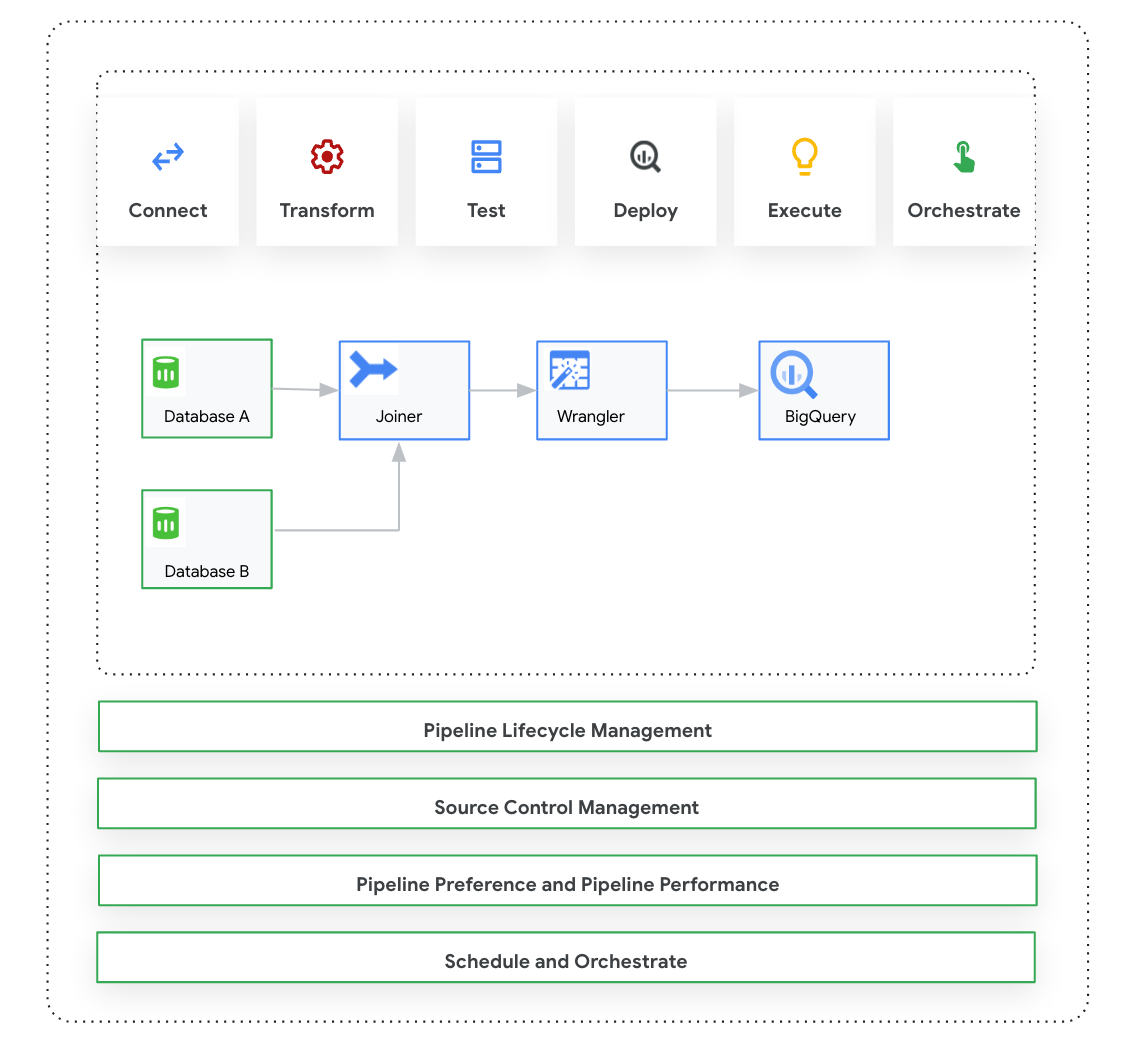
En esta página, se presenta Cloud Data Fusion: Studio, que es una interfaz visual de arrastrar y soltar para crear canalizaciones de datos a partir de una biblioteca de complementos precompilados y una interfaz en la que configuras, ejecutas y administras tus canalizaciones. Por lo general, la compilación de una canalización en Studio sigue este proceso:
- Conéctate a una fuente de datos local o en la nube.
