Ce guide explique comment déployer, configurer et exécuter des pipelines de données qui utilisent le plug-in SAP OData.
Vous pouvez utiliser SAP en tant que source pour l'extraction de données par lots dans Cloud Data Fusion à l'aide du protocole OData (Open Data Protocol). Le plug-in SAP OData vous aide à configurer et à exécuter des transferts de données à partir de SAP OData Catalog Services sans aucun codage.
Pour en savoir plus sur les services et les sources de données de catalogue OData SAP compatibles, consultez les informations d'assistance. Pour en savoir plus sur SAP surGoogle Cloud, consultez la présentation de SAP sur Google Cloud.
Objectifs
- Configurez le système SAP ERP (activer DataSources dans SAP).
- Déployez le plug-in dans votre environnement Cloud Data Fusion.
- Téléchargez le transport SAP à partir de Cloud Data Fusion et installez-le dans SAP.
- Utilisez Cloud Data Fusion et SAP OData pour créer des pipelines de données destinés à l'intégration des données SAP.
Avant de commencer
Pour utiliser ce plug-in, vous devez connaître les domaines suivants :
- Créer des pipelines dans Cloud Data Fusion
- Gestion des accès avec IAM
- Configurer SAP Cloud et les systèmes ERP sur site
Rôles utilisateur
Les tâches de cette page sont effectuées par des personnes disposant des rôles suivants dans Google Cloud ou dans leur système SAP:
| Type d’utilisateur | Description |
|---|---|
| Administrateur Google Cloud | Les utilisateurs auxquels ce rôle est attribué sont des administrateurs de compte Google Cloud. |
| Utilisateur Cloud Data Fusion | Les utilisateurs auxquels ce rôle est attribué sont autorisés à concevoir et à exécuter des pipelines de données. Ils disposent au minimum du rôle Lecteur Data Fusion (
roles/datafusion.viewer). Si vous utilisez le contrôle des accès basé sur les rôles, vous aurez peut-être besoin de rôles supplémentaires.
|
| Administrateur SAP | Les utilisateurs auxquels ce rôle est attribué sont les administrateurs du système SAP. Ils ont accès à la page de téléchargement du logiciel à partir du site de service SAP. Il ne s'agit pas d'un rôle IAM. |
| Utilisateur SAP | Les utilisateurs auxquels ce rôle est attribué sont autorisés à se connecter à un système SAP. Il ne s'agit pas d'un rôle IAM. |
Conditions préalables à l'extraction OData
Le service de catalogue OData doit être activé dans le système SAP.
Les données doivent être renseignées dans le service OData.
Prérequis pour votre système SAP
Dans les versions SAP NetWeaver 7.02 à SAP NetWeaver 7.31, les fonctionnalités OData et SAP Gateway sont fournies avec les composants logiciels SAP suivants:
IW_FNDGW_COREIW_BEP
Dans la version 7.40 de SAP NetWeaver et les versions ultérieures, toutes les fonctionnalités sont disponibles dans le composant
SAP_GWFND, qui doit être mis à disposition dans SAP NetWeaver.
Facultatif: Installer des fichiers de transport SAP
Les composants SAP nécessaires pour l'équilibrage de charge des appels vers SAP sont envoyés sous forme de fichiers de transport SAP archivés sous forme de fichier ZIP (une requête de transport composée d'un cofile et d'un fichier de données). Vous pouvez utiliser cette étape pour limiter les appels parallèles multiples à SAP, en fonction des processus de travail disponibles dans SAP.
Le téléchargement du fichier ZIP est disponible lorsque vous déployez le plug-in dans le hub Cloud Data Fusion.
Lorsque vous importez les fichiers de transport dans SAP, les projets SAP OData suivants sont créés:
Projets OData
/GOOG/GET_STATISTIC/GOOG/TH_WPINFO
Nœud de service ICF:
GOOG
Pour installer le transport SAP, procédez comme suit :
Étape 1 : Importer les fichiers de requête de transport
- Connectez-vous au système d'exploitation de l'instance SAP.
- Utilisez le code de transaction SAP
AL11pour obtenir le chemin d'accès du dossierDIR_TRANS. Le chemin d'accès est généralement/usr/sap/trans/. - Copiez les fichiers cofile dans le dossier
DIR_TRANS/cofiles. - Copiez les fichiers de données dans le dossier
DIR_TRANS/data. - Définissez l'utilisateur et le groupe de données et de cofichier sur
<sid>admetsapsys.
