Cette page explique comment modifier la version de l'image Dataproc utilisée par votre instance Cloud Data Fusion. Vous pouvez modifier l'image au niveau de l'instance, de l'espace de noms ou du pipeline.
Avant de commencer
Arrêtez tous les pipelines en temps réel et les tâches de réplication dans l'instance Cloud Data Fusion. Si un pipeline ou une réplication en temps réel sont en cours d'exécution lorsque vous modifiez la version de l'image Dataproc, les modifications ne sont pas appliquées à l'exécution du pipeline.
Pour les pipelines en temps réel, si la création de points de contrôle est activée, l'arrêt des pipelines n'entraîne aucune perte de données. Pour les jobs de réplication, tant que les journaux de base de données sont disponibles, l'arrêt et le démarrage du job de réplication n'entraînent aucune perte de données.
Console
Accédez à la page Instances de Cloud Data Fusion et ouvrez l'instance dans laquelle vous devez arrêter un pipeline.
Ouvrez chaque pipeline en temps réel dans Pipeline Studio, puis cliquez sur Arrêter.
Ouvrez chaque tâche de réplication sur la page Répliquer, puis cliquez sur Arrêter.
API REST
Pour récupérer tous les pipelines, utilisez l'appel d'API REST suivant :
GET -H "Authorization: Bearer ${AUTH_TOKEN}" \ "${CDAP_ENDPOINT}/v3/namespaces/NAMESPACE_ID/apps"Remplacez
NAMESPACE_IDpar le nom de votre espace de noms.Pour arrêter un pipeline en temps réel, utilisez l'appel d'API REST suivant :
POST -H "Authorization: Bearer ${AUTH_TOKEN}" \ "${CDAP_ENDPOINT}/v3/namespaces/NAMESPACE_ID/apps/PIPELINE_NAME/spark/DataStreamsSparkStreaming/stop"Remplacez NAMESPACE_ID par le nom de votre espace de noms et PIPELINE_NAME par celui du pipeline en temps réel.
Pour arrêter un job de réplication, utilisez l'appel d'API REST suivant :
POST -H "Authorization: Bearer ${AUTH_TOKEN}" \ "${CDAP_ENDPOINT}/v3/namespaces/NAMESPACE_ID/apps/REPLICATION_JOB_NAME/workers/DeltaWorker/stop"Remplacez NAMESPACE_ID par le nom de votre espace de noms et REPLICATION_JOB_NAME par le nom du job de réplication.
Pour en savoir plus, consultez les sections Arrêter les pipelines en temps réel et Arrêter les jobs de réplication.
Vérifier et remplacer la version par défaut de Dataproc dans Cloud Data Fusion
Cliquez sur Administrateur système > Configuration > Préférences système.
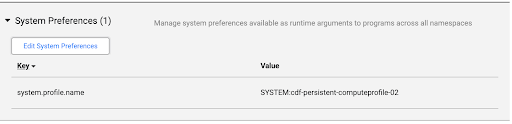
Si aucune image Dataproc n'est spécifiée dans les préférences système ou si vous souhaitez modifier la préférence, cliquez sur Modifier les préférences système.
Saisissez le texte suivant dans le champ Clé :
system.profile.properties.imageVersionSaisissez l'image Dataproc choisie dans le champ "Valeur", par exemple
2.1.Cliquez sur Enregistrer et fermer.
