Cloud Data Fusion data lineage
You can use Cloud Data Fusion data lineage to do the following:
Detect the root cause of bad data events.
Perform an impact analysis before making data changes.
We recommend using asset lineage integration in Dataplex Universal Catalog. For more information see, View lineage in Dataplex Universal Catalog.
You can also view lineage at the dataset and field levels in the Cloud Data Fusion Studio using the Metadata option, which shows lineage for a selected time range.
Dataset level lineage shows the relationship between datasets and pipelines.
Field level lineage shows the operations that were performed on a set of fields in the source dataset to produce a different set of fields in the target dataset.
From Cloud Data Fusion 6.9.2.4 onwards, if you don't track lineage in
Cloud Data Fusion, we recommend turning off field level lineage
emission in your instance using the
patch
method:
curl -X PATCH -H 'Content-Type: application/json' -H "Authorization: Bearer
$(gcloud auth print-access-token)"
'https://datafusion.googleapis.com/v1beta1/projects/PROJECT_ID/locations/REGION/instances/INSTANCE_ID?updateMask=options'
-d '{ "options": { "metadata.messaging.field.lineage.emission.enabled": "false" } }'
Replace the following:
PROJECT_ID: the Google Cloud project IDREGION: the location of the Google Cloud projectINSTANCE_ID: the Cloud Data Fusion instance ID
Tutorial Scenario
In this tutorial, you work with two pipelines:
The
Shipment Data Cleansingpipeline reads raw shipment data from a small sample dataset and applies transformations to clean the data.The
Delayed Shipments USApipeline then reads the cleansed shipment data, analyzes it, and finds shipments within the USA that were delayed by more than a threshold.
These tutorial pipelines demonstrate a typical scenario in which raw data is cleaned then sent for downstream processing. This data trail from raw data to the cleaned shipment data to analytic output can be explored using the Cloud Data Fusion lineage feature.
Objectives
- Produce lineage by running sample pipelines
- Explore dataset and field level lineage
- Learn how to pass handshaking information from the upstream pipeline to the downstream pipeline
Costs
In this document, you use the following billable components of Google Cloud:
- Cloud Data Fusion
- Cloud Storage
- BigQuery
To generate a cost estimate based on your projected usage,
use the pricing calculator.
Before you begin
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Cloud Data Fusion, Cloud Storage, Dataproc, and BigQuery APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. - Create a Cloud Data Fusion instance.
- Click the following links to download these small sample datasets to your local machine:
Open the Cloud Data Fusion UI
When using Cloud Data Fusion, you use both the Google Cloud console and the separate Cloud Data Fusion UI. In the Google Cloud console, you can create a Google Cloud console project, and create and delete Cloud Data Fusion instances. In the Cloud Data Fusion UI, you can use the various pages, such as Lineage, to access Cloud Data Fusion features.
In the Google Cloud console, open the Instances page.
In the Actions column for the instance, click the View Instance link. The Cloud Data Fusion UI opens in a new browser tab.
In the Integrate pane, click Studio to open the Cloud Data Fusion Studio page.

Deploy and run pipelines
Import the raw Shipping Data. On the Studio page, click Import or click + > Pipeline > Import, and then select and import the Shipment Data Cleansing pipeline that you downloaded in Before you begin.

Deploy the pipeline. Click Deploy in the top-right of the Studio page. After deployment, the Pipeline page opens.
Run the pipeline. Click Run in the top-center of the Pipeline page.
Import, deploy, and run the Delayed Shipments data and pipeline. After the status of the Shipping Data Cleansing shows Succeeded, apply the preceding steps to the Delayed Shipments USA data that you downloaded in Before You Begin. Return to the Studio page to import the data, then deploy and run this second pipeline from the Pipeline page. After the second pipeline completes successfully, proceed with the remaining steps.
Discover datasets
You must discover a dataset before exploring its lineage. Select Metadata from the Cloud Data Fusion UI left navigation panel to open the metadata Search page. Since the Shipment Data Cleansing dataset specified Cleaned-Shipments as the reference dataset, insert shipment in the Search box. The search results include this dataset.