Étape 2 : Importer les fichiers de requête de transport
L'administrateur SAP peut importer les fichiers de requête de transport de l'une des façons suivantes :
Option 1 : Importer les fichiers de requête de transport à l'aide du système de gestion des transports SAP
- Connectez-vous au système SAP en tant qu'administrateur SAP.
- Saisissez le code STMS de la transaction.
- Cliquez sur Présentation > Importations.
- Dans la colonne File d'attente, double-cliquez sur le SID actuel.
- Cliquez sur Extras > Autres requêtes > Ajouter.
- Sélectionnez l'ID de la requête de transport, puis cliquez sur Continuer.
- Sélectionnez la demande de transport dans la file d'attente d'importation, puis cliquez sur Demander > Importer.
- Saisissez le numéro client.
Dans l'onglet Options, sélectionnez Écraser les versions d'origine et Ignorer la version de composant non valide (si disponible).
(Facultatif) Pour programmer une nouvelle importation des transports pour une utilisation ultérieure, sélectionnez Laisser des requêtes de transport en file d'attente pour une importation ultérieure et Importer à nouveau les requêtes de transport. Cette fonctionnalité est utile pour les mises à niveau du système SAP et les restaurations de sauvegarde.
Cliquez sur Continuer.
Pour vérifier l'importation, utilisez des transactions, telles que
SE80etSU01.
Option 2 : Importer les fichiers de requête de transport au niveau du système d'exploitation
- Connectez-vous au système SAP en tant qu'administrateur de système SAP.
Ajoutez les requêtes appropriées au tampon d'importation en exécutant la commande suivante :
tp addtobuffer TRANSPORT_REQUEST_ID SIDPar exemple :
tp addtobuffer IB1K903958 DD1Importez les requêtes de transport en exécutant la commande suivante :
tp import TRANSPORT_REQUEST_ID SID client=NNN U1238Remplacez
NNNpar le numéro client. Exemple :tp import IB1K903958 DD1 client=800 U1238.Vérifiez que le module de fonction et les rôles d'autorisation ont bien été importés à l'aide des transactions appropriées, telles que
SE80etSU01.
Obtenir la liste des colonnes filtrables pour un service de catalogue SAP
Seules certaines colonnes DataSource peuvent être utilisées pour les conditions de filtre (il s'agit d'une limitation SAP par nature).
Pour obtenir la liste des colonnes filtrables d'un service de catalogue SAP, procédez comme suit:
- Connectez-vous au système SAP.
- Accédez au code t
SEGW. Saisissez le nom du projet OData, qui est une sous-chaîne du nom du service. Exemple :
- Nom du service :
MM_PUR_POITEMS_MONI_SRV - Nom du projet :
MM_PUR_POITEMS_MONI
- Nom du service :
Appuyez sur Entrée.
Accédez à l'entité que vous souhaitez filtrer, puis sélectionnez Properties (Propriétés).
Vous pouvez utiliser les champs affichés dans la section Propriétés en tant que filtres. Les opérations acceptées sont Equal (Égal à) et Between (Entre : plage).

Pour obtenir la liste des opérateurs compatibles avec le langage d'expression, consultez la documentation Open Source OData: Conventions URI (version 2.0 d'OData).
Exemple d'URI avec filtres:
/sap/opu/odata/sap/MM_PUR_POITEMS_MONI_SRV/C_PurchaseOrderItemMoni(P_DisplayCurrency='USD')/Results/?$filter=(PurchaseOrder eq '4500000000')
Configurer le système ERP SAP
Le plug-in SAP OData utilise un service OData activé sur chaque serveur SAP à partir duquel les données sont extraites. Ce service OData peut être une norme fournie par SAP ou un service OData personnalisé développé sur votre système SAP.
Étape 1: Installez SAP Gateway 2.0
L'administrateur SAP (Basis) doit vérifier que les composants SAP Gateway 2.0 sont disponibles dans le système source SAP, en fonction de la version de NetWeaver. Pour en savoir plus sur l'installation de SAP Gateway 2.0, connectez-vous à SAP ONE Support Launchpad et consultez la note 1569624 (connexion requise) .