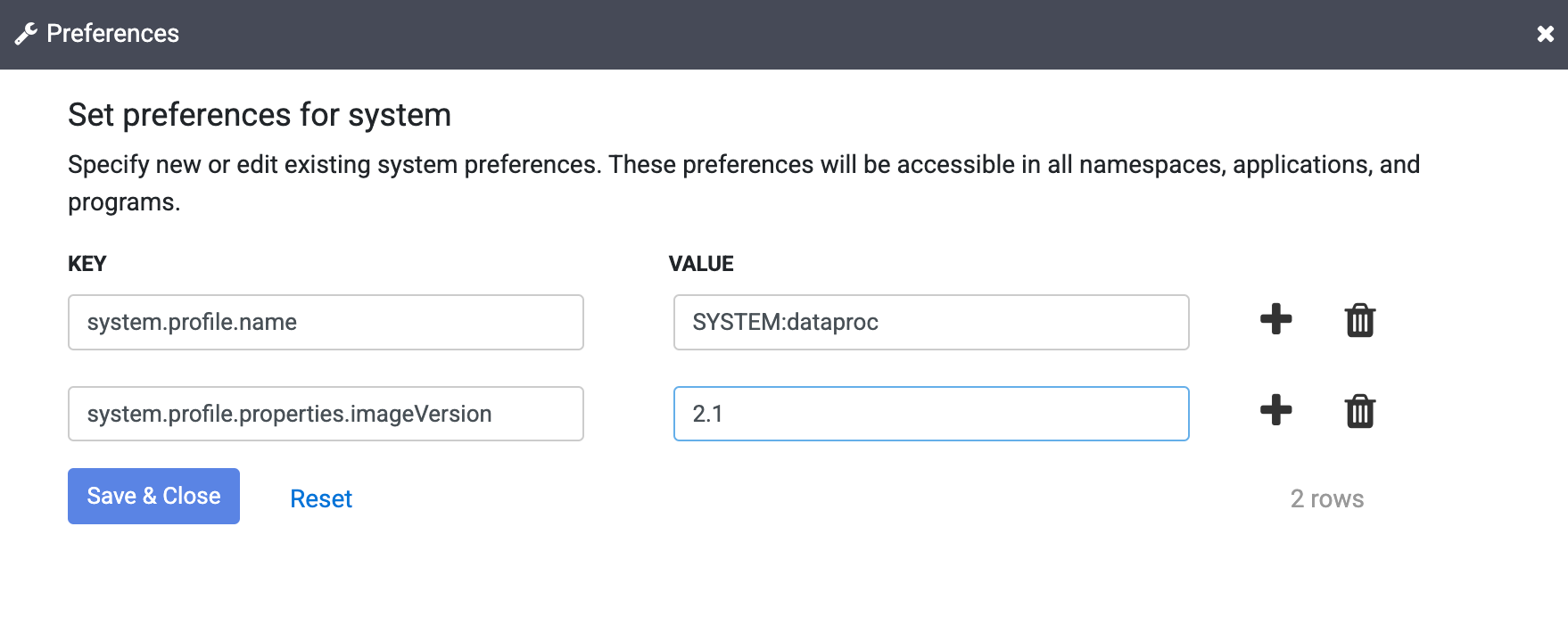
Cette modification affecte l'ensemble de l'instance Cloud Data Fusion, y compris tous ses espaces de noms et toutes ses exécutions de pipeline, sauf si la propriété de version de l'image est remplacée dans un espace de noms, un pipeline ou un argument d'exécution de votre instance.
Modifier la version d'image Dataproc
La version de l'image peut être définie dans l'interface Web Cloud Data Fusion, dans les configurations de calcul, les préférences d'espace de noms ou les arguments d'exécution du pipeline.
Modifier l'image dans les préférences de l'espace de noms
Si vous avez remplacé la version de l'image dans les propriétés de votre espace de noms, procédez comme suit :
Cliquez sur Administrateur système > Configuration > Espaces de noms.
Ouvrez chaque espace de noms et cliquez sur Préférences.
Assurez-vous qu'aucune substitution avec la clé
system.profile.properties.imageVersionn'est associée à une valeur de version d'image incorrecte.Cliquez sur Terminer.
Modifier l'image dans les profils de calcul système
Cliquez sur Administrateur système > Configuration.
Cliquez sur Système Profils de calcul > Créer un profil.
Sélectionnez le provisionneur Dataproc.