- Prepara y transforma tus datos.
- Conéctate al destino.
- Prueba tu canalización.
- Ejecuta tu canalización.
- Programa y activa tus canalizaciones.
Después de diseñar y ejecutar la canalización, puedes administrar las canalizaciones en la página Pipeline Studio de Cloud Data Fusion:
- Para volver a usar canalizaciones, paramétralas con preferencias y argumentos de entorno de ejecución.
- Administra la ejecución de canalizaciones personalizando perfiles de procesamiento, administrando recursos y ajustando el rendimiento de la canalización.
- Edita las canalizaciones para administrar su ciclo de vida.
- Administra el control de código fuente de la canalización con la integración de Git.
Antes de comenzar
- Habilita la API de Cloud Data Fusion
- Crea una instancia de Cloud Data Fusion.
- Comprende el control de acceso en Cloud Data Fusion.
- Comprende los conceptos y términos clave de Cloud Data Fusion.
Cloud Data Fusion: Descripción general de Studio
Studio incluye los siguientes componentes.
Administración
Cloud Data Fusion te permite tener varios espacios de nombres en cada instancia. En Studio, los administradores pueden administrar todos los espacios de nombres de forma centralizada o cada uno de forma individual.
Studio proporciona los siguientes controles de administrador:
- Administración de sistemas
- El módulo Administrador del sistema de Studio te permite crear espacios de nombres nuevos y definir las configuraciones centrales del perfil de procesamiento a nivel del sistema, que se pueden aplicar a cada espacio de nombres en esa instancia. Para obtener más información, consulta Cómo administrar la administración de Studio.
- Administración de espacios de nombres
- El módulo Administrador de espacios de nombres de Studio te permite administrar las configuraciones del espacio de nombres específico. Para cada espacio de nombres, puedes definir perfiles de procesamiento, preferencias de entorno de ejecución, controladores, cuentas de servicio y configuraciones de git. Para obtener más información, consulta Administra la administración de Studio.
Pipeline Design Studio
Diseñas y ejecutas canalizaciones en Pipeline Design Studio en la interfaz web de Cloud Data Fusion. El diseño y la ejecución de canalizaciones de datos incluyen los siguientes pasos:
- Conectarse a una fuente: Cloud Data Fusion permite conexiones a fuentes de datos locales y en la nube. La interfaz de Studio tiene complementos del sistema predeterminados, que vienen preinstalados en Studio. Puedes descargar complementos adicionales desde un repositorio de complementos, conocido como Hub. Para obtener más información, consulta la descripción general de los complementos.
- Preparación de datos: Cloud Data Fusion te permite preparar tus datos con su potente complemento de preparación de datos: Wrangler. Wrangler te ayuda a ver, explorar y transformar una pequeña muestra de tus datos en un solo lugar antes de ejecutar la lógica en todo el conjunto de datos en Studio. Esto te permite aplicar transformaciones rápidamente para comprender cómo afectan a todo el conjunto de datos. Puedes crear varias transformaciones y agregarlas a una receta. Para obtener más información, consulta la descripción general de Wrangler.
- Transform: Los complementos de transformación cambian los datos después de que se cargan desde una fuente. Por ejemplo, puedes clonar un registro, cambiar el formato del archivo a JSON o usar el complemento de JavaScript para crear una transformación personalizada. Para obtener más información, consulta la descripción general de los complementos.
- Conectarse a un destino: Después de preparar los datos y aplicar las transformaciones, puedes conectarte al destino al que planeas cargar los datos. Cloud Data Fusion admite conexiones a varios destinos. Para obtener más información, consulta Descripción general de los complementos.
- Versión preliminar: Después de diseñar la canalización, para depurar problemas antes de implementar y ejecutar una canalización, ejecutas una tarea de vista previa. Si encuentras algún error, puedes corregirlo en el modo Borrador. Studio usa las primeras 100 filas de tu conjunto de datos de origen para generar la vista previa. Studio muestra el estado y la duración de la tarea de vista previa. Puedes detener la tarea en cualquier momento. También puedes supervisar los eventos de registro mientras se ejecuta la tarea de vista previa. Para obtener más información, consulta Cómo obtener una vista previa de los datos.