Étape 2: Activez le service OData
Activez le service OData requis sur le système source. Pour en savoir plus, consultez Serveur d'interface: activer les services OData.
Étape 3: Créer un rôle d'autorisation
Pour vous connecter à la source de données, créez un rôle d'autorisation avec les autorisations requises dans SAP, puis attribuez-le à l'utilisateur SAP.
Pour créer le rôle d'autorisation dans SAP, procédez comme suit :
- Dans l'IUG SAP, saisissez le code de transaction PFCG pour ouvrir la fenêtre Maintenance des rôles.
Dans le champ Rôle, saisissez un nom pour le rôle.
Par exemple :
ZODATA_AUTHCliquez sur Rôle unique.
La fenêtre Créer des rôles s'ouvre.
Dans le champ Description, saisissez une description, puis cliquez sur Enregistrer.
Exemple :
Authorizations for SAP OData plugin.Cliquez sur l'onglet Autorisations. Le titre de la fenêtre passe à Modifier les rôles.
Sous Modifier les données d'autorisation et générer des profils, cliquez sur Modifier les données d'autorisation.
La fenêtre Choisir un modèle s'ouvre.
Cliquez sur Ne pas sélectionner de modèles.
La fenêtre Modifier le rôle : Autorisations s'ouvre.
Cliquez sur Manuellement.
Fournissez les autorisations indiquées dans le tableau suivant.
Cliquez sur Enregistrer.
Pour activer le rôle d'autorisation, cliquez sur l'icône Générer.
Autorisations SAP
| Classe d'objet | Texte de classe d'objet | Objet d'autorisation | Texte d'objet d'autorisation | Autorisation | Texte | Valeur |
|---|---|---|---|---|---|---|
| AAAB | Objets d'autorisation inter-applications | S_SERVICE | Vérifier au démarrage des services externes | SRV_NAME | Nom du programme, de la transaction ou du module de fonction | * |
| AAAB | Objets d'autorisation inter-applications | S_SERVICE | Vérifier au démarrage des services externes | SRV_TYPE | Type d'indicateur de vérification et valeurs par défaut d'autorisation | HT |
| VEN | Comptabilité financière | F_UNI_HIER | Accès universel à la hiérarchie | ACTVT | Activité | 03 |
| VEN | Comptabilité financière | F_UNI_HIER | Accès universel à la hiérarchie | HRYTYPE | Type de hiérarchie | * |
| VEN | Comptabilité financière | F_UNI_HIER | Accès universel à la hiérarchie | HRYID | ID de hiérarchie | * |
Pour concevoir et exécuter un pipeline de données dans Cloud Data Fusion (en tant qu'utilisateur Cloud Data Fusion), vous avez besoin d'identifiants utilisateur SAP (nom d'utilisateur et mot de passe) pour configurer le plug-in afin qu'il se connecte à la source de données.
L'utilisateur SAP doit être de type Communications ou Dialog. Pour éviter d'utiliser les ressources de boîte de dialogue SAP, le type Communications est recommandé. Les utilisateurs peuvent être créés à l'aide du code de transaction SU01 SAP.
Facultatif: Étape 4: Sécurisez la connexion
Vous pouvez sécuriser la communication sur le réseau entre votre instance Cloud Data Fusion privée et SAP.
Pour sécuriser la connexion, procédez comme suit:
- L'administrateur SAP doit générer un certificat X509. Pour générer le certificat, consultez Créer un PSE de serveur SSL.
- L' Google Cloud administrateur doit copier le fichier X509 dans un bucket Cloud Storage lisible dans le même projet que l'instance Cloud Data Fusion, puis indiquer le chemin d'accès au bucket à l'utilisateur Cloud Data Fusion, qui le saisit lorsqu'il configure le plug-in.
- L'administrateur Google Cloud doit accorder un accès en lecture au fichier X509 à l'utilisateur Cloud Data Fusion qui conçoit et exécute des pipelines.
Facultatif: Étape 5: Créer des services OData personnalisés
Vous pouvez personnaliser l'extraction des données en créant des services OData personnalisés dans SAP:
- Pour créer des services OData personnalisés, consultez Créer des services OData pour les débutants.