Using tags to discover datasets
A Metadata search discovers datasets that have been consumed, processed, or generated by Cloud Data Fusion pipelines. Pipelines execute on a structured framework that generates and collects technical and operational metadata. The technical metadata includes dataset name, type, schema, fields, creation time, and processing information. This technical information is used by the Cloud Data Fusion metadata search and lineage features.
Cloud Data Fusion also supports the annotation of datasets with business metadata, such as tags and key-value properties, which can be used as search criteria. For example, to add and search for a business tag annotation on the Raw Shipping Data dataset:
Click the Properties button of the Raw Shipping Data node on the Shipment Data Cleansing Pipeline page to open the Cloud Storage Properties page.
Click View Metadata to open the Search page.
Under Business Tags, click + then insert a tag name (alphanumeric and underscore characters are allowed) and press Enter.

Explore lineage
Dataset level lineage
Click the Cleaned-Shipments dataset name listed on the Search page (from Discover datasets), then click the Lineage tab. The lineage graph shows that this dataset was generated by the Shipments-Data-Cleansing pipeline, which had consumed the Raw_Shipping_Data dataset.
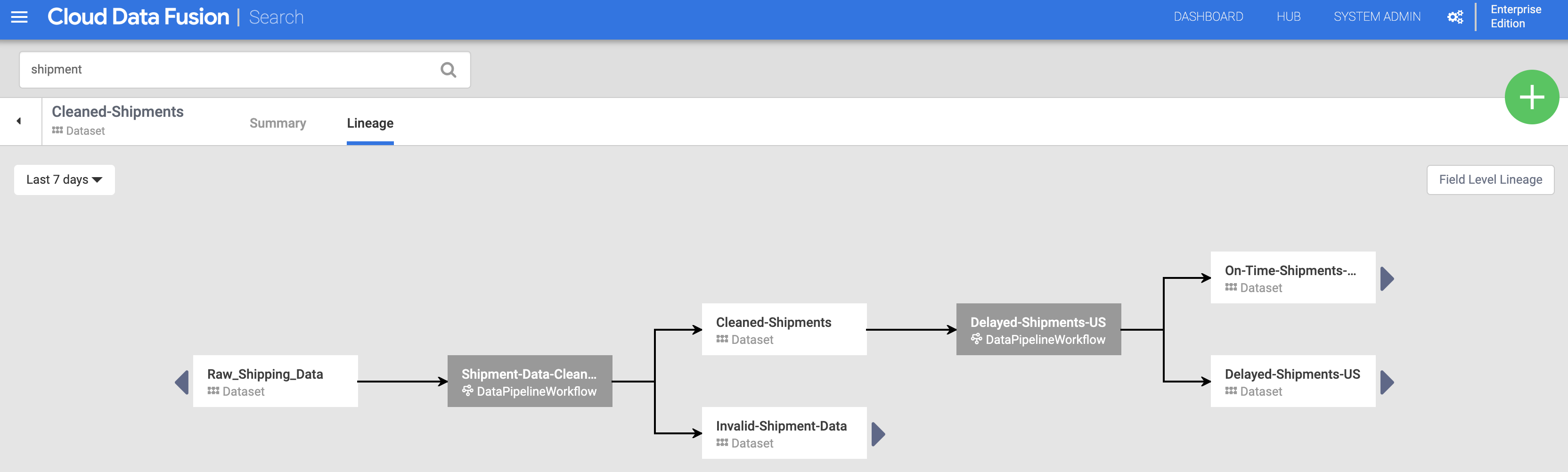
The left and right arrows let you navigate back and forward through any previous or subsequent dataset lineage. In this example, the graph displays the full lineage for the Cleaned-Shipments dataset.
Field level lineage
Cloud Data Fusion field level lineage shows the relationship between the fields of a dataset and the transformations that were performed on a set of fields to produce a different set of fields. Like dataset level lineage, field level lineage is time-bound, and its results change with time.
Continuing from the Dataset level lineage step, click the Field Level Lineage button in the top right of the Cleaned Shipments dataset-level lineage graph to display its field level lineage graph.
