Halaman ini menjelaskan cara meneruskan argumen runtime dalam tugas replikasi Cloud Data Fusion.
Meneruskan argumen Debezium ke tugas replikasi
Untuk meneruskan argumen dari aplikasi Debezium ke tugas replikasi MySQL atau SQL Server di Cloud Data Fusion, tentukan argumen runtime menggunakan awalan, source.connector.
Konsol
Buka instance Anda:
Di konsol Google Cloud , buka halaman Cloud Data Fusion.
Untuk membuka instance di Cloud Data Fusion Studio, klik Instance, lalu klik View instance.
Klik Menu > Pusat Kontrol.
Cari Aplikasi untuk tugas replikasi, lalu klik Preferensi. Jendela Preferensi akan terbuka.
Di kolom Key, tentukan argumen runtime untuk tugas replikasi dengan menambahkan awalan
source.connector.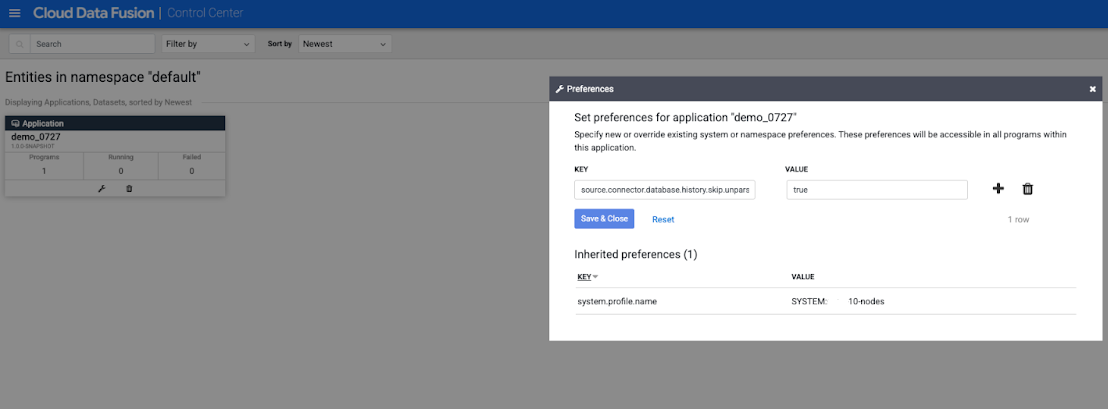
Klik Save & Close.
REST API
Untuk menetapkan argumen runtime menggunakan REST API, lihat referensi Microservice Preferensi CDAP.
Mengonfigurasi parameter JDBC
Untuk meneruskan parameter JDBC ke tugas replikasi MySQL atau SQL Server,
tentukan argumen runtime yang diawali dengan source.connector.database.
Misalnya, untuk mengonfigurasi parameter JDBC sessionVariables ke
MAX_EXECUTION_TIME=43200000, tetapkan argumen runtime
dengan kunci source.connector.database.sessionVariables dan nilai
MAX_EXECUTION_TIME=43200000.
Untuk mengonfigurasi beberapa parameter JDBC, tetapkan argumen runtime untuk
setiap parameter. Misalnya, untuk mengonfigurasi parameter JDBC
encrypt=true&trustServerCertificate=true, teruskan argumen berikut:
| Kunci | Nilai |
|---|---|
source.connector.database.encrypt |
true |
source.connector.database.trustServerCertificate |
true |
Mengonfigurasi parameter kunci utama
Tabel sumber yang direplikasi harus memiliki kunci utama. Hal ini merupakan persyaratan ketat hanya jika Oracle adalah database sumber. Untuk sumber SQL Server dan MySQL, Anda dapat menentukan kunci utama kustom, meskipun tabel sumber tidak memilikinya.