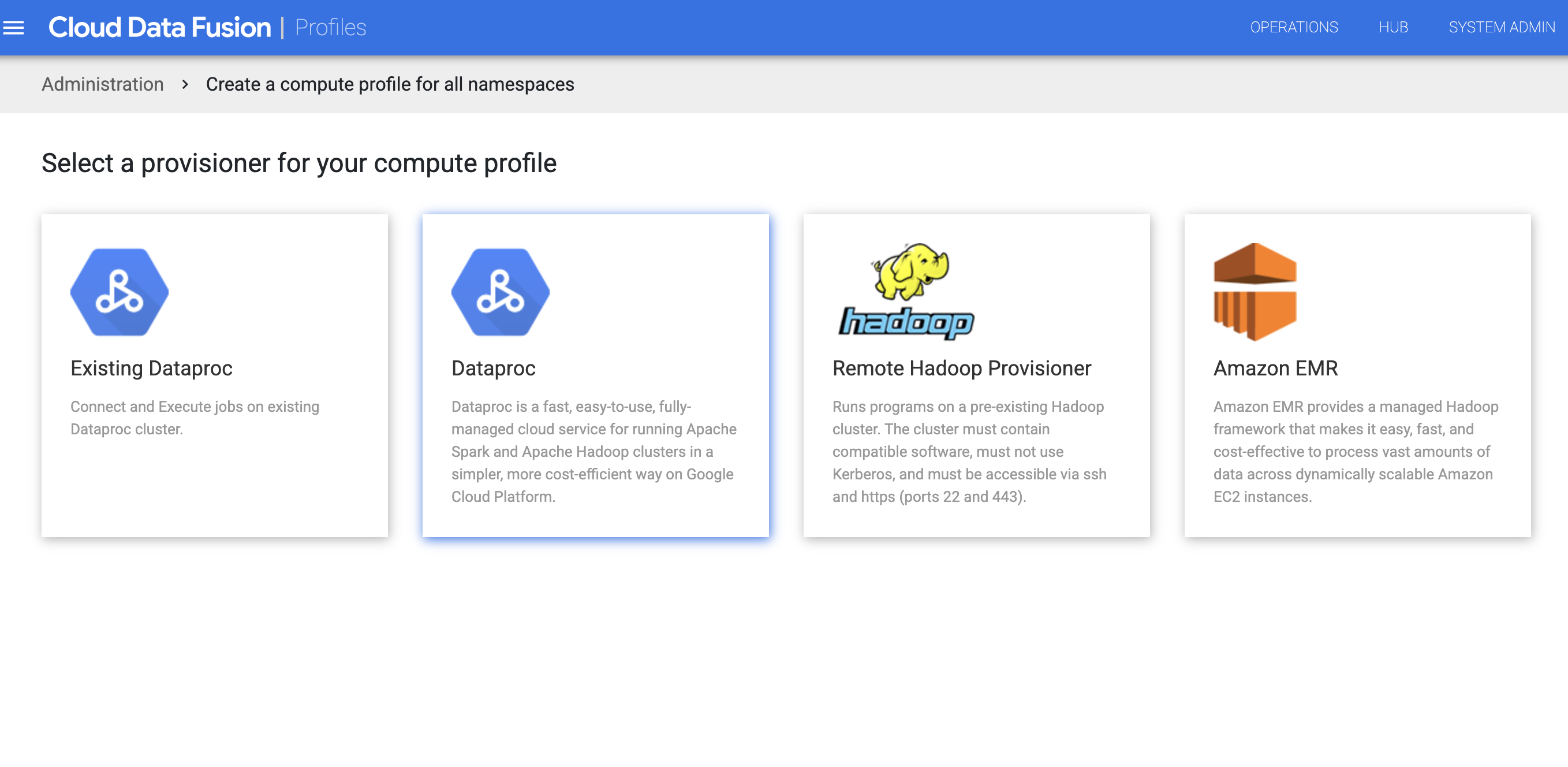
Créez le profil pour Dataproc. Dans le champ Version de l'image, saisissez une version d'image Dataproc.