- Pour créer des services OData personnalisés à l'aide de vues de services de données de base (CDS), consultez la section Créer un service OData et exposer des vues CDS en tant que service OData.
- Tout service OData personnalisé doit prendre en charge les requêtes
$top,$skipet$count. Ces requêtes permettent au plug-in de partitionner les données pour une extraction séquentielle et parallèle. Si elles sont utilisées, les requêtes$filter,$expandou$selectdoivent également être compatibles.
Configurer Cloud Data Fusion
Assurez-vous que la communication est activée entre l'instance Cloud Data Fusion et le serveur SAP. Pour les instances privées, configurez l'appairage de réseaux. Une fois l'appairage de réseaux établi avec le projet hébergeant les systèmes SAP, aucune configuration supplémentaire n'est requise pour la connexion à votre instance Cloud Data Fusion. Le système SAP et l'instance Cloud Data Fusion doivent se trouver dans le même projet.
Étape 1: Configurez votre environnement Cloud Data Fusion
Pour configurer votre environnement Cloud Data Fusion pour le plug-in, procédez comme suit :
Accédez aux détails de l'instance :
Dans la Google Cloud console, accédez à la page Cloud Data Fusion.
Cliquez sur Instances, puis sur le nom de l'instance pour accéder à la page Détails de l'instance.
Vérifiez que l'instance a été mise à niveau vers la version 6.4.0 ou ultérieure. Si l'instance utilise une version antérieure, vous devez la mettre à niveau.
Cliquez sur Afficher l'instance. Lorsque l'interface utilisateur de Cloud Data Fusion s'ouvre, cliquez sur Hub.
Sélectionnez l'onglet SAP > SAP OData.
Si l'onglet SAP n'est pas visible, consultez la section Résoudre les problèmes d'intégration de SAP.
Cliquez sur Déployer le plug-in SAP OData.
Le plug-in apparaît désormais dans le menu Source de la page Studio.
Étape 2: Configurer le plug-in
Le plug-in SAP OData lit le contenu d'une source de données SAP.
Pour filtrer les enregistrements, vous pouvez configurer les propriétés suivantes sur la page "Propriétés SAP OData".
| Nom de propriété | Description |
|---|---|
| Basic | |
| Nom de référence | Nom utilisé pour identifier de manière unique cette source pour la traçabilité ou l'annotation de métadonnées. |
| URL de base SAP OData | URL de base OData de SAP Gateway (utilisez le chemin d'URL complet, semblable à https://ADDRESS:PORT/sap/opu/odata/sap/).
|
| Version OData | Version SAP OData compatible. |
| Nom du service | Nom du service OData SAP à partir duquel vous souhaitez extraire une entité. |
| Nom de l'entité | Nom de l'entité extraite (par exemple, Results) Vous pouvez utiliser un préfixe, tel que C_PurchaseOrderItemMoni/Results. Ce champ accepte les paramètres de catégorie et d'entité. Exemples :
|
| Identifiants* | |
| Type SAP | Basique (via un nom d'utilisateur et un mot de passe). |
| Nom d'utilisateur de connexion SAP | Nom d'utilisateur SAP Recommandé: si le nom d'utilisateur de connexion SAP change régulièrement, utilisez une macro. |
| Mot de passe d'ouverture de session SAP | Mot de passe utilisateur SAP Recommandé: Utilisez des macros sécurisées pour les valeurs sensibles, telles que les mots de passe. |
| Certificat client X.509 SAP (voir Utiliser des certificats client X.509 sur le serveur d'applications SAP NetWeaver pour ABAP) |
|
| ID de projet GCP | Identifiant unique global pour votre projet. Ce champ est obligatoire si le champ Chemin d'accès Cloud Storage du certificat X.509 ne contient pas de valeur de macro. |
| Chemin d'accès GCS | Chemin d'accès au bucket Cloud Storage contenant le certificat X.509 importé par l'utilisateur, qui correspond au serveur d'applications SAP pour les appels sécurisés en fonction de vos exigences (voir l'étape Sécuriser la connexion). |
| Phrase secrète | Phrase de passe correspondant au certificat X.509 fourni. |
| Bouton Obtenir un schéma | Génère un schéma basé sur les métadonnées de SAP, avec mappage automatique des types de données SAP sur les types de données Cloud Data Fusion correspondants (même fonctionnalité que le bouton Valider). |
| Avancé | |