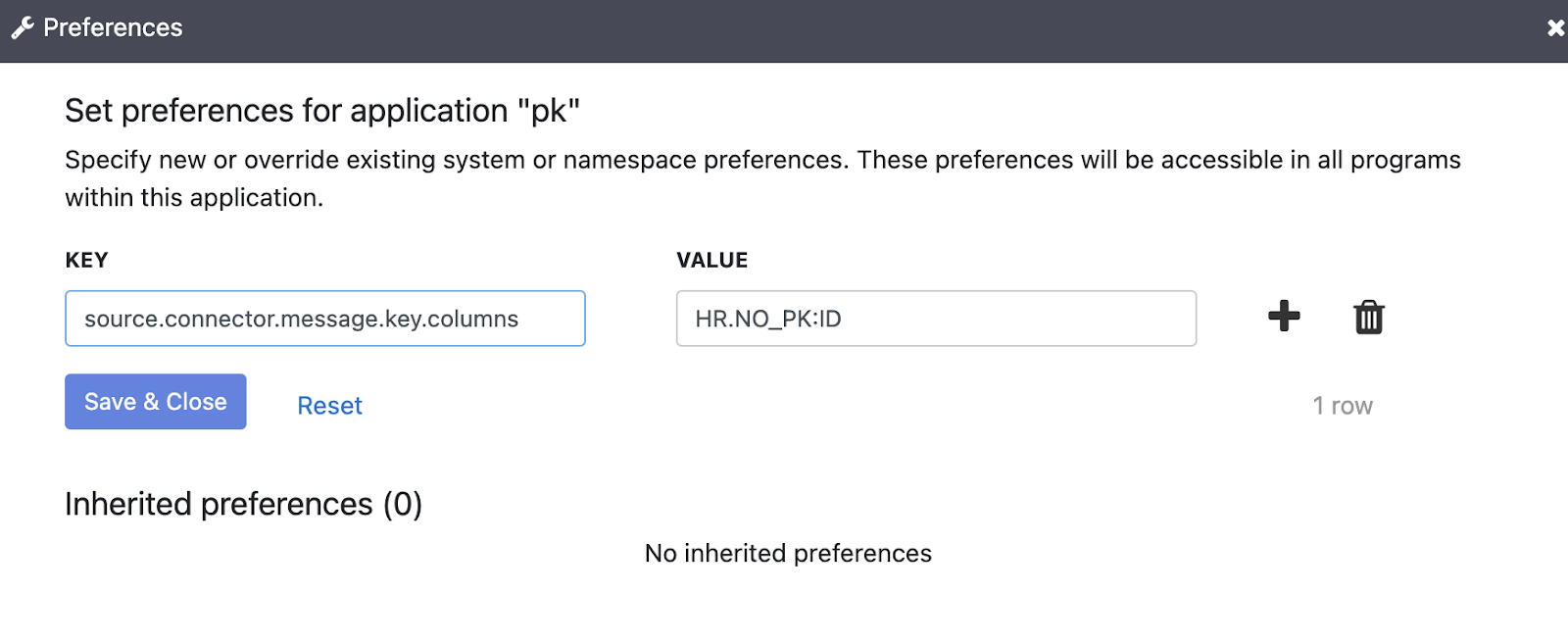
Tetapkan parameter key dengan argumen runtime berikut:
source.connector.message.key.columns = SCHEMA.TABLE:KEY_COLUMN
Ganti kode berikut:
- SCHEMA: Nama skema sumber.
- TABLE: Nama tabel sumber.
- KEY_COLUMN: Kolom yang berisi kunci aman.
Anda dapat menetapkan kunci utama untuk beberapa tabel dengan properti key. Contoh
berikut menunjukkan cara menetapkan kunci untuk tabel inventory.customers
dan purchase.orders:
source.connector.message.key.columns = inventory.customers:pk1,pk2;purchase.orders:pk3,pk4
Mengonfigurasi mode isolasi untuk snapshot dalam replikasi SQL Server
Untuk mengetahui informasi selengkapnya tentang argumen runtime untuk mode isolasi, lihat Tingkat isolasi dalam replikasi SQL Server.
Langkah selanjutnya
- Pelajari Replikasi lebih lanjut di Cloud Data Fusion.
- Lihat referensi Replication API.