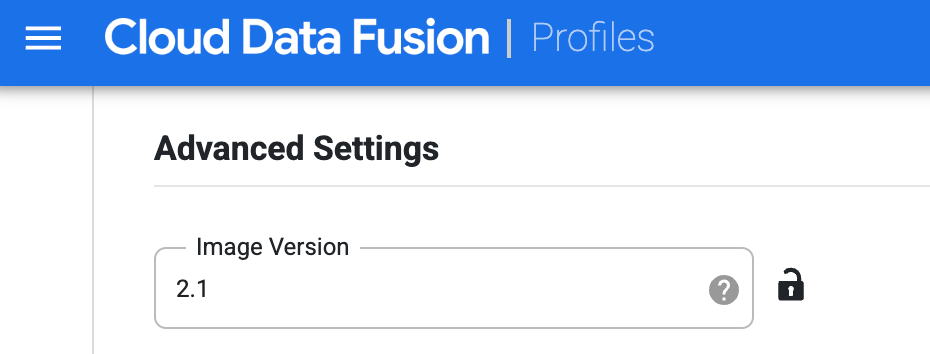
Sélectionnez ce profil de calcul lorsque vous exécutez le pipeline sur la page Studio. Sur la page d'exécution du pipeline, cliquez sur Configurer > Configuration du calcul, puis sélectionnez ce profil.
Sélectionnez le profil Dataproc, puis cliquez sur Enregistrer.
Cliquez sur Terminer.
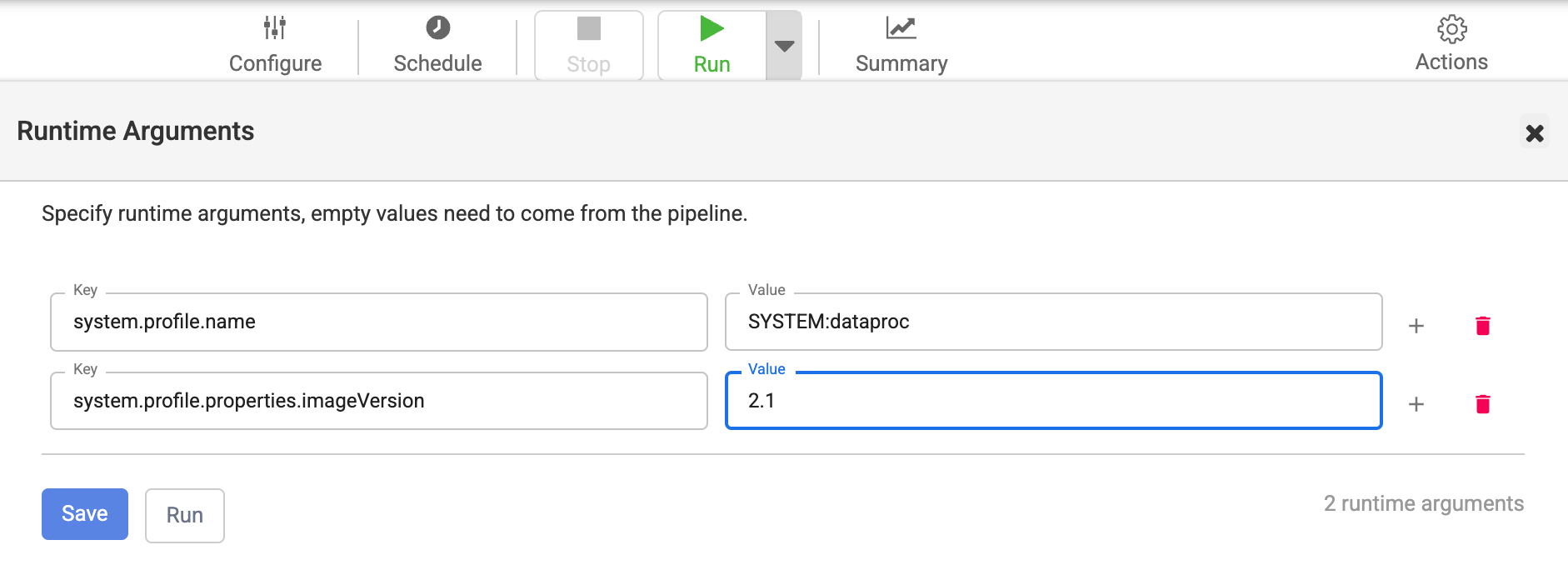
Modifier l'image dans les arguments d'exécution du pipeline
Si vous avez remplacé la version de l'image par une propriété dans les arguments d'exécution de votre pipeline, procédez comme suit :
Cliquez sur menu Menu > Liste.
