이 페이지에서는 Cloud Data Fusion: Studio에 대해 소개합니다. 사전 빌드된 플러그인 라이브러리와 파이프라인을 구성, 실행 및 관리하는 인터페이스에서 데이터 파이프라인을 빌드하기 위한 시각적 클릭 앤 드래그 인터페이스입니다. Studio에서 파이프라인을 빌드하는 과정은 일반적으로 다음과 같습니다.
- 온프레미스 또는 클라우드 데이터 소스에 연결합니다.
- 데이터를 준비하고 변환합니다.
- 대상에 연결합니다.
- 파이프라인을 테스트합니다.
- 파이프라인을 실행합니다.
- 파이프라인을 예약하고 트리거합니다.
파이프라인을 설계하고 실행한 후 Cloud Data Fusion Pipeline Studio 페이지에서 파이프라인을 관리할 수 있습니다.
- 환경설정 및 런타임 인수로 파이프라인을 매개변수화하여 재사용합니다.
- 컴퓨팅 프로필을 맞춤설정하고, 리소스를 관리하고, 파이프라인 성능을 미세 조정하여 파이프라인 실행을 관리합니다.
- 파이프라인을 수정하여 파이프라인 수명 주기를 관리합니다.
- Git 통합을 사용하여 파이프라인 소스 제어를 관리합니다.
시작하기 전에
- Cloud Data Fusion API를 사용 설정합니다.
- Cloud Data Fusion 인스턴스 만들기
- Cloud Data Fusion의 액세스 제어를 알아봅니다.
- Cloud Data Fusion의 주요 개념 및 용어를 이해합니다.
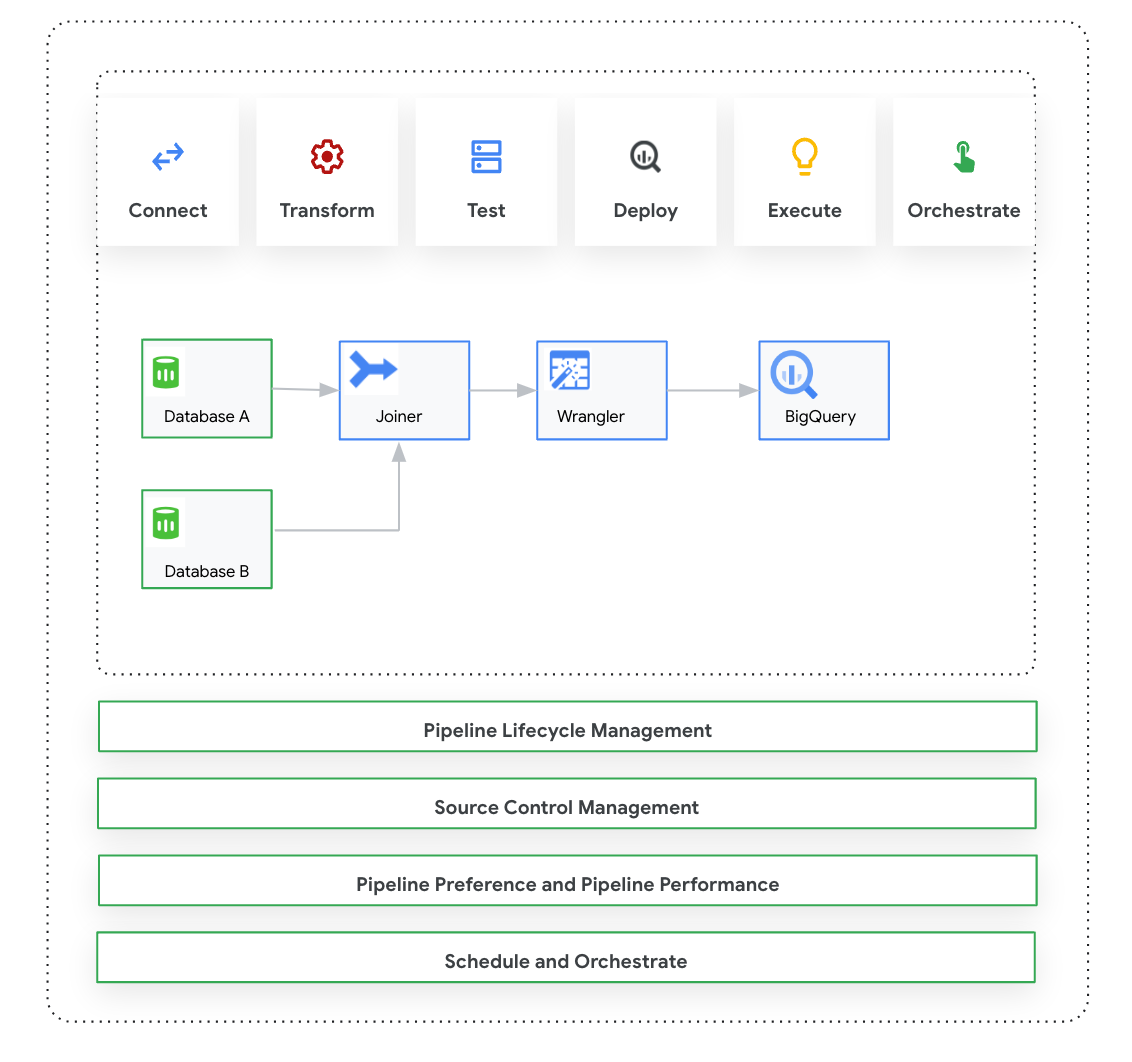
Cloud Data Fusion: Studio 개요
Studio에는 다음 구성요소가 포함됩니다.