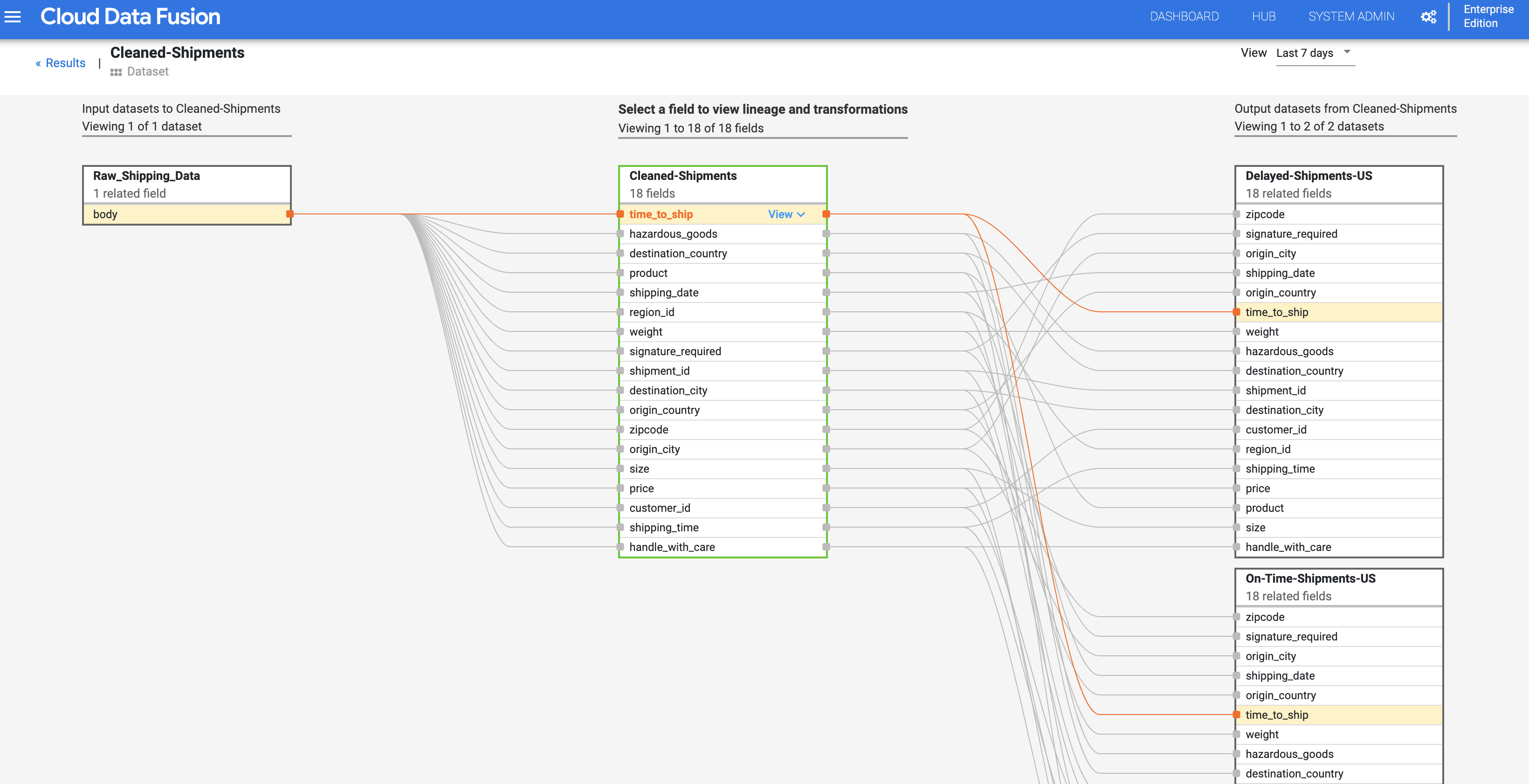
The field level lineage graph shows connections between fields. You can select a field to view its lineage. Select View > Pin field to view lineage of that field only.