Sur la page Liste, sélectionnez le pipeline que vous souhaitez mettre à jour.
Le pipeline s'ouvre sur la page Studio.
Pour développer les options Exécuter, cliquez sur la flèche de développement .
La fenêtre Arguments d'exécution s'ouvre.
Vérifiez qu'aucune valeur de remplacement n'est associée à la clé
system.profile.properties.imageVersionavec une version d'image incorrecte.Cliquez sur Enregistrer.
Recréer les clusters Dataproc statiques utilisés par Cloud Data Fusion avec la version d'image choisie
Si vous utilisez des clusters Dataproc existants avec Cloud Data Fusion, suivez le guide Dataproc pour recréer les clusters avec la version d'image Dataproc choisie pour votre version de Cloud Data Fusion.
Vous pouvez également créer un cluster Dataproc avec la version d'image Dataproc choisie, puis supprimer et recréer le profil de calcul dans Cloud Data Fusion avec le même nom de profil de calcul et le nom de cluster Dataproc mis à jour. De cette façon, l'exécution des pipelines par lot peut se terminer sur le cluster existant, et les exécutions de pipeline suivantes ont lieu sur le nouveau cluster Dataproc. Vous pouvez supprimer l'ancien cluster Dataproc une fois que vous avez vérifié que toutes les exécutions de pipeline sont terminées.
Vérifier que la version de l'image Dataproc est à jour
Console
Dans la console Google Cloud , accédez à la page Clusters Dataproc.
Ouvrez la page Détails du cluster pour le nouveau cluster que Cloud Data Fusion a créé lorsque vous avez spécifié la nouvelle version.
Le champ Version de l'image contient la nouvelle valeur que vous avez spécifiée dans Cloud Data Fusion.
API REST
Obtenez la liste des clusters avec leurs métadonnées :
GET -H "Authorization: Bearer ${AUTH_TOKEN}" \ https://dataproc.googleapis.com/v1/projects/PROJECT_ID/regions/REGION_ID/clustersRemplacez les éléments suivants :
PROJECT_IDpar le nom de votre espace de nomsREGION_IDpar le nom de la région où se trouvent vos clusters ;
Recherchez le nom de votre pipeline (nom du cluster).
Sous cet objet JSON, consultez l'image dans
config > softwareConfig > imageVersion.
Remplacez l'image Dataproc par la version 2.1 ou ultérieure.
Les versions 6.9.1 et ultérieures de Cloud Data Fusion sont compatibles avec l'image Dataproc 2.1 Compute Engine, qui s'exécute dans Java 11. Dans les versions 6.10.0 et ultérieures, l'image 2.1 est celle par défaut.
Si vous passez à l'image 2.1 ou version ultérieure à partir d'une image antérieure, les pilotes JDBC utilisés par les plug-ins de base de données dans ces instances doivent être compatibles avec Java 11 pour que vos pipelines de traitement par lot et vos jobs de réplication réussissent.
Les images Dataproc 2.2 et 2.1 présentent les limites suivantes dans Cloud Data Fusion :
- Les jobs MapReduce ne sont pas acceptés.