| Options de filtrage | Indique la valeur qu'un champ doit avoir pour être lu. Utilisez cette condition de filtre pour limiter le volume de données de sortie. Par exemple, "Price Gt 200" sélectionne les enregistrements dont la valeur du champ "Price" est supérieure à "200". (Voir Obtenir la liste des colonnes filtrables pour un service de catalogue SAP.) |
| Sélectionner des champs | Champs à conserver dans les données extraites (par exemple, "Catégorie", "Prix", "Nom", "Fournisseur/Adresse"). |
| Développer les champs | Liste des champs complexes à développer dans les données de sortie extraites (par exemple, "Produits/Fournisseurs"). |
| Nombre de lignes à ignorer | Nombre total de lignes à ignorer (par exemple, 10). |
| Nombre de lignes à extraire | Nombre total de lignes à extraire. |
| Nombre de divisions à générer | Nombre de répartitions utilisées pour partitionner les données d'entrée. Plus de partitions augmentent le niveau de parallélisme, mais nécessitent plus de ressources et de frais généraux. Si vous ne spécifiez pas de valeur, le plug-in choisit une valeur optimale (recommandé). |
| Taille de lot | Nombre de lignes à récupérer dans chaque appel réseau vers SAP. Une taille de package réduite entraîne une fréquence plus élevée d'appels réseau. Une taille importante peut ralentir la récupération des données et entraîner une utilisation excessive des ressources dans SAP.
Si la valeur est définie sur 0, la valeur par défaut est 2500 et la limite de lignes à extraire dans chaque lot est 5000. |
| Délai avant expiration de la lecture | Durée d'attente (en secondes) pour le service SAP OData. La valeur par défaut est 300. Pour ne pas appliquer de limite de temps, définissez cette valeur sur 0. |
Types OData acceptés
Le tableau suivant présente le mappage entre les types de données OData v2 utilisés dans les applications SAP et les types de données Cloud Data Fusion.
| Type OData | Description (SAP) | Type de données Cloud Data Fusion |
|---|---|---|
| Numérique | ||
| SByte | Valeur d'entier signé 8 bits | int |
| Byte | Valeur entière non signée de 8 bits | int |
| Int16 | Valeur d'entier signé 16 bits | int |
| Int32 | Valeur d'entier signé de 32 bits | int |
| Int64 | Valeur d'entier signé de 64 bits suivie du caractère: "L" Exemples: 64L, -352L |
long |
| Unique | Nombre à virgule flottante avec une précision de sept chiffres pouvant représenter des valeurs avec une plage approximative de ± 1,18e-38 à ± 3,40e+38, suivi du caractère: "f" Exemple: 2.0f |
float |
| Double | Nombre à virgule flottante avec une précision de 15 chiffres pouvant représenter des valeurs avec des plages approximatives de ± 2,23e-308 à ± 1,79e+308, suivi du caractère: 'd' Exemples: 1E+10d, 2.029d, 2.0d |
double |
| Decimal | Valeurs numériques avec une précision et une échelle fixes décrivant une valeur numérique allant de -10^255 + 1 à 10^255 - 1, suivies du caractère: "M" ou "m" Exemple: 2.345M |
decimal |
| Caractère | ||
| GUID | Valeur d'identifiant unique de 16 octets (128 bits), commençant par le caractère: "guid" Exemple: guid'12345678-aaaa-bbbb-cccc-ddddeeeeffff' |
string |
| Chaîne | Données de caractères de longueur fixe ou variable encodées en UTF-8 | string |
| Byte | ||
| Binaire | Données binaires de longueur fixe ou variable, commençant par "X" ou "binary" (les deux sont sensibles à la casse) Exemple: X'23AB', binary'23ABFF' |
bytes |
| Logique | ||
| Booléen | Concept mathématique de logique à valeurs binaires | boolean |
| Date/Heure | ||
| Date/Heure | Date et heure, avec des valeurs comprises entre 00h00:00 le 1er janvier 1753 et 23h59:59 le 31 décembre 9999 | timestamp |
| Heure | Heure de la journée, avec des valeurs comprises entre 0:00:00.x et 23:59:59.y, où "x" et "y" dépendent de la précision | time |
| DateTimeOffset | Date et heure sous la forme d'un décalage, en minutes par rapport au GMT, avec des valeurs comprises entre 00h00:00 le 1er janvier 1753 et 23h59:59 le 31 décembre 9999 | timestamp |
| Complexe | ||
| Propriétés de navigation et non de navigation (multiplicité = *) | Collections d'un type, avec une multiplicité de type un à plusieurs. | array,string,int. |
| Propriétés (multiplicité = 0,1) | Références à d'autres types complexes avec une multiplicité de relations un à un | record |
Validation
Cliquez sur Valider en haut à droite ou sur Obtenir un schéma.