Administrar configuraciones de canalización: Después de obtener una vista previa de los datos, puedes implementar la canalización y administrar las siguientes configuraciones:
- Configuración de procesamiento: Puedes cambiar el perfil de procesamiento que ejecuta la canalización. Por ejemplo, deseas ejecutar la canalización en un clúster de Dataproc personalizado en lugar del clúster de Dataproc predeterminado.
- Configuración de la canalización: Para cada canalización, puedes habilitar o inhabilitar la instrumentación, como las métricas de tiempo. De forma predeterminada, la instrumentación está habilitada.
- Configuración del motor: Spark es el motor de ejecución predeterminado. Puedes pasar parámetros personalizados para Spark.
- Recursos: Puedes especificar la memoria y la cantidad de CPUs para el controlador y el ejecutor de Spark. El controlador organiza el trabajo de Spark. El ejecutor controla el procesamiento de datos en Spark.
- Alerta de canalización: Puedes configurar la canalización para que envíe alertas y comience tareas de procesamiento posterior después de que finalice la ejecución de la canalización. Cuando diseñas la canalización, creas alertas de canalización. Después de implementar la canalización, podrás ver las alertas. Para cambiar la configuración de alertas, puedes editar la canalización.
- Envío de transformaciones: Puedes habilitar el envío de transformaciones si deseas que una canalización ejecute ciertas transformaciones en BigQuery.
Para obtener más información, consulta Cómo administrar las configuraciones de canalización.
Reutiliza canalizaciones con macros, preferencias y argumentos de tiempo de ejecución: Cloud Data Fusion te permite reutilizar canalizaciones de datos. Con canalizaciones de datos reutilizables, puedes tener una sola canalización que pueda aplicar un patrón de integración de datos a una variedad de casos de uso y conjuntos de datos. Las canalización reutilizables te brindan una mejor capacidad de administración. Te permiten configurar la mayor parte de la configuración de una canalización en el momento de la ejecución, en lugar de codificarla de forma fija en el momento del diseño. En Pipeline Design Studio, puedes usar macros para agregar variables a las configuraciones de complementos, de modo que puedas especificar las sustituciones de variables en el tiempo de ejecución. Para obtener más información, consulta Administra macros, preferencias y argumentos del entorno de ejecución.
Ejecutar: Una vez que hayas revisado las configuraciones de la canalización, puedes iniciar su ejecución. Puedes ver el cambio de estado durante las fases de la ejecución de la canalización, por ejemplo, aprovisionamiento, inicio, ejecución y éxito.
Programar y organizar: Las canalizaciones de datos por lotes se pueden configurar para que se ejecuten en una programación y frecuencia específicas. Después de crear e implementar una canalización, puedes crear un programa. En Pipeline Design Studio, puedes orquestar canalizaciones creando un activador en una canalización de datos por lotes para que se ejecute cuando se completen una o más ejecuciones de canalización. Estos se denominan canalizaciones descendentes y ascendentes. Creas un activador en la canalización descendente para que se ejecute según la finalización de una o más canalizaciones ascendentes.
Opción recomendada: También puedes usar Composer para organizar canalizaciones en Cloud Data Fusion. Para obtener más información, consulta Programa canalizaciones y Orquesta canalizaciones.
Editar canalizaciones: Cloud Data Fusion te permite editar una canalización implementada. Cuando editas una canalización implementada, se crea una versión nueva de la canalización con el mismo nombre y se marca como la versión más reciente. Esto te permite desarrollar canalizaciones de forma iterativa en lugar de duplicarlas, lo que crea una canalización nueva con un nombre diferente. Para obtener más información, consulta Edita canalizaciones.
Administración de control de código fuente: Cloud Data Fusion te permite administrar mejor las canalizaciones entre desarrollo y producción con la administración de control de código fuente de las canalizaciones con GitHub.
Registro y supervisión: Para supervisar los registros y las métricas de la canalización, se recomienda que habilites el servicio de registro de Stackdriver para usar Cloud Logging con tu canalización de Cloud Data Fusion.
¿Qué sigue?
- Obtén más información para administrar Studio.