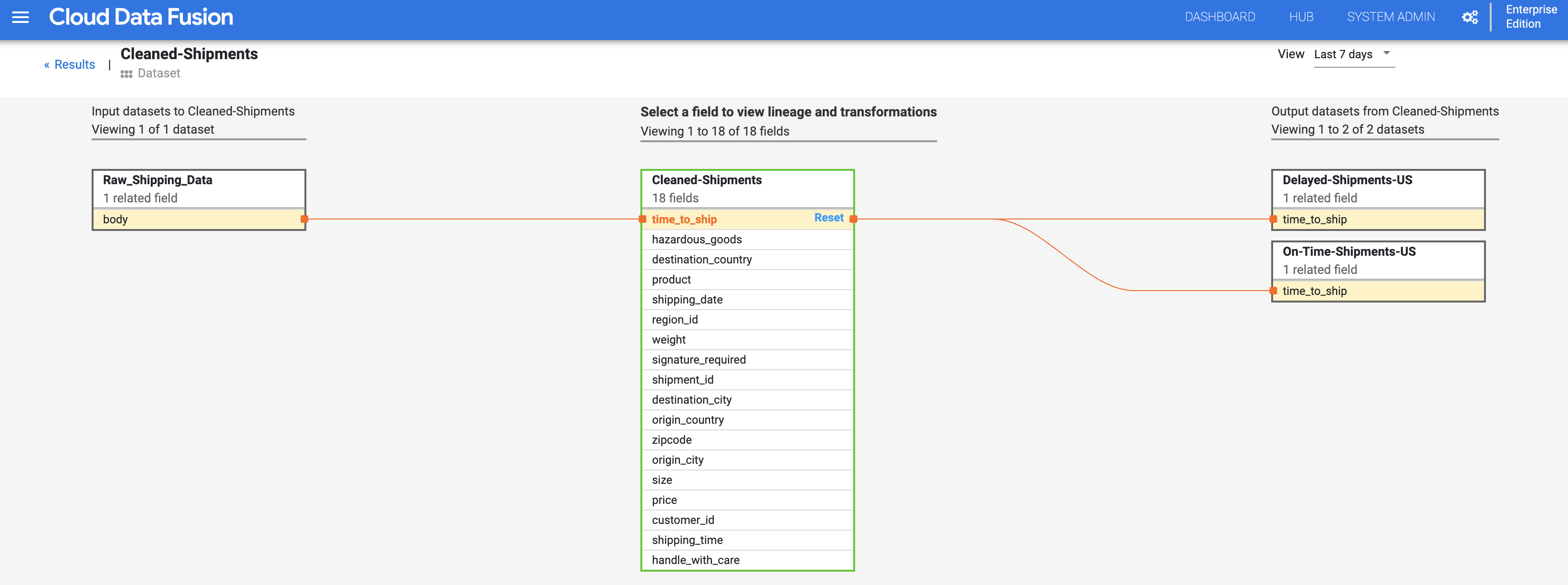
Select View > View impact to perform an impact analysis.

The cause and impact links show the transformations performed on both sides of a field in a human-readable ledger format. This information can be essential for reporting and governance.
Clean up
To avoid incurring charges to your Google Cloud account for the resources used in this tutorial, either delete the project that contains the resources, or keep the project and delete the individual resources.
After you've finished the tutorial, clean up the resources you created on Google Cloud so they won't take up quota and you won't be billed for them in the future. The following sections describe how to delete or turn off these resources.
Delete the tutorial dataset
This tutorial creates a logistics_demo dataset with several tables in your project.
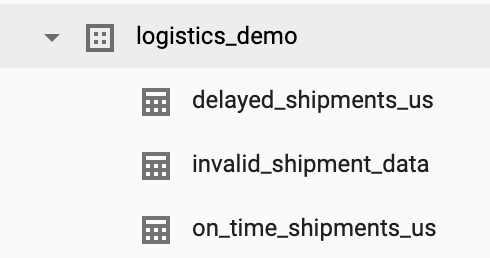
You can delete the dataset from the BigQuery Web UI in the Google Cloud console.
Delete the Cloud Data Fusion instance
Follow the instructions to delete your Cloud Data Fusion instance.
Delete the project
The easiest way to eliminate billing is to delete the project that you created for the tutorial.
To delete the project:
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
What's next
- Read the how-to guides
- Work through another tutorial