Le plug-in valide les propriétés et génère un schéma basé sur les métadonnées de SAP. Il mappe automatiquement les types de données SAP sur les types de données Cloud Data Fusion correspondants.
Exécuter un pipeline de données
- Après avoir déployé le pipeline, cliquez sur Configurer dans le panneau supérieur central.
- Sélectionnez Ressources.
- Si nécessaire, modifiez le processeur d'exécuteur et la mémoire en fonction de la taille globale des données et du nombre de transformations utilisées dans le pipeline.
- Cliquez sur Enregistrer.
- Pour démarrer le pipeline de données, cliquez sur Exécuter.
Performances
Le plug-in utilise les fonctionnalités de parallélisation de Cloud Data Fusion. Les instructions suivantes vous aideront à configurer l'environnement d'exécution afin de fournir suffisamment de ressources au moteur d'exécution pour atteindre le degré de parallélisme et de performances attendu.
Optimiser la configuration du plug-in
Recommandation:Sauf si vous connaissez les paramètres de mémoire de votre système SAP, laissez les champs Nombre de divisions à générer et Taille de lot vides (non spécifiés).
Pour de meilleures performances lorsque vous exécutez votre pipeline, utilisez les configurations suivantes:
Number of Splits to Generate (Nombre de divisions à générer) : des valeurs comprises entre
8et16sont recommandées. Toutefois, elles peuvent augmenter jusqu'à32, voire64, avec les configurations appropriées côté SAP (allouer les ressources de mémoire appropriées pour les processus de travail dans SAP). Cette configuration améliore le parallélisme du côté de Cloud Data Fusion. Le moteur d'exécution crée le nombre de partitions spécifié (et les connexions SAP requises) lors de l'extraction des enregistrements.Si le service de configuration (fourni avec le plug-in lorsque vous importez le fichier de transport SAP) est disponible, le plug-in utilise par défaut la configuration du système SAP. Les fractionnements représentent 50% des processus de travail de boîte de dialogue disponibles dans SAP. Remarque: Le service de configuration ne peut être importé que depuis des systèmes S/4HANA.
Si le service de configuration n'est pas disponible, la valeur par défaut est
7.Dans les deux cas, si vous spécifiez une valeur différente, celle que vous fournissez prévaut sur la valeur de fractionnement par défaut,sauf qu'elle est limitée par les processus de boîte de dialogue disponibles dans SAP, moins deux fractionnements.
Si le nombre d'enregistrements à extraire est inférieur à
2500, le nombre de fractionnements est1.
Taille du lot: nombre d'enregistrements à récupérer dans chaque appel réseau vers SAP. Une taille de lot plus petite entraîne des appels réseau fréquents, ce qui répète les frais généraux associés. Par défaut, le nombre minimal est
1000et le nombre maximal est50000.
Pour en savoir plus, consultez la section Limites des entités OData.
Paramètres de ressources Cloud Data Fusion
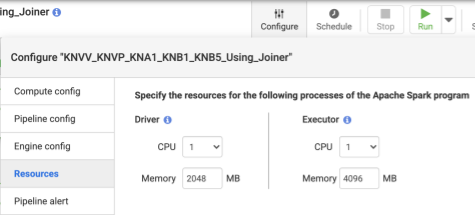
Recommandé:Utilisez 1 CPU et 4 Go de mémoire par exécuteur (cette valeur s'applique à chaque processus d'exécuteur). Définissez ces paramètres dans la boîte de dialogue Configurer > Ressources.
Paramètres du cluster Dataproc
Recommandé:attribuez au minimum un nombre total de processeurs (sur les nœuds de calcul) supérieur au nombre souhaité de divisions (consultez la section Configuration du plug-in).
