連のアーティファクトを取得するための Storage オブジェクト閲覧者ロール。
- Cloud Data Fusion ランナーのロール。これにより、Dataproc クラスタは実行中に Cloud Data Fusion と通信できます。
|
API
| ベースライン |
ユースケース |
Cloud Data Fusion API を有効にすると、次の API も有効になります。これらの API の詳細については、プロジェクトの [API とサービス] ページに移動してください。
[API とサービス] に移動
- Cloud Autoscaling API
- Dataproc API
- Cloud Dataproc Control API
- Cloud DNS API
- Cloud OS Login API
- Pub/Sub API
- Compute Engine API
- Container Filesystem API
- Container Registry API
- Service Account Credentials API
- Identity and Access Management API
- Google Kubernetes Engine API
Cloud Data Fusion API を有効にすると、次のサービス アカウントがプロジェクトに自動的に追加されます。
- Google API サービス エージェント
- Compute Engine サービス エージェント
- Kubernetes Engine サービス エージェント
- Google Container Registry サービス エージェント
- Google Cloud Dataproc サービス エージェント
- Cloud KMS サービス エージェント
- Cloud Pub/Sub サービス アカウント
|
このユースケースでは、Dataproc プロジェクトを含むプロジェクトで次の API を有効にします。
- Compute Engine API
- Dataproc API(このプロジェクトですでに有効になっている可能性があります)。Dataproc API を有効にすると、Dataproc Control API が自動的に有効になります。
- Resource Manager API。
|
暗号鍵
| ベースライン |
ユースケース |
ベースライン構成では、暗号鍵は Google が管理することも、CMEK にすることもできます。
重要ポイント:
CMEK を使用する場合、ベースライン構成には次の対象が必要です。
- 鍵はリージョンの鍵であり、Cloud Data Fusion インスタンスと同じリージョンに作成する必要があります。
- 作成されたプロジェクトの次のサービス アカウントに( Google Cloud コンソールの IAM ページではなく)、鍵レベルで Cloud KMS 暗号鍵の暗号化/復号のロールを付与します。
- Cloud Data Fusion API サービス アカウント
- Dataproc サービス アカウント、デフォルトでは Compute Engine サービス エージェント(
service-PROJECT_NUMBER@compute-system.iam.gserviceaccount.com)
- Google Cloud Dataproc サービス エージェント
(
service-PROJECT_NUMBER@dataproc-accounts.iam.gserviceaccount.com)
- Cloud Storage サービス エージェント
(
service-PROJECT_NUMBER@gs-project-accounts.iam.gserviceaccount.com)
パイプラインで使用されるサービス(BigQuery や Cloud Storage など)に応じて、サービス アカウントには Cloud KMS 暗号鍵の暗号化 / 復号のロールも付与する必要があります。
- BigQuery サービス アカウント
(
bq-PROJECT_NUMBER@bigquery-encryption.iam.gserviceaccount.com)
- Pub/Sub サービス アカウント
(
service-PROJECT_NUMBER@gcp-sa-pubsub.iam.gserviceaccount.com)
- Spanner サービス アカウント
(
service-PROJECT_NUMBER@gcp-sa-spanner.iam.gserviceaccount.com)
|
CMEK を使用しない場合、このユースケースでは追加の変更は必要ありません。
CMEK を使用する場合、作成されたプロジェクトの次のサービス アカウントに、鍵レベルで Cloud KMS CryptoKey の暗号化 / 復号のロールを、提供する必要があります。
- Cloud Storage サービス エージェント
(
service-PROJECT_NUMBER@gs-project-accounts.iam.gserviceaccount.com)
パイプラインで使用されるサービス(BigQuery や Cloud Storage など)に応じて、他のサービス アカウントに鍵レベルで Cloud KMS 暗号鍵の暗号化 / 復号のロールも付与する必要があります。例:
- BigQuery サービス アカウント
(
bq-PROJECT_NUMBER@bigquery-encryption.iam.gserviceaccount.com)
- Pub/Sub サービス アカウント
(
service-PROJECT_NUMBER@gcp-sa-pubsub.iam.gserviceaccount.com)
- Spanner サービス アカウント
(
service-PROJECT_NUMBER@gcp-sa-spanner.iam.gserviceaccount.com)
|
これらのユースケース固有の構成を行った後、データ パイプラインを別のプロジェクトのクラスタで実行できます。
次のステップ
特に記載のない限り、このページのコンテンツはクリエイティブ・コモンズの表示 4.0 ライセンスにより使用許諾されます。コードサンプルは Apache 2.0 ライセンスにより使用許諾されます。詳しくは、Google Developers サイトのポリシーをご覧ください。Java は Oracle および関連会社の登録商標です。
最終更新日 2025-10-19 UTC。
[[["わかりやすい","easyToUnderstand","thumb-up"],["問題の解決に役立った","solvedMyProblem","thumb-up"],["その他","otherUp","thumb-up"]],[["わかりにくい","hardToUnderstand","thumb-down"],["情報またはサンプルコードが不正確","incorrectInformationOrSampleCode","thumb-down"],["必要な情報 / サンプルがない","missingTheInformationSamplesINeed","thumb-down"],["翻訳に関する問題","translationIssue","thumb-down"],["その他","otherDown","thumb-down"]],["最終更新日 2025-10-19 UTC。"],[],[]]