Esta página descreve como transmitir argumentos de execução em jobs de replicação do Cloud Data Fusion.
Transmitir um argumento do Debezium para um job de replicação
Para transmitir um argumento de um aplicativo Debezium para um trabalho de replicação do MySQL ou do SQL Server no Cloud Data Fusion, especifique um argumento de execução usando o prefixo source.connector.
Console
Acesse sua instância:
No console Google Cloud , acesse a página do Cloud Data Fusion.
Para abrir a instância no Cloud Data Fusion Studio, clique em Instâncias e em Ver instância.
Clique em Menu > Centro de controle.
Localize o Aplicativo do job de replicação e clique em Preferências. A janela Preferências é aberta.
No campo Chave, especifique um argumento de ambiente de execução para o job de replicação prefixando-o com
source.connector.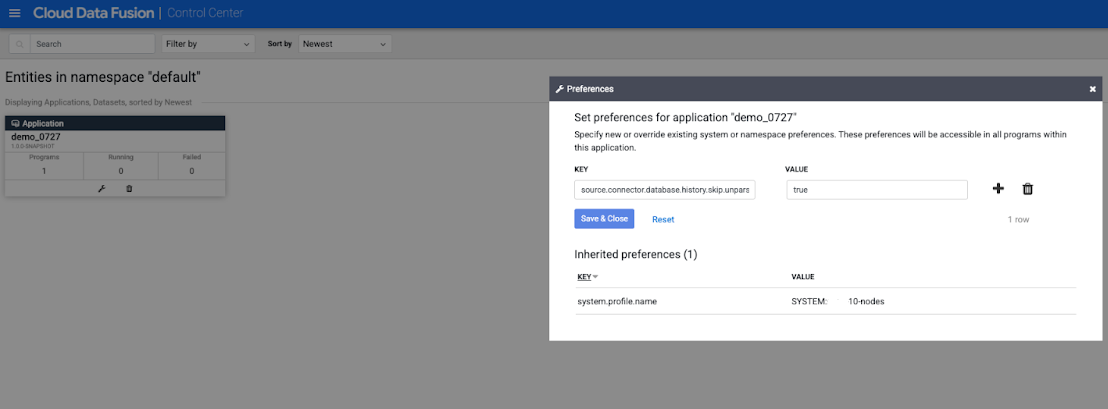
Clique em Salvar e fechar.
API REST
Para definir um argumento de execução usando a API REST, consulte a referência Microsserviços de preferências do CDAP.
Configurar parâmetros JDBC
Para transmitir um parâmetro JDBC a um job de replicação do MySQL ou do SQL Server,
especifique o argumento de execução com o prefixo source.connector.database.
Por exemplo, para configurar o parâmetro JDBC sessionVariables como
MAX_EXECUTION_TIME=43200000, defina um argumento de execução
com a chave source.connector.database.sessionVariables e o valor
MAX_EXECUTION_TIME=43200000.
Para configurar vários parâmetros JDBC, defina um argumento de execução para
cada parâmetro. Por exemplo, para configurar os parâmetros JDBC
encrypt=true&trustServerCertificate=true, transmita os seguintes argumentos:
| Chave | Valor |
|---|---|
source.connector.database.encrypt |
true |
source.connector.database.trustServerCertificate |
true |
Configurar o parâmetro de chave primária
A tabela de origem replicada precisa ter uma chave primária. Esse é um requisito estrito apenas quando o Oracle é o banco de dados de origem. Para origens do SQL Server e do MySQL, é possível especificar uma chave primária personalizada, mesmo que a tabela de origem não tenha uma.
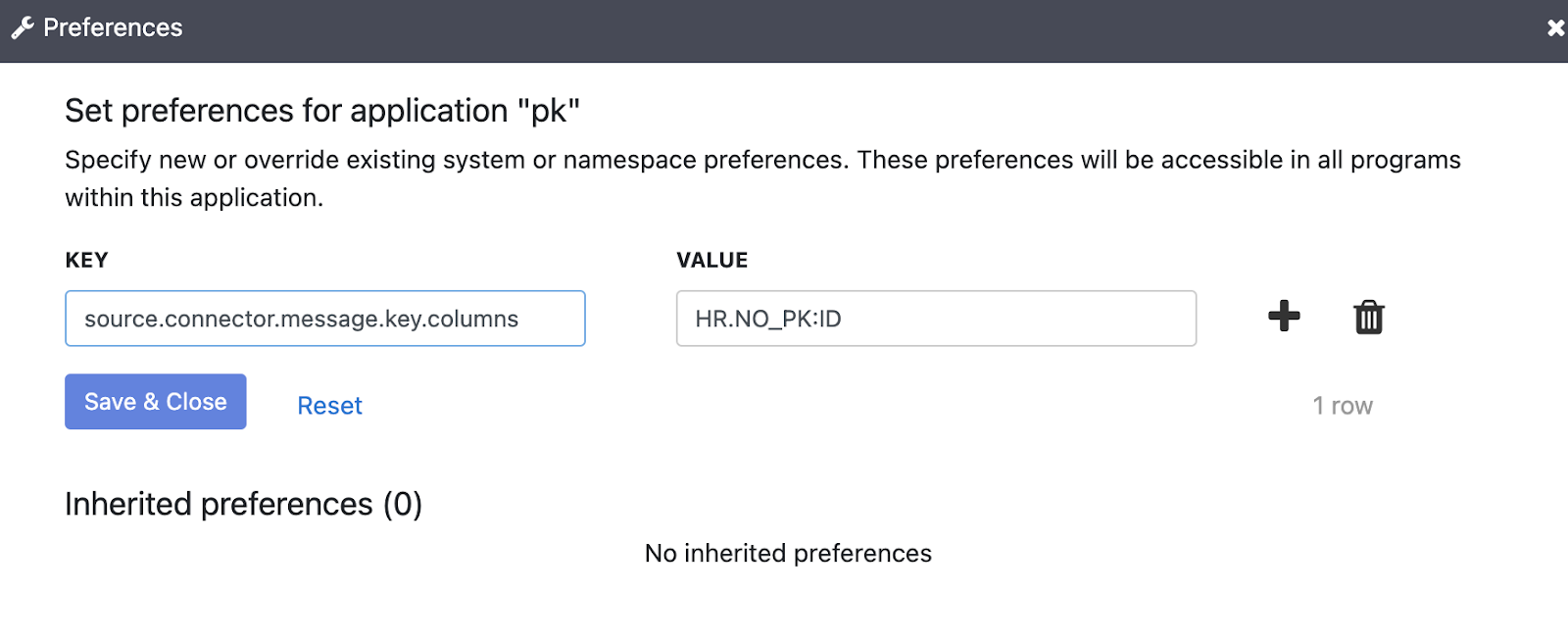
Defina o parâmetro key com o seguinte argumento de execução:
source.connector.message.key.columns = SCHEMA.TABLE:KEY_COLUMN
Substitua:
- SCHEMA: o nome do esquema de origem.
- TABLE: o nome da tabela de origem.
- KEY_COLUMN: a coluna que contém a chave segura.
É possível definir a chave primária para várias tabelas com a propriedade key. O
exemplo abaixo mostra como definir a chave para as tabelas inventory.customers
e purchase.orders:
source.connector.message.key.columns = inventory.customers:pk1,pk2;purchase.orders:pk3,pk4
Configurar o modo de isolamento para um snapshot na replicação do SQL Server
Para mais informações sobre o argumento de execução para o modo de isolamento, consulte Níveis de isolamento na replicação do SQL Server.
A seguir
- Saiba mais sobre replicação no Cloud Data Fusion.
- Consulte a referência da API Replication.