Dans les paramètres Dataproc, chaque nœud de calcul doit disposer d'au moins 6,5 Go de mémoire allouée par processeur (ce qui correspond à 4 Go ou plus disponibles par Cloud Data Fusion Executor). Vous pouvez conserver les valeurs par défaut pour les autres paramètres.
Recommandé:Utilisez un cluster Dataproc persistant pour réduire le temps d'exécution du pipeline de données (cette opération élimine l'étape de provisionnement qui peut prendre quelques minutes ou plus). Définissez ce paramètre dans la section de configuration de Compute Engine.
Exemples de configurations et débit
Les sections suivantes décrivent des exemples de configurations de développement et de production, ainsi que le débit.
Exemples de configurations de développement et de test
- Cluster Dataproc avec huit nœuds de calcul, chacun avec quatre CPU et 26 Go de mémoire. Générez jusqu'à 28 divisions.
- Cluster Dataproc avec deux nœuds de calcul, chacun avec huit CPU et 52 Go de mémoire Générez jusqu'à 12 divisions.
Exemples de configurations et de débit en production
- Cluster Dataproc avec 8 nœuds de calcul, chacun avec 8 CPU et 32 Go de mémoire Générez jusqu'à 32 fractionnements (la moitié des processeurs disponibles).
- Cluster Dataproc avec 16 nœuds de calcul, chacun avec 8 processeurs et 32 Go de mémoire. Générez jusqu'à 64 fractionnements (la moitié des processeurs disponibles).
Exemple de débit pour un système source de production SAP S4HANA 1909
Le tableau suivant présente un exemple de débit. Le débit affiché n'inclut pas d'options de filtrage, sauf indication contraire. Lorsque vous utilisez des options de filtrage, le débit est réduit.
| Taille de lot | Tours | Service OData | Nombre total de lignes | Lignes extraites | Débit (lignes par seconde) |
|---|---|---|---|---|---|
| 1000 | 4 | ZACDOCA_CDS | 5,37 M | 5,37 M | 1069 |
| 2500 | 10 | ZACDOCA_CDS | 5,37 M | 5,37 M | 3384 |
| 5000 | 8 | ZACDOCA_CDS | 5,37 M | 5,37 M | 4630 |
| 5000 | 9 | ZACDOCA_CDS | 5,37 M | 5,37 M | 4817 |
Exemple de débit pour un système source de production cloud SAP S4HANA
| Taille de lot | Tours | Service OData | Nombre total de lignes | Lignes extraites | Débit (Go/heure) |
|---|---|---|---|---|---|
| 2500 | 40 | TEST_04_UOM_ODATA_CDS/ | 201 M | 10 M | 25.48 |
| 5000 | 50 | TEST_04_UOM_ODATA_CDS/ | 201 M | 10 M | 26,78 |
Informations relatives à l'assistance
Le plug-in est compatible avec les cas d'utilisation suivants.
Produits et versions SAP compatibles
Les sources compatibles incluent SAP S4/HANA 1909 et versions ultérieures, S4/HANA sur le cloud SAP et toute application SAP capable d'exposer des services OData.
Le fichier de transport contenant le service OData personnalisé pour l'équilibrage de charge des appels à SAP doit être importé dans S4/HANA 1909 et versions ultérieures. Le service permet de calculer le nombre de divisions (partitions de données) que le plug-in peut lire en parallèle (voir nombre de divisions).
La version 2 d'OData est compatible.
Le plug-in a été testé avec des serveurs SAP S/4HANA déployés sur Google Cloud.
Les services de catalogue OData SAP sont compatibles avec l'extraction
Le plug-in est compatible avec les types de source de données suivants :
- Données de transaction
- Vues CDS exposées via OData
Données de référence
- Attributs
- Textes
- Hiérarchies
Notes SAP
Aucune note SAP n'est requise avant l'extraction, mais SAP Gateway doit être disponible sur le système SAP. Pour en savoir plus, consultez la note 1560585 (ce site externe nécessite une connexion SAP).