관리
Cloud Data Fusion을 사용하면 각 인스턴스에 여러 개의 네임스페이스를 보유할 수 있습니다. 관리자는 Studio 내에서 모든 네임스페이스를 중앙에서 관리하거나 각 네임스페이스를 개별적으로 관리할 수 있습니다.
Studio에서는 다음과 같은 관리자 설정을 제공합니다.
- 시스템 관리
- Studio의 시스템 관리자 모듈을 사용하면 새 네임스페이스를 만들고 시스템 해당 인스턴스의 각 네임스페이스에 적용되는 시스템 수준에서 중앙 컴퓨팅 프로필 구성을 정의할 수 있습니다. 자세한 내용은 Studio 관리 운영을 참고하세요.
- 네임스페이스 관리
- Studio의 네임스페이스 관리 모듈을 사용하면 특정 네임스페이스에 대한 구성을 관리할 수 있습니다. 각 네임스페이스에 대해 컴퓨팅 프로필, 런타임 환경설정, 드라이버, 서비스 계정, git 구성을 정의할 수 있습니다. 자세한 내용은 Studio 관리 운영을 참고하세요.
파이프라인 설계 스튜디오
Cloud Data Fusion 웹 인터페이스의 파이프라인 설계 스튜디오에서 파이프라인을 설계하고 실행합니다. 데이터 파이프라인을 설계하고 실행하는 단계는 다음과 같습니다.
- 소스에 연결: Cloud Data Fusion을 사용하면 온프레미스 및 클라우드 데이터 소스에 연결할 수 있습니다. Studio 인터페이스에는 Studio에 사전 설치된 기본 시스템 플러그인이 있습니다. 허브라고 하는 플러그인 저장소에서 추가 플러그인을 다운로드할 수 있습니다. 자세한 내용은 플러그인 개요를 참고하세요.
- 데이터 준비: Cloud Data Fusion을 사용하면 강력한 데이터 준비 플러그인인 Wrangler를 사용하여 데이터를 준비할 수 있습니다. Wrangler를 사용하면 Studio의 전체 데이터 세트에서 로직을 실행하기 전에 한 곳에서 소량의 데이터 샘플을 확인, 탐색 및 변환할 수 있습니다. 이렇게 하면 변환을 빠르게 적용하여 변환이 전체 데이터 세트에 미치는 영향을 파악할 수 있습니다. 여러 변환을 만들어 레시피에 추가할 수 있습니다. 자세한 내용은 Wrangler 개요를 참조하세요.
- 변환: 변환 플러그인은 소스에서 데이터를 로드한 후 데이터를 변경합니다. 예를 들어 레코드를 클론하거나, 파일 형식을 JSON으로 변경하거나, JavaScript 플러그인을 사용하여 커스텀 변환을 만들 수 있습니다. 자세한 내용은 플러그인 개요를 참고하세요.
- 대상에 연결: 데이터를 준비하고 변환을 적용한 후 데이터를 로드할 대상에 연결할 수 있습니다. Cloud Data Fusion은 여러 대상에 대한 연결을 지원합니다. 자세한 내용은 플러그인 개요를 참고하세요.
- 미리보기: 파이프라인을 설계한 후 파이프라인을 배포하고 실행하기 전에 문제를 디버그하려면 미리보기 작업을 실행합니다. 오류가 발생하면 초안 모드에서 수정할 수 있습니다. Studio는 소스 데이터 세트의 처음 100개 행을 사용하여 미리보기를 생성합니다. Studio에 미리보기 작업의 상태와 기간이 표시됩니다. 언제든지 작업을 중지할 수 있습니다. 미리보기 작업이 실행되는 동안 로그 이벤트를 모니터링할 수도 있습니다. 자세한 내용은 데이터 미리보기를 참고하세요.
파이프라인 구성 관리: 데이터를 미리 본 후 파이프라인을 배포하고 다음 파이프라인 구성을 관리할 수 있습니다.