- Les versions des pilotes JDBC utilisés dans les plug-ins de base de données de votre instance doivent être mises à jour pour être compatibles avec Java 11. Consultez le tableau suivant pour connaître les versions de pilote compatibles avec Dataproc 2.2, 2.1 et Java 11 :
| Pilotes JDBC | Versions antérieures supprimées de Cloud Data Fusion 6.9.1 | Versions compatibles avec Java 8 et Java 11 qui fonctionnent avec Dataproc 2.2, 2.1 ou 2.0 |
|---|---|---|
| Pilote JDBC Cloud SQL pour MySQL | - | 1.0.16 |
| Pilote JDBC Cloud SQL pour PostgreSQL | - | 1.0.16 |
| Pilote JDBC Microsoft SQL Server | Pilote Microsoft JDBC 6.0 | Pilote Microsoft JDBC 9.4 |
| Pilote JDBC MySQL | 5.0.8, 5.1.39 | 8.0.25 |
| Pilote JDBC PostgreSQL | 9.4.1211.jre7, 9.4.1211.jre8 | 42.6.0.jre8 |
| Pilote Oracle JDBC | ojdbc7 | ojdbc8 (12c et versions ultérieures) |
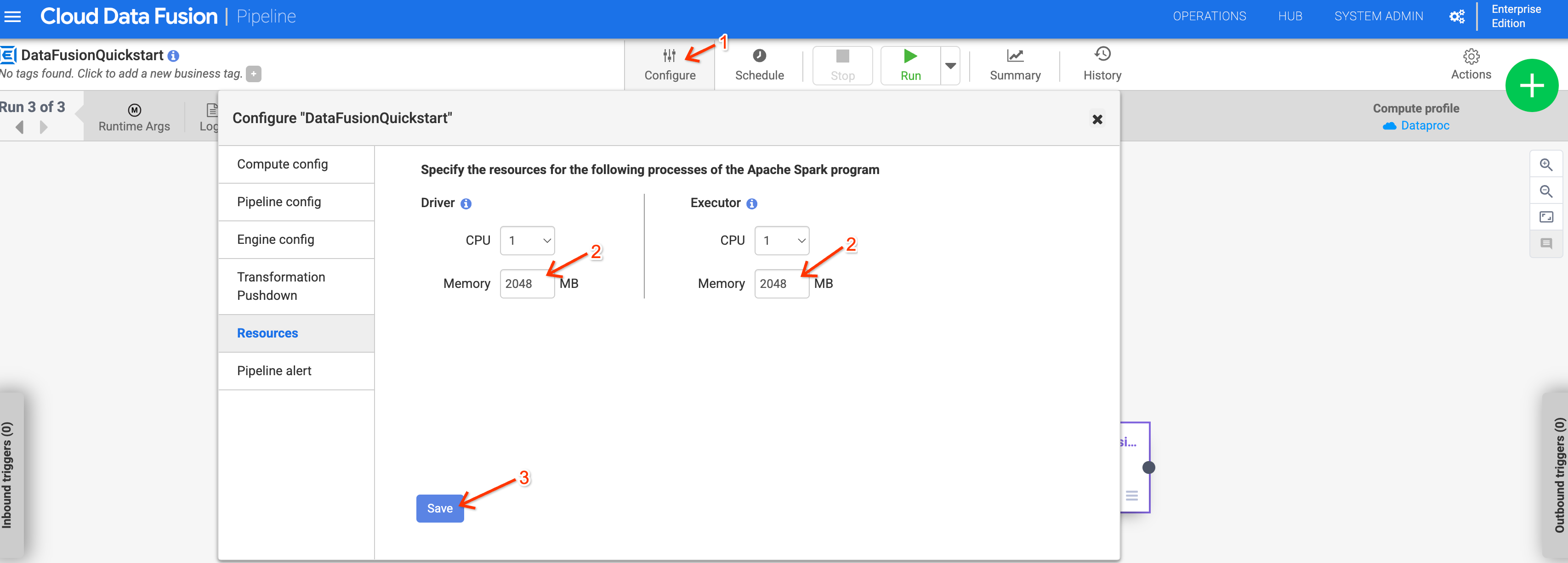
Utilisation de la mémoire avec Dataproc 2.1 ou version ultérieure
L'utilisation de la mémoire peut augmenter pour les pipelines qui utilisent Dataproc 2.1 ou version ultérieure. Si vous mettez à niveau votre instance vers la version 6.10 ou ultérieure et que les anciens pipelines échouent en raison de problèmes de mémoire, augmentez la mémoire du pilote et de l'exécuteur à 2 048 Mo dans la configuration Resources du pipeline.
Vous pouvez également remplacer la version Dataproc en définissant l'argument d'exécution system.profile.properties.imageVersion sur 2.0-debian10.