Limites concernant le volume de données ou la largeur des enregistrements
Aucune limite n'est définie pour le volume de données extrait. Nous avons testé jusqu'à 6 millions de lignes dans un seul appel, avec une largeur d'enregistrement de 1 Ko. Pour SAP S4/HANA dans le cloud, nous avons testé jusqu'à 10 millions de lignes extraites en un seul appel, avec une largeur d'enregistrement de 1 Ko.
Débit du plug-in attendu
Pour un environnement configuré conformément aux consignes de la section Performances, le plug-in peut extraire environ 38 Go par heure. Les performances réelles peuvent varier en fonction de la charge du système Cloud Data Fusion et SAP, ou du trafic réseau.
Extraction delta (données modifiées)
L'extraction delta n'est pas disponible.
Scénarios d'erreur
Au moment de l'exécution, le plug-in écrit des entrées de journal dans le journal de pipeline de données Cloud Data Fusion. Ces entrées sont précédées du préfixe CDF_SAP pour faciliter l'identification.
Au moment de la conception, lorsque vous validez les paramètres du plug-in, les messages s'affichent dans l'onglet Propriétés et sont mis en surbrillance en rouge.
La liste suivante décrit certaines de ces erreurs:
| ID du message | Message | Action recommandée |
|---|---|---|
| Aucun | Required property 'CONNECTION_PROPERTY' for connection
type 'CONNECTION_PROPERTY_SETTING'. |
Saisissez une valeur réelle ou une variable de macro. |
| Aucun | Invalid value for property 'PROPERTY_NAME'. |
Saisissez un nombre entier non négatif (0 ou supérieur, sans décimal) ou une variable de macro. |
| CDF_SAP_ODATA_01505 | Failed to prepare the Cloud Data Fusion output schema. Please
check the provided runtime macros value. |
Vérifiez que les valeurs de macro fournies sont correctes. |
| N/A | SAP X509 certificated 'STORAGE_PATH' is missing. Please
make sure the required X509 certificate is uploaded to your specified
Cloud Storage bucket 'BUCKET_NAME'. |
Assurez-vous que le chemin d'accès Cloud Storage fourni est correct. |
| CDF_SAP_ODATA_01532 | Code d'erreur générique lié à des problèmes de connectivité SAP ODataFailed to call given SAP OData service. Root Cause:
MESSAGE. |
Vérifiez la cause fondamentale affichée dans le message et prenez les mesures appropriées. |
| CDF_SAP_ODATA_01534 | Code d'erreur générique lié à une erreur du service OData SAP.Service validation failed. Root Cause: MESSAGE. |
Vérifiez la cause fondamentale affichée dans le message et prenez les mesures appropriées. |
| CDF_SAP_ODATA_01503 | Failed to fetch total available record count from
SAP_ODATA_SERVICE_ENTITY_NAME. Root Cause: MESSAGE.
|
Vérifiez la cause fondamentale affichée dans le message et prenez les mesures appropriées. |
| CDF_SAP_ODATA_01506 | No records found to extract in
SAP_ODATA_SERVICE_ENTITY_NAME.
Please ensure that the provided entity contains records. |
Vérifiez la cause fondamentale affichée dans le message et prenez les mesures appropriées. |
| CDF_SAP_ODATA_01537 | Failed to process records for
SAP_ODATA_SERVICE_ENTITY_NAME.
Root Cause: MESSAGE. |
Vérifiez la cause fondamentale affichée dans le message et prenez les mesures appropriées. |
| CDF_SAP_ODATA_01536 | Failed to pull records from
SAP_ODATA_SERVICE_ENTITY_NAME. Root Cause:
MESSAGE. |
Vérifiez la cause fondamentale affichée dans le message et prenez les mesures appropriées. |
| CDF_SAP_ODATA_01504 | Failed to generate the encoded metadata string for the given OData
service SAP_ODATA_SERVICE_NAME. Root Cause:
MESSAGE. |
Vérifiez la cause fondamentale affichée dans le message et prenez les mesures appropriées. |
| CDF_SAP_ODATA_01533 | Failed to decode the metadata from the given encoded metadata
string for service SAP_ODATA_SERVICE_NAME. Root Cause:
MESSAGE. |
Vérifiez la cause fondamentale affichée dans le message et prenez les mesures appropriées. |
Étape suivante
- Apprenez-en plus sur Cloud Data Fusion.
- En savoir plus sur SAP sur Google Cloud