- 컴퓨팅 구성: 파이프라인을 실행하는 컴퓨팅 프로필을 변경할 수 있습니다. 예를 들어 기본 Dataproc 클러스터가 아닌 맞춤설정된 Dataproc 클러스터에 대해 파이프라인을 실행하려는 경우입니다.
- 파이프라인 구성: 각 파이프라인에 대해 타이밍 측정항목과 같은 계측을 사용 설정 또는 중지할 수 있습니다. 기본적으로 계측은 사용 설정되어 있습니다.
- 엔진 구성: Spark가 기본 실행 엔진입니다. Spark에 커스텀 파라미터를 전달할 수 있습니다.
- 리소스: Spark 드라이버 및 실행자의 메모리와 CPU 수를 지정할 수 있습니다. 드라이버는 Spark 작업을 조정합니다. 실행자는 Spark에서 데이터 처리를 처리합니다.
- 파이프라인 알림: 파이프라인 실행이 완료된 후 알림을 보내고 후처리 태스크를 시작하도록 파이프라인을 구성할 수 있습니다. 파이프라인을 설계할 때 파이프라인 알림을 만듭니다. 파이프라인을 배포한 후 알림을 볼 수 있습니다. 알림 설정을 변경하려면 파이프라인을 수정하면 됩니다.
- 변환 푸시다운: 파이프라인이 BigQuery에서 특정 변환을 실행하도록 하려면 변환 푸시다운을 사용 설정할 수 있습니다.
자세한 내용은 파이프라인 구성 관리를 참조하세요.
매크로, 환경설정, 런타임 인수를 사용하여 파이프라인 재사용: Cloud Data Fusion을 사용하면 데이터 파이프라인을 재사용할 수 있습니다. 재사용 가능한 데이터 파이프라인을 사용하면 다양한 사용 사례와 데이터 세트에 데이터 통합 패턴을 적용할 수 있는 단일 파이프라인을 보유할 수 있습니다. 재사용 가능한 파이프라인을 사용하면 관리 효율성이 향상됩니다. 이를 통해 파이프라인의 대부분의 구성을 설계 시점에 하드코딩하는 대신 실행 시점에 설정할 수 있습니다. 파이프라인 디자인 스튜디오에서 매크로를 사용하여 플러그인 구성에 변수를 추가할 수 있으므로 런타임 시 변수 대체를 지정할 수 있습니다. 자세한 내용은 매크로, 환경설정, 런타임 인수 관리를 참조하세요.
실행: 파이프라인 구성을 검토한 후 파이프라인 실행을 시작할 수 있습니다. 프로비저닝, 시작, 실행, 성공과 같은 파이프라인 실행 단계 중에 상태 변경사항을 확인할 수 있습니다.
예약 및 조정: 배치 데이터 파이프라인을 지정된 일정 및 빈도로 실행되도록 설정할 수 있습니다. 파이프라인을 만들고 배포한 후에는 일정을 만들 수 있습니다. 파이프라인 디자인 스튜디오는 일괄 데이터 파이프라인에 트리거를 만들어 하나 이상의 파이프라인 실행될 때 트리거가 실행되도록 파이프라인을 조정할 수 있습니다. 이를 다운스트림 및 업스트림 파이프라인이라고 합니다. 하나 이상의 업스트림 파이프라인이 완료될 때 실행되도록 다운스트림 파이프라인에 트리거를 만듭니다.
권장: Composer를 사용하여 Cloud Data Fusion에서 파이프라인을 조정할 수도 있습니다. 자세한 내용은 파이프라인 예약 및 파이프라인 조정을 참고하세요.
파이프라인 수정: Cloud Data Fusion을 사용하면 배포된 파이프라인을 수정할 수 있습니다. 배포된 파이프라인을 수정하면 동일한 이름으로 새 버전의 파이프라인이 생성되고 최신 버전으로 표시됩니다. 이렇게 하면 파이프라인을 중복하지 않고 반복적으로 파이프라인을 개발할 수 있으며, 이를 통해 다른 이름의 새로운 파이프라인을 만들 수 있습니다. 자세한 내용은 파이프라인 수정을 참고하세요.
소스 제어 관리: Cloud Data Fusion을 사용하면 GitHub를 사용한 파이프라인의 소스 제어 관리를 통해 개발과 프로덕션 간의 파이프라인을 더 효과적으로 관리할 수 있습니다.
로깅 및 모니터링: 파이프라인 측정항목과 로그를 모니터링하려면 Cloud Data Fusion 파이프라인에서 Cloud Logging을 사용하도록 Stackdriver 로깅 서비스를 사용 설정하는 것이 좋습니다.
다음 단계
- Studio 관리 운영에 대해 자세히 알아보세요.